参考:
- 由浅入深聊聊Golang的sync.Map 通过对源码的逐行分析,清晰易懂
- Golang sync.Map原理 通过向 sync.Map 中增删改查来介绍sync.Map的底层原理
- Golang中sync.Map的实现原理是什么 很好的概括了sync.Map的原理
- 手摸手Go 深入理解sync.Map 知乎大佬
大家都知道go中的原生map是非线程安全的,多个协程并发读写map常常会出现这样的问题 fatal error: concurrent map writes,所以一般为了使map能够做到线程安全,都会采取以下两种方式实现:
- map + mutex (读多写少的场景下,锁的粒度太大存在效率问题:影响其他的元素操作)
- sync.Map(减少加锁时间:读写分离,降低锁粒度,空间换时间,降低影响范围)
那么问题来了,sync.Map是如何做到线程安全的呢?一起来了解下~
sync.Map原理解析:
原理
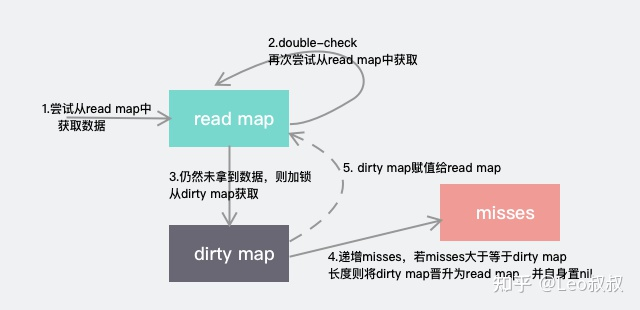
sync.Map底层使用了两个原生map,一个叫read,仅用于读;一个叫dirty,用于在特定情况下存储最新写入的key-value数据:
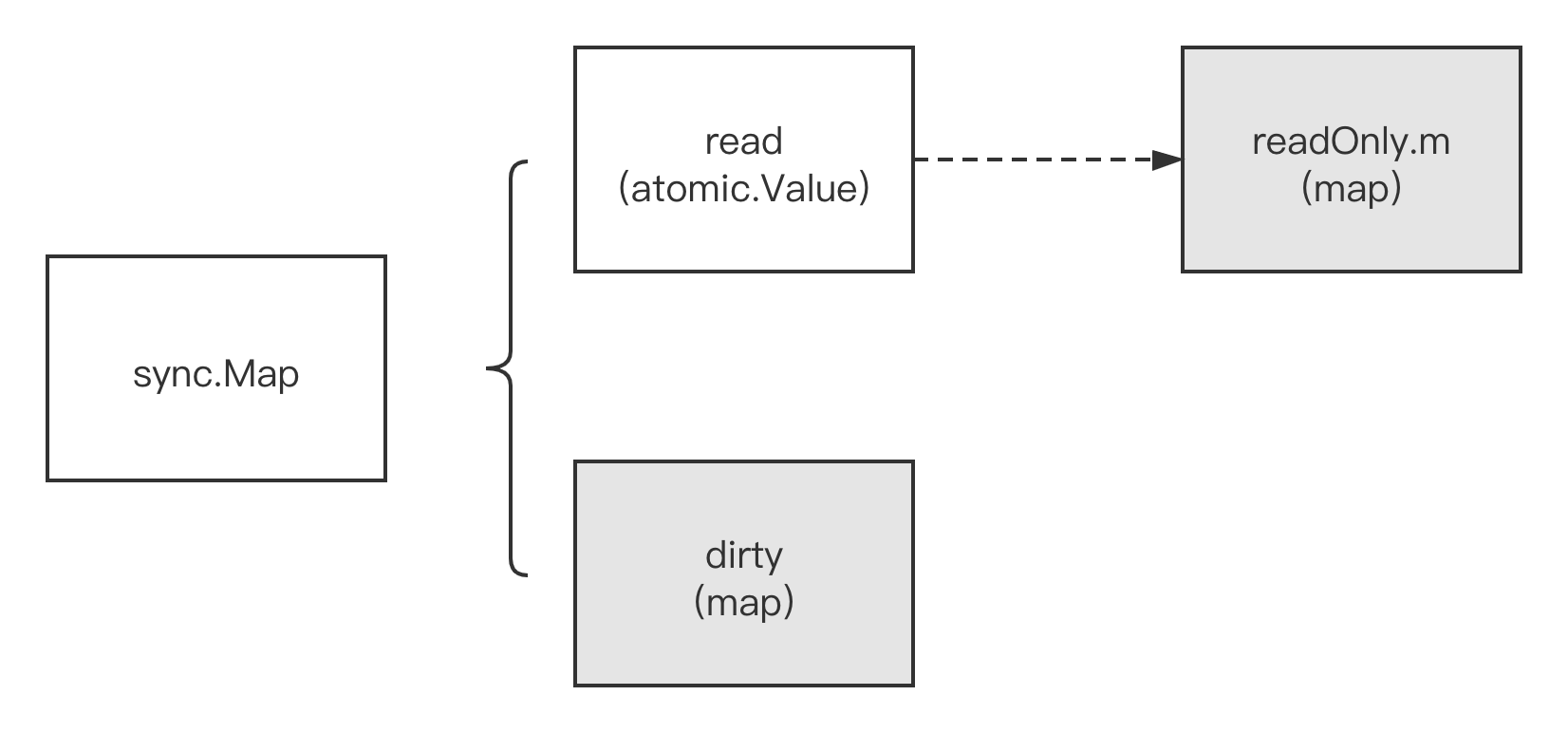
read好比整个sync.Map的一个“高速缓存”,当goroutine从sync.Map中读数据时,sync.Map会首先查看read这个缓存层是否有用户需要的数据(key是否命中),如果有(key命中),则通过原子操作将数据读取并返回,这是sync.Map推荐的快路径(fast path),也是sync.Map的读性能极高的原因。
- 写操作:直接写入dirty(负责写的map)
- 读操作:先读read(负责读操作的map),没有再读dirty(负责写操作的map)
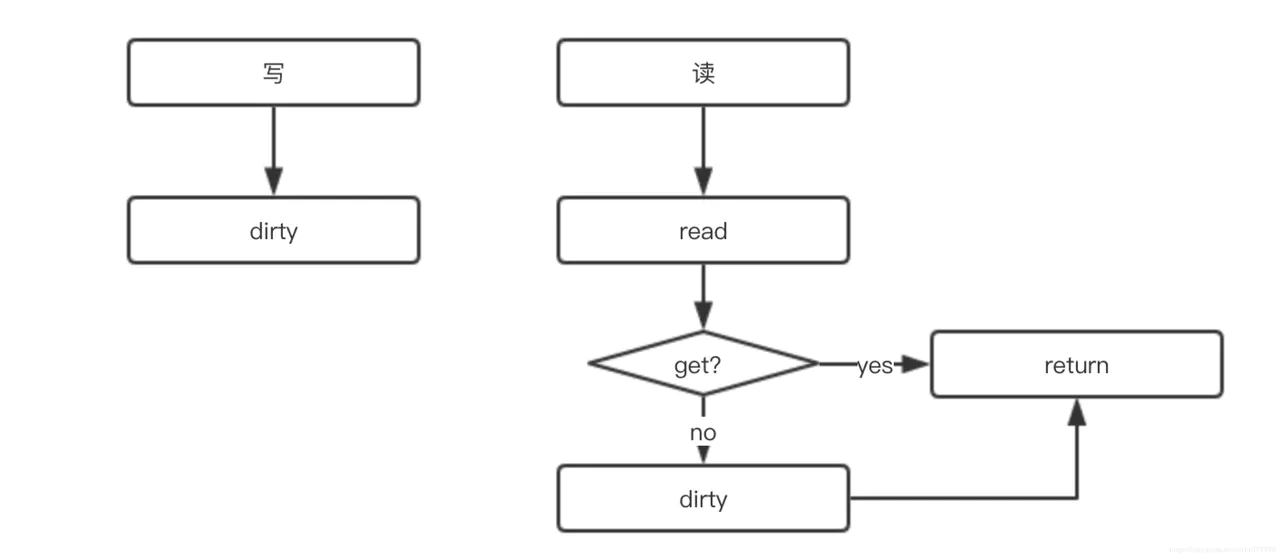
sync.Map 的实现原理可概括为:
