文章目录
- 1. 概要
- 2. 区域卷积卷积神经网络R-CNN
- 2.1 模型结构
- 2.2 Selective Search
- 2.3 warp
- 2.4 R-CNN训练
- 2.5 R-CNN推理
- 2.6 R-CNN性能评价
- 2.7 R-CNN的缺点
- 3. SPP-Net
- 3.1 SPP-Net对RCNN的改进
- 3.2 SPP-Net网络结构
- 3.3 SPP-Net训练过程
- 3.4 SPP-Net的问题
- 4. Fast R-CNN
- 4.1 Fast R-CNN改进点
- 4.2 Fast R-CNN网络结构
- 4.3 训练
- 5. Faster R-CNN
- 5.1 Region Proposal Network(RPN)
- 5.2 Faster R-CNN训练过程
- 6. 总结
- 参考
1. 概要
目标检测的任务是检测图片中所有物体的类别标签 和 位置(最小外接矩阵/Bounding Box),如下图所示

目标检测与其他任务的区别如下图所示

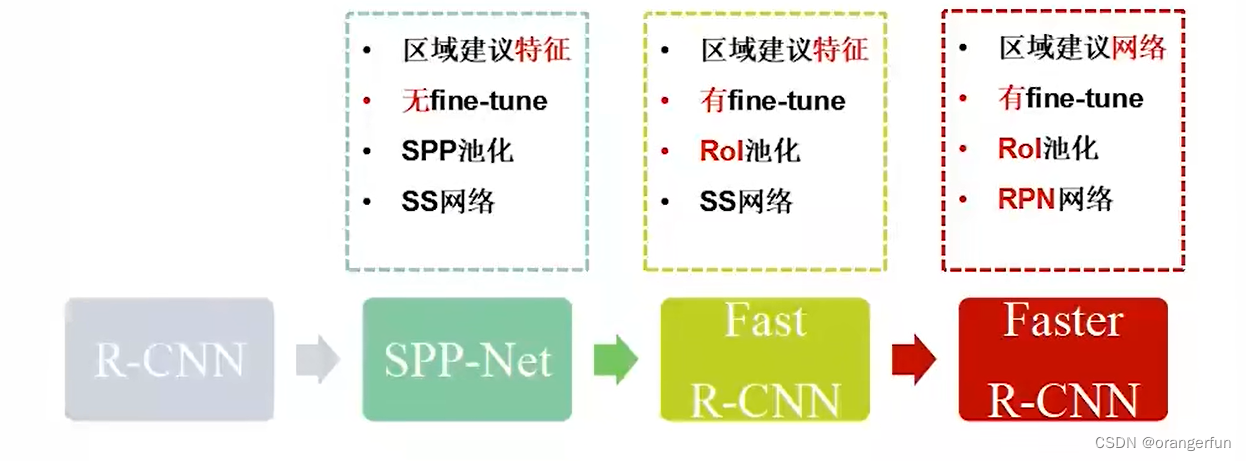
目标检测模型进化过程如下

2. 区域卷积卷积神经网络R-CNN
论文来源:CVPR-2014
论文链接:Rich feature hierarchies for accurate object detection and semantic segmentation
代码链接:RCNN-PyTorch实现
2.1 模型结构
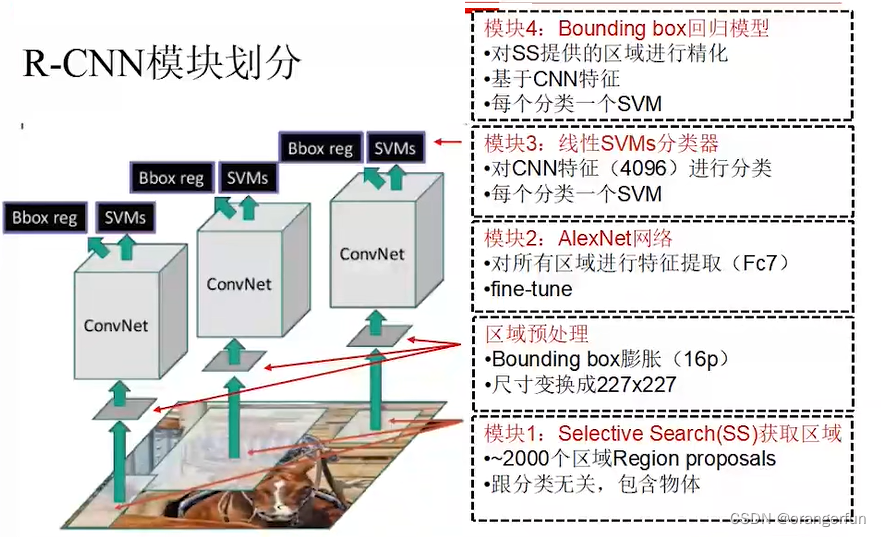
总体按分类问题对待,分为两个模块
(1)模块1:提取物体区域(Region Proposal)
不同位置、不同尺寸,数量很多
(2)模块2:对区域进行分类识别(Classification)
CNN 分类器,计算量大
传统方法与R-CNN比较如下
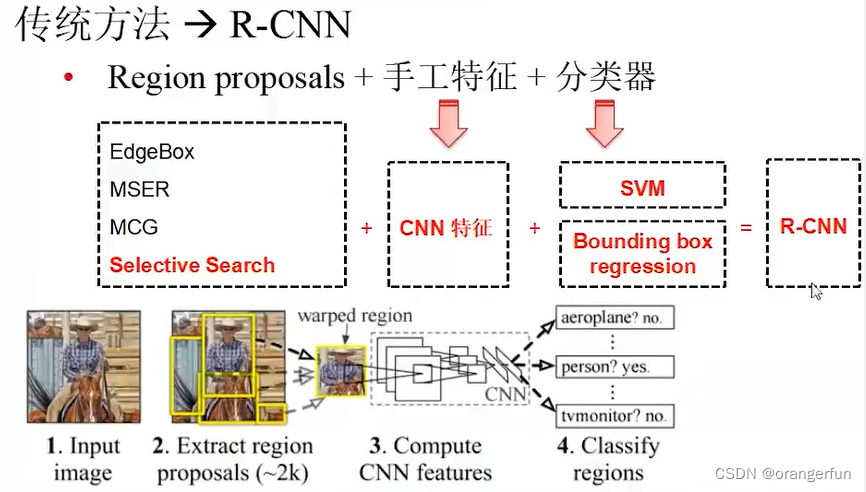
R-CNN总体流程如上图所示:
- 输入图片
- 通过Selective Search(SS) 方法抽取候选区域(数量很多,大概有2k个左右)
- 对候选区域进行warped,使得所有候选区域都变成相同大小
- 将warped候选区域送入CNN网络提取特征,并进行分类
2.2 Selective Search
使用Felzenszwalb and Huttenlocher[1]的方法产生图像初始区域,使用贪心算法对区域进行迭代分组,具体步骤如下
- 按照Felzenszwalb and Huttenlocher的方法产区域集R
- 计算区域集R里每个相邻区域的相似度 S = { s 1 , s 2 , . . . } S=\{s_1, s_2, ...\} S={s1,s2,...}
- 找出S中相似度最高的两个区域,将其合并为新集,并添加到R
- 从S 中移除所有与step3中有关的子集
- 计算新集与所有子集的相似度
- 跳转至step3,直至S为空
在合并时优先合并四种区域
