项目简介
项目简介
本项目来源于飞桨AI for Science共创计划的论文复现赛题,复现论文为《AMGNET: multi-scale graph neural networks for flow field prediction》。该论文主要采用图神经网络,因为在计算流体力学中计算域被网格离散化,这与图结构天然契合。论文中通过训练 CFD 仿真数据,构建一种数据驱动模型进行流场预测。本文将与大家分享基于飞桨完成该论文的复现过程,欢迎大家一起沟通学习。
论文链接
https://doi.org/10.1080/09540091.2022.2131737
原文代码
https://github.com/baoshiaijhin/amgnet、

环境依赖

硬件与框架
本项目需要的硬件环境与框架要求如下所示:
GPU Memory >= 8GB
飞桨== 2.4.0
Python ==3.7.4
PGL == 2.2.4
Matplotlib == 3.5.3
pyamg == 4.2.3
scipy

本地安装
通过以下指令完成飞桨以及各个库的安装。
1.conda create -n paddle_env python=3.7
2.conda install paddlepaddle-gpu==2.4.0 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
3.pip install pgl==2.2.4
4.pip install matplotlib==3.5.3
5.pip install pyamg==4.2.3
6.pip install scipy
模型介绍

模型框架
AMGNET 是一种基于图神经网络的 CFD 计算模型,该模型可以预测在不同物理参数下的流场。图3.1为模型的网络结构图,该模型的基本原理就是将网格结构转化为图结构,然后通过网格中节点的物理信息、位置信息以及节点类型对图中的节点和边进行编码。接着对得到的图神经网络使用基于代数多重网格算法( Olson and Schroder, 2018 )的粗化层进行粗化,将所有节点分类为粗节点集和细节点集,其中粗节点集是细节点集的子集。粗图的节点集合就是粗节点集,于是完成了图的粗化,缩小了图的规模。粗化完成后通过设计的图神经网络信息传递块( GN )来总结和提取图的特征。之后图恢复层采用反向操作,使用空间插值法( Qi et al.,2017 )对图进行上采样。例如要对节点i插值,则在粗图中找到距离节点i最近的k个节点,然后通过公式计算得到节点i的特征。最后,通过解码器得到每个节点的速度与压力信息。
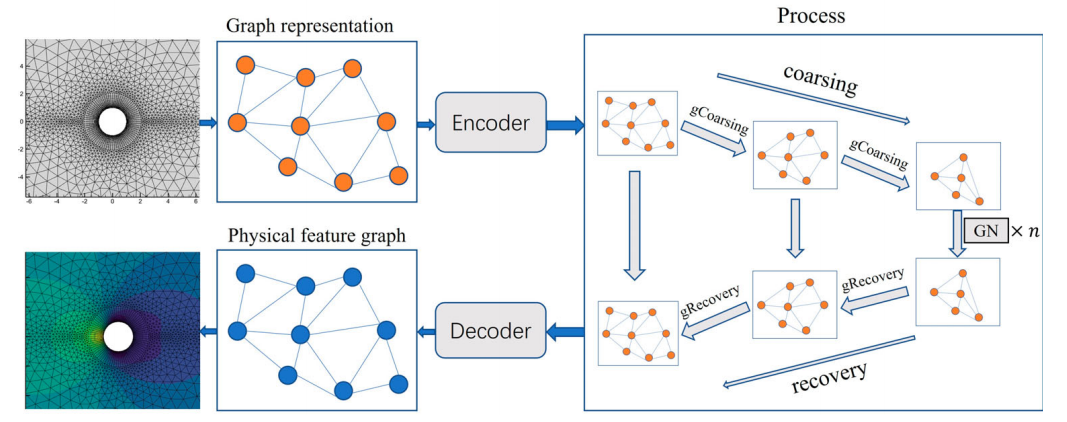
图3.1 网络结构图