- 通过 read 和 dirty 两个字段实现数据的读写分离,读的数据存在只读字段 read 上,将最新写入的数据则存在 dirty 字段上
- 读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirty
- 读取 read 并不需要加锁,而读或写 dirty 则需要加锁
- 另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据更新到 read 中(触发条件:misses=len(dirty))
优缺点
- 优点:Go官方所出;通过读写分离,降低锁时间来提高效率;
- 缺点:不适用于大量写的场景,这样会导致 read map 读不到数据而进一步加锁读取,同时dirty map也会一直晋升为read map,整体性能较差,甚至没有单纯的 map+metux 高。
- 适用场景:读多写少的场景。
可见,通过这种读写分离的设计,解决了并发场景下的写入安全,又使读取速度在大部分情况可以接近内建 map,非常适合读多写少的情况。
以上就是sync.Map的基本实现原理了,如果想要从源码角度去了解更多的底层实现细节,就继续往下学习~
sync.Map的 核心数据结构 及 源码解析
// sync.Map的核心数据结构
type Map struct {
mu Mutex // 对 dirty 加锁保护,线程安全
read atomic.Value // readOnly 只读的 map,充当缓存层
dirty map[interface{}]*entry // 负责写操作的 map,当misses = len(dirty)时,将其赋值给read
misses int // 未命中 read 时的累加计数,每次+1
}
// 上面read字段的数据结构
type readOnly struct {
m map[interface{}]*entry //
amended bool // Map.dirty的数据和这里read中 m 的数据不一样时,为true
}
