目录
1,htmlcxx Github 版本源码下载
2,htmlcxx Linux 版本源码下载
3,htmlcxx 解析例子
1,htmlcxx Github 版本源码下载
正如在前一篇文章 c++ CFile 类 里提到的,我想要从指定的 html 文件里提取代码,今天终于实现了,用到了开源的 htmlcxx 库。这个开源库可以在 github htmlcxx 上下载,但这个github 上的代码似乎是 window 版本的,它带了 window 的项目文件,而没有 Linux 下的 configure 或是Makefile,如:
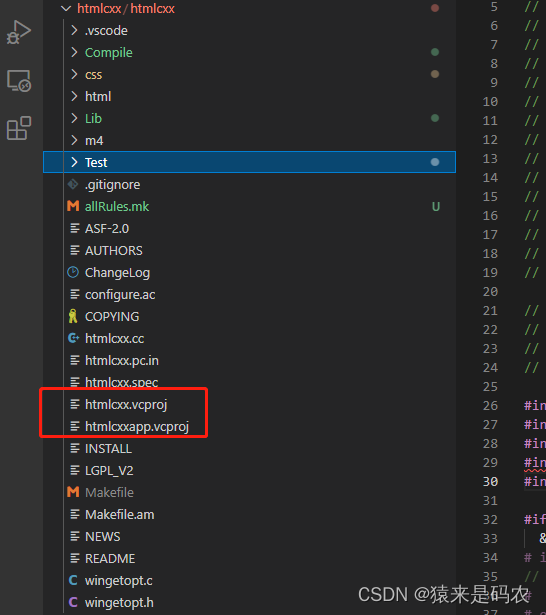
如果你是Linux 开发的话,得自己写 Makefile 来编译了,这里是我的 Makefile 文件:
#Makefile 文件
CPP = @echo "g++ $@"; g++ -std=c++11
CC = @echo "gcc $@"; gcc
LD = @echo "ld $@";ld
AR = @echo "ar $@";ar
RM = rm -f
STRIP = @echo "strip $@";strip
CFLAGS += -Wall -O2 -Os
CFLAGS += -g
LDFLAGS = "-Wl", -pthread -lc -static
AFLAGS += -r
include ./allRules.mk以及 allRules.mk 文件
#allRules.mk 文件
WORK_DIR = $(shell pwd)
#源码目录
SRCS_PATH = css \
html
COMPILE_PATH ?= Compile
LIB_NAME = Htmlcxx
LIB_PATH = Lib
##生成目标库目录
STATIC_LIB_TARGET = $(LIB_PATH)/lib$(LIB_NAME).a
TARGET = $(STATIC_LIB_TARGET)
#cpp源文件
LIB_SRCS_CPP = $(foreach dir, $(SRCS_PATH), $(wildcard $(dir)/*.cc))
LIB_SRCS_C = $(foreach dir, $(SRCS_PATH), $(wildcard $(dir)/*.c))
SRCS = $(LIB_SRCS_CPP) $(LIB_SRCS_C)
#目标文件
LIB_CPP_OBJS = $(patsubst %.cc, $(COMPILE_PATH)/%.o, $(LIB_SRCS_CPP))
LIB_C_OBJS = $(patsubst %.c, $(COMPILE_PATH)/%.o, $(LIB_SRCS_C))