论文源码
原文的代码总体上可以分为4个部分,分别是数据预处理、图粗化层、图卷积块和图恢复层。如图3.2所示。
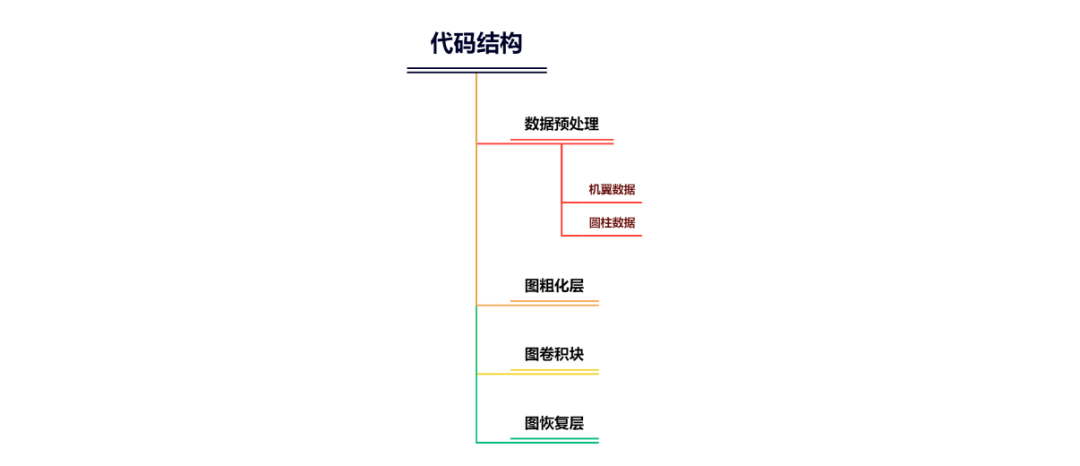
图3.2 原文代码结构
原文代码的关键技术要点如下:
编码节点的特征和边的特征:
(
进而将原始网格数据变换为图结构的数据。
使用代数多重网格算法进行图粗化,这个过程中存在大量的稀疏矩阵乘法,例如:
其中,A表示图的邻接矩阵。
在图恢复层中,源代码采用空间插值法进行上采样:
其中,ri表示要恢复的节点i的特征,wij表示节点i和节点j之间距离的倒数。

