一、综合设计目的与要求
合肥工业大学软件工程专业《云计算、大数据技术与应用》课程综合设计报告。
爬取京东或淘宝某一商品的评论1000条,统计词频(使用MapReduce或HBase或Hive),并以词云的方式可视化呈现,最后设计为一套可以操作的系统。
项目采用Electron+Hadoop技术栈实现,前后端使用Socket进行通讯。
二、背景
随着电子商务的快速发展,京东和淘宝成为中国最大的在线购物平台之一。这两个平台上有数亿的商品和海量的用户评论,这些评论包含了大量有价值的信息,可以用于市场调研、用户行为分析和产品改进等方面。然而,对于人工来处理这么大规模的评论数据是非常困难和耗时的,因此需要借助计算机技术来加速和自动化这个过程。
在这个场景中,我们的目标是爬取京东或淘宝某一商品的评论,并对这些评论进行词频统计和可视化呈现。这样的分析可以帮助我们了解消费者对于特定商品的意见和评价,并从中提取出一些关键词或热门话题,以辅助决策和战略制定。
为了实现这个目标,我们可以采用以下技术和工具:
- 爬取评论数据:使用Python编程语言和相关的网络爬虫库(如Requests、Scrapy等),我们可以编写脚本来抓取京东或淘宝商品的评论数据。这涉及到模拟用户行为,发送HTTP请求,解析网页内容,并提取评论信息。
- 存储评论数据:我们可以选择将爬取的评论数据存储在HBase或Hive中。HBase是一个分布式、可伸缩的NoSQL数据库,适合存储大规模的结构化数据。而Hive是基于Hadoop的数据仓库,提供了类似于SQL的查询语言,可以方便地对数据进行处理和分析。
- 统计词频:为了统计评论中的词频,我们可以使用MapReduce编程模型。MapReduce是一种用于处理大规模数据集的分布式计算模型,可以将任务分解为多个并行的计算任务,然后将结果合并起来。我们可以编写MapReduce程序来对评论数据进行处理,将评论拆分为单词,并计算每个单词的出现次数。
- 可视化呈现:最后,为了以词云的方式可视化词频统计结果,我们可以使用Python中的词云生成库(如WordCloud),根据词频生成漂亮的词云图像。词云图像可以直观地展示出评论中出现频率较高的词汇,以及它们之间的关联性。
综上所述,通过爬取京东或淘宝商品的评论,并利用MapReduce或HBase或Hive进行词频统计,再使用词云图像进行可视化呈现,我们可以更好地理解消费者对于特定商品的看法和评价,并从中提取有价值的信息。这个过程可以为企业决策和市场分析提供重要的参考依据。
三、任务分解
1. 数据采集-爬取电商评论数据
2. 数据清洗-清洗电商评论数据
3. 文本分词
4. 上传清洗后的数据到数据库
5. 制作词云
6. WebSocket服务器设计
7. 前端设计与词云渲染
四、准备方案
4.1 实验环境
处理器 AMD Ryzen 9 7900X 12-Core Processor 4.70 GHz
机带 RAM 32.0 GB (31.2 GB 可用)
系统类型 64 位操作系统, 基于 x64 的处理器
所用软件 Eclipse,VMware Workstation Pro17,CentOS 7.0
4.2 爬虫框架
本次实验中,我们使用WebCollector作为爬虫框架。WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。WebCollector是合肥工业大学大数据知识工程教育部重点实验室发起的开源项目,项目开发负责人是胡骏博士。网址:GitHub - CrawlScript/WebCollector: WebCollector is an open source web crawler framework based on Java.It provides some simple interfaces for crawling the Web,you can setup a multi-threaded web crawler in less than 5 minutes.
