项目地址:
https://github.com/PlayVoice/so-vits-svc-5.0
来源丨元语音技术

-
本项目的目标群体是:深度学习初学者,具备Pyhon和PyTorch的基本操作是使用本项目的前置条件;
-
本项目旨在帮助深度学习初学者,摆脱枯燥的纯理论学习,通过与实践结合,熟练掌握深度学习基本知识;
-
本项目不支持实时变声;(也许以后会支持,但要替换掉whisper)
-
本项目不会开发用于其他用途的一键包。(不会指没学会)

-
【低 配置】6G显存可训练
-
【无 泄漏】支持多发音人
-
【带 伴奏】也能进行转换,轻度伴奏
模型和日志:
https://github.com/PlayVoice/so-vits-svc-5.0/releases/tag/v5.3
-
5.0.epoch1200.full.pth模型包括:生成器+判别器=176M,可用作预训练模型;
-
发音人(56个)文件在configs/singers目录中,可进行推理测试,尤其测试音色泄露;
-
发音人22,30,47,51辨识度较高,音频样本在configs/singers_sample目录中。

GRL去音色泄漏,更多的是理论上的价值;Hugging Face Demo推理模型无泄漏主要归因于PPG扰动;由于使用了数据扰动,相比其他项目需要更长的训练时间。
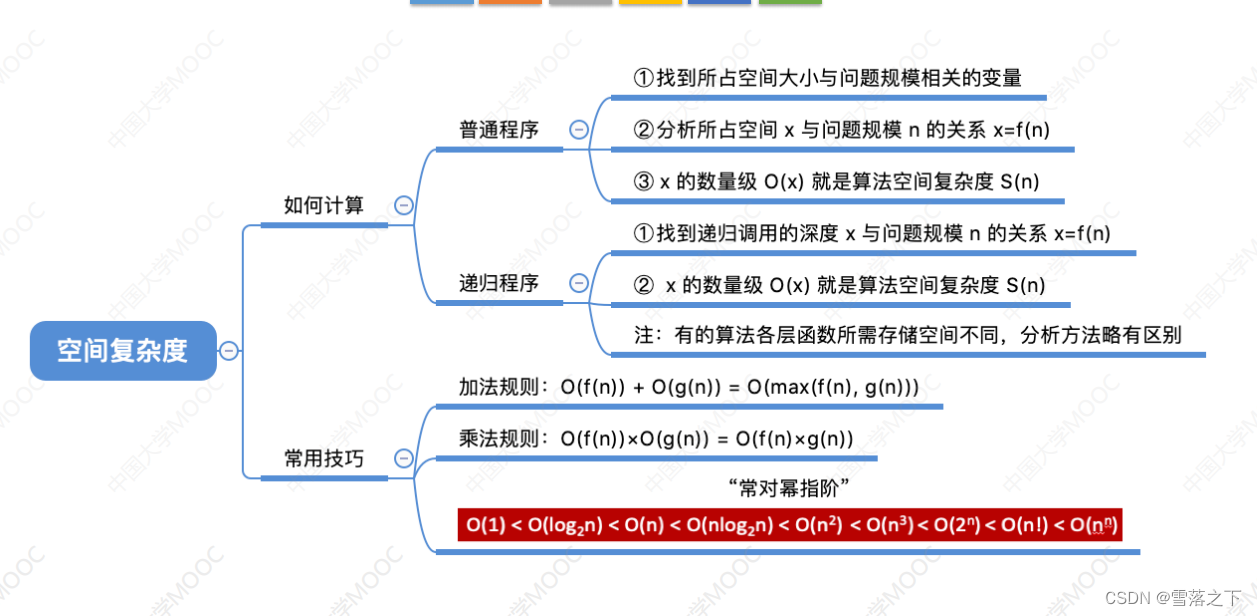
数据集准备

必要的前处理:
-
1 降噪&去伴奏
-
2 频率提升
-
3 音质提升,基于https://github.com/openvpi/vocoders ,待整合
-
4 将音频剪裁为小于30秒的音频段,whisper的要求
然后以下面文件结构将数据集放入dataset_raw目录
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
安装依赖
-
软件依赖
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
-
下载音色编码器: Speaker-Encoder by @mueller91, 解压文件,把
best_model.pth.tar放到目录speaker_pretrain/ -
下载whisper模型 multiple language medium model, 确定下载的是
medium.pt,把它放到文件夹whisper_pretrain/
数据预处理
-
设置工作目录
export PYTHONPATH=$PWD
-
重采样
生成采样率16000Hz音频, 存储路径为:./data_svc/waves-16k
python prepare/preprocess_a.py -w ./data_raw -o ./data_svc/waves-16k -s 16000
生成采样率32000Hz音频, 存储路径为:./data_svc/waves-32k
python prepare/preprocess_a.py -w ./data_raw -o ./data_svc/waves-32k -s 32000
可选的16000Hz提升到32000Hz,待完善~批处理
python bandex/inference.py -w svc_out.wav
-
使用16K音频,提取音高
