mongoDB基础知识
MongoDB的三个核心特性:灵活设计(No Schema)、高可用和分布式(可平行扩展),另外MongoDB自带数据压缩功能,使得同样的数据存储所需的资源更少。
No Schema(BJSON)
MongoDB 是文档型数据库,其文档组织结构BSON(Binary Serialized Document Format) 是类JSON的二进制存储格式,数据组织和访问方式完全和JSON一样。支持动态的添加字段、支持内嵌对象和数组对象。
No Schema特性带来的好处包括:
- 简化开发:MongoDB文档自然映射到现代的面向对象编程语言。使用MongoDB可以避免将代码中的对象转换为关系表的复杂对象关系映射(ORM)层。
- 便于开发和快速迭代:灵活的字段管理,使得项目迭代新增字段非常容易
- 降低运维成本:数据对象结构变更不需要执行DDL语句,降低Online环境的数据库操作风险,特别是在海量数据分库分表场景。
高可用性(复制集)
mongodb的高可用性是通过副本集+选举机制(raft 协议)来实现的。
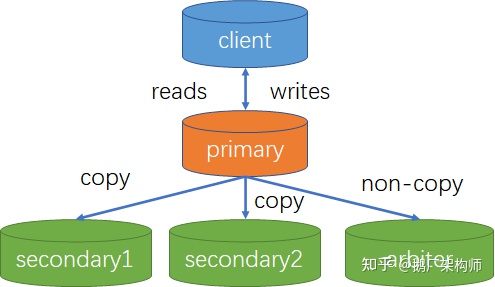
- primary:主节点,接收所有写操作,并将集合的变化记录到操作日志oplog中,同步到从节点。
- secondary:从节点。
复制集的作用:
- 主节点发生故障时自动选举出一个新的主节点,以实现 failover机制(当A无法为客户服务时,系统能够自动地切换,使B能够及时地顶上继续为客户提供服务,且客户感觉不到这个为他提供服务的对象已经更换)。
- 将数据从一个数据中心复制到另一个数据中心,减少另一个数据中心的读延迟。
- 实现读写分离。
- 实现容灾,可以在数据中心故障时快速切换到同城或异地的数据中心。
复制集群确保数据一致性的核心设计是:
-
Journal日志:Journal日志是 MongoDB 的预写日志 WAL,类似 MySQL 的 redo log,然后100ms一次将Journal 日志刷盘。当然触发机制还有其它场景,这里仅仅是讨论异常场景下可能丢失多长时间的数据。更多详细的解释可以参考MongoDB的两种日志journal与oplog
-
**Oplog:**Oplog 是用来做主从复制的,类似 MySql 里的 binlog。MongoDB 的写操作都由 Primary 节点负责,Primary 节点会在写数据时会将操作记录在 Oplog 中,Secondary 节点通过拉取 oplog 信息,回放操作实现数据同步。
-
**Checkpoint:**上面提到了 MongoDB 的写只写了内存和 Journal 日志(Journal 日志是WAL日志),并没有做数据持久化到数据文件中,Checkpoint 就是将内存变更刷新到磁盘持久化的过程。MongoDB 会每60s一次将内存中的变更刷盘,并记录当前持久化点(checkpoint),以便数据库在重启后能快速恢复数据。
-
**节点选举:**MongoDB 的节点选举规则能够保证在Primary挂掉之后选取的新节点一定是集群中数据最全的一个。
从上面4点我们可以得出 MongoDB 高可用的如下结论:
- MongoDB 宕机重启之后可以通过 checkpoint 快速恢复上一个60s之前的数据。
- MongoDB 最后一个 checkpoint 到宕机期间的数据可以通过 Journal 日志回放恢复。
- Journal 日志因为是100ms刷盘一次,因此至多会丢失100ms的数据(这个可以通过 WriteConcern 的参数控制不丢失,只是性能会受影响,适合可靠性要求非常严格的场景)
- 如果在写数据开启了多数写,那么就算 Primary 宕机了也是至多丢失100ms数据(可避免,同上)
可扩展性(分片集)
MongoDB 支持通过分片技术来支持海量数据存储。解决数据增长的扩展方式有两种:垂直扩展和水平扩展。
- 垂直扩展:通过增加单个服务器的能力来实现,比如磁盘空间、内存容量、CPU 数量等;
- 水平扩展:通过将数据存储到多个服务器上来实现。
MongoDB 通过分片实现水平扩展

- shard:每个分片上可以保存一个集合的子集,所有分片上的子集的数据互不相交,构成完整的集合。每个分片可以被部署为复制集架构。最大为 1024 个分片。
- mongos:充当查询路由器,在客户端和分片集之间提供读写接口。mongos 提供集群单一入口,转发应用端请求,选择合适的数据节点进行读写,合并多个数据节点的返回。 mongos 是无状态的,分片集群一般需要配置至少 2 个 mongos。
