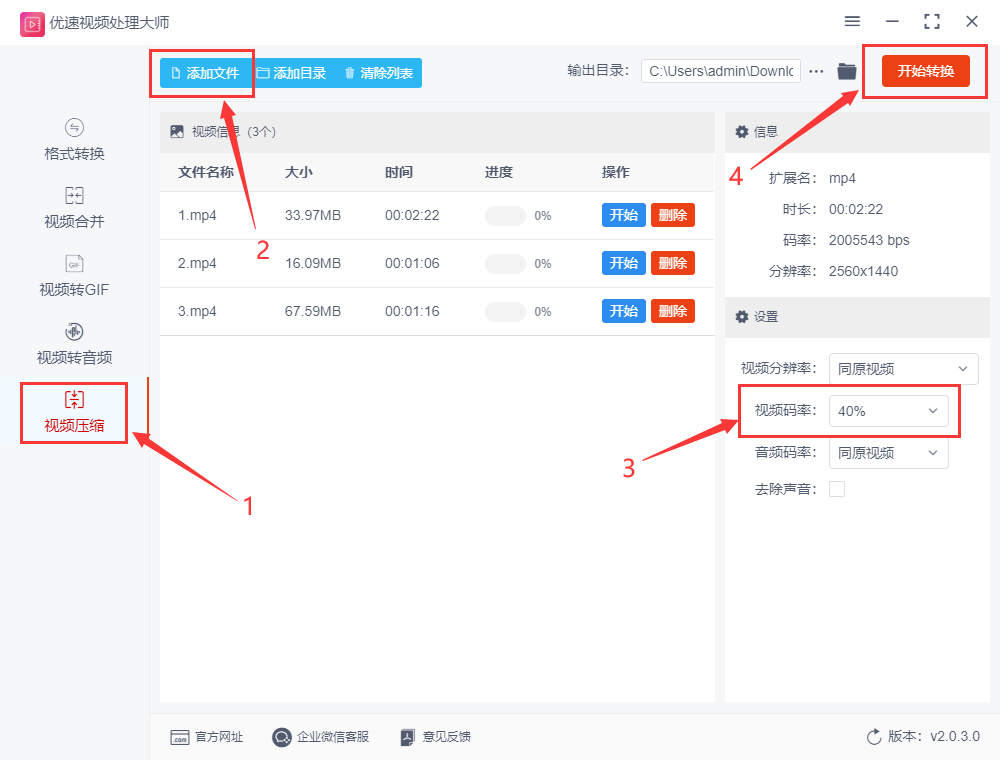
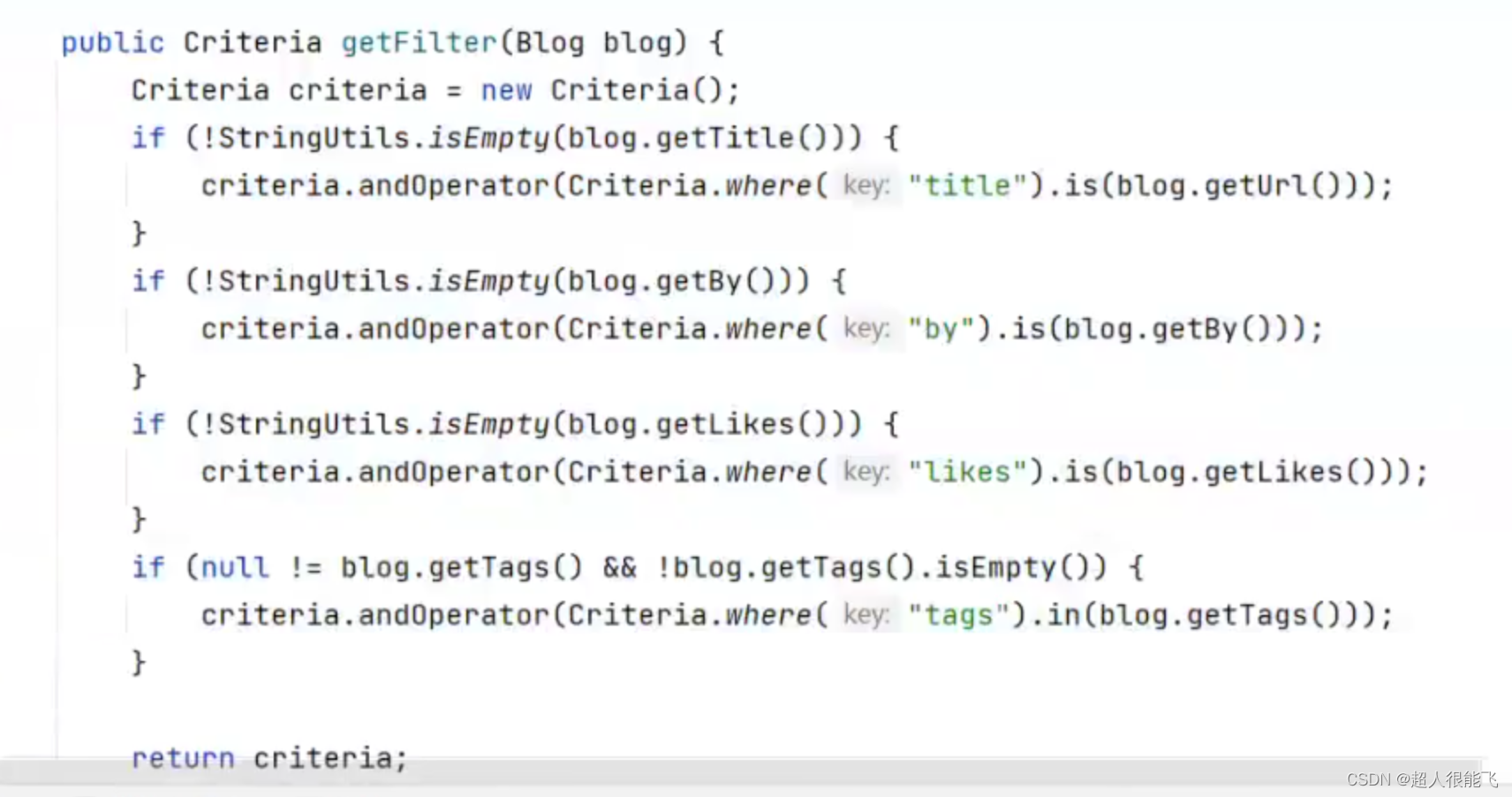
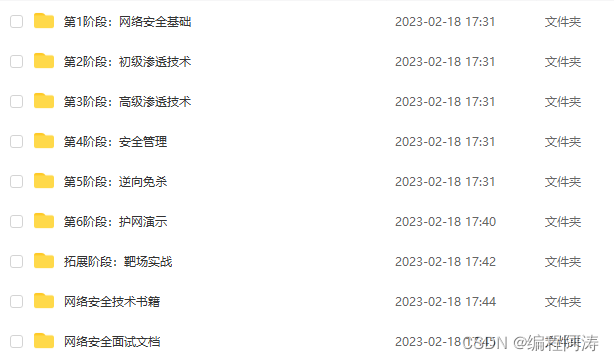
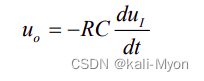1. 引言
主要见Ying Tong在Research Day 2023上视频分享:
- Advances in the Efficiency of Succinct Proofs - Ying Tong
ZKP技术可用于:
- 1)Verifiable virtual machine:如各种zkEVM和zkVM。
- 2)verifiable cloud computing:
2015年论文《Cluster Computing in Zero Knowledge》[CTV15]中使用了recursive proof composition和Proof-Carrying Data ZKP技术,专注于实现zkMapReduce(a distributed SNARK for MapReduce),从而未来可实现zkML(zero-knowledge Machine Learning)。


