文章目录
- 用户行为数据分析
- 1 项目描述
- 2 项目需求
- 3 数据准备
- 1、创建user_data数据表用于导入user_data.csv中的数据
- 2、加载user_data.csv中的数据到user_data表
- 3、接下来进行数据清洗,包括:删除重复值,时间戳格式化,删除异常值。
- 4 统计分析
- 1、查询总访问量PV,总用户量UV
- 2、查询日均访问量,日均用户量
- 3、查询每个用户的购物情况
- 4、根据user_behavior_count的结果查询复购率
- 5、统计转化率
- 6、统计一天内活跃时段点击数、收藏数、加购物车数、购买数的分布
- 7、统计周用户点击数、收藏数、加购物车数、购买数的活跃分布
- 8、统计用户最近一次的购买时间,降序排序只显示前10条记录
- 9、统计消费频率最高的前10名用户

用户行为数据分析
1 项目描述
user_data.csv是一份用户行为数据,时间区间为2017-11-25到2017-12-03,总计29132493条记录,大小为1.0G,包含5个字段。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 字段名 | 数据类型 | 说明 |
|---|---|---|---|
| 用户ID | user_id | string | 用户ID |
| 商品ID | item_id | string | 商品ID |
| 商品类目ID | category_id | string | 商品类目ID |
| 行为类型 | behavior_type | string | 行为类型,包括(pv, buy, cart, fav) |
| 时间戳 | create_time | int | 行为时间戳 |
用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
2 项目需求
1、查询总访问量PV,总用户量UV
2、查询日均访问量,日均用户量
3、查询每个用户的购物情况(统计点击、商品购买、加入购物车、收藏的次数),统计结果放入表user_behavior_count
4、根据user_behavior_count的结果查询复购率:产生两次或两次以上购买的用户占购买用户的比例
5、统计用户各环节行为转化率,分别统计从“点击”到“(加购物车+收藏)”的转化率,和从“(加购物车+收藏)”到“购买”的转化率
6、统计一天内活跃时段点击数、收藏数、加购物车数、购买数的分布
7、统计周用户击数、收藏数、加购物车数、购买数的活跃分布
8、统计用户最近一次的购买时间,降序排序只显示前10个记录
9、统计消费频率最高的前10名用户
3 数据准备
将数据加载到hive,然后通过hive对数据进行处理
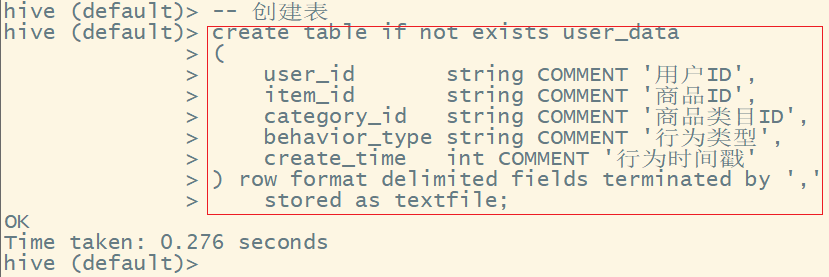
1、创建user_data数据表用于导入user_data.csv中的数据
-- 创建表
create table if not exists user_data
