-
paper link
-
本文提出了使用提示引导特征映射的生成式视频异常检测框架,作者来自中山大学,文章发表在cvpr2023
-
作者首先分析了现有方法并指出当前面临的两个问题
两个关键挑战
-
大多数视频异常检测方法通过在训练阶段学习正常事件的分布,并在测试阶段检测分布外样本来决问题。显著的重建或预测误差被视为异常 。 然而,异常并不总是导致足够的误差被检测到,或者说,异常和重建误差并非等价关系 。
-
因此,一些方法不是用正常行为的分布来计算误差 ,而是试图生成
伪 异 常来模拟异常 行为的分布。例如 , 收集与检测场景无关的图像作为伪异常样本 。通过提取间歇帧来反转动作顺序或运动不规则,从而产生时间异常。 -
然 而,
伪异常和自然异常之间不可避免的差距。
为了 解决伪异常问题,Acsintoae等人利用3D动画和2D背景图像发布了一个名为Ubnormal 的虚拟视频异常检测数据集。

异常差距
- 然而,现有的方法未能解决两个关键挑战。首先,异常 在 虚 拟 数 据 集 中 是 有 界 的 , 但 在 现 实 世 界 中 是 无 界 的 ,作者定义这 种差异 称为异常差距。
场景间隙
-
其次, 不同的场景具有特定场景的异常 (在一个场景中异常但在 另一个场景中正常的事件)和特定场景的属性(例如监控摄像机的视 点), 我们将这种差异定义为场景间隙 。
-
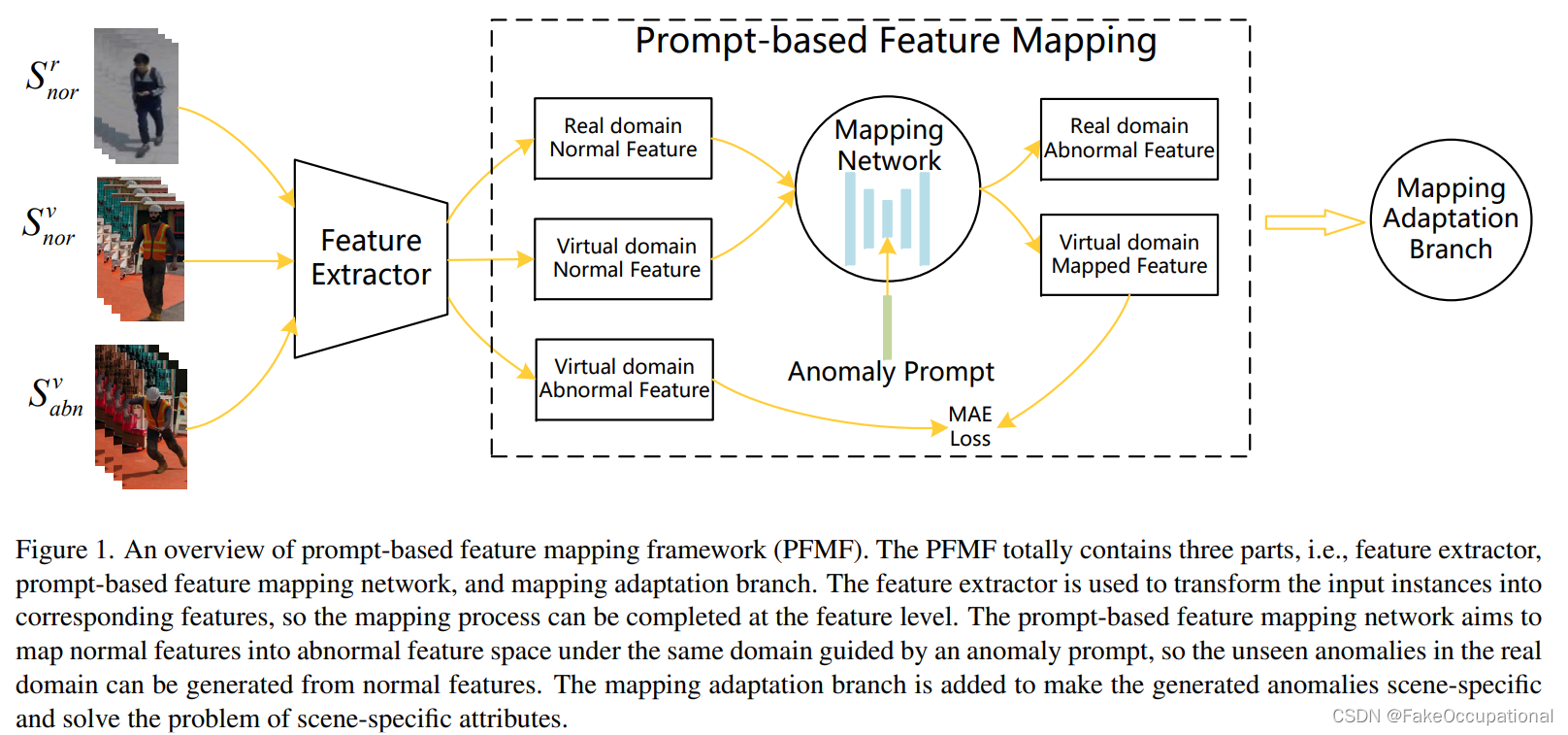
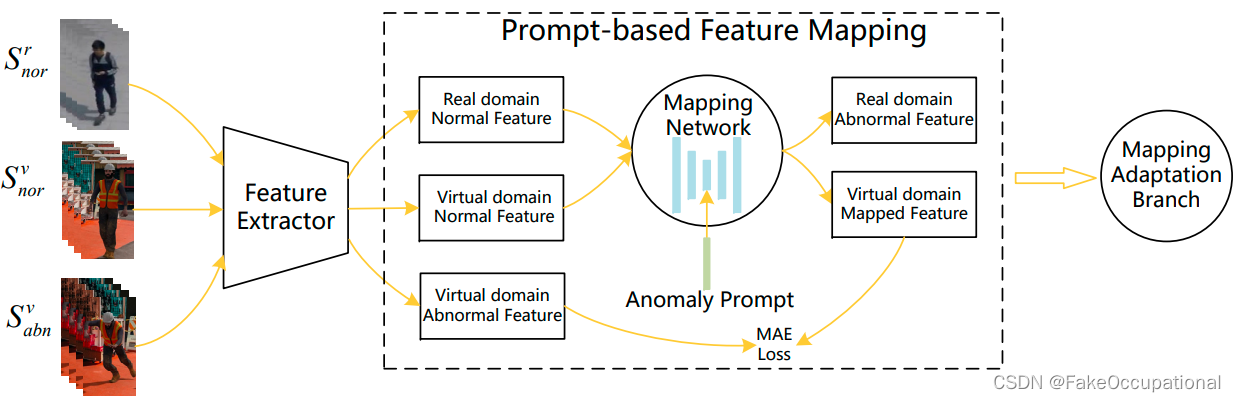
为了解决异常间隙和场景间隙的问题,作者提出了基于提示的特征映射框架 (PFMF)。
-
本文贡献如下:
(1)提出一种新的基于提示的视频异常检测特征映射框架 (PFMF)。该框架通过生成具有无边界类型的异常样本, 解决了将具有限异常的虚拟数据集应用于真实场景的挑战。
