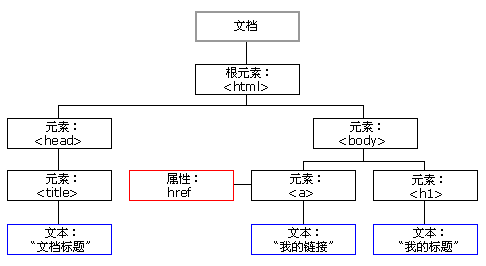
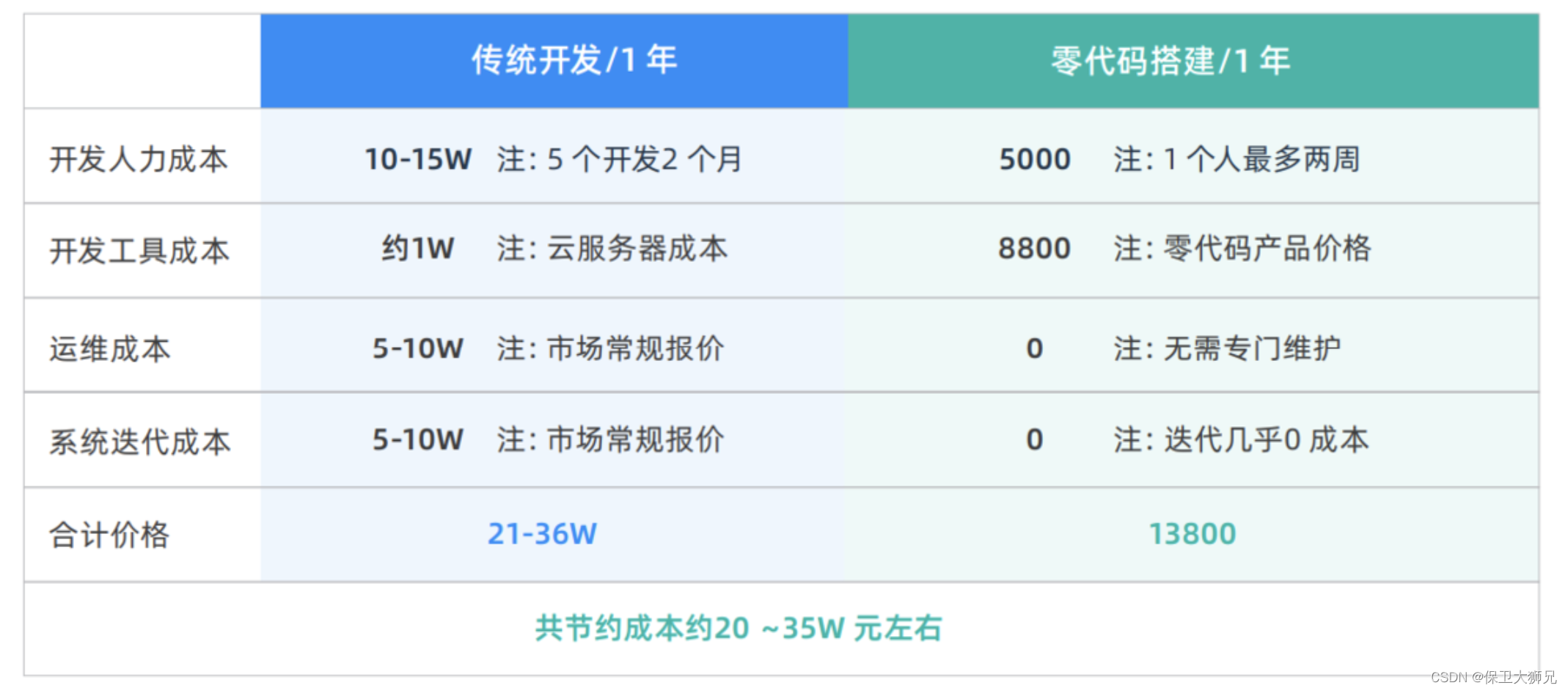
文章目录
- 表格部分数据如下
- 运行效果如下
- 代码解析
- 完整代码
- 附件
表格部分数据如下

附件里会给出全部数据链接
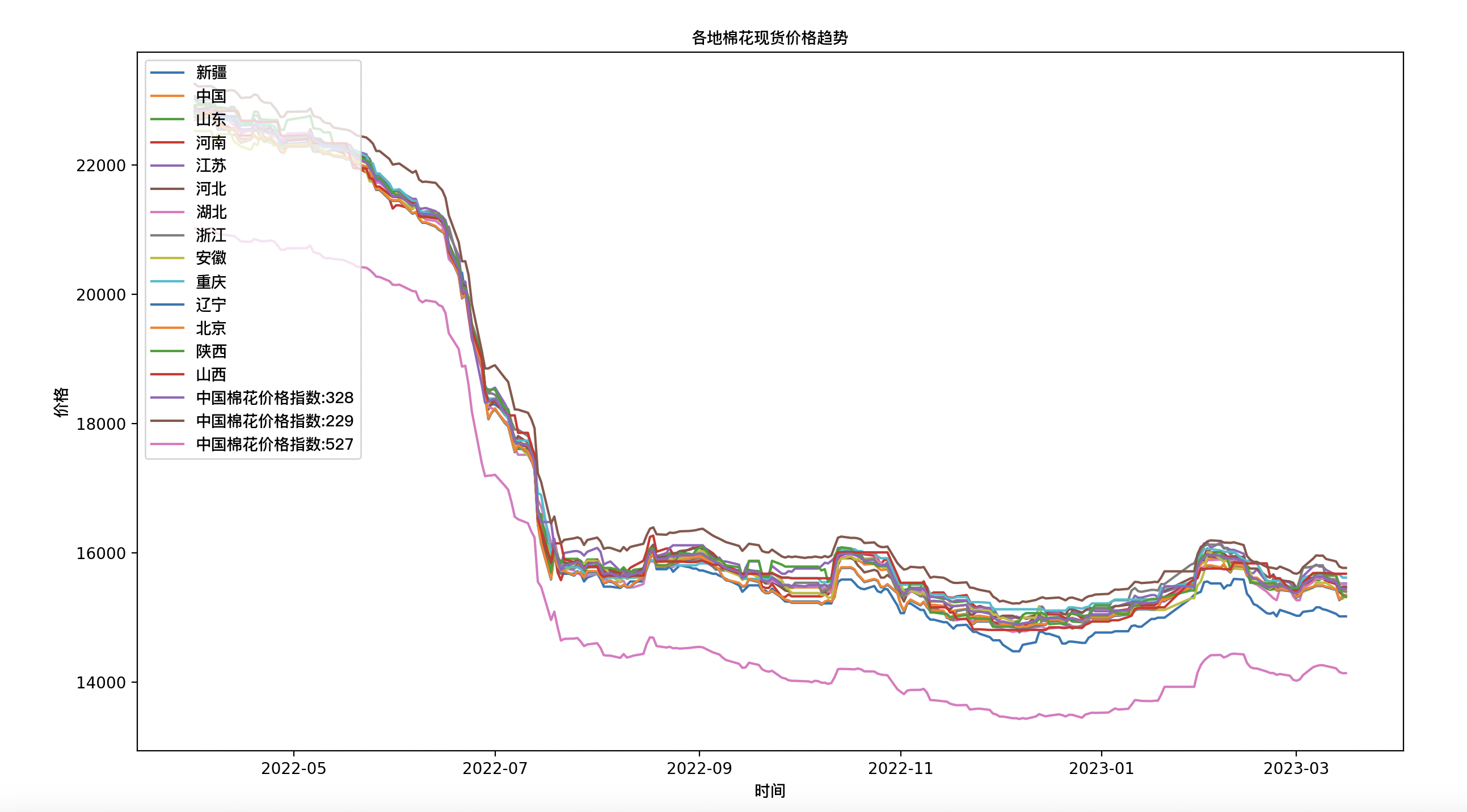
运行效果如下
代码解析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='PingFang Bold.ttf')
导入需要用到的Python库。pandas用于处理数据,numpy用于科学计算,matplotlib.pyplot用于绘图,FontProperties用于设置字体属性。在这里我们导入了中文字体PingFang Bold.ttf,以后进行绘图时就可以使用这个字体了。
df = pd.read_excel('中国各地现货棉花价格.xlsx')
df['指标名称'] = pd.to_datetime(df['指标名称'])
df.set_index('指标名称', inplace=True)
df.fillna(method='ffill', inplace=True)
打开了名为“中国各地现货棉花价格.xlsx”的Excel文件,并将数据存储到名为df的pandas DataFrame中。接下来,在DataFrame中执行以下操作:
- 将“指标名称”列转换为datetime类型;
- 将“指标名称”列设置为索引;
- 使用前向填充(ffill)方法填充缺失值。
plt.figure(figsize=[15,8])
plt.plot(df['新疆:现货价:棉花'], label='新疆')
plt.plot(df['中国:现货价:平均价:棉花'], label='中国')
plt.plot(df['山东:现货价:棉花'], label='山东')
plt.plot(df['河南:现货价:棉花'], label='河南')
plt.plot(df['江苏:现货价:棉花'], label='江苏')
plt.plot(df['河北:现货价:棉花'], label='河北')
plt.plot(df['湖北:现货价:棉花'], label='湖北')
plt.plot(df['浙江:现货价:棉花'], label='浙江')
plt.plot(df['安徽:现货价:棉花'], label='安徽')
plt.plot(df['重庆:现货价:棉花'], label='重庆')
plt.plot(df['辽宁:现货价:棉花'], label='辽宁')
plt.plot(df['北京:现货价:棉花'], label='北京')
plt.plot(df['陕西:现货价:棉花'], label='陕西')
plt.plot(df['山西:现货价:棉花'], label='山西')
