文章目录
- 个体化动态方法(INSCAPE 方法):
- (A)生成脑共同激活状态的组模板:
- (B)个体水平分析:
- 不同的大脑状态有特定的协同激活模式(coactivation patterns)和发生率(occurrence rates)
- 脑状态的发生率在个体水平上是可靠的,并捕捉到了个体间的变异性
- 大脑的偏侧化在共激活脑状态的网络动态中得到了体现。
- 评估中风康复的动态共激活脑状态的发生率
- 局限性
- 参考文献
按:大量证据表明,脑功能连接不是静态的,而是动态的。捕捉个体脑的瞬时网络相互作用需要一种鲁棒的个体内可靠的技术。在这里,作者介绍了一种个体化的基于网络的动态分析技术,并证明它在检测个体脑状态方面具有可靠性,无论是在静息状态还是在认知挑战的语言任务中。作者评估了脑状态在半球对称性方面的表现程度,以及各种表型因素如惯用手和性别对网络动态的影响,发现右侧化的脑状态在男性中比女性更频繁出现,在惯用右手的个体中比惯用左手的个体更频繁出现。在42名患有亚皮质中风的患者中,还显示了纵向脑状态的变化,持续时间为6个月。作者的方法可以量化个体特定的动态脑状态,并在基础和临床神经科学研究中具有潜力应用。

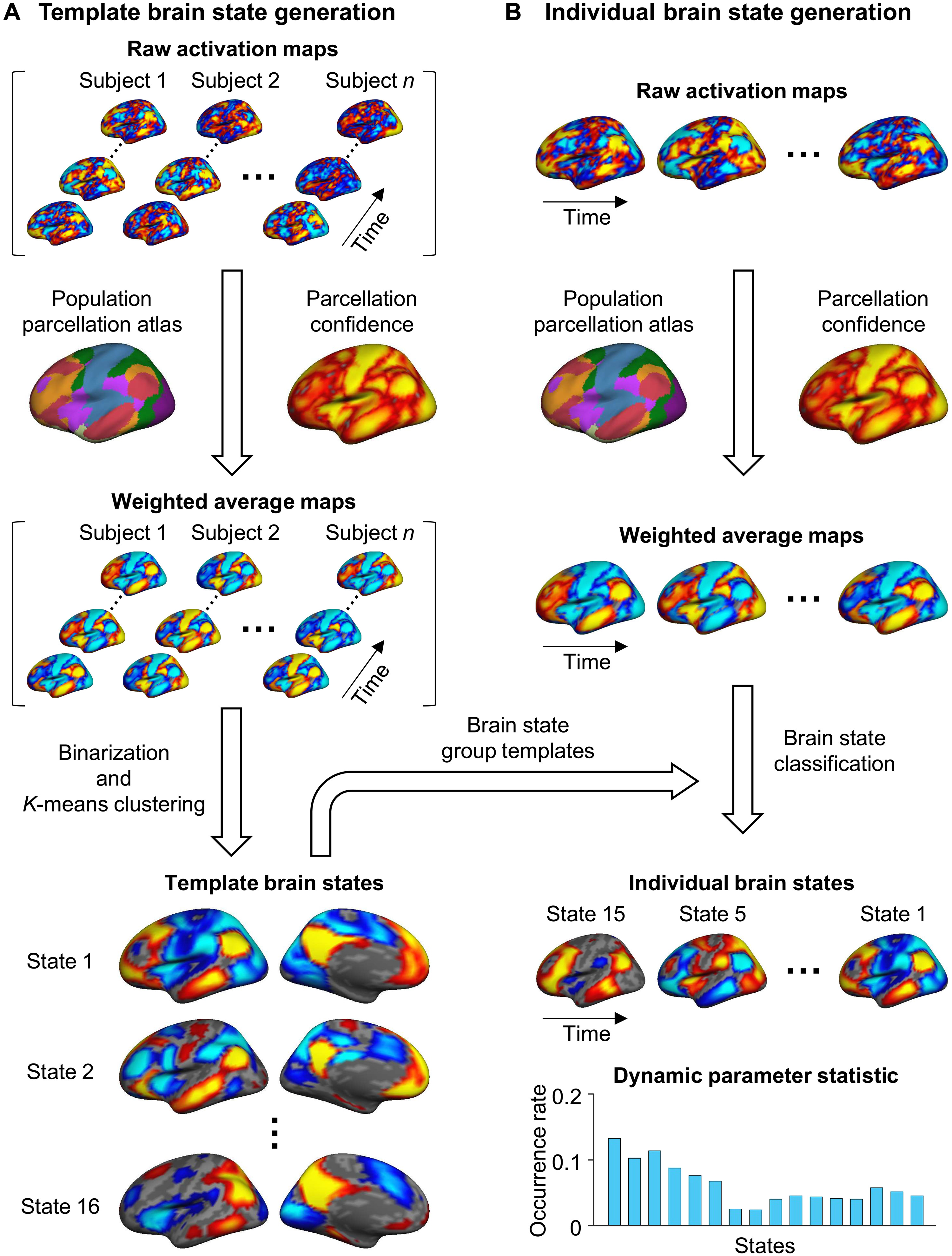
个体化动态方法(INSCAPE 方法):
(A)生成脑共同激活状态的组模板:
- 使用来自GSP(数据集I)的846名健康受试者的静息态fMRI数据集。特别的对每个受试者的fMRI数据进行预处理,并投影到FreeSurfer fsaverage4表面空间,每个半球有2562个顶点(原始的大脑应该是灰度值,这个Raw activation maps应该是全脑归一化的结果)。