(2)提出 映射适 应分 支,以 确保 PFMF 生 成的 异常是 场景特定的,并解决场景特定属性的问题。
(3)在 ShanghaiTech、 Avenue 和 UCF-Crime 三个公共VAD 数据集上展示了所提出框架的有效性。大量实验表明,与 state -of-art相比 ,本文提出的框架表现最好
pipeline
-
如图 1 所 示。 在
缩小异常间隙方面 , PFMF采用提示引导的映射网络,通过发散映射(divergent mapping)过程生成无界异常 。 异常提示是从变分自动编码器(VAE)学习的分布中提取的。 -
至于
场景间隙,作者引入了映射适应分支来 解决 它 。具体来说 ,该分支由 一个异常分类器和两个领域分类器组成 , 前者使生成的异常特定于场景 ,后者减少了场景特定属性导致的不一致。
提示引导的映射网络
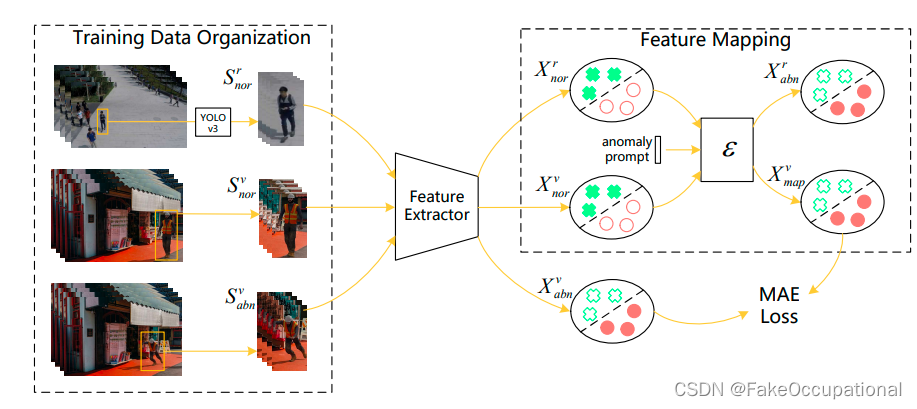
- (1)数据组织
虚拟VAD数据集提供了丰富的实例级异常注释。数据集标注了行为是否异常,同时还提供了每个人的轮廓。然而,现实世界的VAD 数据集只包含没有注释的原始视频,不存在异常行为。因此,如图左侧所示,框架接受三种类型的输入,即实域正常实例、 虚拟域正常实例和虚拟域异常实例。虚拟数据集是基于每个人的。考虑到真实域数据集中没有边界框注释,我们应用MSCOCO数据集上预训练的YOLOv3 检测器来提取每个人的边界框。
基于提示的特征映射
在获得实例级输入后,使用特征提取器提取高维特征,
如图 2 所示 。 然 后, 应 用特 征 映 射网 络 ,通 过 不 对称 映 射
在 虚 拟 域 中 正 常 特 征 和 异 常 特 征 之 间 搭 建 桥 梁 。 映 射 过
程 由 异 常 提 示 引 导 , 生 成 无 界 类 型 的 异 常 。 提 示 生 成 过
程如 图 3 所 示 。