plt.plot(df['中国棉花价格指数:328'], label='中国棉花价格指数:328')
plt.plot(df['中国棉花价格指数:229'], label='中国棉花价格指数:229')
plt.plot(df['中国棉花价格指数:527'], label='中国棉花价格指数:527')
plt.legend(loc='upper left', prop=font)
plt.xlabel('时间', fontproperties=font)
plt.ylabel('价格', fontproperties=font)
plt.title('各地棉花现货价格趋势', fontproperties=font)
plt.show()
绘制了各个地区棉花现货价格趋势图。首先使用matplotlib.pyplot库的figure()函数创建一个大小为15*8的绘图空间,然后使用plot()函数将各地棉花现货价格数据绘制到同一张图表上,并为每个数据系列添加了标签和线条颜色。最后添加图例、横纵坐标标题和图表标题,并调用show()函数显示图表。
train = df.iloc[:-10, :]
test = df.iloc[-10:, :]
将读取的数据集拆分成前面的训练集和后面的测试集。这里将DataFrame对象转换为了numpy数组,并使用“最后10个数据”作为测试集,“除了最后10个数据以外的数据”作为训练集。
X_train = train.drop('中国棉花价格指数:527', axis=1)
y_train = train['中国棉花价格指数:527']
X_test = test.drop('中国棉花价格指数:527', axis=1)
y_test = test['中国棉花价格指数:527']
通过drop()函数删除’target’列,获取输入和输出数据。在这里输入数据由除了中国棉花价格指数:527以外的数据组成,而输出数据只包含中国棉花价格指数:527这一列。
svr = SVR(kernel='rbf', C=10, gamma='auto')
svr.fit(X_train, y_train)
rf = RandomForestRegressor(n_estimators=100, random_state=0, criterion='mse', max_depth=None,
min_samples_split=2, min_samples_leaf=1, max_features='auto',
bootstrap=True, n_jobs=-1)
rf.fit(X_train, y_train)
knn = KNeighborsRegressor(n_neighbors=5, weights='distance')
knn.fit(X_train, y_train)
lr = LinearRegression()
lr.fit(X_train, y_train)