- 对于预处理后的BOLD数据的每个时间帧,进行基于组的皮层分割的置信度加权( parcellation confidence ),并在48个网络区域(每个半球24个)内进行平均。

- parcellation confidence的计算(B. T. Yeo The organization of the human cerebral cortex estimated by intrinsic functional connectivity. J. Neurophysiol):
置信度是每个空间位置属于其分配网络的概率。作者使用了聚类文献中的轮廓系数(Rousseeuw 1987)(参见图8和图10)。数据点(在我们的情况下为空间位置)的轮廓系数测量了该数据点与同一簇(在我们的情况下为网络)中其他数据点的相似性(在我们的情况下为相关性),并将其与属于下一个最近簇的数据点进行比较。

- 对48个区域的平均激活图进行二值化处理(大于0的值设为1,小于0的值设为-1),代表加权共激活图的平均值。
- 将所有受试者的加权共激活图以及时间序列连接在一起。
- 进行k-means聚类分析,将fMRI帧分类为16个簇。选择16个簇的最优簇数基于测试-重测可靠性(the test-retest reliability analysis)分析的结果,以平衡测试-重测可靠性和脑状态的多样性。

**图解:**基于脑状态的测试-重测稳定性确定最佳聚类数。在测试-重测稳定性的基础上,优化了脑状态的聚类数。从数据集I的846名受试者中,随机选择了一半的静息态运行,并分配给测试组,另一半分配给重测组。聚类分析的稳定性被估计为来自测试组和重测组的脑状态的平均空间相似度。这个测试-重测过程重复了100次。在100次重复中绘制了平均稳定性(深蓝曲线)和±SEM(蓝色阴影区域)。曲线上识别出了几个局部极大值(用红色星号标记),表明6、8、10、16和19个聚类解相对稳定。在本研究中,我们选择了16个聚类进行进一步分析,因为它在测试-重测可靠性和脑状态的多样性之间取得了平衡。 - 将分配到同一簇的fMRI帧进行平均,生成16个动态脑状态的群体模板。

