目标检测论文总结
【RCNN系列】
RCNN
RCNN
- 目标检测论文总结
- 前言
- 一、Pipeline
- 二、模型设计
- 1.warp
- 2.SVM
- 3.阈值设定
- 4.box回归
- 三、思考
- 四、缺点
前言
一些经典论文的总结。
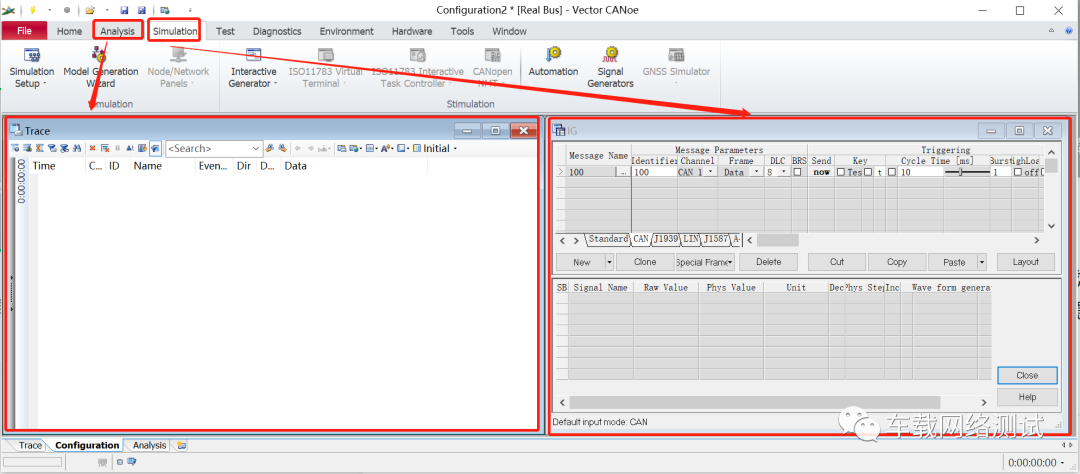
一、Pipeline
首先传入Input image,利用Selective Search(比较古老)算法取搜索图片中可能有物体的区域,并保存到本地磁盘。然后把这些得到的proposals(大约2000个)传入CNN也就是卷积网络抽取特征(只抽取特征不进行分类预测),最后再接一个SVM来进行预测分类(20类物体+1类背景)。
二、模型设计
1.warp
获取region proposals时,作者再每个原始的proposal上增加了16个像素。比如,红框是SS(selective search)算的得到的proposal,作者在周围多提取16个像素,也就是最终得到的是黄框。这样可以获取更多的边缘信息,防止某些特征被截断。