- 对于虚拟域,映射网络ε将正常v特征norx映射到异常特征xabnv,然后使用MAELoss最小化映射特征x与 mapv 异常特征 x 之间的差距。对于vabn真实域,使用虚拟域中学习到的映射网络分别生成看不见的异常x为Xabn rnor v和 Xabnv 。用 ε (.)表 示的映射网络包含一个编码器ε(.)来提取高 级信 息 e,以及一个解码 器 ε (.)来对编码特征进行上采样d。
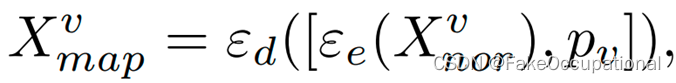
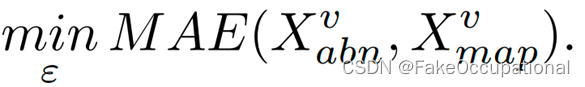
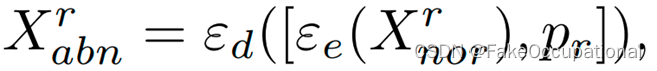
异常提示生成
-
异常向量
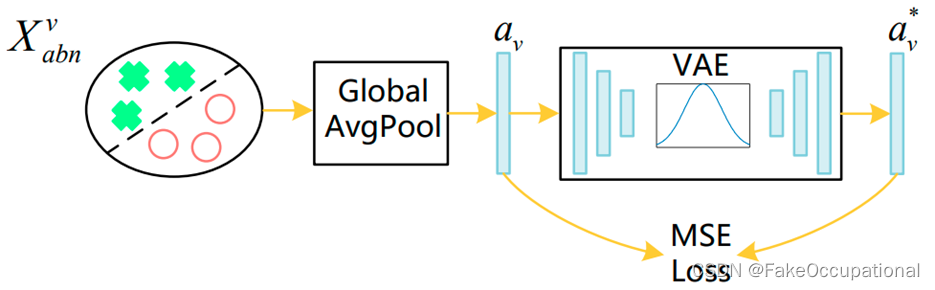
-
虚拟域中的异常向量是通过全局平均池化来压缩异常特征的空间维度而获得的。然后使用VAE网络对异常向量进行特征提取与重建。
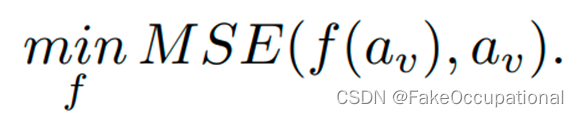
-
在真实域中,我们从VAE的后验分布中采样潜在变量z并对z进行解码以获得异常向量
-
场景向量
-
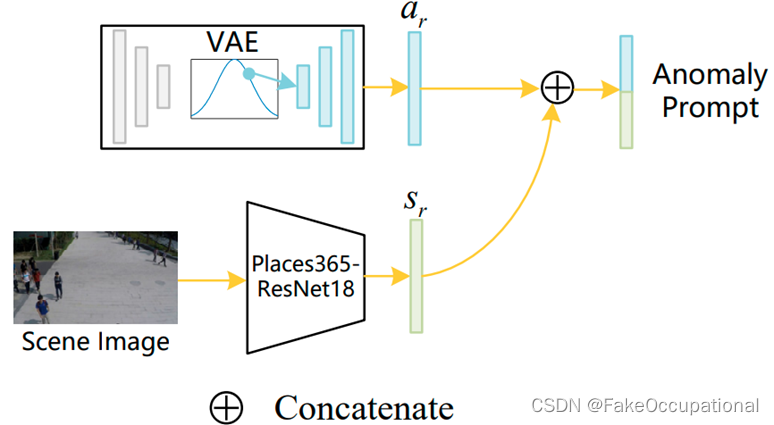
我们的目标是使生成的异常特征与场景无关 (适用于任何输入场景),以缩小场景差距。因此,通过生成场景向量sr来添加额外的场景信息 。如图(b)所 示,我们将场景图像 (未检测YOLOv3)馈送到Places365数据集上预训练的ResNet-18中,以识别场景信息。 我们将ResNet-18 中 softmax之前的特征应用于场景向量。
映射适应分支
- 最后,将所有特征馈送到映射适应分支中,进一步缩小场景 间隙 , 如 图 4 所示。
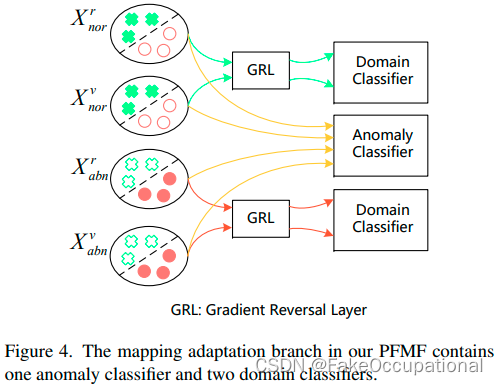
- PFMF中的映射自适应分支包含一个异常分类器和两个域分类器。
GLR