(
user_id string COMMENT '用户ID',
item_id string COMMENT '商品ID',
category_id string COMMENT '商品类目ID',
behavior_type string COMMENT '行为类型',
create_time int COMMENT '行为时间戳'
) row format delimited fields terminated by ','
stored as textfile;
2、加载user_data.csv中的数据到user_data表
上传user_data.csv到虚拟机:
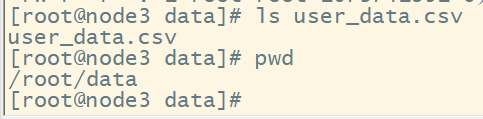
加载数据到user_data表:
load data local inpath '/root/data/user_data.csv' into table user_data;

测试数据是否导入:
select * from user_data limit 10;
结果为:

3、接下来进行数据清洗,包括:删除重复值,时间戳格式化,删除异常值。
(1)user_data表中的create_time是int类型,是时间戳字段。在实际使用时时间戳字段使用不方便,为了使用方便需要把时间戳字段改为日期时间字符串。创建user_data_new表,把其中的create_time字段数据类型从int改为string类型,用于存储日期时间字符串。
-- 创建表
create table if not exists user_data_new
(
user_id string COMMENT '用户ID',
item_id string COMMENT '商品ID',
category_id string COMMENT '商品类目ID',
behavior_type string COMMENT '行为类型',
create_time string COMMENT '行为时间戳'
) row format delimited fields terminated by ','
stored as textfile;
结果为:
(2)对user_data进行数据清洗,去掉完全重复的数据。分组操作可以达到去重的目的,对谁去重就对谁分组。
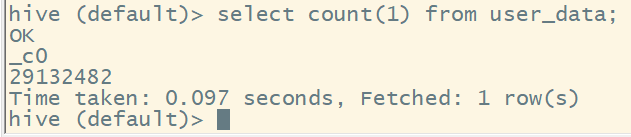
查看去重前数据量:
select count(1) from user_data;
结果为:

数据去重:
insert overwrite table user_data
select user_id, item_id, category_id, behavior_type, create_time
from user_data
group by user_id, item_id, category_id, behavior_type, create_time;
查看去重后数据量:
select count(1) from user_data;
结果为:
(3)对user_data进行数据清洗,int类型的时间戳格式化成日期时间字符串,新数据存于user_data_new表中。使用函数from_unixtime进行日期时间格式化。
insert overwrite table user_data_new
select user_id, item_id, category_id, behavior_type, from_unixtime(create_time, 'yyyy-MM-dd HH:mm:ss')
from user_data;
查看数据是否格式化成功:
select * from user_data_new limit 10;

(4)查看user_data_new表中create_time字段是否有异常值,为NULL的或不在统计时间范围内的
方法一:直接查找
select *
from user_data_new
where date(create_time) not between '2017-11-25' and '2017-12-03'
or create_time is null;
发现有异常值:
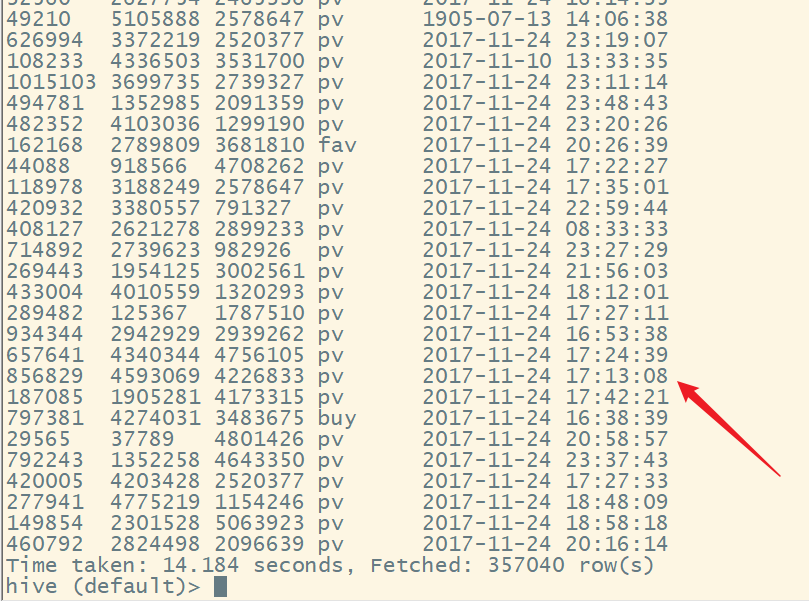
我们发现异常数据也是比较大的,不太容易观察。
方法二:根据group分组聚合
select date(create_time) as day
from user_data_new
group by date(create_time)
having day not between '2017-11-25' and '2017-12-03'
or day is null
order by day;
结果为:
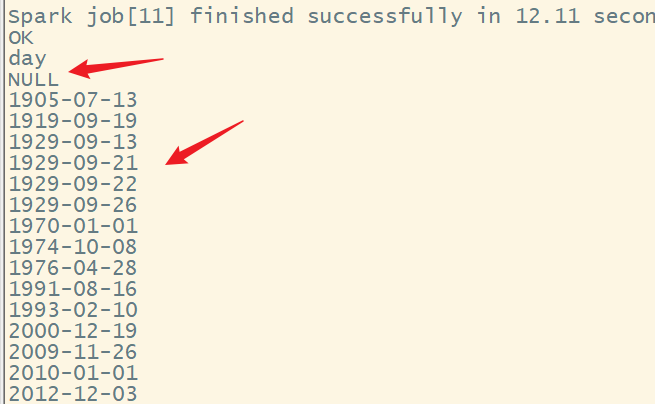
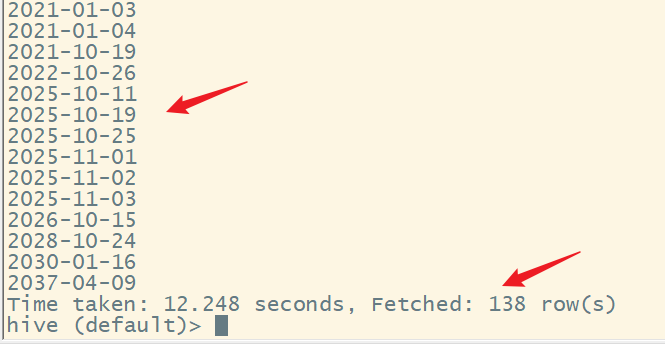
发现异常值还是比较多的。
(5)对user_data_new表进行数据清洗,去掉时间异常的数据。把create_time处于’2017-11-25’ 和 '2017-12-03’之间的数据认为是正常数据。
cast(create_time as date)可以把日期时间字符串转为日期
insert overwrite table user_data_new
select user_id, item_id, category_id, behavior_type, create_time
from user_data_new
where cast(create_time as date) between '2017-11-25' and '2017-12-03';
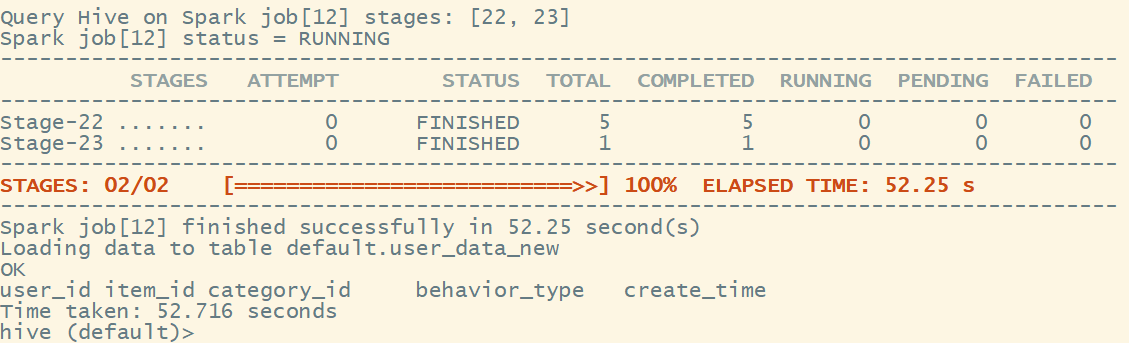
检查一下是否还有异常数据:
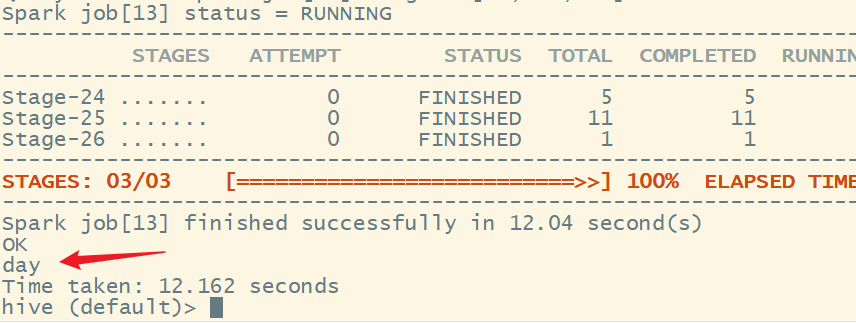
create_time 没有异常数据了。