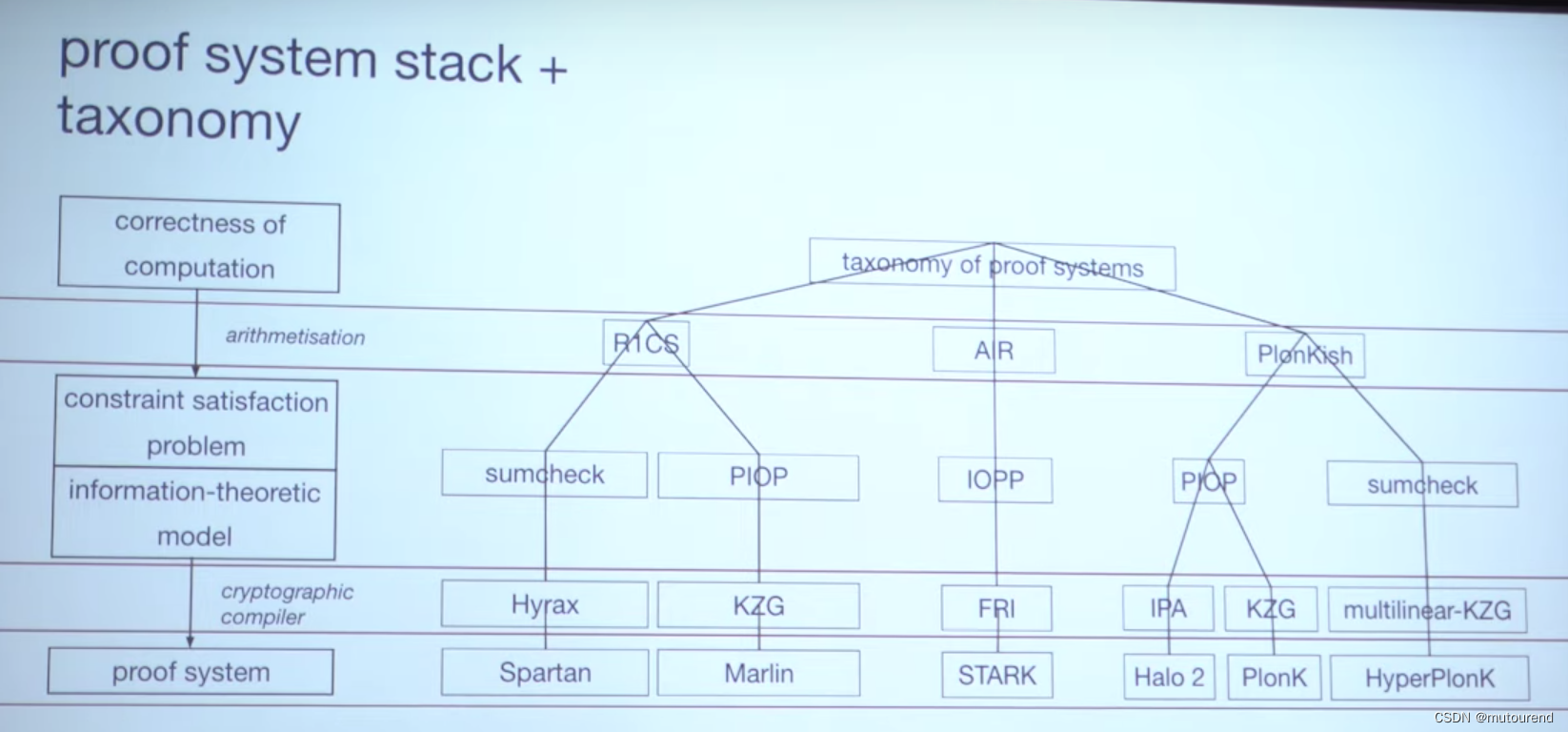
2. ZKP系统栈及分类
ZKP系统栈主要层次为:
- 1)correctness of computation:待证明的某计算的正确性。
- 2)constraint satisfaction problem:将计算正确性问题,经算术化,转换为,约束满足性问题。
- 3)information-theoretic model:借助information-theoretic model,可高效对constraint satisfaction problem做probabilistic algebraic checks。
- 4)proof system:选择某种cryptographic compiler(如DLG或抗碰撞哈希函数密码学安全假设等),高效安全地实例化为,某ZKP证明系统。