LIB_OBJS = $(LIB_CPP_OBJS) $(LIB_C_OBJS)
DEP_CPP := $(LIB_CPP_OBJS:%.o=%.cc.d)
DEP_C := $(LIB_C_OBJS:%.o=%.c.d)
DEP_ALL = $(DEP_CPP) $(DEP_C)
all: $(TARGET)
@echo $(TARGET)
$(foreach dir, $(SRCS_PATH), $(shell mkdir -p $(COMPILE_PATH)/$(dir)))
$(shell mkdir -p $(LIB_PATH))
-include $(DEP_ALL)
$(TARGET): $(LIB_OBJS)
$(RM) $@
$(AR) $(AFLAGS) -o $@ $(LIB_OBJS)
test:
$(MAKE) -C Test
############################################
$(COMPILE_PATH)/%.o: %.cc
$(CPP) -c $(CFLAGS) $< -o $@ -lpthread
$(COMPILE_PATH)/%.o: %.c
$(CC) -c $(CFLAGS) $< -o $@ $(LDFLAGS)
###################################################
$(COMPILE_PATH)/%.cc.d: %.cc
$(CPP) $(CFLAGS) -MM -E $^ > $@
@sed 's/.*\.o/$(subst /,\/, $(dir $@))&/g' $@ >$@.tmp
@mv $@.tmp $@
$(COMPILE_PATH)/%.c.d: %.c
$(CPP) $(CFLAGS) -MM -E $^ > $@
@sed 's/.*\.o/$(subst /,\/, $(dir $@))&/g' $@ >$@.tmp
@mv $@.tmp $@
############################ clean ############################
PHONY: clean
clean:
$(RM) -r $(TARGET) $(COMPILE_PATH)
编译成静态库,如下:
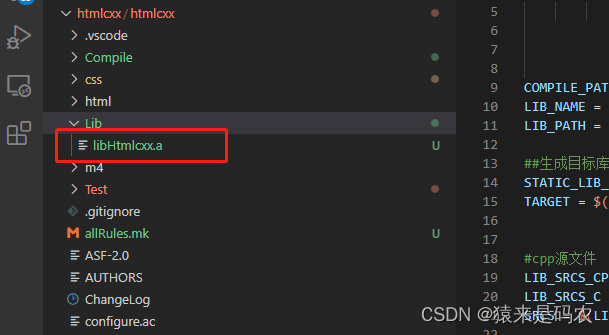
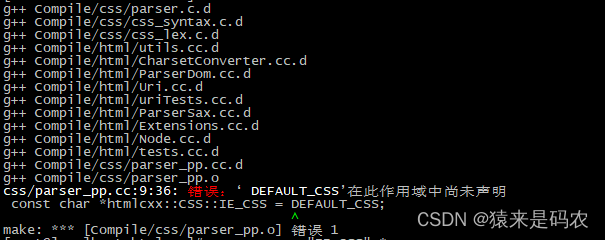
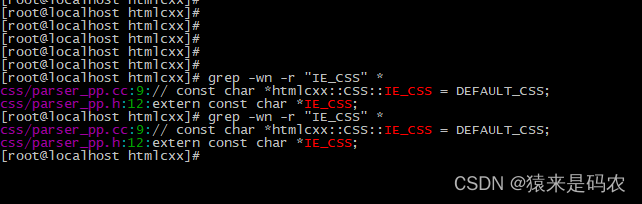
编译过程会遇到一个错误,这个在 window 下应该不会遇到, 搜索了一下这个宏是没地方用到的,所以直接注释掉就行了。