(B)个体水平分析:
- 对个体的预处理fMRI数据进行与(A)步骤相同的操作,将其加权并在48个区域内进行平均。

2. 根据与其最短空间距离的组模板,将每个区域的激活图分配给16个脑状态中的一个。
3. 计算每个脑状态的发生率,即分配到给定脑状态的帧数占总帧数的百分比。

该方法允许基于来自大型数据集生成的群体模板来识别和表征个体特定的功能脑状态。
图1.整体流程图
不同的大脑状态有特定的协同激活模式(coactivation patterns)和发生率(occurrence rates)
使用INSCAPE方法和脑基因组超结构项目(GSP;数据集I)的846名健康个体的静息态fMRI数据生成了16个脑状态的组模板(协同激活模式)和所有脑状态的发生率(计算方式见上图)。
所有脑状态的共同激活模式展现了内在的功能网络特性。在静息状态下,具有默认模式(DN)激活的脑状态具有最高的发生率,其次是展示构成显著性(SN)和额顶叶-顶叶控制(FPN)网络的区域之间共同激活的脑状态。此外,还发现了涉及其他网络(如腹侧注意、视觉和感觉运动网络)的多种不同组合的共同激活脑区。值得注意的是,我们观察到了显示半球侧化的特定脑状态,并将在下一节中详细讨论这些结果。
图2. 16种共激活脑状态的发生率和空间图。
利用INSCAPE方法计算了来自GSP数据集的846名健康个体的脑共激活状态的群体模板。通过对被分配到同一聚类中的FMRI时间帧进行平均并按降序排列它们的发生率,生成了群体级别的脑状态共激活图。在16种脑状态中,状态1至4表现出经典的默认模式(DN)激活,并且在静息状态下在受试者中具有最高的发生率。a.u.表示任意单位。