对于京东评论数据的爬取,一般通过对应的云函数调用完成。云函数的地址中对应的query项productId是产品ID。修改该项即可实现对不同评论数据的爬取。修改pageSize和page即可实现对不同页面的爬取。
具体爬虫代码见附录。
五、实验内容与步骤
5.1 数据上传到HDFS
在完成数据的爬取后,需要将爬虫数据上传到HDFS,以便进一步进行分析。
首先,安装和配置了Hadoop集群。这包括设置好HDFS的相关配置文件,如core-site.xml和hdfs-site.xml,并启动Hadoop集群。
- 在HDFS上创建一个目录,用于存储上传的数据:
| hdfs dfs -mkdir MRDataClean/server_cache |
- 使用以下代码将爬取的数据上传到HDFS上:
try {
FileSystem hdfs;
Configuration conf=new Configuration();
conf.set("fs.default.name", "hdfs://master:9000");
hdfs = FileSystem.get(conf);
Path inFile =new Path("/MRDataClean/server_cache/" + taskId);
FSDataOutputStream outputStream = hdfs.create(inFile);
for(int i = 0 ; i < comments.size(); i ++){
outputStream.writeUTF(comments.get(i).replaceAll("\n", "") + "\n");
}
outputStream.flush();
outputStream.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}上传完毕后,才可以进行下一步的分词操作。
5.2 数据清洗
在上传完成后,首先要进行数据清洗。清洗电商评论数据的目的是消除数据中的噪声、无效信息和冗余内容,使得数据更加干净、准确、可靠,以便进行后续的分析和挖掘。电商评论数据通常包含大量的文本,其中可能存在以下问题:
- 垃圾评论和噪声:电商平台上可能存在一些垃圾评论或无意义的内容,例如广告、垃圾信息、重复内容等。清洗数据可以帮助排除这些干扰因素,使分析结果更加准确和可信。
- 缺失值和异常值:评论数据中可能存在缺失值或异常值,例如缺失的评分、错误的日期或其他非法的数据项。清洗数据可以识别和处理这些问题,以确保数据的完整性和一致性。
- 语言处理和标准化:电商评论可能包含不同的语言、拼写错误、简写或网络用语等。清洗数据可以进行文本处理和标准化操作,如去除标点符号、纠正拼写错误、转换为统一的格式等,以便后续的文本分析和挖掘。
- 敏感信息保护:电商评论中可能包含用户的敏感信息,例如姓名、地址、电话号码等。清洗数据时需要注意保护用户的隐私,对这些敏感信息进行脱敏或删除。
5.3 分词
在完成数据清洗后,需要进行分词、词频统计。这里使用MapReduce模型完成上述操作。
当使用MapReduce进行分词和词频统计时,可以使用Java编程语言来编写Map和Reduce函数。
Mapper代码:
| import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apdachengjieba.*; import java.io.IOException; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
// 创建Jieba分词对象 JiebaSegmenter segmenter = new JiebaSegmenter();
// 对输入文本进行分词 for (SegToken token : segmenter.process(line, JiebaSegmenter.SegMode.INDEX)) { // 过滤掉标点符号等非有效词汇 if (token.word.length() > 1) { word.set(token.word); context.write(word, one); } } } } |
Reducer代码:
| import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;
// 对相同键的值进行累加 for (IntWritable value : values) { sum += value.get(); }
result.set(sum); context.write(key, result); } } |
以上代码中,WordCountMapper类继承了Mapper类,实现了map方法,在该方法中使用了jieba分词库对输入文本进行分词,并将分词结果作为键,值设置为常数1,通过context.write将结果输出。