(6)查看 user_data_new表中behavior_type 是否有异常值,可用分组运算查看behavior_type的值
select behavior_type from user_data_new group by behavior_type;
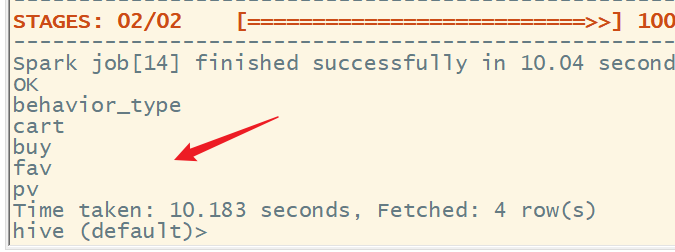
behavior_type 发现没有异常值。
4 统计分析
1、查询总访问量PV,总用户量UV
select sum(if(behavior_type = 'pv', 1, 0)) as pv,
count(distinct user_id) as uv
from user_data_new;
结果为:
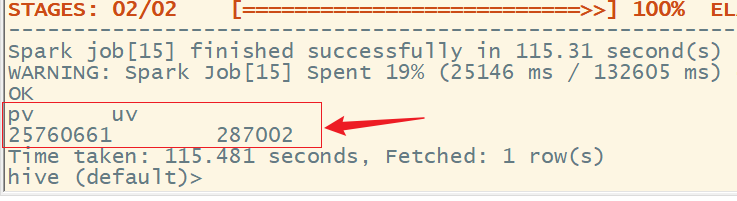
2、查询日均访问量,日均用户量
日期比较函数: datediff
语法:
datediff(string enddate, string startdate)返回值: int
说明: 返回结束日期减去开始日期的天数。
-- datediff(string enddate, string startdate)得到的天数需要加1
select sum(if(behavior_type = 'pv', 1, 0)) / (datediff('2017-12-03', '2017-11-25') + 1) as avg_pv,
count(distinct user_id) / (datediff('2017-12-03', '2017-11-25') + 1) as avg_uv
from user_data_new;
结果为:
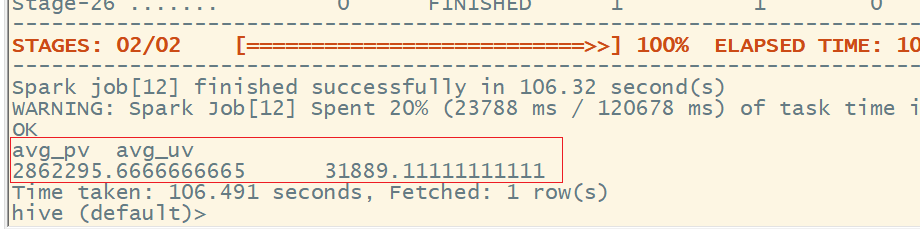
每日访问量,每日用户量:
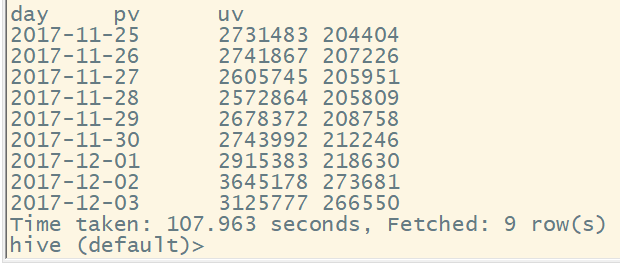
select date(create_time) as day,
sum(if(behavior_type = 'pv', 1, 0)) as pv,
count(distinct user_id) as uv
from user_data_new
group by date(create_time)
order by day;
结果为;
3、查询每个用户的购物情况
查询每个用户的购物情况(统计点击、商品购买、加入购物车、收藏的次数),统计结果放入表user_behavior_count。
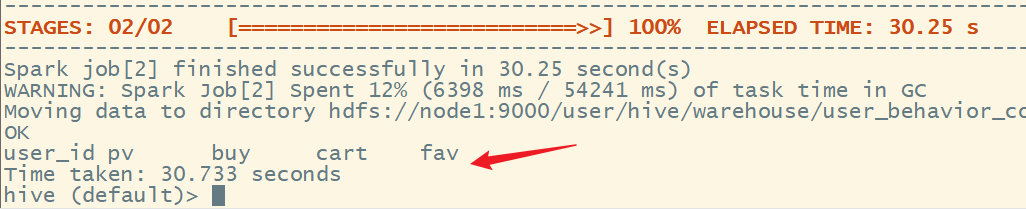
create table user_behavior_count as
select user_id,
sum(if(behavior_type = 'pv', 1, 0)) pv,
sum(if(behavior_type = 'buy', 1, 0)) buy,
sum(if(behavior_type = 'cart', 1, 0)) cart,