- https://arxiv.org/abs/1409.7495
在风格迁移的任务中,存在一种被称作domain shift的现象。深度学习的模型在source domain数据集上训练的很好(90%左右),但是迁移到target domain的效果就很差(54%左右)。
在Target Domain的图片是无标签的情况下,如何提高模型对其识别效果?Unsupervised Domain Adaptation by Backpropagation提出一种在深度架构中适应领域的新方法,该方法可以是 对来自源域的大量标记数据和大量数据进行训练 来自目标域的未标记数据
具体来说在原来feature mapping的基础上外接一个domain classifier(之前那个叫做label classifier),这个domain classifier的作用是判别当前样本是属于哪个domain的,如果你的数据集只有两个分布,那么这个classifier就是一个二分类任务。如果你正常进行梯度更新的话,feature mapping这个向量在不同的domain上就会dissimilar,但是如果你加了梯度反向层(让encoder这个部分关于domain的loss传回来的梯度是反向更新的),那么这个features mapping在不同的domain(数据集)上就可以表现出特征不变性(也就是体现出特征解耦)
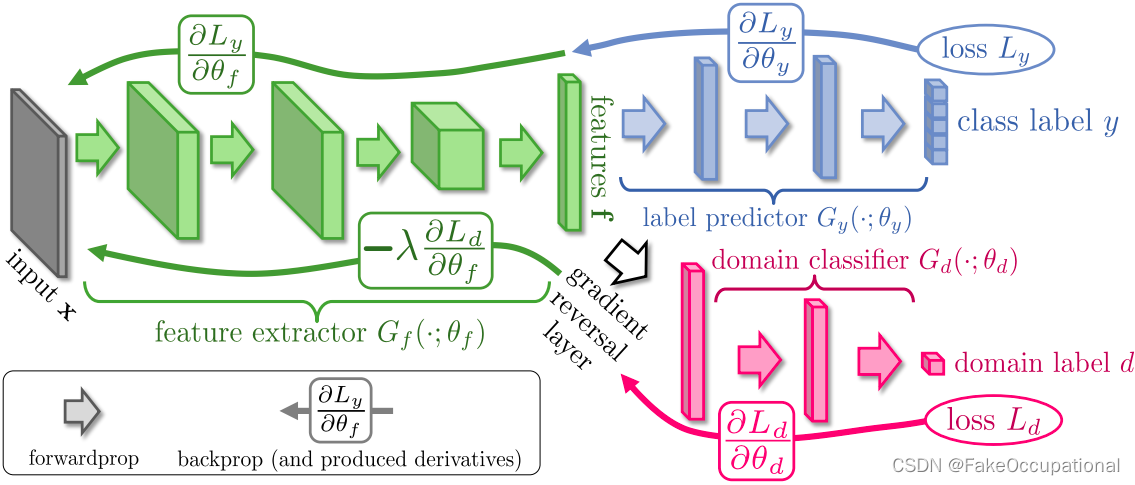
- 该结构包括一个深特征提取器(绿色)和一个深标签预测器(蓝色),它们共同构成一个标准的前馈结构。在基于反向传播的训练过程中,通过梯度反转层将梯度乘以一定的负常数,将一个域分类器(红色)连接到特征提取器,实现无监督域自适应。否则,训练将以标准的方式进行,并最小化标签预测损失(对于源示例)和域分类损失(对于所有示例)。梯度反转确保了两个域上的特征分布是相似的(对于域分类器来说,尽可能难以区分),从而产生域不变的特征。