2,htmlcxx Linux 版本源码下载
这个地址 htmlcxx linux 版本源码 下载的就是 Linux 版本的,没有依赖库,解压后,进到目录里执行: ./configure;make 直接编译出来的是动态库,然后 make install,或者你不想 install 的话,那在编译例子的时候就要指定头文件路径,库路径,因为是动态库,所以在运行前还得设置动态库搜索路径: export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:库的绝对路径,否则会提示找不到 so 库文件而运行失败的。
3,htmlcxx 解析例子
下面是源码,方法很简单,就是从文件里一行一行的提取出来,然后调用 htmlcxx 库接口进行解析,解析出来后把内容写到文件里。Makefile 及源码如下:
#中间文件存放目录,如.o 和 .d 文件
COMPILE_DIR = compile
BIN_DIR = bin
# 可编译arm版本
# CROSS = arm-himix200-linux-
CC = $(CROSS)gcc
CPP = $(CROSS)g++ -std=c++11
CFLAGS = -g -Wall
CFLAGS += -I../html
CFLAGS += -I../css
LIB_DIR = -L../Lib -lHtmlcxx
# INCLUDE = -I../threadpool/include
# LIB = -L../threadpool/lib/x86 -lpthread -lThread
# SRCS_CPP = $(wildcard *.cpp)
SRCS_CPP = $(shell ls -t | grep "\.cpp$$" | head -1)
OBJS = $(patsubst %.cpp, $(COMPILE_DIR)/%.o, $(SRCS_CPP))
DEP = $(patsubst %.o, %.d, $(OBJS))
$(shell if [ ! -d $(COMPILE_DIR) ]; then mkdir $(COMPILE_DIR); fi)
$(shell if [ ! -d $(BIN_DIR) ]; then mkdir $(BIN_DIR); fi)
TARGET=$(BIN_DIR)/a.out
all: $(TARGET)
-include $(DEP)
$(TARGET): $(OBJS)
$(CPP) $(INCLUDE) $(CFLAGS) $^ -o $@ $(LIB) $(LIB_DIR)
$(COMPILE_DIR)/%.o: %.cpp $(COMPILE_DIR)/%.d