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后总面积在其BBOX中所占比例大的
2.3 warp
warp的方式主要包括如下几种
- 在原始区域目标周围取一块区域进行等比缩放到CNN 需要的图片大小
- 去除原始目标区域然后对目标区域进行填充,再等比缩放到CNN所需的图片大小
- 直接将原始目标区域非等比缩放到CNN需要的图片大小
2.4 R-CNN训练
(1)CNN 模型微调
- 先在ImageNet上对CNN模型进行pre-train
- 在SS生成的所有区域上对模型进行fine tunne
- Log Loss
- softmax层改成(N+1) way
- 正样本有N类:跟ground truth重合IoU>0.5
- 负样本1类:IoU < 0.5
注意:
I
o
U
=
A
∩
B
A
∪
B
IoU = \frac{A \cap B}{A \cup B}
IoU=A∪BA∩B,即表示两个区域的重合度,如果IoU=1,表示两块区域完全重合
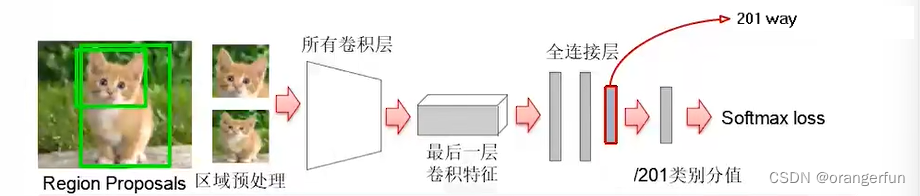
(2)训练分类部分
使用微调的CNN模型抽取候选区域特征,然后训练线性SVM分类器
- 每个物体类别对应一个SVM分类器(即SVM是一对多的分类器)
- 正样本:所有Groundtruth 区域
- 负样本:更ground truth区域重合IoU < 0.3 的SS区域,如下图所示负样本包括不包括目标物体的区域,或者包括其他物体的区域
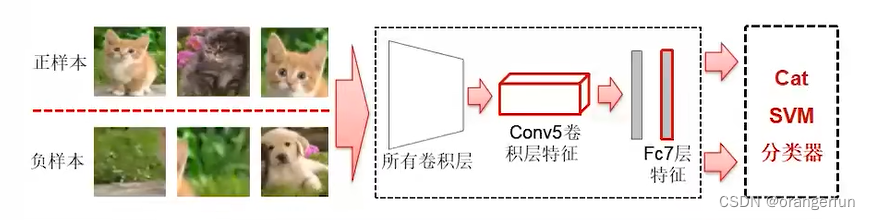
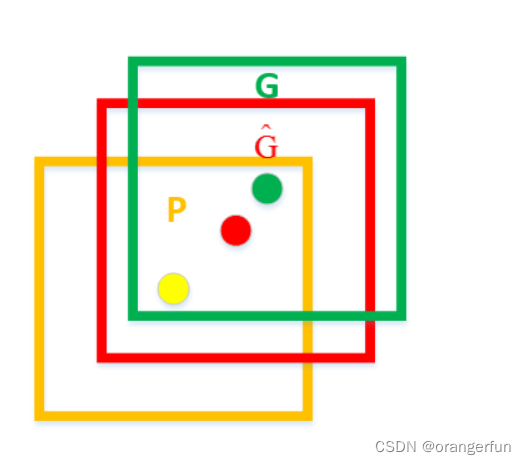
(3)回归部分
回归器主要用于对selective search生成的候选框进行修正。如下图所示,黄色框口P表示建议框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口
G
^
\hat G
G^ 表示Region Proposal进行回归修正后的预测窗口,现在的目标是找到P到
G
^
\hat G
G^的映射,使得
G
^
\hat G
G^与G越相近,这就相当于一个简单的最小二乘法解决的线性回归问题。
具体损失函数的定义如下:
定义
P
P
P 窗口的数学表达式:
P
i
=
(
P
x
i
,
P
y
i
,
P
w
i
,
P
h
i
)
P^i=(P_x^i,P_y^i,P_w^i,P_h^i)
Pi=(Pxi,Pyi,Pwi,Phi),其中
(
P
x
i
,
P
y
i
)
(P_x^i,P_y^i)
(Pxi,Pyi)表示第一个
i
i
i窗口的中心点坐标,
P
w
i
P_w^i
Pwi,
P
h
i
P_h^i
Phi 分别为第
i
i
i个窗口的宽和高;
G G G 窗口的数学表达式为: G i = ( G x i , G y i , G w i , G h i ) G^i=(G^i_x,G^i_y,G^i_w,G^i_h) Gi=(Gxi,Gyi,Gwi,Ghi);