定义了四个回归模型(支持向量回归、随机森林回归、线性回归和K-最近邻回归),并使用fit()函数基于训练集数据对这些模型进行训练。参数的设置需要根据实际情况和调参结果来进行调整。
svr_pred = svr.predict(X_test)
rf_pred = rf.predict(X_test)
knn_pred = knn.predict(X_test)
lr_pred = lr.predict(X_test)
使用 predict() 函数对测试集进行预测,得到四个回归模型的预测值。
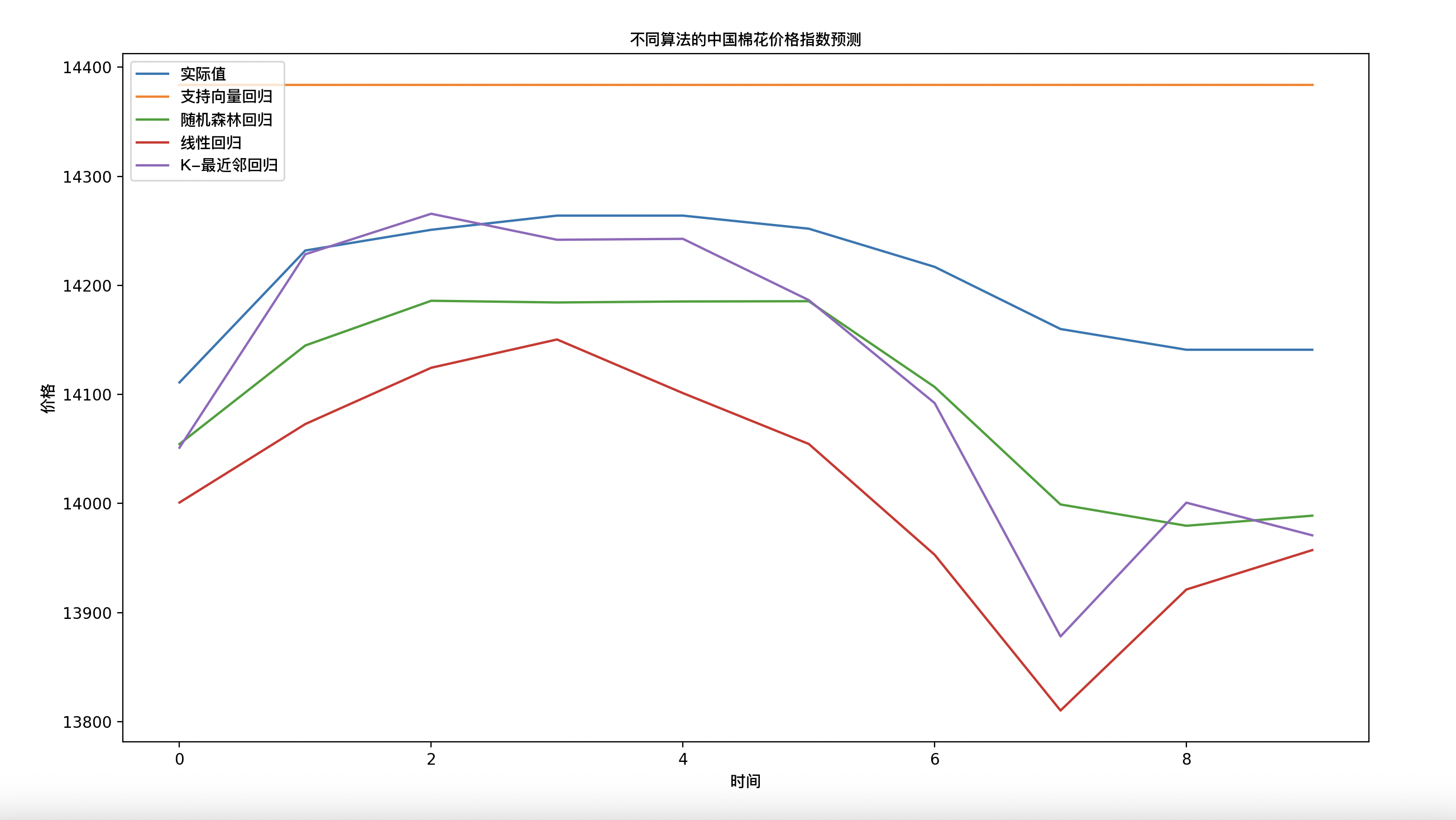
plt.figure(figsize=[15,8])
plt.plot(test['中国棉花价格指数:527'].values, label='实际值')
plt.plot(svr_pred, label='支持向量回归')
plt.plot(rf_pred, label='随机森林回归')
plt.plot(knn_pred, label='K-最近邻回归')
plt.plot(lr_pred, label='线性回归')
plt.legend(loc='upper left', prop=font)
plt.xlabel('时间', fontproperties=font)
plt.ylabel('价格', fontproperties=font)
plt.title('不同算法的中国棉花价格指数预测', fontproperties=font)
plt.show()
将四种回归模型的预测结果与实际值一起绘制成图表,以便于对预测结果进行比较和评估。其中实际值来自测试集中的数据。
完整代码
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 创建字体对象
font = FontProperties(fname='PingFang Bold.ttf')
# from matplotlib.font_manager import FontProperties
# pd.set_option('display.max_rows', None) # 显示所有行
# pd.set_option('display.max_columns', None) # 显示所有列
# 读取数据
df = pd.read_excel('中国各地现货棉花价格.xlsx')
# 将时间戳字段转换为 datetime 类型
df['指标名称'] = pd.to_datetime(df['指标名称'])
# 设定时间戳为数据索引
df.set_index('指标名称', inplace=True)
# 使用缺失值前向填充方法填充缺失值
df.fillna(method='ffill', inplace=True)
# 查看数据框结构
# print(df)
# 绘制每个地区的棉花价格
plt.figure(figsize=[15,8])
plt.plot(df['新疆:现货价:棉花'], label='新疆')