飞桨复现的技术要点
在模型中我们需要使用图神经网络模拟网格,基于图这种数据结构模拟物理场的状态,于是我们调用了飞桨的 PGL 库。由于模型进行图数据的粗化时进行了大量的稀疏矩阵运算,为了提高运算效率,减少运算时间,我们需要对图进行合并。但是 PGL 是以列表的形式存储图,所以在图数据进入模型之前需要预处理,如下:
1.def forward(self, graphs):
2. batch = MyCopy(graphs[0])
3. for index, graph in enumerate(graphs):
4. if index > 0:
5. batch = Myadd(batch, graph)
6.
7. latent_graph = self.encoder(batch)
8. x,p= self.processor(latent_graph)
9. node_features=self.spa_compute(x,p)
10. pred_field = self.decoder(node_features)
11.
12. return pred_field在基于代数多重网格的图粗化层中,我们将图粗化到不同的尺度,然后使用 GN 块通过消息传递来总结和提取图的特征。与基于代数多重网格的图粗化层相比,图恢复层采用反向操作。在图恢复层中,我们使用空间插值方法对图进行上采样,空间插值法的实现如下:
1.def knn_interpolate(features, coarse_nodes, fine_nodes):
2. coarse_nodes_input = paddle.repeat_interleave(coarse_nodes.unsqueeze(0), fine_nodes.shape[0], 0)
3. fine_nodes_input = paddle.repeat_interleave(fine_nodes.unsqueeze(1), coarse_nodes.shape[0], 1)
4. dist_w = 1.0 / (paddle.norm(x=coarse_nodes_input - fine_nodes_input, p=2, axis=-1) + 1e-9)
5. knn_value, knn_index = paddle.topk(dist_w, k=3, largest=True)
6. weight = knn_value.unsqueeze(-2)
7. features_input = features[knn_index]
8. output = paddle.bmm(weight, features_input).squeeze(-2) / paddle.sum(knn_value, axis=-1, keepdim=True)
9. return output使用代数多重网格算法对图进行粗化时,涉及大量的稀疏矩阵乘法,于是我们调用了 scipy.sparse 库。但是 scipy.sparse 库中的.dot 方法和如今大部分深度学习框架中的稀疏矩阵乘法不同,后者会保留一些0,而前者只存非零值。这种差异会导致数据维度不一致,进而影响之后的操作。针对这个问题,我们提出了两种解决方案,第一种是采用填充的方法保持数据维度,第二种是采用编码器与解码器将特征维度进行压缩。其中第一种方法与代数多重网格算法保持一致,精度较高。第二种方法提高了约20倍的训练速度,但是均方根误差会略高。两种方案的代码如下:
方案1:
1.if (index_E.shape[1] != standard_index.shape[1]):
2. index_E, value_E = FillZeros(index_E, value_E, standard_index, kN)
3.
4.def FillZeros(index_E, value_E, standard_index, kN):
5. shape = [kN, kN]
6. row_E = index_E[0]
7. col_E = index_E[1]
8. # coo_E = paddle.sparse.sparse_coo_tensor(index_E, value_E, shape)
9. DenseMatrix_E = sp.coo_matrix((paddle.ones_like(value_E), (row_E, col_E)), shape).toarray()
10.
11. row_S = standard_index[0]
12. col_S = standard_index[1]
13. DenseMatrix_S = sp.coo_matrix((paddle.ones([row_S.shape[0]]), (row_S, col_S)), shape).toarray()
14.
15. diff = DenseMatrix_S - DenseMatrix_E
16. rows, cols = np.nonzero(diff)
17. rows = paddle.to_tensor(rows, dtype = 'int32')
18. cols = paddle.to_tensor(cols, dtype = 'int32')
19. index = paddle.stack([rows, cols], axis=0)
20. value = paddle.zeros([index.shape[1]])
21. index_E = paddle.concat([index_E, index], axis=1)
22. value_E = paddle.concat([value_E, value], axis=-1)
23.
24. sp_x = paddle.sparse.sparse_coo_tensor(index_E, value_E)
25. sp_x = paddle.sparse.coalesce(sp_x)
26. index_E = sp_x.indices()
27. value_E = sp_x.values()
28.
29. return index_E, value_E方案2:
1.model_1 = paddle.nn.Sequential(
2.('l1', paddle.nn.Linear(128, 256)), ('act1', paddle.nn.ReLU()),
3.('l2', paddle.nn.Linear(256, 256)), ('act2', paddle.nn.ReLU()),
4.# ('l3', paddle.nn.Linear(256, 256)), ('act3', paddle.nn.ReLU()),
5.('l4', paddle.nn.Linear(256, 128)), ('act4', paddle.nn.ReLU()),
6.('l5', paddle.nn.Linear(128, 1))
7.)
8.model_2 = paddle.nn.Sequential(
9.('l1', paddle.nn.Linear(1, 64)), ('act1', paddle.nn.ReLU()),
10.('l2', paddle.nn.Linear(64, 128)),('act2', paddle.nn.ReLU()),
11.# ('l3', paddle.nn.Linear(128, 128)),('act3', paddle.nn.ReLU()),
12.('l4', paddle.nn.Linear(128, 128))
13.)
14.
15.val_A = model_1(value_A)
16.val_A = paddle.squeeze(val_A)
17.index_E, value_E = StAS(index_A, val_A, index_S, value_S, N, kN, nor)
18.value_E = paddle.reshape(value_E, shape=[-1, 1])
19.edge_weight = model_2(value_E) 预测结果
预测结果
我们的模型按照论文给的案例,分别在机翼和圆柱这两种不同的物理场景中进行预测,其中机翼采用 NACA0012 翼型,表示翼型的网格包含6648个节点。圆柱体网格包含3887个节点。所有网格均由三角形和四边形网格组成。翼型在稳态、可压缩和无粘性条件下由 Navier-Stokes 方程控制。圆柱在稳态、不可压缩和无粘性条件下由 Navier-Stokes 方程控制。预测结果表明,我们的模型预测的流场与真实流场基本相同,能够达到原文的精度,证明复现成功。我们模型对圆柱和机翼的预测结果如图4.1和图4.2所示。原文的预测结果如图4.3所示,其中原文的预测结果图采用了专业的流体力学软件绘制。
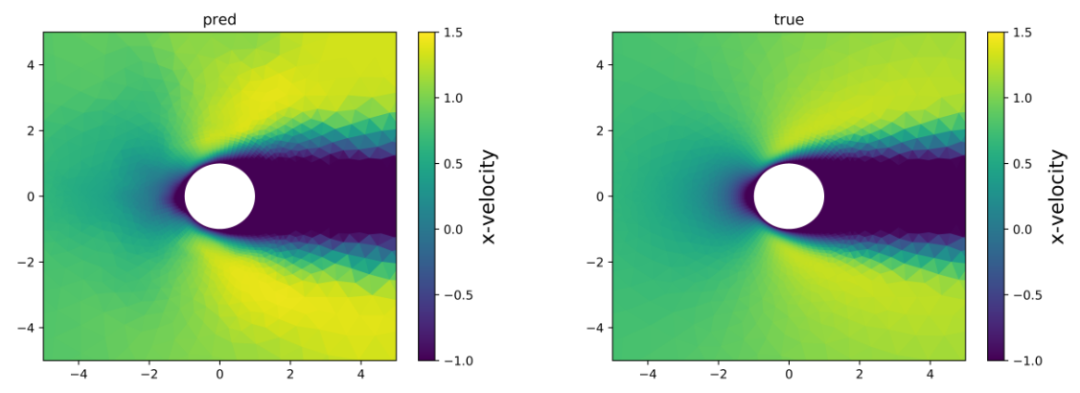 图4.1 雷诺数=78的圆柱速度场的预测值与真实值对比图
图4.1 雷诺数=78的圆柱速度场的预测值与真实值对比图
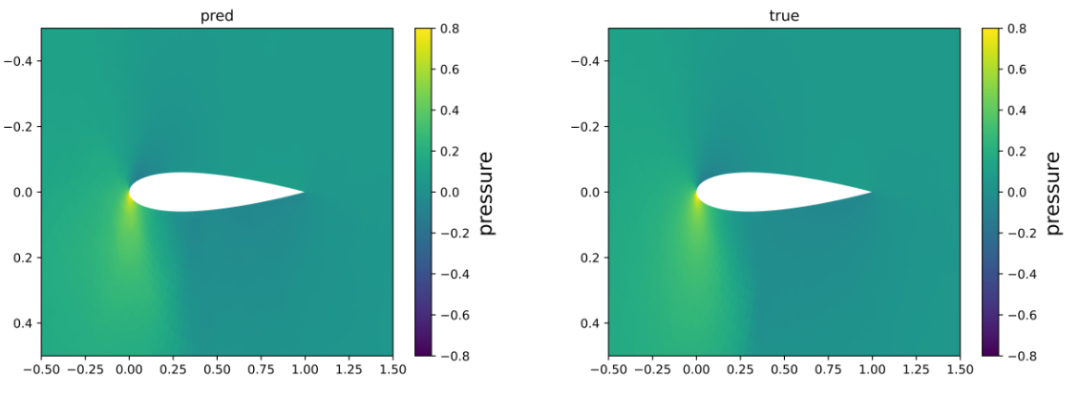 图4.2 攻角=8.0,马赫数=0.65下的机翼压力场的预测值与真实值对比图
图4.2 攻角=8.0,马赫数=0.65下的机翼压力场的预测值与真实值对比图
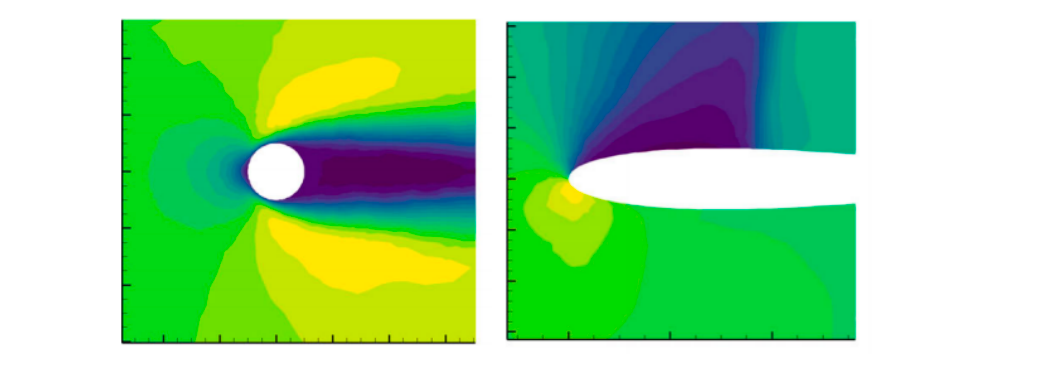
图4.3 原文中雷诺数=78的圆柱速度场的预测(左图);攻角=8.0,马赫数=0.65的机翼压力场的预测(右图)