G ^ \hat G G^ 窗口的数学表达式为: G ^ i = ( G ^ x i , G ^ y i , G ^ w i , G ^ h i ) \hat G^i=(\hat G^i_x,\hat G^i_y,\hat G^i_w,\hat G^i_h) G^i=(G^xi,G^yi,G^wi,G^hi)
则损失函数为:
Loss
=
argmin
∑
i
=
0
N
(
t
∗
i
−
w
^
∗
T
ϕ
5
(
P
i
)
)
2
+
λ
∥
w
^
∗
∥
2
\operatorname{Loss}=\operatorname{argmin} \sum_{\mathrm{i}=0}^{\mathrm{N}}\left(\mathrm{t}_*^{\mathrm{i}}-\hat{\mathrm{w}}_*^{\mathrm{T}} \phi_5\left(\mathrm{P}^{\mathrm{i}}\right)\right)^2+\lambda\left\|\hat{\mathrm{w}}_*\right\|^2
Loss=argmini=0∑N(t∗i−w^∗Tϕ5(Pi))2+λ∥w^∗∥2
其中
ϕ
5
(
P
i
)
\phi_5(P^i)
ϕ5(Pi) 表示目标
P
i
P^i
Pi 在CNN网络Pool5层特征(注意:上一章节中训练分类器使用的是全连接层输出结果),
N
N
N 表示一共有N个bounding box(SS选出的BBOX中与Ground Truth的IoU>0.6的部分);
t
∗
t_*
t∗ 分别表示表示
(
t
x
,
t
y
,
t
h
,
t
w
)
(t_x, t_y, t_h, t_w)
(tx,ty,th,tw):
t
x
=
(
G
x
−
P
x
)
/
P
w
t
y
=
(
G
y
−
P
y
)
/
P
h
t
w
=
log
(
G
w
/
P
w
)
t
h
=
log
(
G
h
/
P
h
)
\begin{gathered} \mathrm{t}_{\mathrm{x}}=\left(\mathrm{G}_{\mathrm{x}}-\mathrm{P}_{\mathrm{x}}\right) / \mathrm{P}_{\mathrm{w}} \\ \mathrm{t}_{\mathrm{y}}=\left(\mathrm{G}_{\mathrm{y}}-\mathrm{P}_{\mathrm{y}}\right) / \mathrm{P}_{\mathrm{h}} \\ \mathrm{t}_{\mathrm{w}}=\log \left(\mathrm{G}_{\mathrm{w}} / \mathrm{P}_{\mathrm{w}}\right) \\ \mathrm{t}_{\mathrm{h}}=\log \left(\mathrm{G}_{\mathrm{h}} / \mathrm{P}_{\mathrm{h}}\right) \end{gathered}
tx=(Gx−Px)/Pwty=(Gy−Py)/Phtw=log(Gw/Pw)th=log(Gh/Ph)