$(CPP) $(INCLUDE) $(CFLAGS) -c $< -o $@ $(LIB)
$(COMPILE_DIR)/%.d: %.cpp
@$(CPP) $(INCLUDE) $(CFLAGS) -MM -E -c $< -o $@
@sed 's/.*\.o/$(subst /,\/,$(dir $@))&/g' $@ > $@.tmp
@mv $@.tmp $@
.PHONY: clean
clean:
rm -rf $(COMPILE_DIR) $(BIN_DIR)
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <fstream>
#include <memory>
#include "ParserDom.h"
void initMap();
bool isAllSpace(std::string &str);
void eraseAllSpace(std::string &str);
int getLineInfo(std::string &lineStr);
bool htmlParse(std::string &htmlStr, FILE *file);
bool readFile(const char *fileName, const char *outFile);
bool findLineInfo(std::string &lineStr, std::string &findStr);
using namespace std;
using namespace htmlcxx;
#define TABSTOP 4
struct ESCAPECHAR_INFO
{
ESCAPECHAR_INFO(size_t len, std::string ch): mLen(len), mOriCh(ch)
{
}
size_t mLen; //转义字符的长度
std::string mOriCh;//真实的字符
};
//原本想定义成<ESCAPECHAR_INFO, st::string> 但自定义类型要重载"<",否则编译不过的
std::map<std::string, ESCAPECHAR_INFO> escapeCharMap;
int main(int argc, char *argv[])
{
if(argc != 2)
{
printf("Usage: %s file\n", argv[0]);
return -1;
}
std::string outFile(argv[1]);
size_t pos = outFile.find(".");
size_t len = outFile.length();
if(pos != std::string::npos)
{