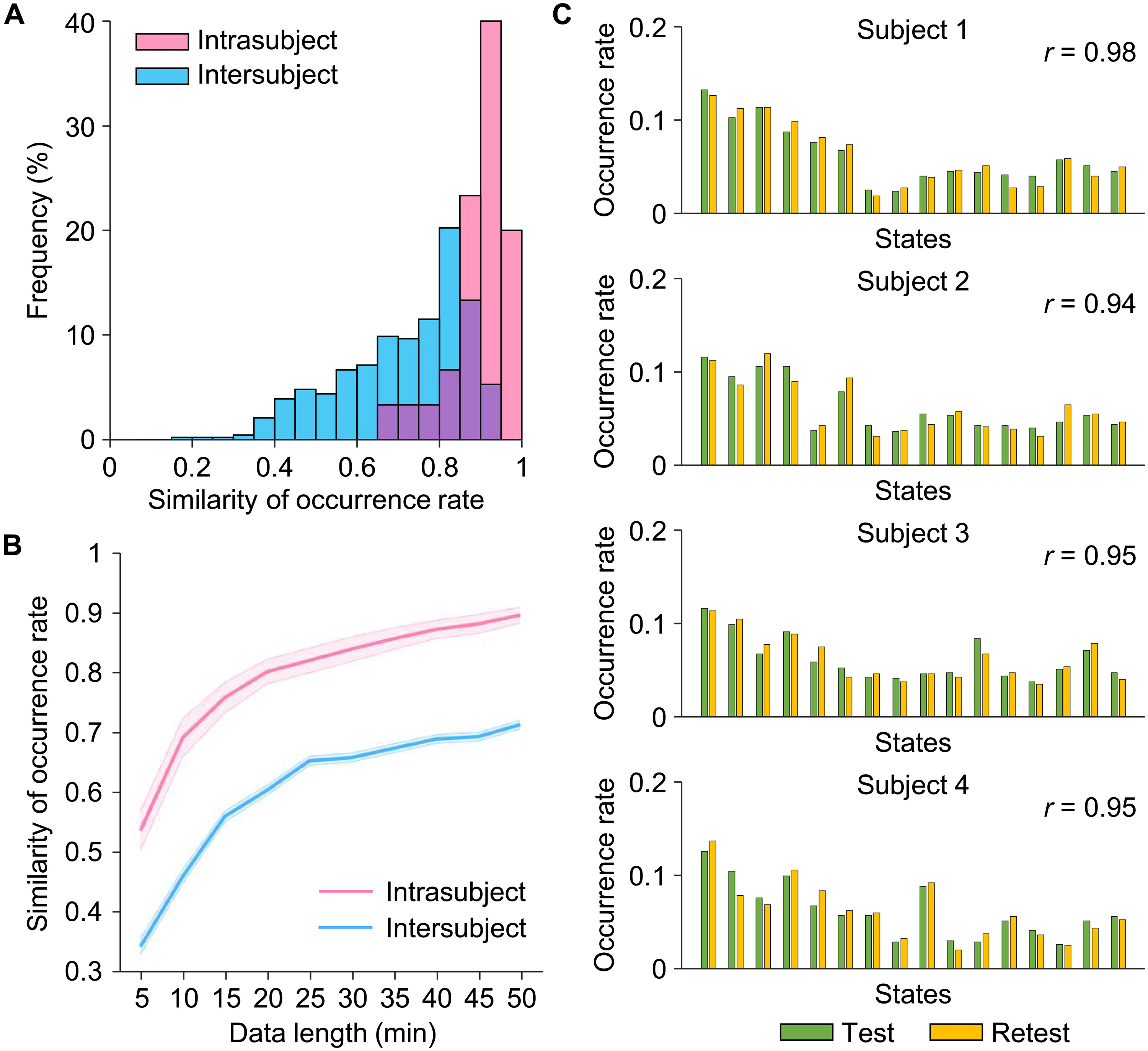
脑状态的发生率在个体水平上是可靠的,并捕捉到了个体间的变异性
- 为了评估我们的INSCAPE方法在捕捉个体特异脑状态的发生率方面的测试-重测可靠性和敏感性,我们将每个参与者在CORR-HNU数据集(数据集II)中的静息态fMRI数据平均分为测试和重测两个部分,并计算了每个部分中脑状态的发生率。
- 我们使用Pearson相关系数测试了脑状态发生率的个体内和个体间相似性(图3A)。两个部分中得出的脑状态发生率的个体内一致性很高,平均内部一致性为r = 0.90。在任意两个个体之间,脑状态发生率的平均相似性为0.71(个体间变异性为0.29)。
- 图3C显示了四位参与者的测试-重测结果,展示了每位参与者脑状态发生率的分布。预期地,个体内脑状态发生率的相似性显著高于个体间相似性[t(463) = 6.621, P < 0.001],表明INSCAPE方法不仅在单个参与者水平上具有高度的可重复性,而且可以可靠而稳健地捕捉到个体间的差异。
- 由于数据采集长度是影响基于fMRI分析可靠性的主要因素之一,我们使用不同长度的静息态fMRI数据(从5到50分钟,每次增加5分钟)估计了发生率的测试-重测可靠性。随着数据长度的增加,个体内和个体间的发生率相似性都增加(图3B)。当使用15分钟的fMRI数据时,观察到0.70的个体内测试-重测可靠性,随着数据增加到50分钟,平均可靠性提高到0.90。
图3. INSCAPE分析的可靠性估计。
大脑的偏侧化在共激活脑状态的网络动态中得到了体现。
大脑的偏侧化是人类大脑的一种组织原则,被认为有助于快速和高效的信息处理。为了确定16个共激活脑状态在功能上的偏侧化程度,研究中计算了偏侧化指数(laterality index,LI),

- 通过比较左右半球激活的顶点数来计算。在分析GSP数据集时,通过INSCAPE方法得出的16个脑状态中,状态15显示了最强的向左偏侧化(图4A),状态11显示了最强的向右偏侧化(图4A)。
- 左偏侧化的状态15包括左侧前额叶皮层、颞顶联合区和后扣带皮层等区域。右偏侧化的状态11则在岛叶、角回和背侧前扣带皮层等区域显示了强烈的共激活。
- 研究还通过在MNI152体积空间中的小脑掩模内对相应的原始共激活图进行平均,来检查这些侧化脑状态在小脑中的激活模式。左偏侧化状态15和右偏侧化状态11在小脑中均显示出对侧小脑上的不对称功能激活。
图4. 共同激活脑状态的大脑侧化在对侧小脑得到体现。