获取region proposals后,因为用的是AlexNet有全连接层,需要统一成227*227大小才能输入进CNN。在Reshape时,作者尝试了很多方法。

A列表示proposal,B列表示根据proposal在原图上直接进行缩放,也就是截取原图上227*227大小,C列表示等比缩放,也就是把长缩放到227,宽缩放相同的倍数(如果此时宽没有达到227就用像素平均值进行padding),D表示不等比缩放,也就是长宽各自缩放成227大小。每张图都有两行,第一行表示不进行每个原始的proposal增加16个像素,第二行表示增加16个像素。最终作者采用D不等比缩放,D的效果最好。
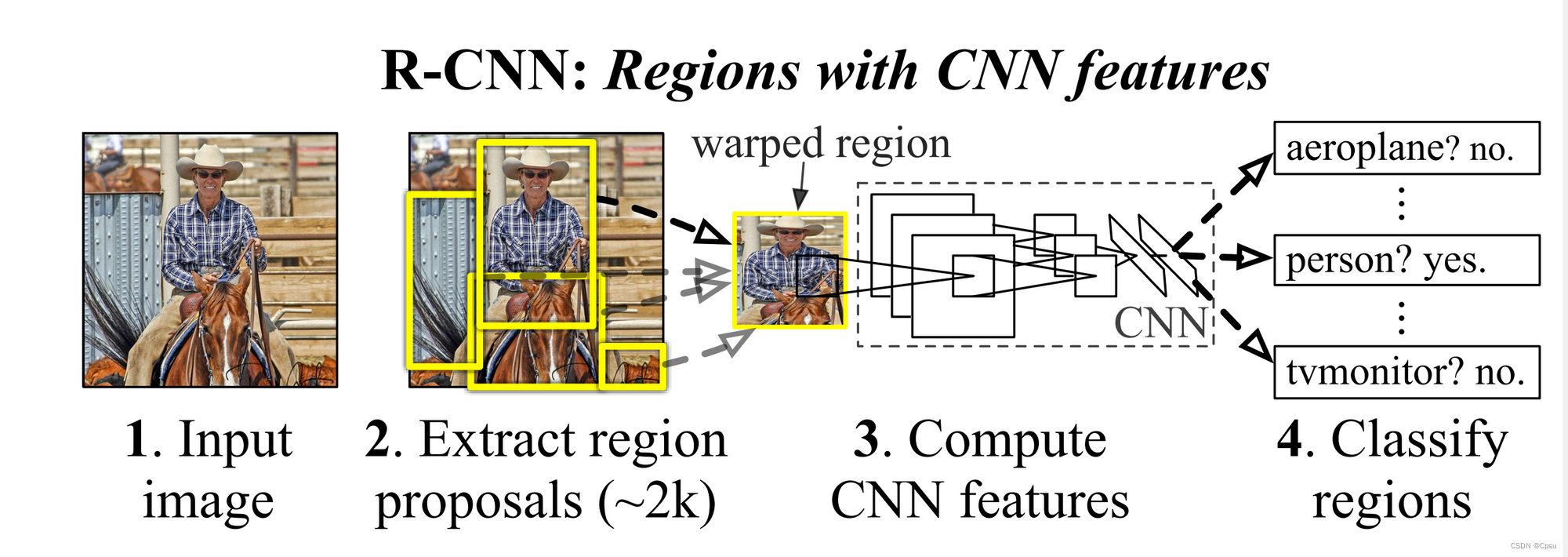
2.SVM
作者并没有把21个SVM分类器分开设计,而是写成矩阵运算的形式。
(x1,x2,...,x4096)表示CNN得到的特征向量即全连接层的最后4096维向量。
(w1,w2,...,w4096)表示参数
由于总共有2000个候选区,所以组成一个2000*4096维的矩阵,最后的输出结果是21类,所以乘上一个4096*21维的参数矩阵。最后输出2000*21维的分类结果。
3.阈值设定