sum(if(behavior_type = 'fav', 1, 0)) fav
from user_data_new
group by user_id;
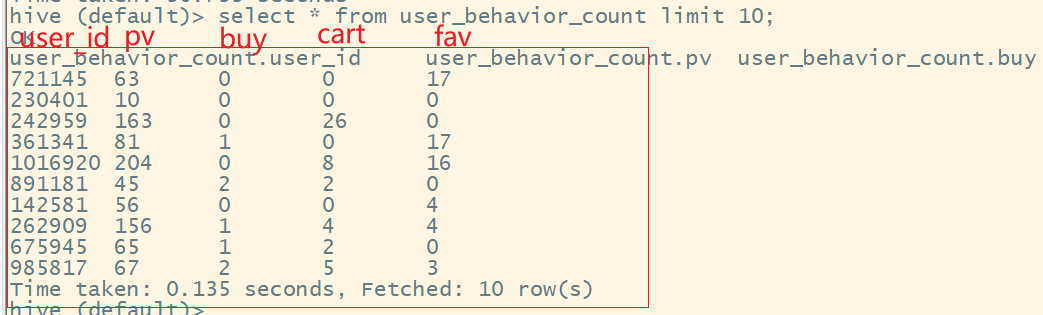
查看数据是否导入表中:
select * from user_behavior_count limit 10;
结果为:
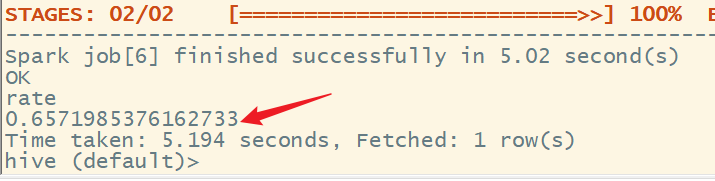
4、根据user_behavior_count的结果查询复购率
复购率:产生两次或两次以上购买的用户占购买用户的比例
select sum(if(buy > 1, 1, 0)) / sum(if(buy > 0, 1, 0)) rate
from user_behavior_count;
结果为:
5、统计转化率
统计用户各环节行为转化率,分别统计从“点击”到“(加购物车+收藏)”的转化率,和从“(加购物车+收藏)”到“购买”的转化率。
select round(sum(cart + fav) / sum(pv), 4), round(sum(buy) / sum(cart + fav), 4)
from user_behavior_count;
结果为:
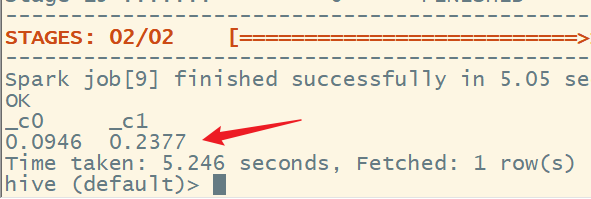
从“点击”到“(加购物车+收藏)”的转化率为0.0946,比较低,可能由于多种因素导致,以下是一些常见的原因:
-
网站设计不够吸引人:用户在点击进入网站后,如果网站布局、颜色、文字排版等没有吸引力,用户可能会失去兴趣,不再进行后续的操作;
-
目标用户不明确:如果网站的推广广告或者流量来源渠道不够明确,会吸引一些不符合目标用户要求的人群,他们不会对网站感兴趣,因此不会进行加购物车或收藏操作;
-
商品的价格过高或者质量不好:如果网站商品的价格过高或者质量不好,用户可能会选择不进行购买、加购物车或者收藏的操作;
-
用户体验不佳:如果进行加购物车或者收藏的流程复杂、页面加载时间较长等,会影响用户体验,导致用户放弃操作;
-
流量质量差:如果网站的流量质量较差,也会导致用户没有进行加购物车或收藏的行为。
从“(加购物车+收藏)”到“购买”的转化率为0.2377,相对较高,可能是因为进行加购物车和收藏的都是对商品感兴趣的,他们购买商品的意愿更强烈。
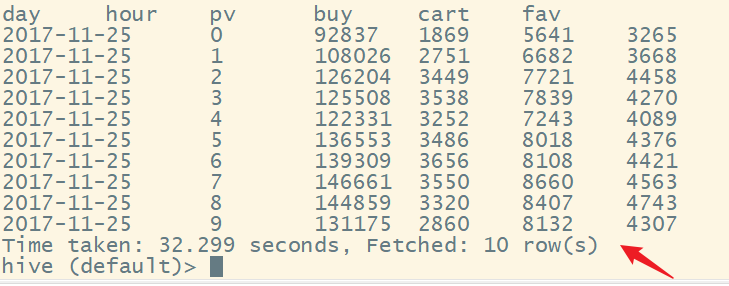
6、统计一天内活跃时段点击数、收藏数、加购物车数、购买数的分布
select date(create_time) day,
hour(create_time) hour,
sum(if(behavior_type = 'pv', 1, 0)) pv,
sum(if(behavior_type = 'buy', 1, 0)) buy,
sum(if(behavior_type = 'cart', 1, 0)) cart,
sum(if(behavior_type = 'fav', 1, 0)) fav