python prepare/preprocess_f0.py -w data_svc/waves-16k/ -p data_svc/pitch
-
使用16k音频,提取内容编码
python prepare/preprocess_ppg.py -w data_svc/waves-16k/ -p data_svc/whisper
-
使用16k音频,提取音色编码
python prepare/preprocess_speaker.py data_svc/waves-16k/ data_svc/speaker
-
使用32k音频,提取线性谱
python prepare/preprocess_spec.py -w data_svc/waves-32k/ -s data_svc/specs
-
使用32k音频,生成训练索引
python prepare/preprocess_train.py
-
训练文件调试
python prepare/preprocess_zzz.py
训练
-
如果基于预训练模型微调,需要下载预训练模型5.0.epoch1200.full.pth
指定configs/base.yaml参数pretrain: "",并适当调小学习率
-
设置工作目录
export PYTHONPATH=$PWD
-
启动训练
python svc_trainer.py -c configs/base.yaml -n sovits5.0
-
恢复训练
python svc_trainer.py -c configs/base.yaml -n sovits5.0 -p chkpt/sovits5.0/***.pth
-
查看日志,release页面有完整的训练日志
tensorboard --logdir logs/

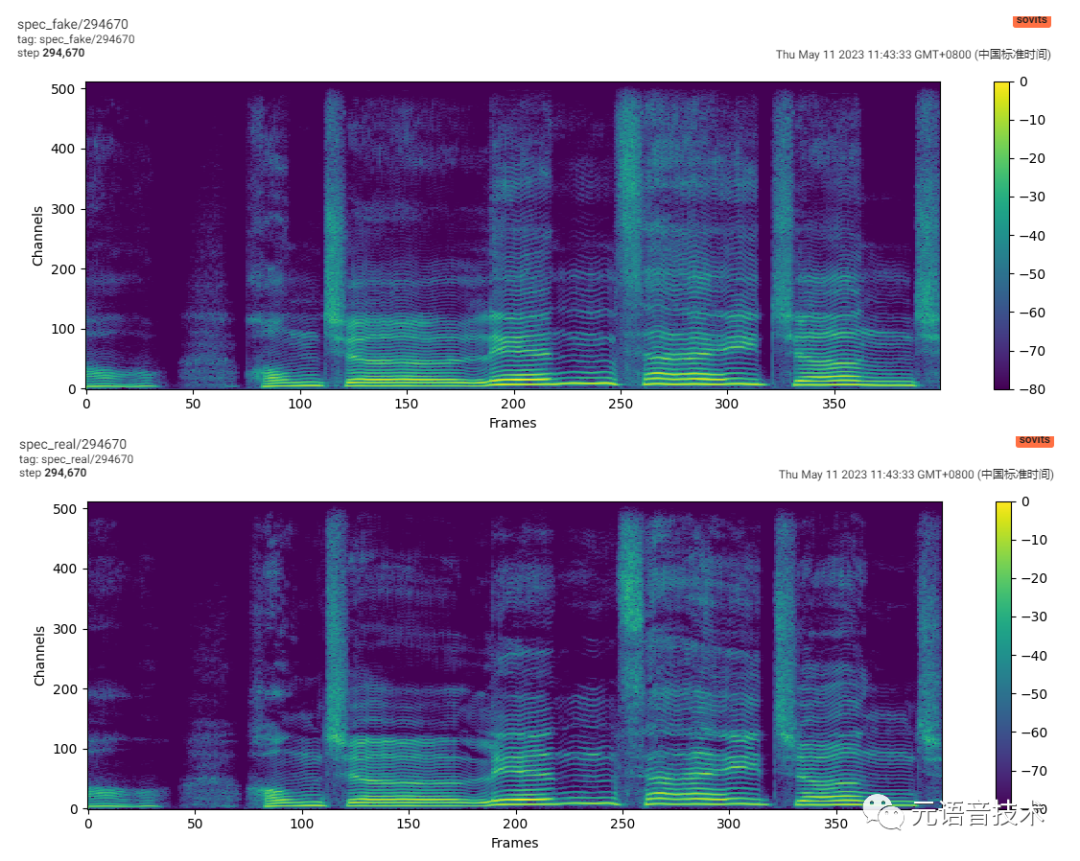
推理
-
设置工作目录
export PYTHONPATH=$PWD
-
导出推理模型:文本编码器,Flow网络,Decoder网络;判别器和后验编码器只在训练中使用
python svc_export.py --config configs/base.yaml --checkpoint_path chkpt/sovits5.0/***.pt
-
使用whisper提取内容编码,没有采用一键推理,为了降低显存占用
python whisper/inference.py -w test.wav -p test.ppg.npy
生成test.ppg.npy;如果下一步没有指定ppg文件,则调用程序自动生成
-
提取csv文本格式F0参数,Excel打开csv文件,对照Audition或者SonicVisualiser手动修改错误的F0
python pitch/inference.py -w test.wav -p test.csv
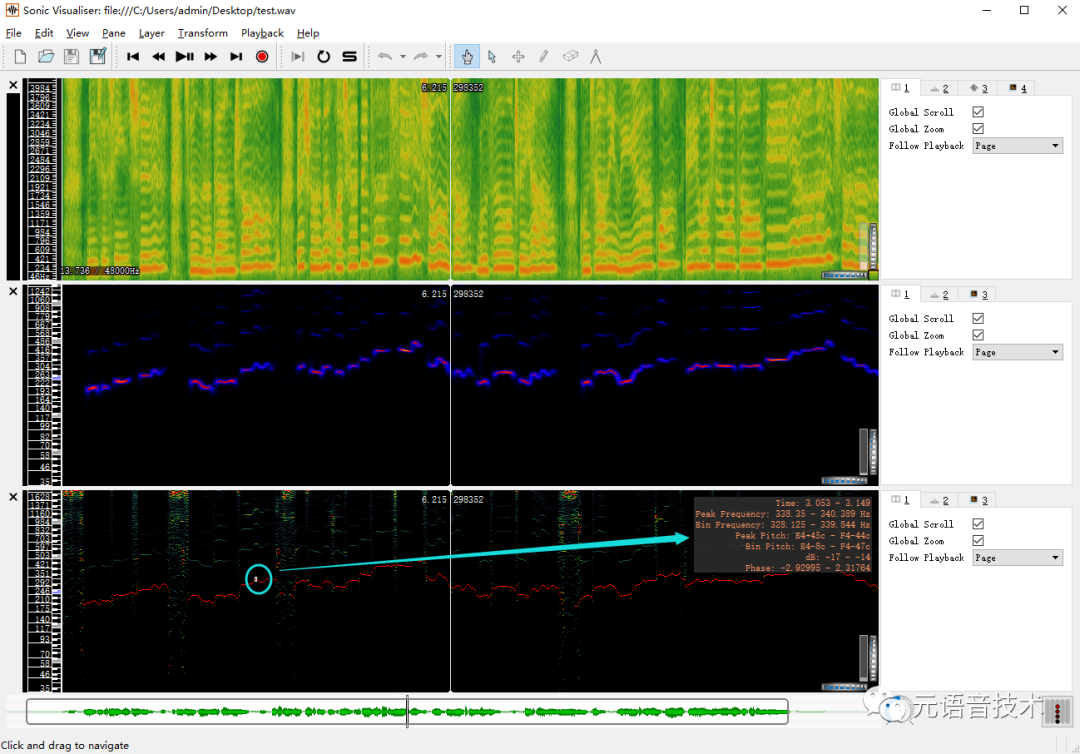
-
指定参数,推理
python svc_inference.py --config configs/base.yaml --model sovits5.0.pth --spk ./configs/singers/singer0001.npy --wave test.wav --ppg test.ppg.npy --pit test.csv
