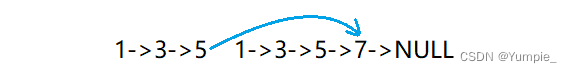文章目录
- 需求
- 解决思路
- 基本设计
- 查询流程
- 插入流程
- 修改流程
- 删除流程
- 优化思路
- 总结
需求
ok,这个需求是我提的,然后我问了我的一位杭州的朋友,然后我们最后一起敲定这个方法。
我的项目有一个根据关键字进行商品名称的搜索功能,用户输入部分关键字之后,那么就需要查询出这个关键字对应的所有商品。假设我现在有1000w行记录,并且不能使用ES做倒排索引解决这个问题。
那么你会如何解决这个问题?
我们先分析,如果我们使用数据库提供的 % 这种模糊匹配机制,首先我们的索引会失效,并且这基本意味着会走全表扫描,对于1000w行的记录如果我们走全表扫描,那么效率可想而知。
并且如果使用分库分表技术,那么维护的难度也大了,不论是业务代码还是数据库都得跟着修改,非常麻烦,那么如何解决这个问题?
解决思路
基本设计
大概流程如下:
我们可以自己实现一个倒排索引的算法,用户创建商品之后,将商品名称进行细粒度的分词,比如输入 “Java技术指导”,那么分词为“Java”,“技术”,“指导”。粒度越细越好。
可以看到此时我们得到的是一个数组,对吧。
然后我们创建两张表,一张表是商品表,存储商品的完整信息。
另一张表是倒排索引表,里面是什么内容?
包括id,word,goods_ids
这里的word就是我们的分词数据,goods_ids也就是我们这个关键字下面对应的所有商品id。
上面我们对一个字符串进行分词后得到的,其实是一个数组对吧,那么我们此时就可以向数据库中插入这三行的数据了,大概格式如下。
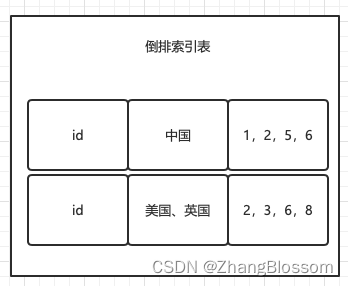
然后我们得到goods_ids是一个集合,我们在使用这个集合去商品表中查询出所有在这个集合中的记录即可。
查询流程
那么我现在大概简述一下一个数据的查询流程:
我们查询一个商品,通过关键字的方式,经过倒排索引的算法得到word值,去数据库中查询是否有这个word值,如果有,那么直接查询出来这个关键字对应的goods_ids这一段字符串,我们对字符串进行处理得到字符串包含的所有id,然后用这些id去商品表查询数据即可。
ok,那么如果有插入和修改,删除等操作怎么办呢?
插入流程
先说插入流程,一样的,当我们要插入一个数据的时候,我们先得到这个商品对应的word,也就是我们取出商品的name商品名称字段,然后对这个name字段进行分词算法,得到细粒度的分词。之后,我们我们将这个记录插入到商品表中,得到插入的id之后,返回id成功后,我们在将分词得到的数组,配合上我们得到的商品id,循环的去插入到这个分词表中,如果分词表中出现了重复的word,那么我们做的是取出goods_ids这个字段,然后再字段尾巴上补上这个id,而如果不存在这个字段,则新建一行记录,word为当前分词,goods_ids直接为刚才返回的id。
修改流程
修改流程其实已经和上面的流程差不多了,依旧是经过分词,然后去精确判断分词对应的行,然后修改对应的ids字段即可。
删除流程
删除流程也差不多,只不过我们如何删除对应的goods_ids中的哪一个id呢?
我们首先取出goods_ids这个字段值,然后通过 “ ,”分隔符得到每一个id,然后我们删除指定的id即可,当然,为了加快速度,我们的商品表中的id是自增的,所以这样子就能尽可能快的删除指定数据了。
优化思路
其实,顺着上面的思路,我忽然想到。其实我们的数据库其实作用就是为了保存一个分词,然后分词后面对应的是一堆的id,这些id是字符串,也就是我们取出来之后还得先经过处理才能得到真正可用的id。
我想的是,上面的结构其实很简单,就是一个 word—goods_ids的结构,这种结构用Redis肯定可以呀对吧。
但是如果你直接K-V结构或者hash,那么结构其实相当于就是把磁盘空间变成了内存空间,我觉得也没有多好。当然,处理起来可能比刚才那个转字符串完毕之后,然后再查询来的快。
然后我就我想到了我常用的Bitmap结构,0101啊,对吧,我只需要把如果说存在这个id,那么我把对应的位置置1即可,这样子增删改的速度全都加快了不是嘛。
当然,有一个缺点就是,查询Redis是有网络开销的。
但是我觉得如果使用Redis的bitmap,那么由于增删改查的速度都更快了,并且也不需要字符串的处理了,可能效果更优。
总结
这个方法只是我的思路,但是我马上就会动手去实现,敬请期待!!