结语
这是我们团队第一次参加百度飞桨的论文复现赛,这次比赛的经历让我们受益良多。首先,飞桨的复现赛赛事流程安排非常合理,我们被要求阅读论文,然后跑通论文的原始参考代码,这使得我们对论文的整体思路和原始代码有了清晰的了解。在复现的过程中,我们快速了解两种框架之间的差异,使用API映射表顺利切换和使用不同的框架。尽管有一些 API 无法完全对应,但我们可以进行适当地改动或重写来解决这个问题。第二,飞桨团队为这个比赛提供了优秀的平台、充足的资源以及充分的指导,这使我们能够更好地理解论文和实现代码。他们的反馈对我们复现的结果和进一步改进非常有帮助。最后,特别感谢论文作者杨志双学长以及实验室的李天宇师兄对本次复现工作提供的技术指导和专业知识讲解。
参与飞桨的论文复现赛是一次宝贵的学习和成长机会。我学到了很多关于论文复现和深度学习框架转换的知识,也结识了许多志同道合的同学和专业人士。未来,我们期待看到更多来自企业、高校、科研院所以及超算的小伙伴,加入飞桨 AI for Science 共创计划,参与建设基于飞桨的 AI for Science 领域顶尖开源项目和开源社区。
论文复现项目的代码链接为:
https://aistudio.baidu.com/aistudio/projectdetail/5592458
往期推荐
基于数据驱动 U-Net 模型的大气污染物扩散快速预测,提升计算速度近6000倍

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~