// 上面m字段中的entry类型
type entry struct {
// 可见value是个指针类型,虽然read和dirty存在冗余情况(amended=false),但是由于是指针类型,存储的空间应该不是问题
p unsafe.Pointer // *interface{}
}
在 sync.Map 中常用的有以下方法:
- Load():读取指定 key 返回 value
- Delete(): 删除指定 key
- Store(): 存储(新增或修改)key-value
下面分别从这三种方法出发来理清底层代码逻辑:
Load()查询操作:
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 因read只读,线程安全,优先读取
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果read没有,并且dirty有新数据,那么去dirty中查找(read.amended=true:dirty和read数据不一致)
if !ok && read.amended {
m.mu.Lock()
// 双重检查(原因是前文的if判断和加锁非原子的,害怕这中间发生故事)
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 如果read中还是不存在,并且dirty中有新数据
if !ok && read.amended {
e, ok = m.dirty[key]
// m计数+1
m.missLocked()
}
m.mu.Unlock()
}
// !ok && read.amended=false:dirty和read数据是一致的,read 和 dirty 中都不存在,返回nil
if !ok {
return nil, false
}
// ok && read.amended=true:dirty和read数据不一致,dirty存在但read不存在该key,直接返回dirty中数据~
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// 将dirty置给read,因为穿透概率太大了(原子操作,耗时很小)
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
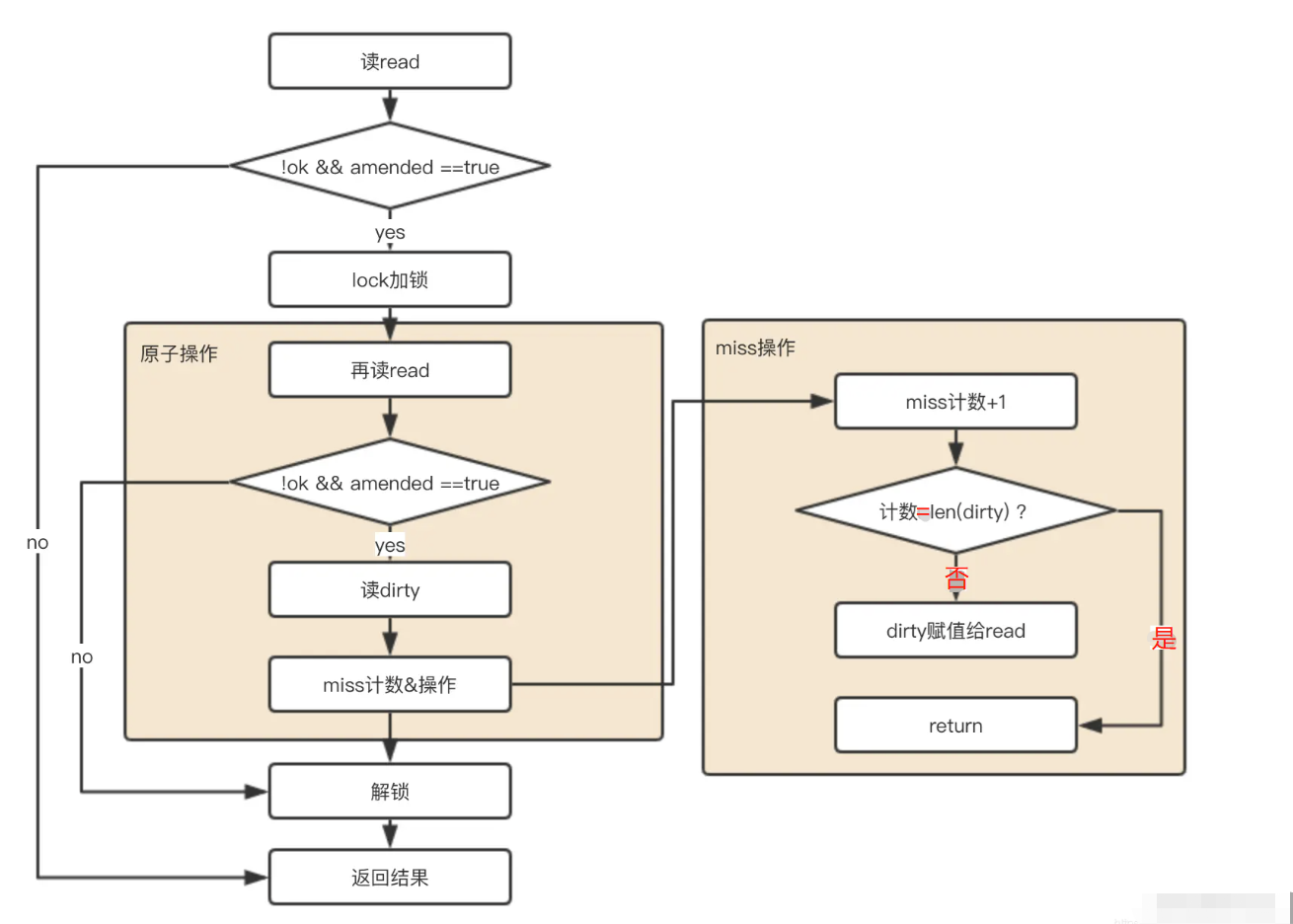
当Load方法在read map中没有命中(miss)目标key时,该方法会再次尝试在dirty中继续匹配key;无论dirty中是否匹配到,Load方法都会在锁保护下调用missLocked方法增加misses的计数(+1);当计数器misses值到达len(dirty)阈值时,则将dirty中的元素整体更新到read,且dirty自身变为nil。
注意点:
- 阈值:misses == len(dirty)
- 写操作仅针对dirty(负责写操作的map),所以dirty是包含read的,最新且全量的数据。
Delete()删除操作:
func (m *Map) Delete(key interface{}) {
// 读出read,断言为readOnly类型
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果read中没有,并且dirty中有新元素,那么就去dirty中去找。这里用到了amended,当read与dirty不同时为true,说明dirty中有read没有的数据。
if !ok && read.amended {
m.mu.Lock()
// 再检查一次,因为前文的判断和锁不是原子操作,防止期间发生了变化。
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
// 直接删除
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
// 如果read中存在该key,则将该value 赋值nil(采用标记的方式删除!)