因此该损失函数的意思为:拟合SS预测的BBOX和人工标注的BBOX的误差,训练完通过误差修正SS预测的BBOX,预测阶段如下所示,其中
d
∗
(
P
)
=
w
∗
T
ϕ
5
(
P
)
\mathrm{d}_*(\mathrm{P})=\mathrm{w}_*^{\mathrm{T}} \phi_5(\mathrm{P})
d∗(P)=w∗Tϕ5(P),
w
∗
T
\text{w}_*^T
w∗T为训练阶段的参数
G
^
x
=
P
w
d
x
(
P
)
+
P
x
G
^
y
=
P
h
d
y
(
P
)
+
P
y
G
^
w
=
P
w
exp
(
d
w
(
P
)
)
G
^
h
=
P
h
exp
(
d
h
(
P
)
)
\begin{gathered} \hat{\mathrm{G}}_{\mathrm{x}}=\mathrm{P}_{\mathrm{w}} \mathrm{d}_{\mathrm{x}}(\mathrm{P})+\mathrm{P}_{\mathrm{x}} \\ \hat{\mathrm{G}}_{\mathrm{y}}=\mathrm{P}_{\mathrm{h}} \mathrm{d}_{\mathrm{y}}(\mathrm{P})+\mathrm{P}_{\mathrm{y}} \\ \hat{\mathrm{G}}_{\mathrm{w}}=\mathrm{P}_{\mathrm{w}} \exp \left(\mathrm{d}_{\mathrm{w}}(\mathrm{P})\right) \\ \hat{\mathrm{G}}_{\mathrm{h}}=\mathrm{P}_{\mathrm{h}} \exp \left(\mathrm{d}_{\mathrm{h}}(\mathrm{P})\right) \end{gathered}
G^x=Pwdx(P)+PxG^y=Phdy(P)+PyG^w=Pwexp(dw(P))G^h=Phexp(dh(P))
以下省去
i
i
i 上标。
d
x
d_x
dx和
d
y
d_y
dy 通过平移对
x
x
x 和
y
y
y 进行变化 ,
d
w
d_w
dw和
d
h
d_h
dh通过缩放对
w
w
w和
h
h
h进行变化
2.5 R-CNN推理
- (1)使用Selective Search提取大约2000个BBOX/区域
- (2)将所有区域放大/缩小到 227*227
- (3)使用fine tunne过的AlexNet计算两套特征。对于每个类别:
- (a)FC7特征 -> SVM分类器 -> 分类分值
- (b)使用非极大值抑制NMS(IoU>=0.5)获取无冗余的区域子集
- (c)Conv5特征 -> BBOX回归模型 -> BBOX误差 -> 修正BBOX
非极大值抑制的具体做法如下
SVM分类器的输出结果为的维度为[2000, 20],即2000个框,每个框分成20类
① 对2000×20维矩阵中每列按从大到小进行排序;
② 从每列最大的得分建议框开始,分别与该列后面的得分建议框进行IoU计算,若IoU>阈值,则剔除得分较小的建议框,否则认为图像中存在多个同一类物体;