训练和推理
- 提出的PFMF以统一的方式进行训练 。总损失包含 四 个术 语 , 特征映射损失 Lm、异常分类损失La、领域分类损失Ld和VAE重建损失Lv。 整个损失为 all 三项的加权和,为
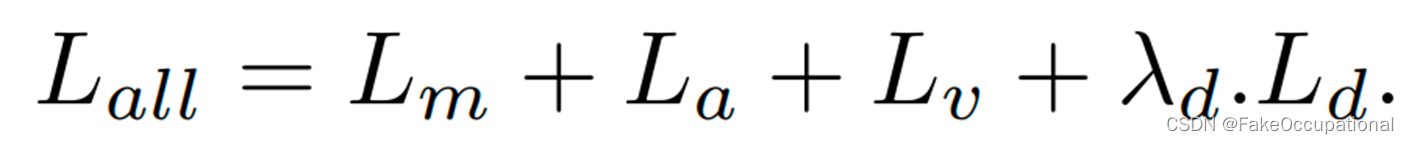
- 生成的异常允许以完全监督的方式训练网络。给定一个未见过的实例,它首先被输入到特征提取器θ,然后通过异常分类器σ。异常分类器中的分类结果被视为实例级异常分数。实例级异常分数被组装成具有与输入帧相同形状的异常图。帧级异常得分是通过取异常图的每帧中的最大值来获得。
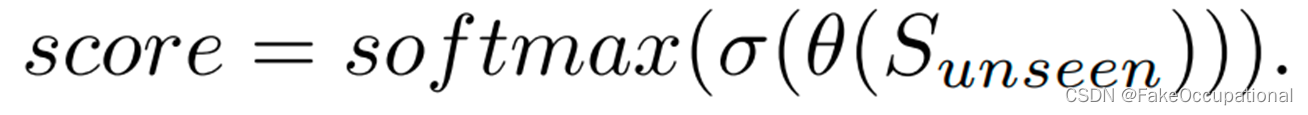
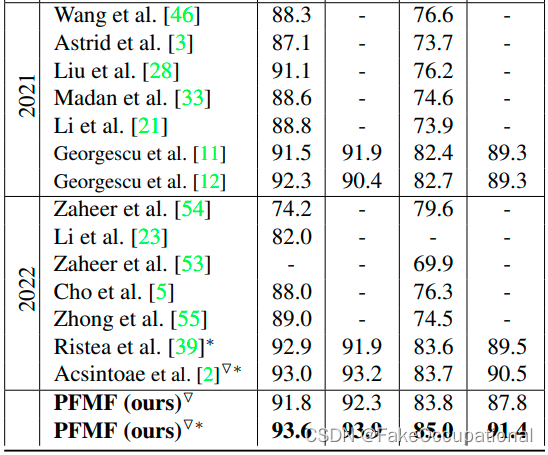
结果比较

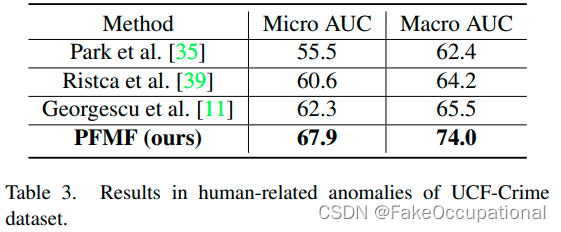
消融实验
CG
- Generating Anomalies for Video Anomaly Detection With Prompt-Based Feature Mapping
- 半监督视频异常检测和预测的综合新基准
- https://dl.acm.org/doi/pdf/10.1145/3577925
- http://www.scholarmate.com/psnweb/outside/homepage?des3PsnId=gdC9pv0cs%2BvK%2BaeBPExIcw%3D%3D&psnLanguage=0
- https://github.com/lilygeorgescu/UBnormal#download

![[CKA]考试之节点维护-指定 node 节点不可用](https://img-blog.csdnimg.cn/39c84673f18745abbae48287e3b79b32.png)