另一个重要发现是,构成左侧化脑状态15的共同激活区域与传统语言皮层区域高度重叠。为了调查侧化脑状态是否反映了语言侧化的程度,我们估计了独立样本(数据集III)中55名健康参与者在静息状态和语言任务(即语义决策任务)期间脑状态15和11的发生率。 - 与静息状态相比,左侧化状态15在语言任务期间显示出显著更高的发生率[图4B;配对t检验,t(54) = 6.633,**P < 0.001],而右侧化状态11在静息状态期间显示出显著更高的发生率[配对t检验,t(54) = 3.875,**P < 0.001]。
- 然后,我们根据两个半球的不对称任务诱发激活,为每个参与者计算了基于任务的语言侧化指数(language LI)。语言侧化与任务期间左侧化脑状态15的发生率呈显著相关(图4C;r = 0.51,P < 0.001)。
- 我们还研究了在语言任务的每个时间点上,所有参与者的脑状态发生率与任务处理引起的血氧响应曲线之间的关系。结果显示,左侧化脑状态15的发生率与语言任务的开始呈强正相关(图4D;r = 0.70,P < 0.001),而右侧化脑状态11与语言任务的开始呈中度负相关(r = −0.34,P < 0.001)。
图4. 共同激活脑状态的大脑侧化在语言任务中得到体现。

最后,考虑到利手性和性别对语言功能侧化的已知影响,我们在两个独立数据集中研究了这些表型特征对共同激活脑状态的侧化的影响。对于利手性比较,我们计算了来自数据集IV的52名左撇子和52名与其在人口统计学特征上匹配的右撇子受试者的侧化脑状态的发生率。 - 与左撇子相比,右撇子显示出右侧化状态11的显著更高的发生率[图5A;双样本t检验,t(102) = 2.037,*P = 0.044]。发生率的分布也显示出右撇子受试者中状态11的发生率较左撇子受试者更高(Kolmogorov-Smirnov检验,P = 0.021)。
- 然后,我们在来自数据集V的279名男性和279名与其在年龄、教育和利手性上匹配的女性中,比较了侧化脑状态的发生率差异。总体而言,与女性相比,男性在右侧化状态11的发生率上显示出显著更高的发生率[双样本t检验,t(556) = 2.674,**P = 0.008],并呈现出在左侧化状态15的发生率上呈现趋势性显著更高的趋势[图5B;双样本t检验,t(556) = 1.877,P = 0.061]。
图5. 左右利手性和性别对侧化脑状态的发生率的影响。

评估中风康复的动态共激活脑状态的发生率
个体化的动态脑状态可用于评估各种脑疾病患者的功能性脑状态,尤其是在监测治疗后的疾病进展或康复过程中。作为一个概念验证,我们将我们的INSCAPE方法应用于一个数据集(数据集VI),其中包括42名亚皮质中风患者和23名健康对照参与者,以评估其在6个月内的功能变化。我们选择了这个中风数据集,因为患者的明确病因和功能损伤在受试者之间的同质性。
- 在6个月的康复期内,对患者在中风后的1至7、14、30、90和180天进行了五个时间点的16种脑状态的发生率估计。我们还在一个健康对照组中的一个时间点估计了16种脑状态的发生率,作为与中风患者组在1至7天中风后时间点的对比基线。重复测量方差分析(ANOVA)的结果显示时间的主效应[F(4)= 4.451,P = 0.002,家族式错误率(FWER)校正]。
- 总体而言,在中风康复的6个月期间观察到左侧定位的脑状态15的发生率逐渐和持续减少。一系列事后配对样本t检验表明,与基线(中风后1至7天)时间点相比,脑状态15的发生率在90天[t(41)= 3.662,**P < 0.001]和180天[t(41)= 2.684,*P = 0.01]中风后显著降低(FWER校正)。急性阶段最初升高的状态15的发生率随着时间的推移而恢复正常,并在6个月时变得类似于健康对照组[two-sample t test,1至7天中风后:t(63)= 1.883,P = 0.064,6个月中风后:t(63)= 0.296,P = 0.768]。然而,状态15的发生率与运动评分无直接相关性(P > 0.05)。