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
// 再次加载数据的指针,如果指针为空或已被标记删除,那么返回false,删除失败
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return false
}
// 原子操作
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}
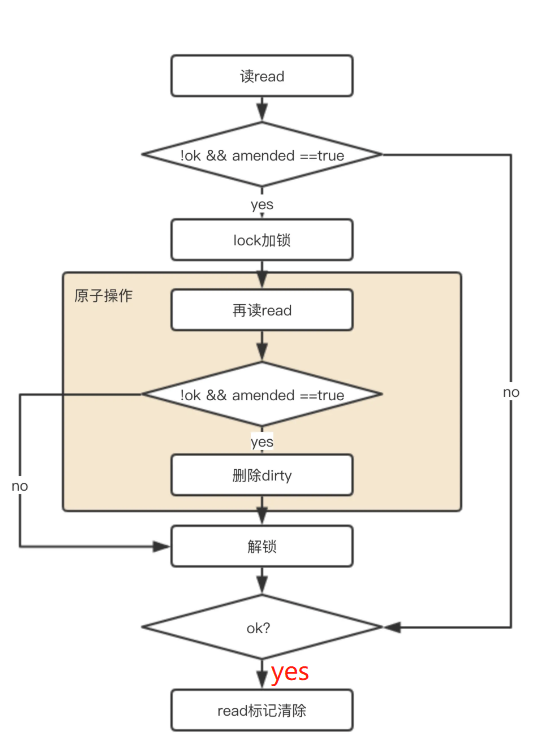
注意点:
delete(m.dirty, key)这里采用直接删除dirty中的元素,而不是先查再删:
这样的删除成本低。读一次需要寻找,删除也需要寻找,无需重复操作。- 通过延迟删除对read中的值域先进行标记:
将read中目标key对应的value值置为nil(e.delete()→将read=map[interface{}]*entry中的值域*entry置为nil)
Store(): 新增/修改 操作
func (m *Map) Store(key, value interface{}) {
// 如果m.read存在这个key,并且没有被标记删除,则尝试更新。
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 如果read不存在或者已经被标记删除
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok { // read 存在该key
// 如果read值域中entry已删除且被标记为expunge,则表明dirty没有key,可添加入dirty,并更新entry
if e.unexpungeLocked() {
// 加入dirty中,这里是指针
m.dirty[key] = e
}
// 更新value值
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok { // dirty 存在该 key,更新
e.storeLocked(&value)
} else { // read 和 dirty都没有
// 如果read与dirty相同,则触发一次dirty刷新(因为当read重置的时候,dirty已置为 nil了)
if !read.amended {
// 将read中未删除的数据加入到dirty中
m.dirtyLocked()
// amended标记为read与dirty不相同,因为后面即将加入新数据。
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
// 将read中未删除的数据加入到 dirty中
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
// 遍历read。
for k, e := range read.m {
// 通过此次操作,dirty中的元素都是未被删除的,可见标记为expunged的元素不在dirty中!!!