plt.plot(df['中国:现货价:平均价:棉花'], label='中国')
plt.plot(df['山东:现货价:棉花'], label='山东')
plt.plot(df['河南:现货价:棉花'], label='河南')
plt.plot(df['江苏:现货价:棉花'], label='江苏')
plt.plot(df['河北:现货价:棉花'], label='河北')
plt.plot(df['湖北:现货价:棉花'], label='湖北')
plt.plot(df['浙江:现货价:棉花'], label='浙江')
plt.plot(df['安徽:现货价:棉花'], label='安徽')
plt.plot(df['重庆:现货价:棉花'], label='重庆')
plt.plot(df['辽宁:现货价:棉花'], label='辽宁')
plt.plot(df['北京:现货价:棉花'], label='北京')
plt.plot(df['陕西:现货价:棉花'], label='陕西')
plt.plot(df['山西:现货价:棉花'], label='山西')
plt.plot(df['中国棉花价格指数:328'], label='中国棉花价格指数:328')
plt.plot(df['中国棉花价格指数:229'], label='中国棉花价格指数:229')
plt.plot(df['中国棉花价格指数:527'], label='中国棉花价格指数:527')
plt.legend(loc='upper left', prop=font)
plt.xlabel('时间', fontproperties=font)
plt.ylabel('价格', fontproperties=font)
plt.title('各地棉花现货价格趋势', fontproperties=font)
plt.show()
# 划分数据集
train = df.iloc[:-10, :]
test = df.iloc[-10:, :]
# 支持向量回归
from sklearn.svm import SVR
X_train = train.drop('中国棉花价格指数:527', axis=1)
y_train = train['中国棉花价格指数:527']
X_test = test.drop('中国棉花价格指数:527', axis=1)
y_test = test['中国棉花价格指数:527']
# svr = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1, coef0=1)
# svr.fit(X_train, y_train)
#
# # # 随机森林回归
# from sklearn.ensemble import RandomForestRegressor
#
# rf = RandomForestRegressor(n_estimators=10, random_state=0)
# rf.fit(X_train, y_train)
#
# # 线性回归
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