③ 从每列次大的得分建议框开始,重复步骤②;
④ 重复步骤③直到遍历完该列所有建议框;
⑤ 遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
⑥ 最后剔除各个类别中剩余建议框得分少于该类别阈值的建议框
2.6 R-CNN性能评价
(1)平均精度(AP): 针对某一类别,计算PR曲线下的面积,是precision对于recall的积分
(2)mAP:针对所有类别,计算AP的均值
2.7 R-CNN的缺点
(1)训练时间很长(84h): Fine Tune(18h) + 特征提取(63h) + SVM/BBOX训练(3h)
(2)测试阶段很慢:VGG一张图片47s(每张图片的2000个都会计算CNN特征)
(3)复杂的多阶段训练:用于SVM,BBOX回归的特征需要存储到磁盘中,这将占用大量磁盘空间,此外特征提取也很慢
3. SPP-Net
3.1 SPP-Net对RCNN的改进
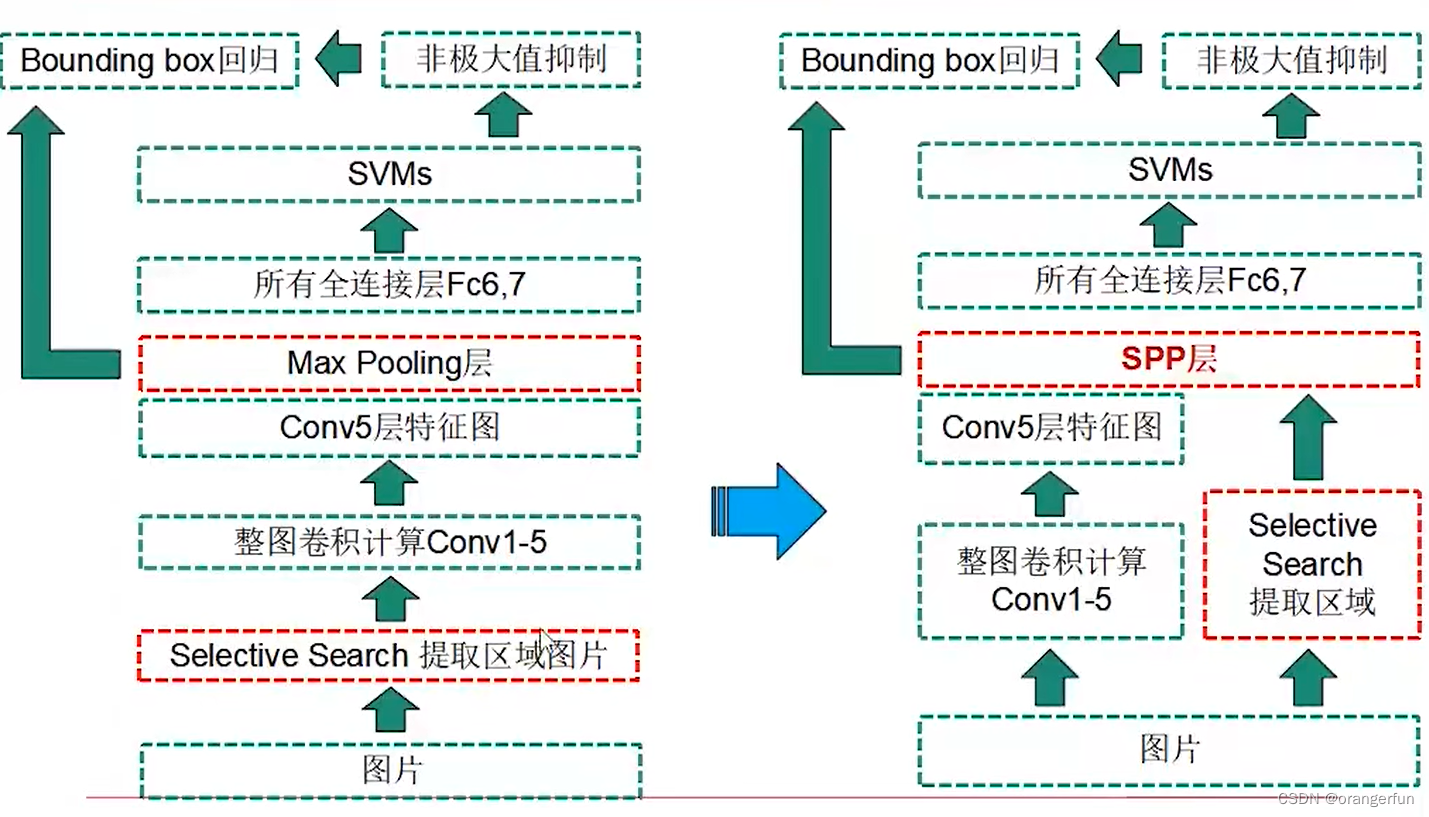
(1)直接输入整张图片,所有区域共享卷积计算(将CNN计算提前到SS之前,在Conv5输出上提取所有区域特征)
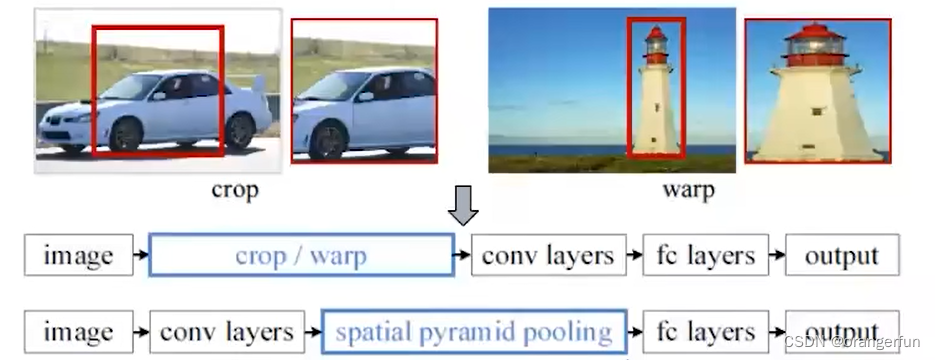
(2)引入空间金字塔结构(Spatial Pyramid Pooling),为不同尺寸的区域在Conv5输出上提取特征,将不同尺寸映射到尺寸固定的全连接层上
3.2 SPP-Net网络结构
具体结构如下图所示
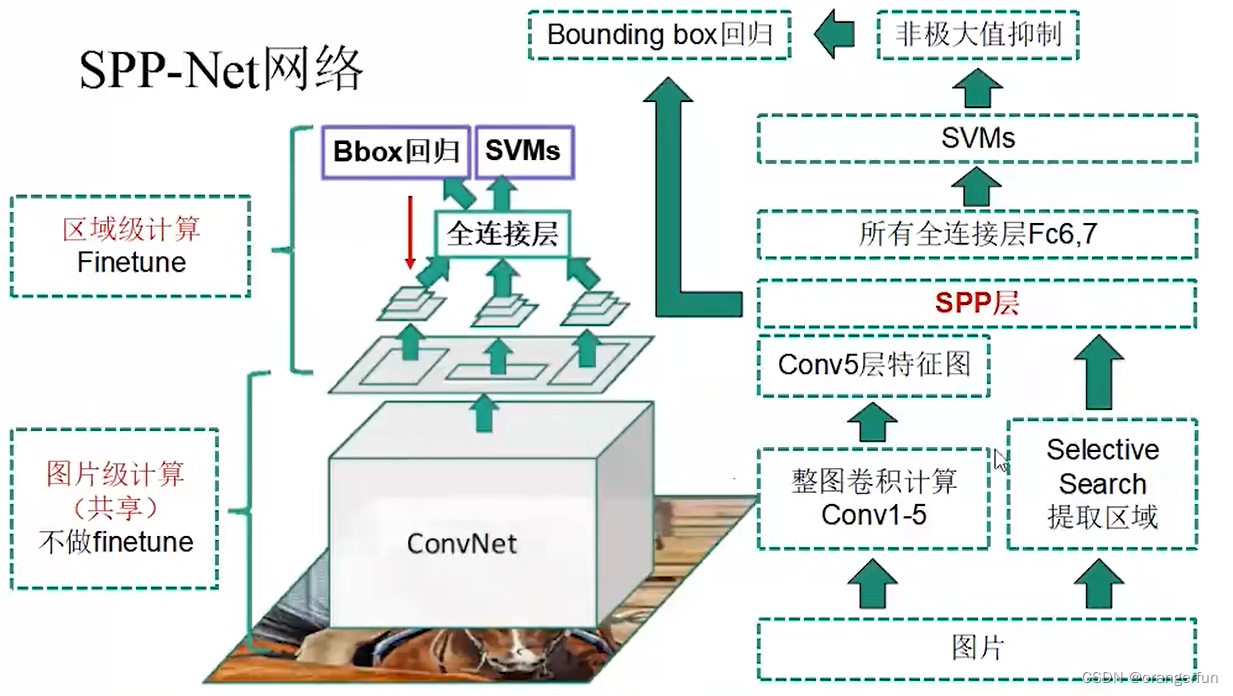
(1)直接一整张图输入CNN网络,提取整个图片的特征,然后再根据region proposal的位置在整个feature map上截取出对应的feature,这样就避免了重复性用CNN对每个region proposal单独提取特征
(2)CNN网络的conv5层后加入了SPP layer,这样就可以不需要warp/crop region proposal了,因为SPP layer可以接受不同size的输入,并可以得到相同尺寸的输出
图片特征抽取
在SPP-net中,一整张图输入CNN网络中,然后经过5个卷积层得到整个图的feature map,然后从这整个feature map上截取出每个region proposal对应的feature。
如下图所示,在feature map中得到原图中蓝色的region对应的feature。定位一个矩形框,只要知道中心点的坐标和矩形框的宽高就可以。所以我们需要根据原图中的region proposal推导出对应的feature map的中心点和宽高。这就需要我们找到卷积网络中两个卷积层之间的映射关系:包括边的映射和点的映射。具体映射关系可以查看SPP-net

SPP层