2.1 算术化表示
算术化表示用于将待证明的某计算的正确性,转换为,约束满足性问题。
算术化方案应具有的主要特性为:
- 1)支持高效的lookup argument:以实现将某些昂贵的计算 转移给 预计算 或 offline phase。如位移、电路中的哈希函数等昂贵计算,可在电路外对其进行预计算,而在证明生成期间进行查找即可。lookup argument是 当今zkEVM具备可行性的关键。
- 2)支持high-degree约束:如Plonky2的Poseidon gate。Plonky2具有当今已知的最快的Poseidon哈希实现,原因在于其可将整个Poseidon函数 squeeze进单个约束——该约束具有很高的degree。
- 3)与folding scheme兼容
当前流行的算术化方案主要有:
- R1CS
- AIR
- Plonkish
算术化表示,统一 VS 异构:
- CCS的统一表示:[STW23] Customizable constraint systems for succinct arguments论文中,在不增加开销的情况下,所实现的Customizable constraint systems(CCS)统一兼容了以上三种算术化方案。
同时在[STW23]论文中,其声称具有比STARK Prover更快的 Prover for AIR。 - 乐高组合式的异构表示:不同于CCS[STW23]中的统一化思路,[CFQ19] LegoSNARK: Modular Design and Composition of Succinct Zero-Knowledge Proofs 论文中采用乐高组合式思路,LegoSNARK认为某类计算适合以某种算术化方案表示。针对heterogenous异构计算,可多个组件分别以不同算术化表示,再分别以不同的ZKP方式证明然后再组合,即所谓的commit-and-prove proof composition。所谓组合是指证明各ZKP系统中的这些组件都采用了相同的witness。