图解:(A) 在患有亚皮质中风的患者中,我们估计了16种脑状态在6个月期间的五个时间点上的发生率(即中风后的1至7、14、30、90和180天)。条形图显示了患者组(n = 42;蓝色柱)在每个连续时间点上脑状态15的平均发生率(±SEM),以及健康对照组(n = 23;白色柱)的发生率。与基线(中风后1至7天)相比,中风患者在90天和180天的时间点上左侧定位的脑状态15发生率显著降低(配对t检验,*P < 0.05和**P < 0.01)。右侧显示了患者在中风后1至7天和180天的左侧定位脑状态15的共同激活图。
考虑到脑状态15是一个偏侧脑状态,我们假设在中风后的6个月康复期内,脑状态15的发生率持续降低可能表明亚皮质中风引起的两半球对应性缺陷的逐渐康复。为了测试这一假设,我们选择了五个左半球区域(L1:感觉运动区,L2:顶叶上沟回,L3:侧前额皮质,L4:中颞回,L5:角回),它们在中风后的1至7天内在脑状态15中具有最高激活度,并选择了对称的五个右半球区域(R1、R2、R3、R4和R5)(图6B)。
- 在每个时间点,我们计算了这些区域之间(即L1-R1、L2-R2、L3-R3、L4-R4和L5-R5)的功能连接强度(FC),并对中风后的各时间点的患者进行了平均,以测量两半球之间连接随时间的变化。重复测量方差分析(ANOVA)的结果显示了时间的主效应[F(4)= 4.504,P = 0.002,FWER校正],表明在中风后的6个月康复期间,患者的两半球之间的FC逐渐增加(。
- 事后配对样本t检验显示,在30天[t(41)= 2.201,*P = 0.033]、90天[t(41)= 3.540,**P = 0.001]和180天[t(41)= 2.289,*P = 0.027]中风后,两半球之间的FC显著增加,与基线(中风后1至7天)相比
- 然后,在每个半球内估计任意两个区域之间的FC,并进行平均以代表半球内的连接强度。在中风康复的6个月期间,两个半球都显示出半球内FC的逐渐减少[重复测量方差分析,左半球:F(4)= 4.688,P = 0.001,右半球:F(4)= 2.623,P = 0.037]。一系列事后配对样本t检验显示,在90天和180天中风后,两个半球内的FC显著降低,与急性阶段相比[中风后90天与中风后7天对比,左半球:t(41)= 2.874,**P = 0.

局限性
- 首先,选择了一定数量的脑状态有一定的随意性。在本研究中,我们选择了16个脑状态的解决方案,以最大化测试和重测数据中脑状态的空间相似性。这个过程在一定程度上可以避免聚类数目选择对脑状态的时间特性(即发生率,本研究中的主要动态指标)的影响。在未来的研究中可以尝试使用其他指标,如轮廓系数,来寻找最优的聚类数目。
- 其次,在本研究中我们选择了发生率作为我们的主要指标,没有评估其他动态指标,如停留时间和状态转换次数。我们发现停留时间和状态转换概率高度依赖于发生率。然而,鉴于我们的方法在个体水平上为每个时间点提供了一个脑状态标签,可以轻松地计算出各种次要的动态指标,包括停留时间和状态转换概率。
- 第三,一些最近的研究表明,在单体积MRI数据中观察到的共同激活模式可能并不完全归因于静息脑活动的非平稳性,而应注意所有时间点,而不仅仅是那些被假定包含神经事件的时间点。虽然我们发现INSCAPE方法得到的脑状态可以反映语言任务中的神经事件,但是应谨慎解释这些状态。
- 第四,在当前的INSCAPE流程中,我们对数据进行了带通滤波,就像传统的静息态fMRI分析一样。一些研究表明,静息态fMRI信号的高频振荡(>0.1 Hz)也能编码有意义的神经信息,尽管它们更容易受到心跳和呼吸引起的生理噪声的影响。因此,未来可以探索高频带中的时间动态。
- 最后,在我们当前的INSCAPE流程中,fMRI数据被根据来自群体级皮层分区的置信度加权。应考虑功能网络动态的个体间差异。例如,组分区模板可以在未来的研究中被个体化的皮层分区所取代。
参考文献
Robust dynamic brain coactivation states estimated in individuals
INSCAPE!破解时空交织中的动态大脑指纹 — 引读刘河生教授最新个体化研究成果