CNN时需要输入固定size的图像,这主要是受CNN中的全连接层所限制。因为卷积层计算的方式类似于滑窗,因此对于不同size的输入,卷积层都可以正确计算。但是对于连接数固定的全连接层,例如4096*1000,那么这个全连接层的输入必须是4096维,否则就会出现错误。因此在训练CNN之前都需要先把图片resize到一个固定的尺寸,如3.1章节中图所示crop是从原图中裁剪出固定大小的图片,这样的方式会使得部分图像的信息丢失。warp是直接将图片resize到规定的大小,这样会导致图片发生形变。
在RCNN中通过selective search来提取出不同size的region proposal,然后对不同的region proposal提取出不同尺寸的feature map, 那这些feature map也要经过warp之后才输入之后的FC layer或SVM分类器,那这样或多或少会影响最后的检测结果。
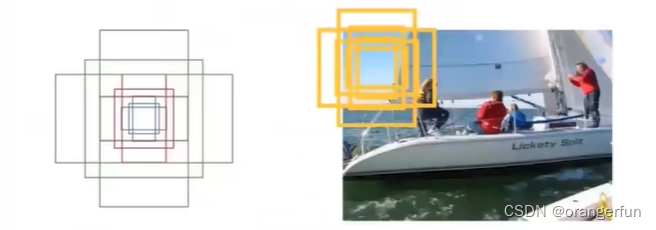
在SPP-Net中增加了空间金字塔结构,如下图
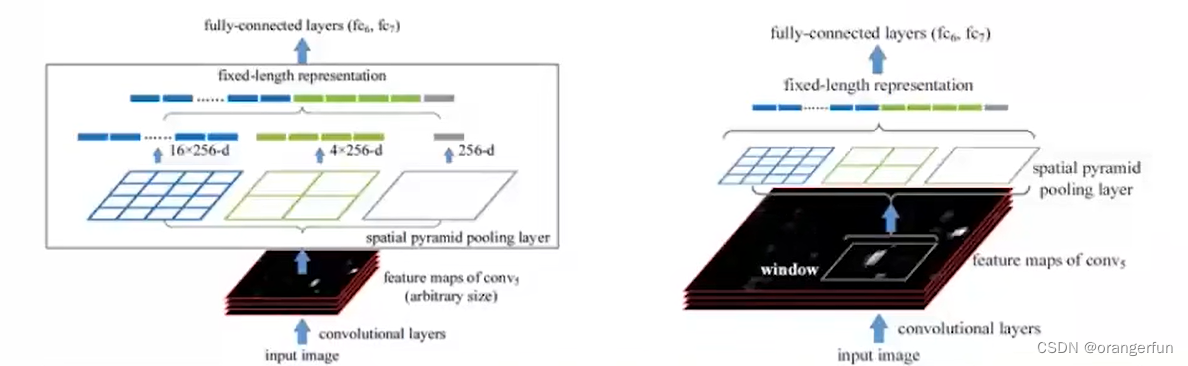
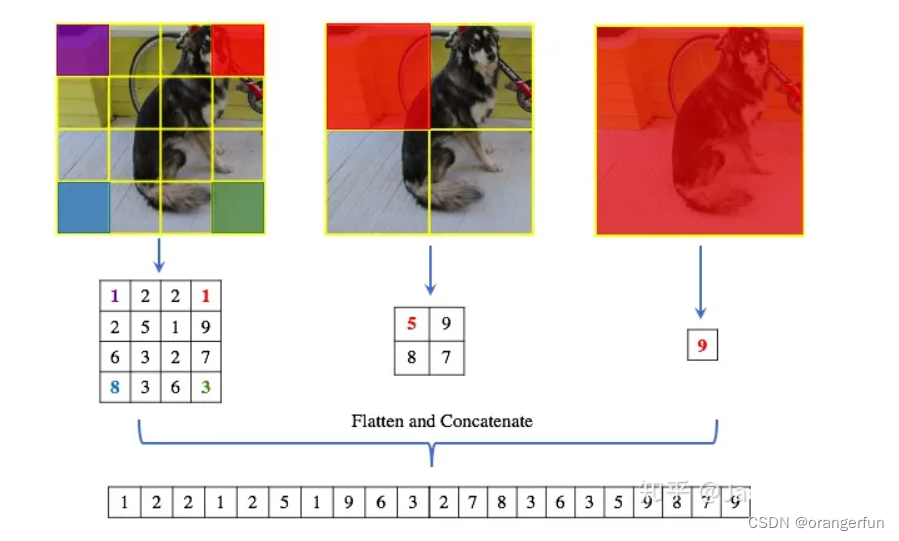
具体来说就是把输入的feature map划分成不同尺度,比如图中(4, 4) (2, 2) (1, 1)三种不同的尺度,然后会产生不同的bin,比如分成(4, 4)就16个bin,然后在每个bin中使用max pooling,然后就变成固定长度为16的向量。如下图不同尺寸的输入,经过SPP层之后都得到了相同的长度的向量,之后再输入FC layer。所以,使用SPP Layer之后,不同size的输入就可以输出相同的size
3.3 SPP-Net训练过程
(1)在ImageNet上对CNN模型进行pretrain
(2)计算所有SS的候选区域的的spp特征
(3)使用SPP特征fine tunne后面的全连接层fc6, fc7, fc8
(4)取fc7层特征训练svm分类器
(5)使用SPP特征训练BBOX回归器
与RCNN区别:
- fine tunne的时候只能fine tunne全连接层(感受野太大,fine tunne CNN困难)
3.4 SPP-Net的问题
(1)需要存储大量的特征
(2)复杂的多阶段训练
(3)训练时间仍然长(25.5h): fine tune(16h)+特征提取(5.5h)+SVM/BBOX训练(4h)
(4)SPP层之前的所有卷积层参数无法fine tune
4. Fast R-CNN
4.1 Fast R-CNN改进点
(1)比R-CNN, SPP-Net 更快的训练/测试速度
(2)更高的精度mAP
(3)实现端到端的单阶段训练(多任务损失函数)
(4)所有层参数都能fine tune
(5)不需要理想存储特征文件
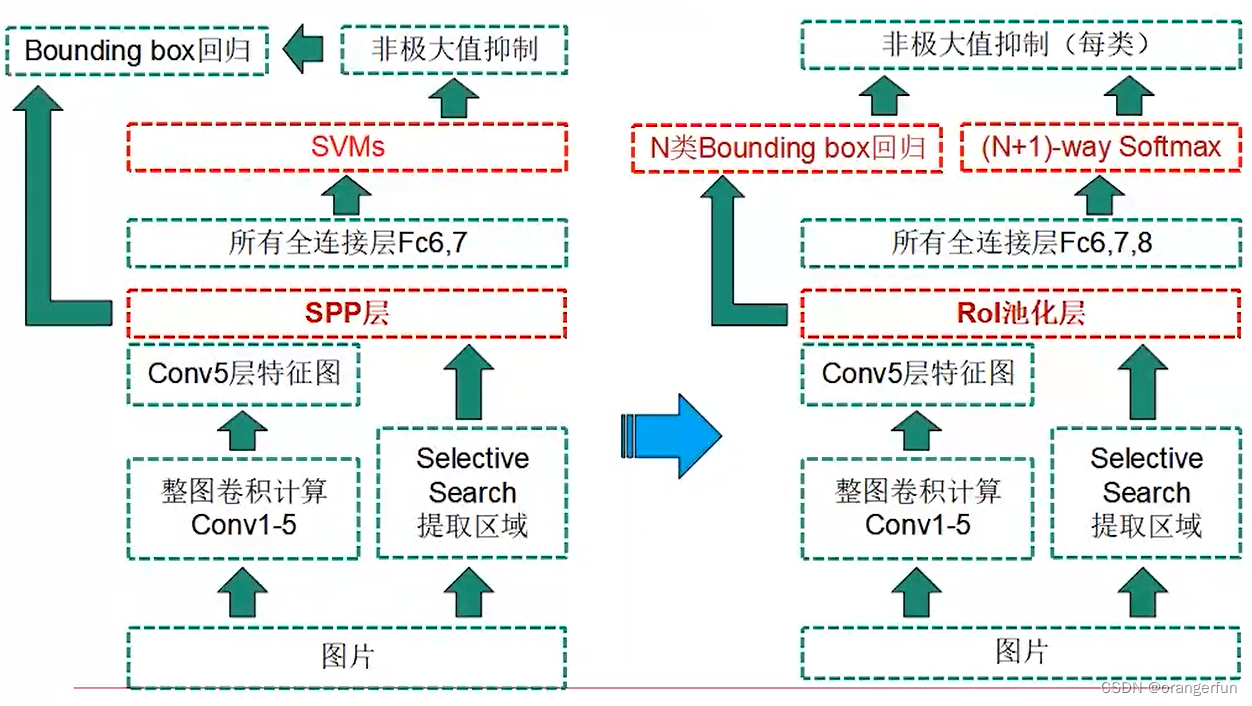
综合来说,Fast R-CNN在SPP-Net上引入2个新技术
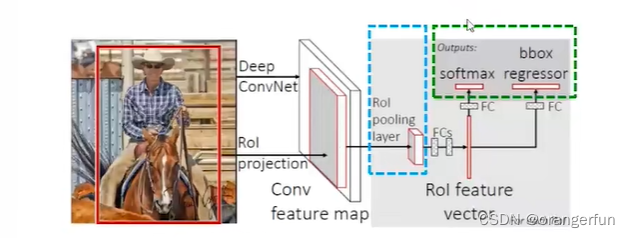
- 感兴趣区域池化层(RoI Pooling Layer)
- 多任务损失函数(Multi task Loss)
如下图所示