from user_data_new
group by date(create_time), hour(create_time) -- 不能使用别名
order by day, hour
limit 10;
结果为:
也可以使用字符串函数截取,然后分组聚合。
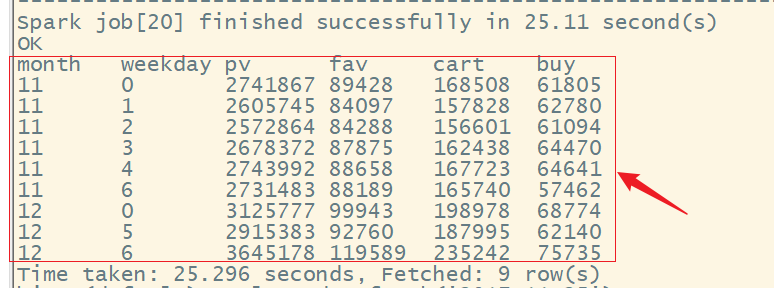
7、统计周用户点击数、收藏数、加购物车数、购买数的活跃分布
如何计算周几?
方法一:这样得到的周日为第0天。
pmod(int a, int b),pmod(double a, double b):返回a除b的余数的绝对值。
datediff(endDate, startDate):返回startDate到endDate相差的天数
计算create_time所代表的日期是星期几,pmod(datediff(create_time, ‘1920-01-01’) - 3, 7)
方法二:这样得到的周日为第7天。
select dayofweek('2017-11-25');
以第一种方法为例:
select month(create_time) month,
pmod(datediff(create_time, '1920-01-01') - 3, 7) weekday,
sum(if(behavior_type = 'pv', 1, 0)) pv,
sum(if(behavior_type = 'fav', 1, 0)) fav,
sum(if(behavior_type = 'cart', 1, 0)) cart,
sum(if(behavior_type = 'buy', 1, 0)) buy
from user_data_new
group by month(create_time), pmod(datediff(create_time, '1920-01-01') - 3, 7)
order by month, weekday;
结果为:
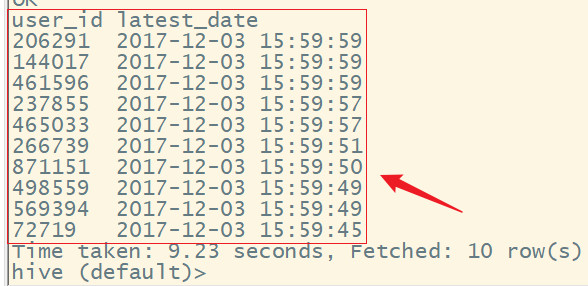
8、统计用户最近一次的购买时间,降序排序只显示前10条记录
select user_id, max(create_time) latest_date
from user_data_new
where behavior_type = 'buy' --指定行为为buy
group by user_id
order by latest_date desc
limit 10;
结果为:
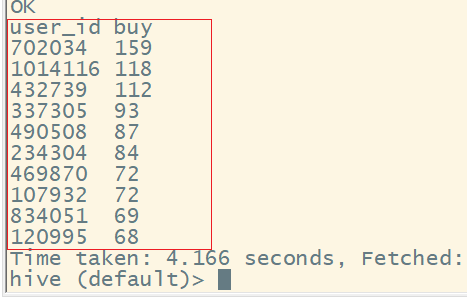
9、统计消费频率最高的前10名用户
select user_id, buy
from user_behavior_count
order by buy desc
limit 10;
结果为:
参考文章:
https://blog.csdn.net/weixin_46436010/article/details/129732809?spm=1001.2014.3001.5502