WordCountReducer类继承了Reducer类,实现了reduce方法,在该方法中对相同键的值进行累加,并将键和最终计数结果输出。
最后,需要编写驱动程序(Driver)来配置和运行MapReduce作业:
| import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) throws Exception { // 创建配置对象和作业对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); // 设置作业的主类、Mapper类和Reducer类 job.setJarByClass(WordCount.class); job.setMapperClass(WordCountMapper.class); job.setCombinerClass(WordCountReducer.class); job.setReducerClass(WordCountReducer.class); // 设置Mapper和Reducer的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 提交作业并等待完成 System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
在上述代码中,WordCount类作为作业的驱动程序,设置了作业的主类、Mapper类、Combiner类和Reducer类,同时指定了输入路径和输出路径。
编译并打包以上代码后,可以使用以下命令将其提交到Hadoop集群上运行:
| hadoop jar WordCount.jar hfut/data hfut/output_data |
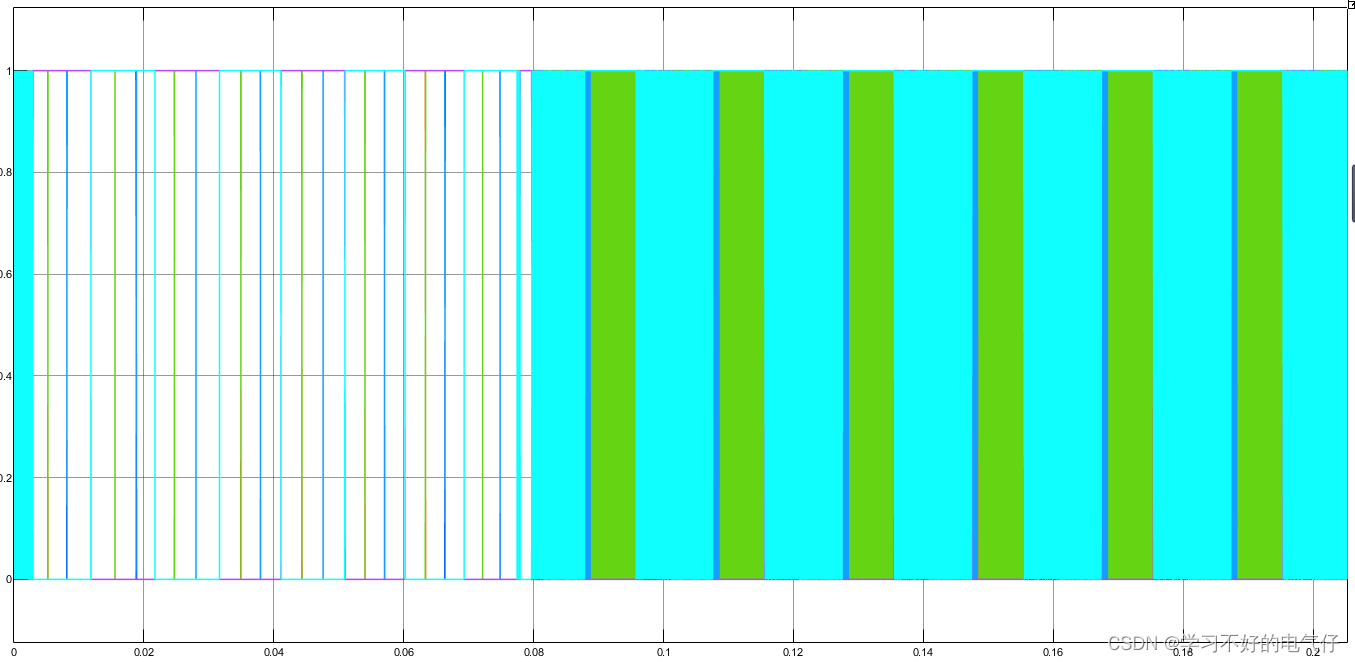
分词的结果如图所示:
5.5 Socket服务器设计
为了使项目服务端、客户端之间能够有一个通信方式,这里采用Socket进行通信。服务端与客户端之间可以通过Socket连接传输工作需求和工作状态。从而实现通信。
创建一个MyServerSocket类,继承Thread类,使得其可以以单独的线程工作,防止其阻塞hadoop工作的主线程。
在run函数中,进行服务器的启动与创建,并等待客户端的连接。
约定客户端连接后以“#StartProgram#{productId}#{pageCount}”传输工作需求,其中productId为商品ID,pageCount为需要爬取的商品评论页数量。
收到传输工作需求后,服务端即调用JdCommentCrawler主类的工作方法,主类会自动开始接下来的一整套工作。
try {
server = new ServerSocket(port);
System.out.println("- 服务已在端口 " + port + "上启动。\n");
//从ServerSocket等待新连接的Socket。
client = server.accept();
System.out.println("- " + client.getInetAddress().getLocalHost() + " 已连接到服务。\n");
is = client.getInputStream();
os = client.getOutputStream();
br = new BufferedReader(new InputStreamReader(is));
bw = new BufferedWriter(new OutputStreamWriter(os));
while(true) {
String newMsg = br.readLine();
if (newMsg != null) {
System.out.println(">> " + newMsg + "\n");
// 判断客户端发来需要爬取的信息来源
if (newMsg.startsWith("#StartProgram")) {
String[] params = newMsg.substring("#StartProgram".length()).split("#");
String productId = params[0];
int pageCount = Integer.parseInt(params[1]);
JdCommentCrawler jcc = new JdCommentCrawler(productId, pageCount);
}
}
}
} catch (IOException e) {
e.printStackTrace();
if (e instanceof java.net.ConnectException)