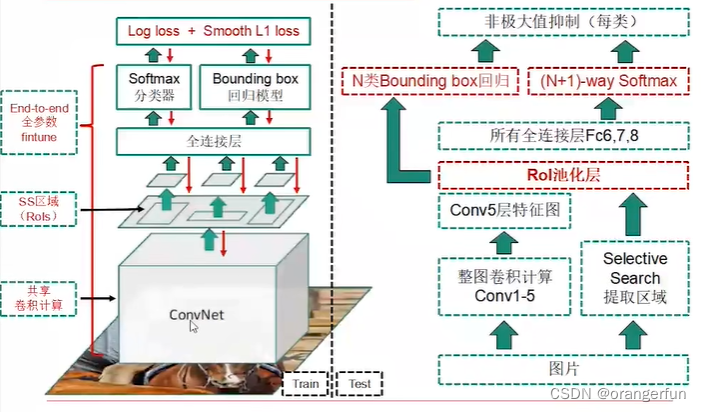
4.2 Fast R-CNN网络结构
RoI Pooling
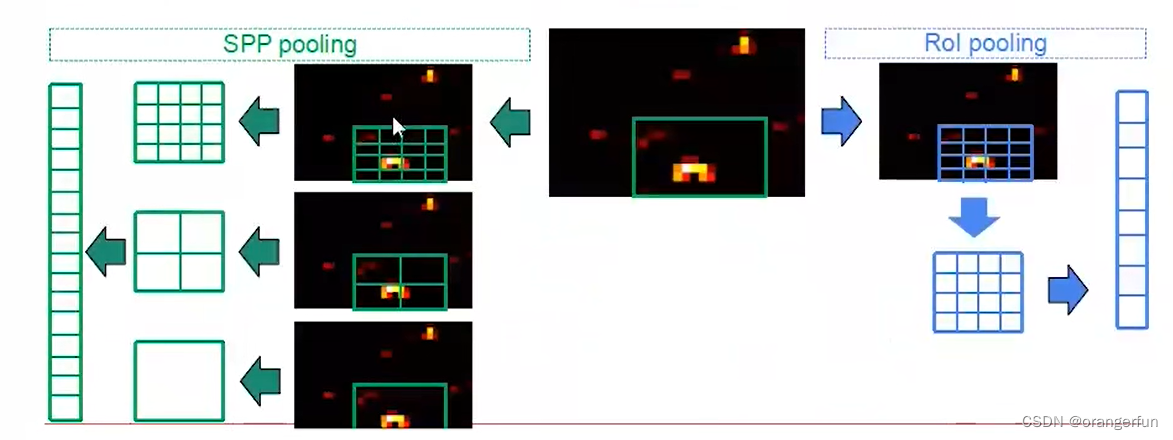
下图展示RoI pooling和 SPP Pooling层的区别
ROI Pooling 是 SPP Pooling的单层特例,具体来说将CNN网络输出的图片特征只进行一次7*7的分割,然后将每个Bin中的所有特征做Max Pooling。
好处是输入特征尺寸不同,但输出尺寸都相同
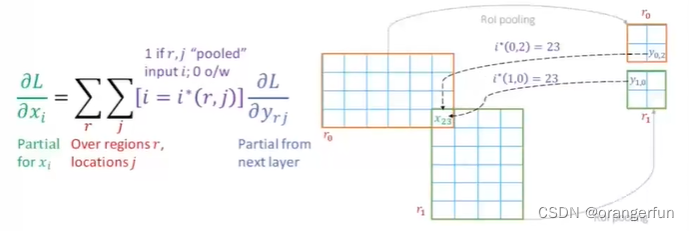
在反向传播时,重叠的ROI区域如何处理?
多个区域的偏导之和
多任务损失
总体损失为分类器损失+回归损失
分类器损失为使用softmax得到每个类别的概率后,取负对数
而回归损失基本原理与SPP-Net一致,拟合误差,但是采用了smopth L1损失,如下图所示,防止两个预测BOX与Ground Truth相差太大造成影响(
∣
x
∣
<
1
|x|<1
∣x∣<1 部分)

4.3 训练
(1)在pretrain模型上做fine tunne
(2)采用了 mini batch sampling抽样的trick,具体做法为:
分层抽样法:每个batch大小为128(候选框的数量)=每个batch图片数量为2 * 每个图片的ROI数量64
ROI分类:基于RoI与Ground Truth重叠
- 包含物体的RoI占25%(IoU>=0.5)
- 背景占75%:IoU在[0.1, 0.5)
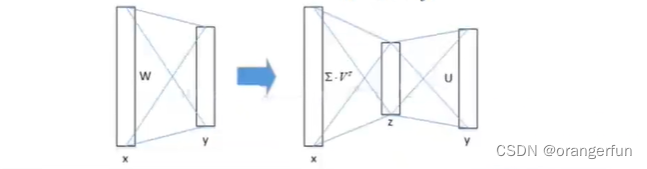
(3)采用SVD分解加速运算
由于要处理的RoI数量比较多,几乎一半的前向计算时间都被用于全链接层。就Fast R-CNN来说,RoI池化层后的全链接层需要进行约2k次计算,因此Fast R-CNN采用了SVD分解加速全连接层的计算
具体来说如下图所示,将两个矩阵相乘,分解成三个矩阵相乘,由于右边的中间层很小,所以总的参数量会比左边的计算小
5. Faster R-CNN
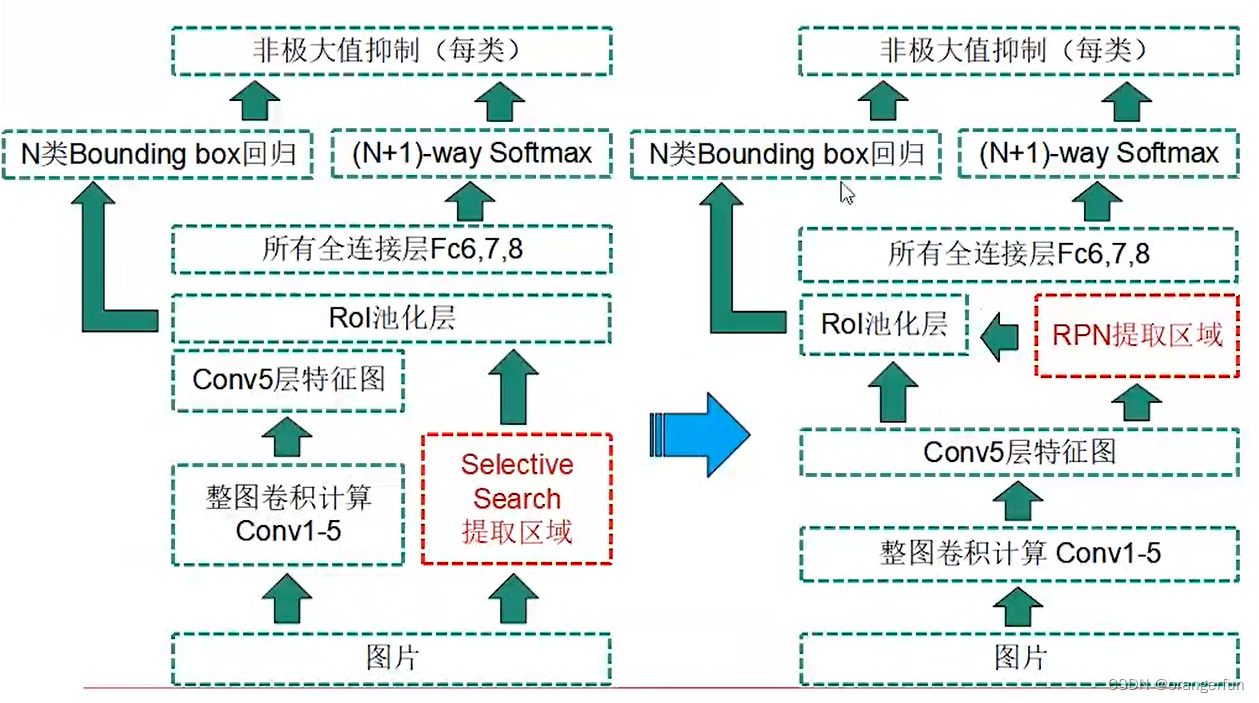
使用region proposal network(RPN)网络代替离线selective search模块,即Faster R-CNN = Fast R-CNN + RPN;基于attention机制引导Fast R-CNN关注区域,Region Proposal 量少(约300个)质高
5.1 Region Proposal Network(RPN)
RPN网络结构如下图所示
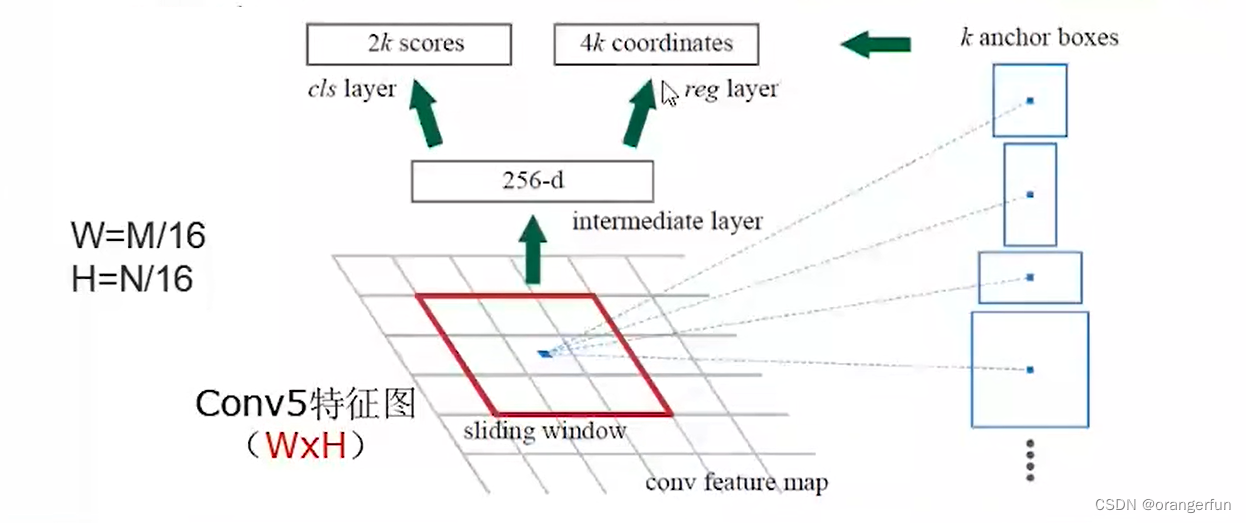
(1)输入图片的Conv5特征输入到RPN网络中,首先进行33 256-d卷积层 + RELU
(2)进行11, 4k-d卷积层,输出k组proposal的偏差(r, c, w, h)
(3)进行1*1, 2k-d卷积层,输出k组得分(包含目标和不包含目标)