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
// 判断entry是否被标记删除,并且将标记为nil的entry更新标记为expunge
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 将已经删除标记为nil的数据标记为expunged
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
// 对entry尝试更新 (原子cas操作)
func (e *entry) tryStore(i *interface{}) bool {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
for {
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
p = atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
}
}
// read里 将标记为expunge的更新为nil
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
// 更新entry
func (e *entry) storeLocked(i *interface{}) {
atomic.StorePointer(&e.p, unsafe.Pointer(i))
}
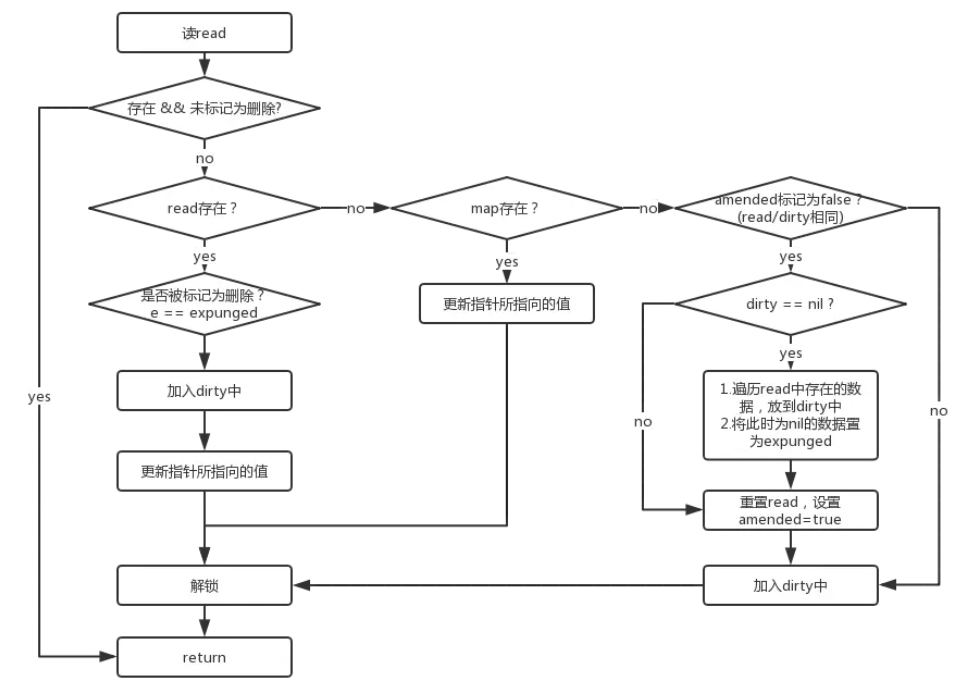
注意点:
m.dirtyLocked()通过迭代的方式,将read中未删除的数据加入到 dirty 中:
是一个整体的指针交换操作。
当之前执行Load()方法且满足条件misses=len(dirty)时,会将dirty数据整体迁移到read中。sync.Map直接将原dirty指针store给read并将dirty自身也置为nil。
因此sync.Map若想要保证在 amended=true(read和dirty中数据不一致),并且下一次发生数据迁移时(dirty → read)不会丢失数据,dirty中就必须拥有整个Map的全量数据才行。所以这里m.dirtyLocked()又会【将read中未删除的数据加入到 dirty中】。
不过dirtyLocked()是通过一个迭代实现的元素从read到dirty的复制,如果Map中元素数量很大,这个过程付出的损耗将很大,并且这个过程是在锁保护下的。这里迭代遍历复制的方式可能会存在性能问题。- 惰性删除:
和仅在read中的情况不同(仅将value设置为nil),仅存在于dirty中的key被删除后,该key就不再存在了。这里还有一点值得注意的是:当向dirty写入一个新的key时,dirty会复制read中未被删除的元素,已经被删除key对应的value会先标记为哨兵*(expunged:算是一个标记,表示dirty map中对应的值已经被干掉了)并延迟删除,并且该key不会被加入到dirty中。直到下一次promote全量更新read时,该key才会被回收(因为read被交换指向新的dirty,原read指向的内存将被GC)。
总结:
通过阅读源码我们发现sync.Map是通过冗余的两个数据结构(read、dirty),实现性能的提升。为了提升性能,load、delete、store等操作尽量使用只读的read;为了提高read的key击中概率,采用动态调整,将dirty数据提升为read;对于数据的删除,采用延迟标记删除法,只有在提升dirty的时候才删除。
![[附源码]JAVA毕业设计农产品的物流信息服务平台(系统+LW)](https://img-blog.csdnimg.cn/e55ce54cd8554e9d92ccdb59127adb37.png)

![[附源码]计算机毕业设计社区生活废品回收APPSpringboot程序](https://img-blog.csdnimg.cn/9d32129672704204aa07472b1e1baa94.png)