outFile.replace(pos + 1, len - pos, "cc");
}
initMap();
readFile(argv[1], outFile.c_str());
return 0;
}
//常用的转义字符表,遇到再添加吧
void initMap()
{
escapeCharMap.insert(std::pair<std::string, ESCAPECHAR_INFO>("<", ESCAPECHAR_INFO(4, "<")));
escapeCharMap.insert(std::pair<std::string, ESCAPECHAR_INFO>(">", ESCAPECHAR_INFO(4, ">")));
escapeCharMap.insert(std::pair<std::string, ESCAPECHAR_INFO>(""", ESCAPECHAR_INFO(6, "\"")));
escapeCharMap.insert(std::pair<std::string, ESCAPECHAR_INFO>("&", ESCAPECHAR_INFO(5, "&")));
escapeCharMap.insert(std::pair<std::string, ESCAPECHAR_INFO>("'", ESCAPECHAR_INFO(5, "'")));
}
bool readFile(const char *fileName, const char *outFile)
{
FILE *fp = nullptr;
if((fp = fopen(fileName, "r")) == nullptr)
{
printf("fopen error: %s", strerror(errno));
return false;
}
FILE *saveFp = fopen(outFile, "w");
fseek(fp, 0, SEEK_END);
long len = ftell(fp);
fseek(fp, 0, SEEK_SET);
char buf[4] = {0};
size_t ret = 0;
size_t readSize = 0; //已经读取的字符总数
size_t totalLine = 0; //总行数
size_t curPos = 0; //当前位置
size_t tempPos = 0; //保存上一次位置
size_t curLineLen = 0; //当前行长度,用于申请内存
size_t nilLine = 0; //空行总数
size_t srcTotalLine = 0; //源码总行数
size_t lineIndex = 1; //源码行计数