2.1.1 lookup argument研究进展
Plonkish算术化表示的lookup argument研究情况为:

- [BCG+18]:2018年Bootle等人《Nearly lineartime zero-knowledge proofs for correct program execution》论文中首次提出使用lookup argument来改进proving time。
- plookup:2020年论文[GW20]
- halo2:2021年ZCash ECC提出
- Caulk:2022年论文[ZBK22]
- Caulk+:2022年论文[PK22]。在此之前的lookup argument算法中,Prover的工作量与lookup table size是相关的,只是相比于处理整个table,工作量要少一些。而自Caulk+ lookup argument算法之后,Prover工作量与lookup table size是无关的。
- Flookup:2022年论文[GK22]
- MVLookup:2022年论文[Hab22]
- baloo:2022年论文[ZGK+22]
- cq:2022年论文[EFG22]
- ProtoStar:2023年论文[BC23]。其针对CCS统一算术表示,提出了兼容folding scheme的lookup argument。
这些lookup argument方案对比情况为:
-
baloo论文中对比情况为:

-
cq论文中对比情况为:

需指出,自Caulk+之后的lookup argument中Prover的开销与lookup table size无关,仅与witness size(或 待open的set size,也即需查找的数量)有关。这对范围约束等应用场景来说是足够的。因范围约束中,可能的合法取值数量 要远远多于 实际所需查找的数量。
2.2 约束满足性问题、信息理论模型、cryptographic compiler以及ZKP
针对不同的算术化表示方案,对应有不同的约束满足性问题以及信息理论模型,分别需采用不同的cryptographic compiler来 实例化为不同的ZKP证明系统:
- 1)R1CS,对应的模型有:
- sumcheck:对应的cryptographic compiler有Hyrax。对应的ZKP证明系统有:Spartan。
- PIOP:对应的cryptographic compiler有KZG。对应的ZKP证明系统有:Marlin。
- 2)AIR,对应的模型有:
- IOPP:对应的cryptographic compiler有FRI。对应的ZKP证明系统有:STARK。
- 3)Plonkish,对应的模型有:
- PIOP:对应的cryptographic compiler有IPA和KZG。对应的ZKP证明系统有:Halo2和PlonK。
- sumcheck:对应的cryptographic compiler有multi-linear KZG。对应的ZKP证明系统有:HyperPlonK。
sumcheck [LFKN92]的最大亮点在于,其将vector commitment看成是multi-linear poly commitment,sumcheck的主要特点为:
- 避免计算quotient多项式(即避免大型FFT运算)等昂贵运算
- 与folding scheme兼容:可folded with no error terms in the group
- 可用于batch源自多个sumchecks的多个multi-linear polynomials 为 一个multi-linear多项式
3. 递归证明
所谓递归证明,是指不互信的各参与方协作证明整条链路上计算的有效性。
可在ZKP系统栈的不同层次上实现递归,对应的递归证明技术有不同的分支:

- 1)full recursion分支:包括:
- atomic accumulation分支:见[BCMS20]、[BCH19]
- split accumulation分支:见[BCLMS21]
- folding scheme分支:见[KST21]
- 2)incrementally verifiable computation(IVC)分支:见[Val08],包括:
- non-uniform IVC分支:如[KS22]
- PCD(Proof-Carrying Data)分支:如[Chi10]、[CTV15]
3.1 IVC from full recursion
所谓IVC from full recursion,是指在“cryptographic compiler”层进行递归。
如Plonky2为full recursion IVC方案,其cryptographic compiler对应为FRI,在cryptographic compiler层进行递归表示为:

其中每个recursive step会fully verify previous step所生成的proof。因此在每个step嵌入full verifier。
Plonky2性能卓越的原因在于,其具有succinct verifier,其verifier为sublinear in the circuit size。 不过这种方案也有局限性,因为并不是所有系统都适于这种full recursion IVC实现。
3.2 IVC from atomic accumulation
所谓IVC from atomic accumulation,也是指“在cryptographic compiler”层进行递归。但是其弱化了要求底层ZKP证明系统具有succinct Verifier的需求。
如Halo2,对应cryptographic compiler为IPA(Inner Product Argument),对应的底层ZKP系统不具有succinct Verifier,在做递归实现时,仅需要由succinct accumulation verifier,即意味着在每个recursive step,将昂贵的验证部分推迟给accumulator,在每个recursive step,仅简单地对所有这些昂贵计算进行累加,仅在最后进行验证,从而对cost进行了amortization(摊销):

IPA(Inner Product Argument)对应的ZKP不具有succinct Verifier,为linear time verifier,是昂贵的。但是借助IVC from atomic accumulation所实现的Halo2,可实现无需trusted setup的IVC,可跨巨大recursive step计算进行摊销,仅需在最后一步做一次linear time check。
3.3 IVC from split accumulation
所谓split accumulation,又名folding scheme。
所谓IVC from split accumulation,是指在“约束满足性问题+信息理论模型”层进行递归。其将递归开销由3.2再降低了某constant size。
IVC from split accumulation,不仅不要求succinct verifier,还不要求succinct accumulation verifier,其仅需要a succinct representation of the accumulator witness。如witness为某R1CS assignment,只要可 以constant size group element来表示该witness的commitment——如Pederson commitment承诺方案,就适于split accumulation场景。
IVC from split accumulation 与 IVC from atomic accumulation的不同之处在于:
- split accumulation不对整个proof进行累加,而仅对instance以及witness的commitment值进行累加
- split accumulation verifier是tiny的,其仅需要关心constant size witness的commitments
- split accumulation机制的Prover效率更高
[BCLMS21]对应2020年论文Proof-Carrying Data without Succinct Arguments:其牺牲了succinctness。

3.4 IVC from folding scheme
所谓IVC from folding scheme,与IVC from split accumulation类似,但在更高的“算术化表示”层进行递归。
在更高的"算术化表示"层进行递归,意味着在每个recursive step,Prover:
- 无需计算和commit quotient多项式:可节约昂贵的如FFT计算
- 无需做任何形式的proof计算
- 直接接收relation(R1CS relation或Plonkish relation)
- 仅需累加instance
- 仅需对witness进行commit
如针对Plonkish算术化表示的Sangria和ProtoStar。在“算术化表示”层进行递归,存在的问题:
- 无zero-knowledge属性:在每个recursive step,Prover仅需接收整个witness。而在atomic accumulation的Halo2中,每个recursive step中Prover仅需要previous step的proof。
- folding scheme适于单个Prover计算大量recursive steps的场景。
- 缺乏灵活性:folding scheme必须fold相同的电路。
而IVC from split accumulation中,是对evaluation claims进行累加,所以任何commitment evaluation point和value均可累加——即均可fold。因此IVC from split accumulation的灵活性更强。

根据在ZKP栈中不同的层进行fold:
- 在越高的层进行fold,具有的Prover越快,但也会有一定的牺牲(如牺牲灵活性、zero-knowledge属性等)
- 在越低的层进行fold,Prover在每个recursive step需做一些昂贵的运算(如FFT等)。不过对于FFT和MSM等运算,可借助GPU加速并行计算,当速度足够快时,可以向ZKP栈的更低层进行fold,这样就还可保持一些迷人的属性(如zero-knowledge属性等),这样有助于协作prover证明场景。
具体的方案有:

3.5 non-uniform IVC
在之前的IVC中,每个recursive step具有相同的computation,而non-uniform IVC,支持每个recursive step从
L
L
L个预定义的circuit中选择一个。
non-uniform IVC适于virtual machine应用场景,可将
L
L
L个电路 看成是 虚拟机的
L
L
L个opcode,这就意味着无需在每个step 用same huge circuit来表示整个虚拟机的逻辑,而可以在每个step选择特定的opcode,从而可节约大量的递归开销。

需注意的是,在non-uniform IVC中:
- 需维护 L L L个累加器,每个累加器都具有constant size,对应的是very succinct commitments值。