- config server:存储分片集的相关配置信息。
通过分片集,mongodb自带的分布式特性使得使用者不需要像MySQL那样考虑分库分表的繁琐问题。
MongoDB 支持两种分片算法来满足不同的查询需求:
- **区间分片:**可以按 shardkey 做区间查询的分片算法,直接按照 shardkey 的值来分片。
- **hash分片:**用的最多的分片算法,按shardkey 的 hash 值来分片。hash 分片可以看作一种特殊的区间分片。
数据压缩
MongoDB 的另外一个比较重要的特性是数据压缩,MongoDB 会自动把客户数据压缩之后再落盘,这样就可以节省存储空间。
MYSQL与MongoDB对比
虽然MongoDB和Redis同为NoSQL类型的数据库,但二者差别比较大,
- Redis一般用作缓存,存储结构比较简单,支持string、hash、set等少数几种类型。
- MongoDB一般用作数据库,存储结构分成数据库、集合、文档这三个层级,而文档以BSON形式存储数据。
因此MongoDB应该与MySQL进行对比,分析二者的优缺点和适用场景,从而可以为自己的系统选择更合适的数据库。
几十年来,关系型数据库已经成为企业应用程序的基础,自从MySQL在1995年发布以来,它已经成为一种受欢迎并且廉价的选择。然而随着近年来数据量和数据的不断激增,非关系数据库技术如MongoDB应运而生,以满足新应用的需求,以及扩充或替换现有的关系型数据库。
关键字对比
| MySQL | MongoDB | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 表/集合 |
| row | document | 行/文档 |
| column | field | 字段/域 |
| index | index | 索引 |
| join | 嵌入文档 | 表关联/MongoDB不支持join,MongoDB通过嵌入式文档来替代多表连接 |
| primary key | primary key | 主键/MongoDB自动将_id字段设置为主键 |
MYSQL概述
MySQL是由Oracle公司开发,发布和支持的受欢迎的开源关系数据库管理系统(RDBMS)。
- MySQL将数据存储在表中,并使用结构化查询语言(SQL)来进行数据库访问。
- MySQL可以根据需要预先定义数据库模式,并设置规则来管理表中字段之间的关系。
- 在MySQL中,相关信息可能存储在单独的表中,但通过使用关联查询来关联。通过使用这种方式,使得数据重复量被最小化。
MongoDB概述
MongoDB由 C++ 编写,是基于分布式的、面向文档存储的非关系型数据库,是非关系型数据库当中功能最丰富、最像关系数据库的,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
- MongoDB将数据存储在类似JSON的文档中,通过MongoDB查询语言进行快速查询访问。
- 文档的JSON结构可以轻松地代表层次关系,存储数组和其他更复杂的结构。
- MongoDB使用动态模式,可以在不首先定义结构的情况下创建文档,例如字段或其值的类型。集合中的文档不需要具有相同的一组字段,数据的非规范化是常见的,每个文档的json串结构可能有所不同 。
- MongoDB还设计了高可用性和可扩展性,并提供了即用型复制和自动分片功能。
MongoDB 最大的特点是支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
优点
- MongoDB天然特性:灵活、高可用、高可扩展。
- 在适量级的内存的MongoDB的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。
缺点
- 不支持事务操作。MongoDB本身没有自带事务机制,需要自己实现。因此不保证一致性,不能用于银行交易等复杂业务。
- mongodb的数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,这样提高查询效率,同时也会占用大量的内存。
- 应用经验少,由于NoSQL兴起时间短,应用经验相比关系型数据库较少。
参考文章
MongoDB 学习笔记: BSON 结构分析
万字详解,吃透 MongoDB!
MySQL 和 MongoDB 对比,一文看全
MongoDB 高性能、高可用之副本集、读写分离、分片、操作实践
MongoDB 基础浅谈
MongoDB - 全方位知识图谱