当指定--ppg后,多次推理同一个音频时,可以避免重复提取音频内容编码;没有指定,也会自动提取;
当指定--pit后,可以加载手工调教的F0参数;没有指定,也会自动提取;
生成文件在当前目录svc_out.wav;
| args | --config | --model | --spk | --wave | --ppg | --pit |
|---|---|---|---|---|---|---|
| name | 配置文件 | 模型文件 | 音色文件 | 音频文件 | 音频内容 | 音高内容 |
数据集
| Name | URL |
|---|---|
| KiSing | http://shijt.site/index.php/2021/05/16/kising-the-first-open-source-mandarin-singing-voice-synthesis-corpus/ |
| PopCS | https://github.com/MoonInTheRiver/DiffSinger/blob/master/resources/apply_form.md |
| opencpop | https://wenet.org.cn/opencpop/download/ |
| Multi-Singer | https://github.com/Multi-Singer/Multi-Singer.github.io |
| M4Singer | https://github.com/M4Singer/M4Singer/blob/master/apply_form.md |
| CSD | https://zenodo.org/record/4785016#.YxqrTbaOMU4 |
| KSS | https://www.kaggle.com/datasets/bryanpark/korean-single-speaker-speech-dataset |
| JVS MuSic | https://sites.google.com/site/shinnosuketakamichi/research-topics/jvs_music |
| PJS | https://sites.google.com/site/shinnosuketakamichi/research-topics/pjs_corpus |
| JUST Song | https://sites.google.com/site/shinnosuketakamichi/publication/jsut-song |
| MUSDB18 | https://sigsep.github.io/datasets/musdb.html#musdb18-compressed-stems |
| DSD100 | https://sigsep.github.io/datasets/dsd100.html |
| Aishell-3 | http://www.aishelltech.com/aishell_3 |
| VCTK | https://datashare.ed.ac.uk/handle/10283/2651 |
代码来源和参考文献
-
https://github.com/facebookresearch/speech-resynthesis paper
-
https://github.com/jaywalnut310/vits paper