通过SS算法得到2000多个proposal,但很多都不是我们想要的物体框,这时就涉及到正负样本的划分。
在CNN中:正样本是与GT(真实标注框)IoU≥0.5 的proposal,其他均为负样本(即分为背景类),且输入CNN的batchsize=128=32(正)+96(负)有32个正样本和96个负样本组成,来平衡正负样本的输入。
原因:
0.5阈值实验效果效果最好
SS算法提取的region大部分都都不包含目标即大部分应该都是负样本而CNN需要大量的数据进行训练,0.5阈值让正样本数扩大了30倍。
在SVM中:正样本是GT,负样本与GT的IoU≤0.3(一个个阈值实验所得)的proposal,作者发现如果阈值设为0.5效果会变差。而IoU大于0.3的会被抛弃,既不是正样本也不是负样本。因为这些样本可能都是比较好区分的,对于SVM来说,往往那些好区分的样本是不会影响SVM参数的取值的,对于SVM来说,远离支持向量的样本是不影响SVM效果的,也就是关键是要区分支持向量。也即是论文中说的难例挖掘。
注:其实作者一开始是没打算微调AlexNet,直接使用ImageNet训练得到的AlexNet。所以是先制定了SVM的正负样本划分阈值。后来引入了微调才需要划分正负样本重新训练,但发现CNN用SVM的划分方法效果太差,所以设定了不同的划分方法。