System.out.println("- 服务启动失败,请重试或更换端口。" + "\n");
else
System.out.println("- 与客户端的连接已断开,服务停止。\n");
} finally {
try {
server.close();
} catch (IOException e) {
e.printStackTrace();
}
}由于后续过程中客户端不需要再给服务端发送请求,但服务端需要给客户端发送大量响应,因此这里对服务端的响应体进行定义,统一采用JSON格式进行发送,如下:
public void sendMsg(String type,String msg) {
System.out.println(msg);
try {
bw.write("{\"type\":\"" + type + "\",\"data\":\"" + msg + "\"}\n|");
bw.flush();
System.out.println("<< " + msg + "\n");
} catch (IOException e) {
e.printStackTrace();
}
}
public void sendMsg(String msg) {
System.out.println(msg);
try {
bw.write("{\"type\":\"" + "message" + "\",\"data\":\"" + msg + "\"}\n|");
bw.flush();
System.out.println("<< " + msg + "\n");
} catch (IOException e) {
e.printStackTrace();
}
}这里定义了sendMsg的两种实现,默认情况下消息的type为message,但调用者也可以手动指定消息的type。
5.6 客户端消息接收
发送工作需求后,客户端应当在有限期内等待服务端的工作与响应。
客户端这里采用Electron技术实现,Electron是一套使用Web相关技术开发桌面端应用的技术,允许使用Node.js在页面中混入原生的代码,从而实现底层功能。
由于这是一个小项目,这里为了开发方便,我们开启原生代码混入。

接下来,进行主界面设计:
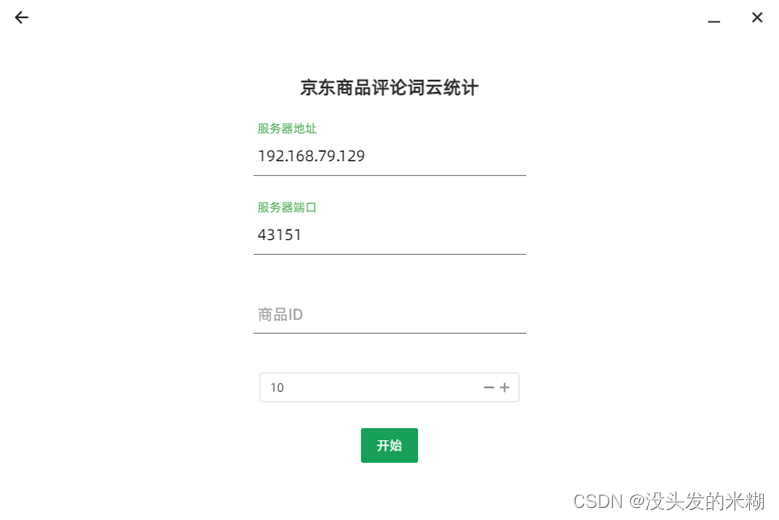
首页要求用户输入服务器地址、端口、商品ID和爬取的页数。
输入完成后,点击开始按钮,即连接到服务器,并向服务器提交工作需求:
var net = require('net');
let results = [];
var client = net.connect({ host: serverIP.value, port: Number(serverPort.value) }, function () {
console.log('连接到服务器!');
client.write("#StartProgram" + productId.value + "#" + pageCount.value + "\n")
});工作需求提交后,应当建立一个接收缓冲区对数据进行接收、分块、处理:
// 使用缓冲区接收大量响应数据,并进行对应的处理。
let cache = "";
client.on('data', function (data) {
let result = data.toString();
let unhandledMessages = [];
cache = cache + result;
if (cache.indexOf("|") != -1) {
unhandledMessages = cache.split("|");
cache = unhandledMessages[unhandledMessages.length - 1];
}
let sentence;
for (let item of unhandledMessages) {
sentence = item;
if (item != "") {
try {
let parsedResult = JSON.parse(item);
// console.log(parsedResult);
if (parsedResult.type == "result") {
let tuple = parsedResult.data.split(" ");
tuple[1] = Number(tuple[1]);
results.push(tuple);
} else if (parsedResult.type == "word") {
popWords.push(parsedResult.data);
} else if (parsedResult.type == "end") {
console.log("end");
message.loading(
"任务已完成,正在渲染词云..."