#
# # K-最近邻回归
# from sklearn.neighbors import KNeighborsRegressor
#
# knn = KNeighborsRegressor(n_neighbors=2)
# knn.fit(X_train, y_train)
svr = SVR(kernel='rbf', C=10, gamma='auto')
svr.fit(X_train, y_train)
# 随机森林回归
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100, random_state=0, criterion='friedman_mse', max_depth=None,
min_samples_split=2, min_samples_leaf=1, max_features='auto',
bootstrap=True, n_jobs=-1)
rf.fit(X_train, y_train)
# K-最近邻回归
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=5, weights='distance')
knn.fit(X_train, y_train)
# 预测
svr_pred = svr.predict(X_test)
rf_pred = rf.predict(X_test)
lr_pred = lr.predict(X_test)
knn_pred = knn.predict(X_test)
# print(test['中国棉花价格指数:527'].values)
# 展示预测结果
plt.figure(figsize=[15,8])
plt.plot(test['中国棉花价格指数:527'].values, label='实际值')
plt.plot(svr_pred, label='支持向量回归')
plt.plot(rf_pred, label='随机森林回归')
plt.plot(lr_pred, label='线性回归')
plt.plot(knn_pred, label='K-最近邻回归')
plt.legend(loc='upper left', prop=font)
plt.xlabel('时间', fontproperties=font)
plt.ylabel('价格', fontproperties=font)
plt.title('不同算法的中国棉花价格指数预测', fontproperties=font)
plt.show()
附件
链接: https://pan.baidu.com/s/1qa99ntHsozgqB2xliVYd7A 提取码: sp9h
–来自百度网盘超级会员v6的分享