bool found = false; //是否找到源码行数信息
bool lineIdxFound = false; //每行源码都会有一个对应行号
while(len - readSize > 0)
{
if((ret = fread(buf, 1, 1, fp)) != 0)
{
readSize += ret;
if(strcmp(buf, "\n") == 0)
{
tempPos = curPos;
curPos = ftell(fp);
totalLine++;
curLineLen = curPos - tempPos;
if(curLineLen > 1)
{
fseek(fp, -(curLineLen), SEEK_CUR);
std::shared_ptr<char> ptr(new char[curLineLen], std::default_delete<char[]>());
memset(ptr.get(), 0, curLineLen);
fread(ptr.get(), curLineLen, 1, fp);
std::string str(ptr.get(), curLineLen);
//已经找到这里不再进来
if(srcTotalLine == 0 && found)
{
found = false;
srcTotalLine = getLineInfo(str);
}
//同上
std::string tmp("text-mono");
if(srcTotalLine == 0 && findLineInfo(str, tmp))
{
// printf("find the src line = %u\n", totalLine);
found = true;
}
//当下面找到倒数第2个的时候,这里的lineIndex已经是+1的值了,如果
//直接和srcTotalLine比较就直接break了,实际是少了2行,因为我们总是
//取下一行的内容
if(lineIndex == srcTotalLine + 2)
{
break;
}
if(srcTotalLine)
{
char buf[256] = {0};
//这里找到之后取的是下一行的内容,因为下面是lineIndex++,在这里用的时候已经是+1后的值
snprintf(buf, sizeof(buf), "data-line-number=\"%u\"", lineIndex);
if(lineIdxFound)
{
lineIdxFound = false;
htmlParse(str, saveFp);
}
if(str.find(buf) != std::string::npos)
{
lineIdxFound = true;
