背景
线上查询慢的问题日益突出,专门写一个帖子记录一下处理过程,会定期更新优化处理方案
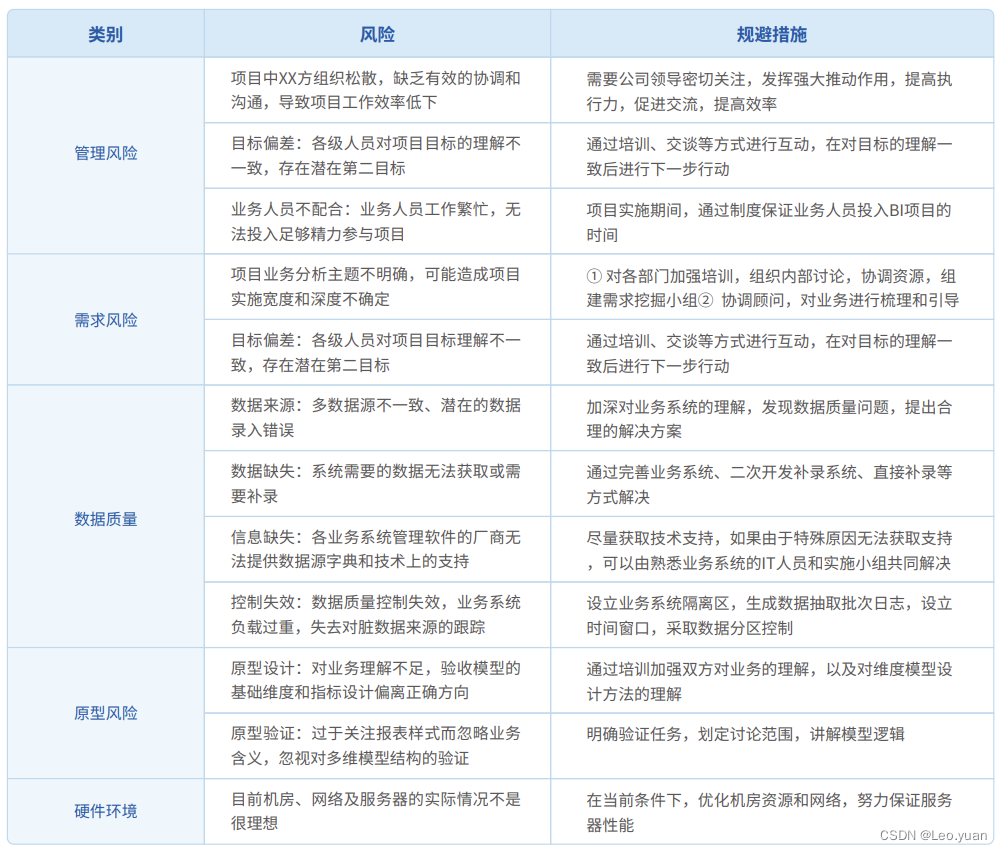
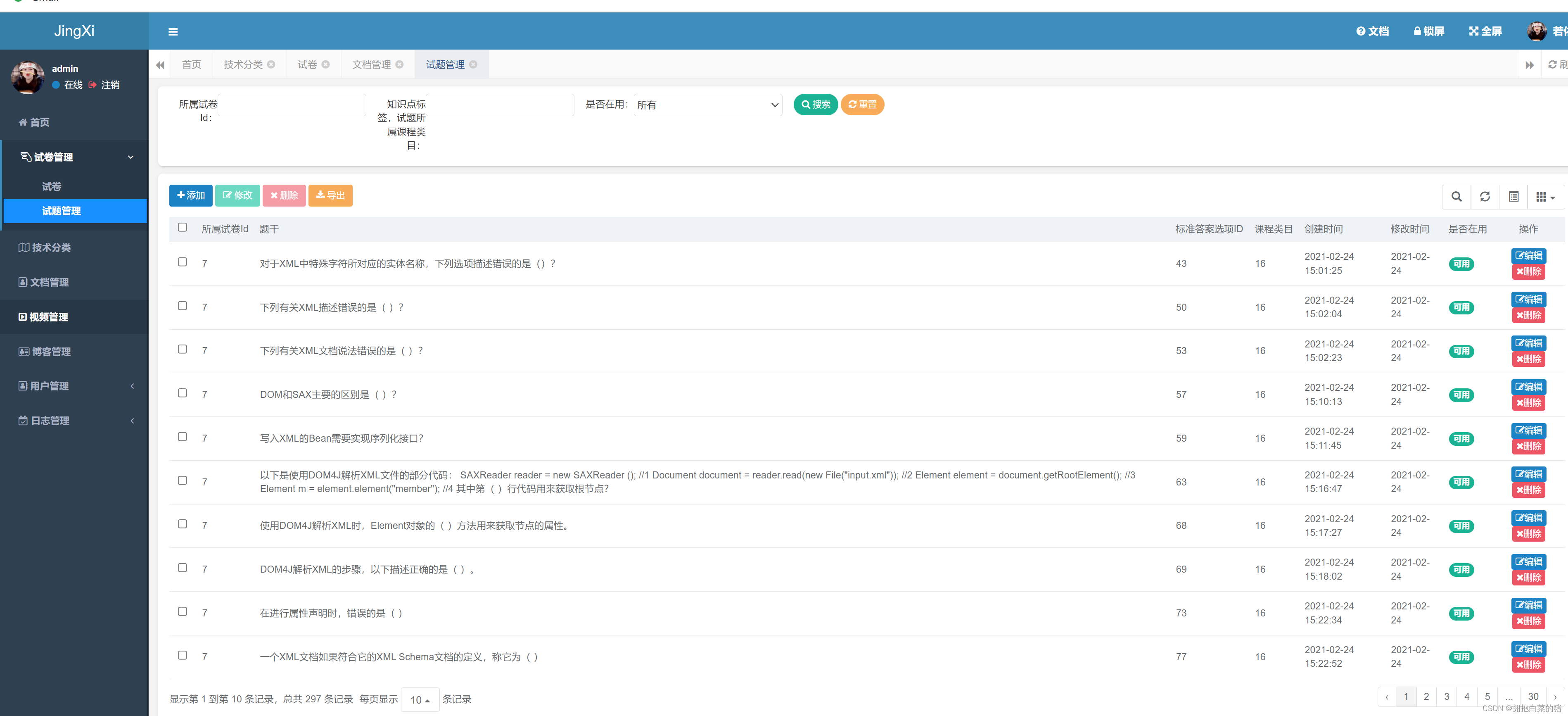
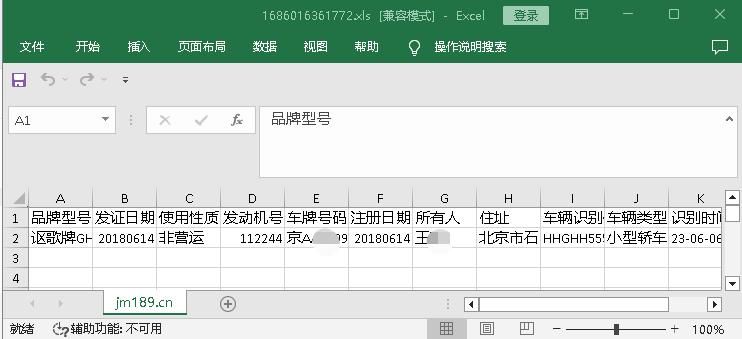
套餐余量统计查询菜单,数据库查询时间一分钟五十秒,优化之后耗时109毫秒,性能提升很大.所有时间统计均以数据库层面进行统计.用户使用层面因为有数据传输、带宽、业务逻辑处理等因素查询时间会更长,只看数据库查询层面可以排除其他因素影响。
待优化sql:
SELECT manage_staff_card.id,manage_staff_card.card_no, manage_staff_card.status, manage_staff_card.rest_count,
manage_staff_card.card_type, manage_card.time_type , manage_staff_card.single_price
FROM manage_staff_card
LEFT JOIN `manage_staff` ON manage_staff.`login` = manage_staff_card.`login` LEFT JOIN `manage_card`
ON manage_card.`id` = manage_staff_card.`card_id` LEFT JOIN `manage_studio` ON manage_studio.`id` = manage_staff_card.`studio_id`
LEFT JOIN `manage_staff_studio` ON manage_staff_studio.`login` = manage_staff_card.`login` AND manage_staff_studio.`studio_id` = manage_staff_card.`studio_id`
LEFT JOIN `manage_user_studio` ON manage_user_studio.`login` = manage_staff_studio.`teacher_login` AND manage_staff_studio.`studio_id` = manage_user_studio.`studio_id`
LEFT JOIN `manage_contract_card` ON manage_contract_card.`staff_card_id` = manage_staff_card.`id`
LEFT JOIN `manage_contract` ON manage_contract.`contract_no` = manage_contract_card.`contract_no`
WHERE manage_staff_card.status IN(8,5,15,20) ORDER BY manage_staff_card.create_time DESC
执行计划如下:

根据优化经验,一般type为all、index都需要进行优化,最少保证到ref。先从下面开始看
manage_contract中type为all,看下sql中manage_contract用作表连接,直接将contract_no字段添加索引:
ALTER TABLE manage_contract ADD INDEX idx_card_no (contract_no);
添加成功后查询索引:
SHOW INDEX FROM manage_contract
重新explain:

type变更为ref,预估扫描的行数变更为1.继续看往下看.
manage_contract_card中type为all,看sql中manage_contract_card中staff_card_id、contract_no在查询中都体现,是不是两个都需要创建索引呢,答案是不需要,只需要对staff_card_id进行创建索引。自己测试过两个都添加索引最终的执行计划type会变更为index,index和all都算是全表扫描,因为添加上contract_no之后再和manage_contract联查时需要按照contract_no全部扫描一遍manage_contract_card,实际上执行上一步的时候已经根据staff_card_id将符合要求的manage_contract_card查询出来,所有这里对于manage_contract_card只添加一个staff_card_id即可。
添加索引
ALTER TABLE manage_contract_card ADD INDEX idx_staff_card_id (staff_card_id);
添加成功后查询索引:
SHOW INDEX FROM manage_contract_card
重新explain:

type变更为ref,预估扫描的行数变更为1.继续看往下看.
manage_staff_card放到最后讲是因为这个会比较特殊。首先看排序,排序会导致索引失效,对按照创建时间排序的业务来讲,可以使用主键id进行倒序可以进行替换实现业务逻辑,另外不需要单独根据创建时间字段添加索引,直接使用主键索引。毕竟不是索引越多越好。修改sql之后重新explain:

type变更为index,由于是id主键排序,所以基本上开始全表扫描.下面在看manage_staff_card中status.直接给status添加索引:
ALTER TABLE manage_staff_card ADD INDEX idx_status (STATUS);
重新执行explain发现索引是不生效的,是因为in会导致索引失效,继续往下看.

关于in的业务场景实际开发中还是比较多的,i查阅资料总结了一下in常用的优化方案:
1.使用JOIN替代IN查询。如果条件中的IN查询可以转换为JOIN查询,有可能会对性能有一定提升
2.IN查询中的值列表存储到临时表中,然后使用JOIN查询
3.exists能否替代
注意:对于in中全部是参数值的,使用exist代替in无效
以上各种优化方案都试过,对于本场景中in为参数值的情况,上面都不适用,这里的处理方式是对于manage_staff_card 中的status索引进行强制执行,manage_staff_card后面添加FORCE INDEX(idx_status).重新执行explain:

会发现type类型变更为range.重新执行sql后耗时:0.109秒
最终优化后的sql:
EXPLAIN SELECT manage_staff_card.id,manage_staff_card.card_no, manage_staff_card.status, manage_staff_card.rest_count,
manage_staff_card.card_type, manage_staff.real_name , manage_card.time_type , manage_staff_card.single_price
FROM manage_staff_card FORCE INDEX(idx_status)
LEFT JOIN `manage_staff` ON manage_staff.`login` = manage_staff_card.`login` LEFT JOIN `manage_card`
ON manage_card.`id` = manage_staff_card.`card_id` LEFT JOIN `manage_studio` ON manage_studio.`id` = manage_staff_card.`studio_id`
LEFT JOIN `manage_staff_studio` ON manage_staff_studio.`login` = manage_staff_card.`login` AND manage_staff_studio.`studio_id` = manage_staff_card.`studio_id`
LEFT JOIN `manage_user_studio` ON manage_user_studio.`login` = manage_staff_studio.`teacher_login` AND manage_staff_studio.`studio_id` = manage_user_studio.`studio_id`
LEFT JOIN `manage_contract_card` ON manage_contract_card.`staff_card_id` = manage_staff_card.`id`
LEFT JOIN `manage_contract` ON manage_contract.`contract_no` = manage_contract_card.`contract_no`
WHERE manage_staff_card.status IN(8,5,15,20) ORDER BY manage_staff_card.id DESC
总结:
1.left join中添加索引一般是从left join后面的表中的连接字段进行添加索引,而不是只要left join表的查询条件中有的字段都添加索引.
2.order by排序时可以使用主键排序替换字符串排序;
3.in的常用优化处理方式,上面已补充,这里不再重复;
以上sql优化的处理过程,如果看到这里感觉有所帮助欢迎点赞或收藏!下面是最近参与的一个匿名社交类的微信小程序,有兴趣的可以看下