);
results.sort((a, b) => {
return (a[1] < b[1]);
})
results = results.filter((item) => {
return (stopwords.indexOf(item[0]) == -1);
})
results = results.slice(0, 500);
console.log(results);
setTimeout(() => {
showCloud.value = true;
shownResults.value = results;
}, 1000);
} else {
terminalOutput.value += parsedResult.data + "\n";
}
} catch (e) {
// console.log(sentence);
console.log(e);
}
}
}
});这段代码主要负责消息的接收、处理、渲染。消息接收过程中的UI如下图所示:

这里为了更好的使用体验和效果,还将Hadoop分词过程中产生的词传送到了前端,并进行了动画展示:

分词工作结束后,会进入到最后页面,进行词云的渲染与绘制。
5.7 词云绘制
首先需要将分词和词频统计结果从HDFS中读出:
server.sendMsg("STEP 4 分词完成");
String result = "";
Path path = new Path("hdfs://master:9000/MRDataClean/server_cache/out/" + taskId + "/part-r-00000");
Configuration configuration = new Configuration();
FSDataInputStream fsDataInputStream = null;
FileSystem fileSystem = null;
BufferedReader br = null;
// 定义一个字符串用来存储文件内容
try {
fileSystem = path.getFileSystem(configuration);
fsDataInputStream = fileSystem.open(path);
br = new BufferedReader(new InputStreamReader(fsDataInputStream));
String str2;
while ((str2 = br.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
server.sendMsg("result", str2.replace(" ", " "));
}
} catch (IOException e) {
e.printStackTrace();
}词云绘制采用Vue-WordCloud这个组件进行渲染。在渲染时,选取前500个词,并剔除stop_words。
message.loading(
"任务已完成,正在渲染词云..."
);
results.sort((a, b) => {
return (a[1] < b[1]);
})
results = results.filter((item) => {
return (stopwords.indexOf(item[0]) == -1);
})
results = results.slice(0, 500);
console.log(results);
setTimeout(() => {
showCloud.value = true;
shownResults.value = results;
}, 1000);渲染结果如下图所示:


-
- 服务端转入下一工作流程状态
服务端在完成本次工作需求后,应当关闭连接,并转入下一流程状态,等待全新的连接进入。
server.sendMsg("STEP 5 结果传送完成");
server.sendMsg("end","");
server.close();
server = new MySocketServer(port);六、结果分析与感悟
- 数据采集-爬取电商评论数据:在这个实验中,我使用了Java编程语言和WebCollector来实现爬取京东上的电商评论数据。
- 数据清洗-清洗电商评论数据:在完成数据采集后,我对爬取到的电商评论数据进行了清洗对评论文本进行处理,去除不必要的内容,并保留有意义的文本数据。
- 文本分词:在清洗后的电商评论数据上,我进行了文本分词的处理。通过使用Java中的分词库,如IKAnalyzer或jieba,我将评论文本进行分词,将长句子或段落切分成词语的序列。这样可以将文本数据转化为词语的集合,方便后续的词频统计和词云生成。
- 上传清洗后的数据到数据库:将清洗后的电商评论数据上传到MySQL数据库中。通过Java程序连接到数据库,创建表格和字段,然后将清洗后的评论数据逐条插入到数据库表中。这样可以方便地对数据进行存储和后续的分析。
- 制作词云:使用词云生成库,如WordCloud,我将清洗和分词后的评论数据制作成了词云。通过设置字体、颜色和布局等参数,我调整了词云的外观,使其更加美观和易于理解。最后,将生成的词云以图像文件或通过Web控制器直接返回给用户,供用户进行可视化分析和观察。
通过这个实验,我学到了如何使用Java编程语言和Web控制器进行数据采集、数据清洗、文本分词、数据库操作和词云生成等方面的知识和技能。这些技能对于实际的数据处理和分析工作非常有帮助,也为我未来在软件开发和数据科学领域的工作提供了基础。
完成这个实验的过程中,我学到了很多关于网络爬虫和数据可视化的知识和技巧。通过编写爬虫程序,我深入了解了HTTP请求和网页解析的原理,提高了对网页结构和内容的理解能力。
此外,通过制作词云,我能够更加直观地观察和分析文本数据。词云可以将文本信息以图形化的方式展示出来,使我能够更好地捕捉到其中的关键信息和趋势。
在实验中,我还学会了如何处理和清洗文本数据,以及如何调整词云的外观。这些技能对于日后进行数据处理和可视化工作将非常有用。
总的来说,这个实验让我在网络爬虫和数据可视化方面有了实际的经验,并且提高了我对文本数据分析的能力。我相信这些技能和经验将对我的学习和职业发展产生积极的影响。
最后,感谢吴共庆老师在《云计算、大数据技术及应用》这门课程中传授的理论知识与工程技能,使得我能够顺利地完成本次综合设计。
七、附录
7.1 项目地址
该项目已在github上发布,项目地址为:GitHub - RicePasteM/JdCommentCrawler: JdCommentCrawler - 基于Hadoop与Electron的京东商品评论词云统计系统。
欢迎互相学习与交流!