lineIndex++;
}
}
}
else
{
nilLine++;
}
}
memset(buf, 0, sizeof(buf));
}
}
fclose(fp);
fclose(saveFp);
return true;
}
//找到html里行数相关的信息
bool findLineInfo(std::string &lineStr, std::string &findStr)
{
return (lineStr.find(findStr) != std::string::npos);
}
//取得源码总行数,html里有标示源码总行籹
int getLineInfo(std::string &lineStr)
{
eraseAllSpace(lineStr);
//这里直接用 atoi 比较合适,它在遇到第一个不是数字时返回
//正好是我需要的
int srcLine = atoi(lineStr.c_str());
printf("src Total Line = %d\n", srcLine);
return srcLine;
}
//清空所有空格
void eraseAllSpace(std::string &str)
{
size_t index = 0;
while((index = str.find_first_of(" ")) != std::string::npos)
{
str.erase(index, 1);
}
}
//转义字符
void escapeChar(std::string &str)
{
size_t index = 0;
for(auto ite : escapeCharMap)
{
while((index = str.find(ite.first.c_str())) != std::string::npos)
{
str.replace(index, ite.second.mLen, ite.second.mOriCh.c_str());
}
}
}
//是否全部是空格,太长空格不写入文件
bool isAllSpace(std::string &str)
{
size_t index = 0;
size_t len = str.length();
if(len <= TABSTOP)
{
return false;
}
for(; index < len; index++)
{
if(str[index] != ' ')
{
break;
}
}
return index == len;
}
//用htmlcxx里的例子,稍等修改一下
bool htmlParse(std::string &htmlStr, FILE *saveFp)
{
//Parse some html code