4.box回归
框回归是作者后来改进的做法,是为了得到更准确的预测目标框。就是把预测的目标框进行一些偏移,更加接近GT。
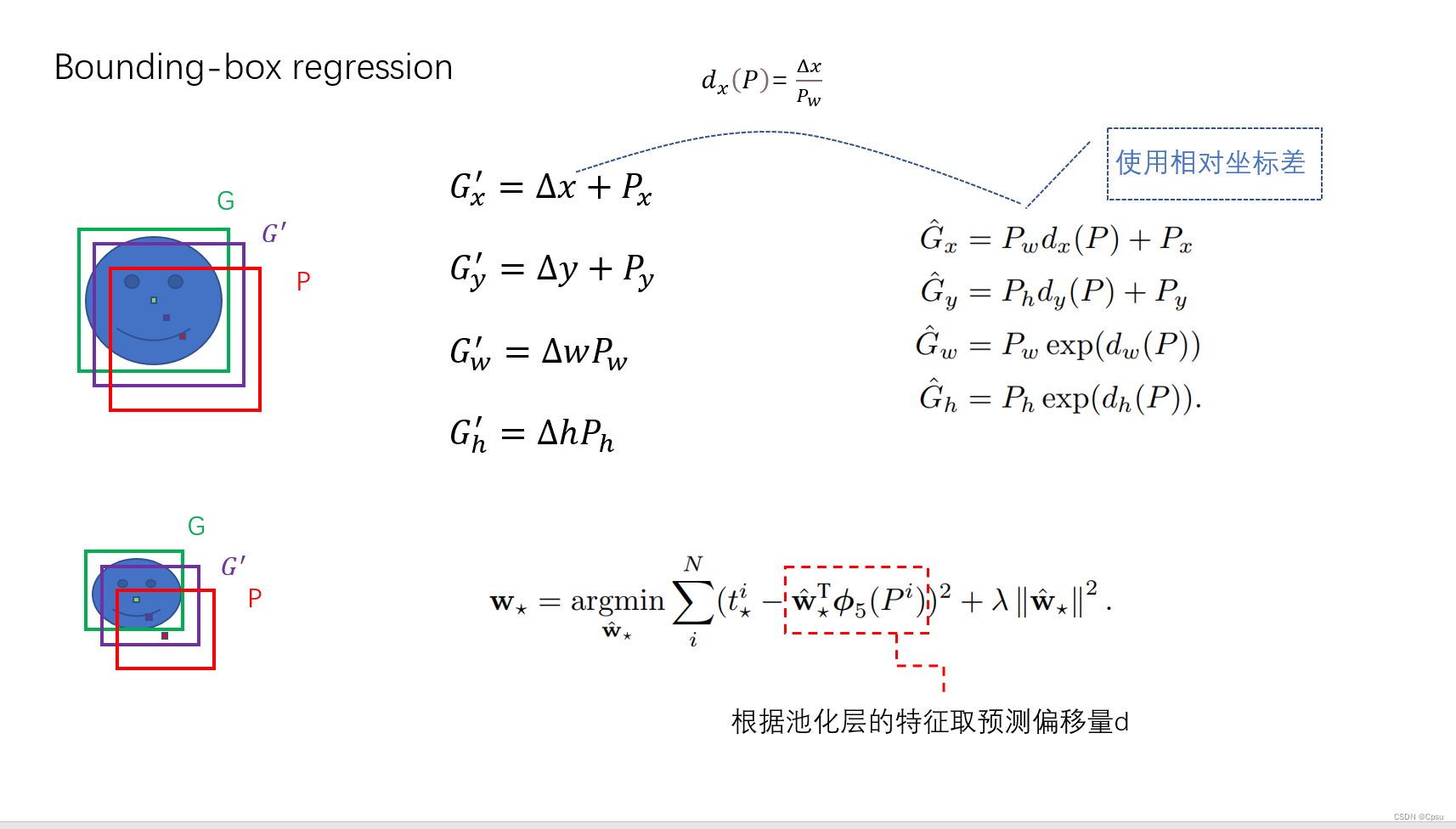
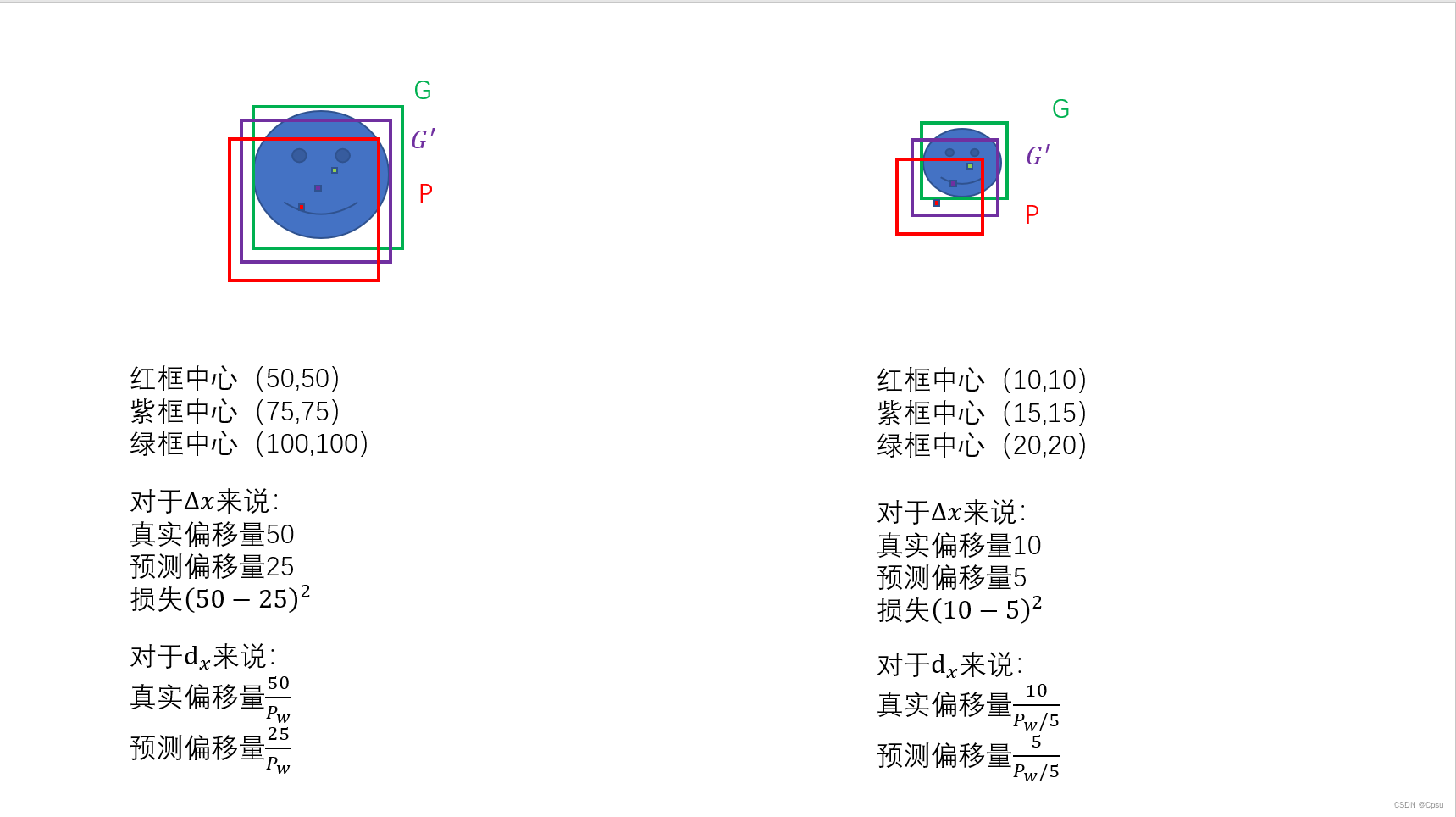
为什么不直接预测框的坐标而是预测偏移呢?因为这样大小目标可以有相同的损失
三、思考
为什么要额外用SVM?
1.作者实验发现直接用CNN分类精度会降低
2.CNN和SVM的正负样本划分不同。CNN中正样本的定义并不是精确的目标框,会导致误差
3.CNN的负样本是随机采样的,大部分都是容易识别的负样本。这里可以使用SVM进行难例挖掘,对于SVM来说,远离支持向量的样本是不影响SVM效果的,也就是关键是要区分支持向量。
四、缺点
RCNN是RCNN系列的第一个两阶段检测器,肯定是不完善的:
1.分阶段训练。流程太繁琐,每个region proposal都要送进CNN去跑一遍还要训练SVM分类(Fast RCNN改进点).
2.SS算法太弱而且还要保存到本地磁盘(Faster RCNN改进点)