-
https://github.com/openai/whisper/ paper
-
https://github.com/NVIDIA/BigVGAN paper
-
https://github.com/mindslab-ai/univnet paper
-
https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf
-
https://github.com/brentspell/hifi-gan-bwe
-
https://github.com/mozilla/TTS
-
https://github.com/OlaWod/FreeVC paper
-
SNAC : Speaker-normalized Affine Coupling Layer in Flow-based Architecture for Zero-Shot Multi-Speaker Text-to-Speech
-
Adapter-Based Extension of Multi-Speaker Text-to-Speech Model for New Speakers
-
AdaSpeech: Adaptive Text to Speech for Custom Voice
-
Cross-Speaker Prosody Transfer on Any Text for Expressive Speech Synthesis
-
Learn to Sing by Listening: Building Controllable Virtual Singer by Unsupervised Learning from Voice Recordings
-
Adversarial Speaker Disentanglement Using Unannotated External Data for Self-supervised Representation Based Voice Conversion
-
Speaker normalization (GRL) for self-supervised speech emotion recognition
基于数据扰动防止音色泄露的方法
-
https://github.com/auspicious3000/contentvec/blob/main/contentvec/data/audio/audio_utils_1.py
-
https://github.com/revsic/torch-nansy/blob/main/utils/augment/praat.py
-
https://github.com/revsic/torch-nansy/blob/main/utils/augment/peq.py
-
https://github.com/biggytruck/SpeechSplit2/blob/main/utils.py
-
https://github.com/OlaWod/FreeVC/blob/main/preprocess_sr.py



![读书笔记-《ON JAVA 中文版》-摘要16[第十六章 代码校验]](https://img-blog.csdnimg.cn/da00d831b73f47d69d3b218871838183.png)