HTML::ParserDom parser;
tree<HTML::Node> dom = parser.parseTree(htmlStr);
//Dump all links in the tree
tree<HTML::Node>::iterator it = dom.begin();
tree<HTML::Node>::iterator end = dom.end();
//Dump all text of the document
it = dom.begin();
end = dom.end();
for (; it != end; ++it)
{
if ((!it->isTag()) && (!it->isComment()))
{
std::string srcStr(it->text());
if(isAllSpace(srcStr))
{
continue;
}
// 转义字符处理一下
escapeChar(srcStr);
fwrite(srcStr.c_str(), srcStr.length(), 1, saveFp);
}
}
return true;
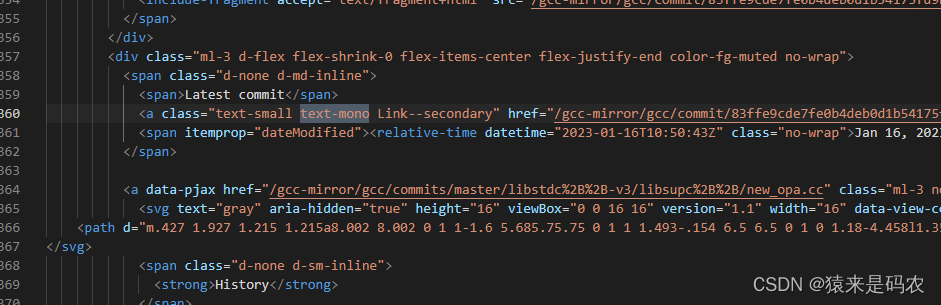
}首先看一下实际 github 上源码的那个页面,如下:
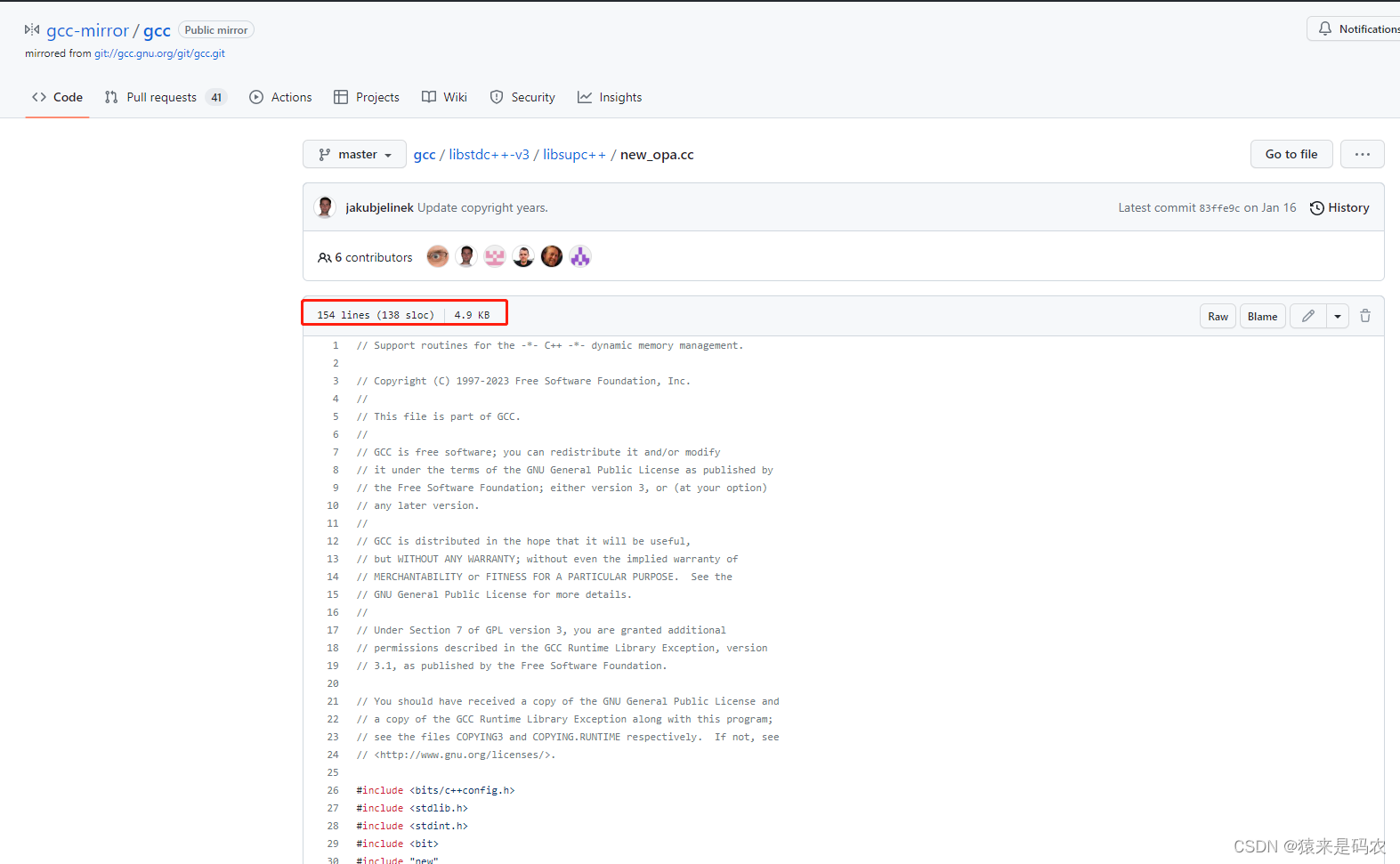
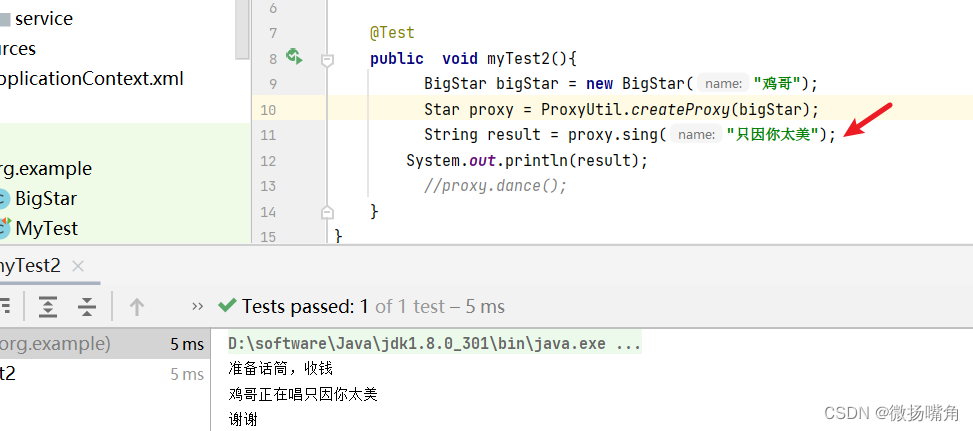
红框那里指明了源码是 154 行,用上面代码执行的结果如下:
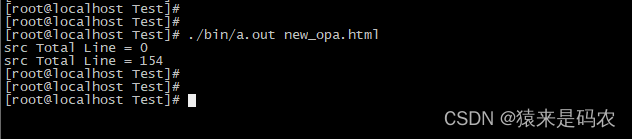
因为代码里是通过搜索"text-mono" 来找到源码的行数的,那搜索的这个文件里明显有两个"text-mono",但这里执行也没有关系,因为0也不会做什么:

最终写到文件里的代码就是这样子了:
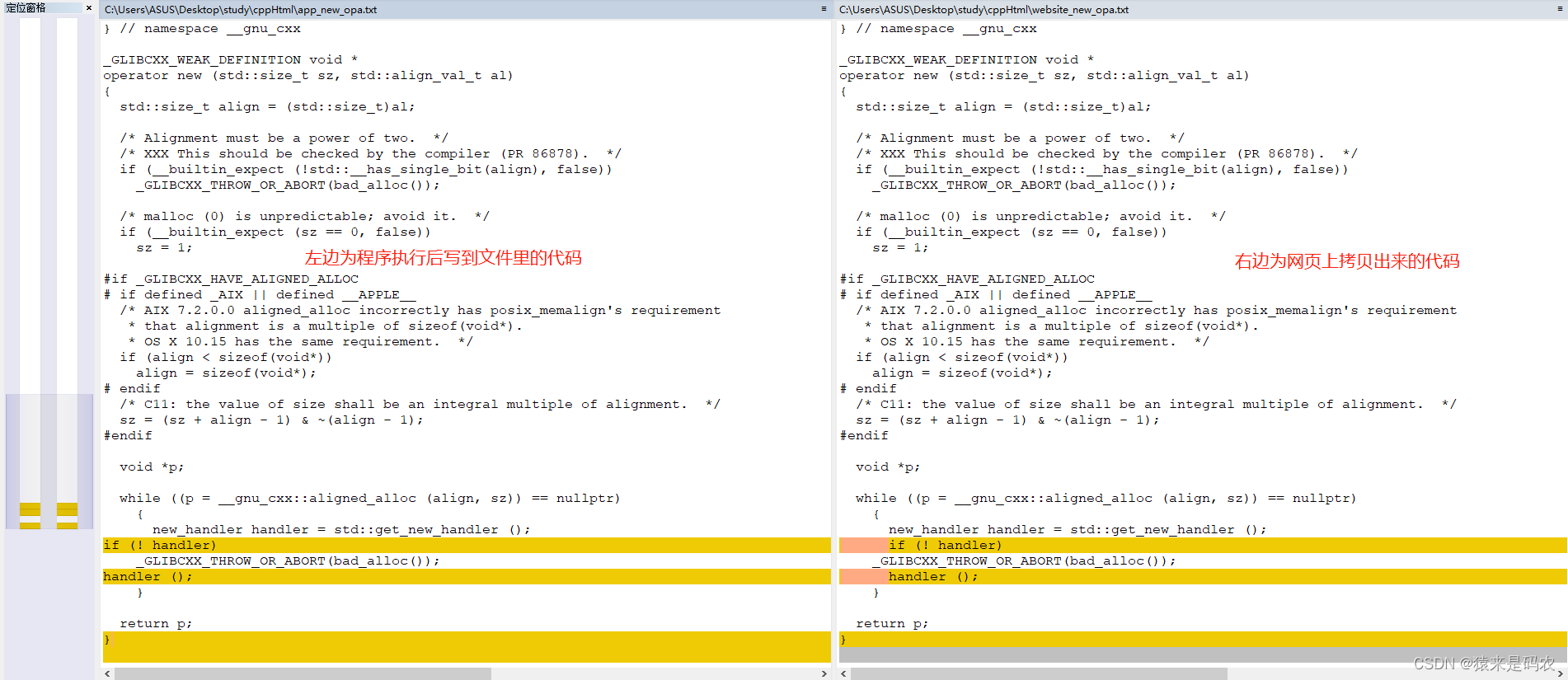
其实相差得不多,基本就是格式问题。下面再以这个1357 行代码的 debug.cc 为例,先下载再解析。
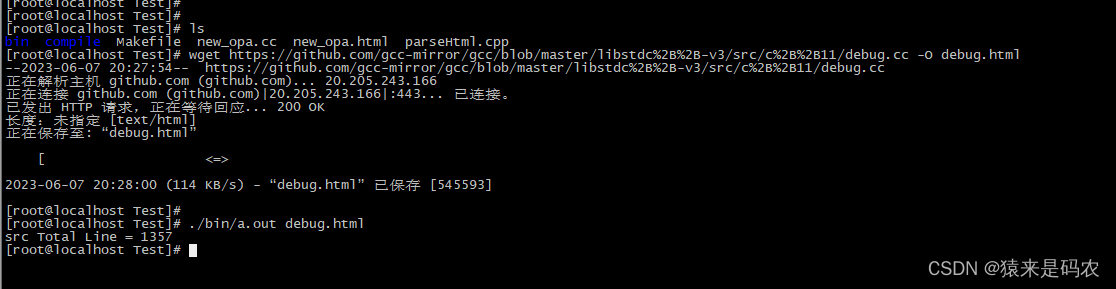
然后我从网页上拷贝源码下来,然后跟程序执行的结果进行一下比较,内容是一样的,只是格式上有点区别:
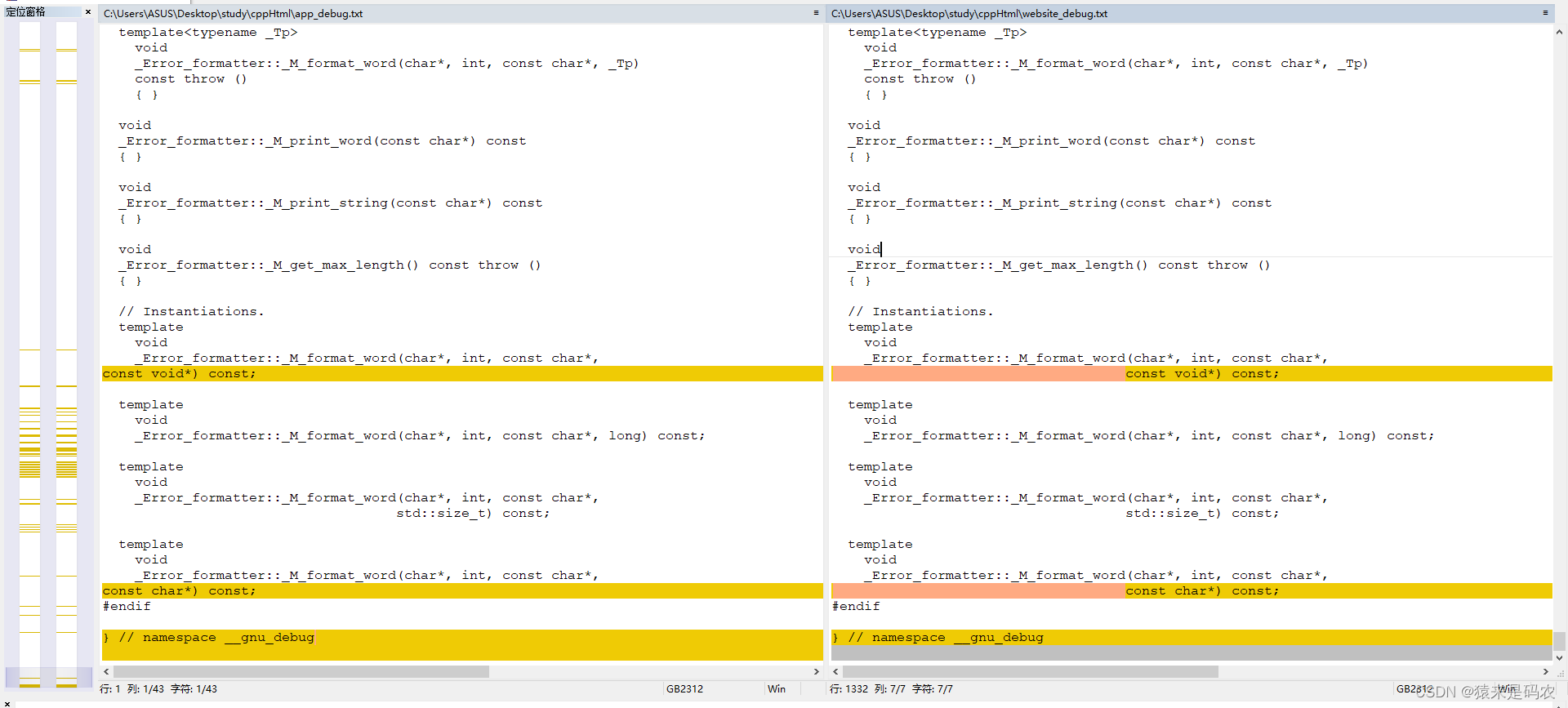
总结:这个好像没有多大的实际意义,因为很少有人想单个文件下载,即使想要单个文件的源码,也是在页面上去拷贝,但如果这个源码比较大,如上面的1357行源码,拷贝起来也是不容易的,这个时候有个自动提取代码的程序应该是个不错的选择。只需要用 wget 下载下来,再用程序执行一下就可以了。