k默认为9,是指预定义的9种大小的候选框(anchor);包含三种尺度scale (128, 256, 512)和三种宽高比(1:1, 1:2, 2:1)。Conv5特征图上每个点都有k个anchor,所以anchor的总量为W*H*k
RPN网络损失函数
总体损失函数如下所示
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
P
i
,
i
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
L\left(\left\{p_i\right\},\left\{t_i\right\}\right)=\frac{1}{N_{c l s}} \sum_i L_{c l s}\left(P_i, i_i^*\right)+\lambda \frac{1}{N_{r e g}} \sum_i p_i^* L_{r e g}\left(t_i, t_i^*\right)
L({pi},{ti})=Ncls1i∑Lcls(Pi,ii∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
分为两部分:
- 分类损失 L c l s L_{cls} Lcls覆盖两类:框种存在目标,框中不存在目标
- 回归损失
L
r
e
g
L_{reg}
Lreg,与Fast RCNN基本一致,使用sooth L1,拟合候选框的偏差

同时在训练样本中也存在采样,保证正负样本的分布均衡。对于每一张图片,包含128个正样本:与groundth的IoU > 0.7的anchor(或若都小于0.7则取最大Iou);128个负样本:IoU<0.3的anchor框
5.2 Faster R-CNN训练过程
(1)训练RPN网络:通过ImageNet上预训练的模型参数初始化卷积层
(2)训练Fast R-CNN网络(除了RPN以外其他部分):卷积层由ImageNet上预训练的模型参数初始化;Region Proposal由step1RPN生成
(3)调优RPN:使用step2的参数初始化卷积层,然后固定卷积层,finetunne剩余层
(4)调优Fast R-CNN:固定卷积层,fine tune剩余层,Region Prosals由step3的RPN生成
6. 总结
从SPP-Net到Fast R-CNN是一个巨大的进步,从分别训练分类器和回归器的多任务,到分类器回归器合二为一一起训练
R-CNN 和 SPP-Net对比
SPP-Net和Fast R-CNN对比
Fast R-CNN 和 Faster R-CNN 对比
参考
[1] Felzenszwalb P F, Huttenlocher D P. Efficient Graph-Based Image Segmentation[J]. International Journal of Computer Vision, 2004, 59(2):167-181.
[2]. 知乎-SPP-net
[3]. R-CNN论文详解
[4]. 一文读懂Faster RCNN
[5]. b站-计算机视觉零基础入门