目录
MySQL
连接查询
表
约束
存储引擎
事务
索引
视图(View)
数据库的导入导出(DBA命令)
数据库设计三范式
MySQL
-
sql、DB、DBMS分别是什么?它们之间的关系?
-
DB:
DataBase(数据库,实际上在硬盘以上以文件的形式存在)
-
DBMS:
DataBase Management System(数据库管理系统,常见的有:MySQL Oracle DB2 SqlServer…)
-
SQL:
结构化查询语言,是一门标准通用的语言。标准的sql适合于所有的数据库产品。
SQL属于高级语言,只要能看懂英语单词,都可以看懂sql语句是什么意思
SQL语句在执行的时候,实际上内部也会先进行编译,然后再执行sql。(sql的编译由DBMS完成)
-
DBMS负责执行sql语句,通过执行sql语句来操作DB当中的数据
DBMS—(执行)—>SQL—(操作)—>DB
-
-
什么是表?
表:table。
表table是数据库的基本组成单元,所有数据都以表格的形式组成,目的是可读性强
学号(int) 姓名(varchar) 年龄(int) ---------------------------------------- 110 张三 20 120 李四 21每一个字段应该包括哪些类型?
字段名、数据类型、相关的约束
-
学习MySQL主要还是学习通用的SQL语句,那么SQL语句包括增删改查,SQL语句怎么分类呢?
- DQL(数据查询语言):查询语言,凡是select语句都是DQL
- DML(数据操作语言):insert、delete、update,对表当中的数据进行增删改查
- DDL(数据定义语言):create、drop、alter,对表结构的增删改
- TCL(事务控制语言):commit提交事务,rollback回滚事务。(TCL中的T是Transaction)
- DCL(数据控制语言):grant授权、revoke撤销权限等
-
导入数据
-
第一步:登录mysql数据库管理系统。
dos命令窗口:mysql -uroot -p123
-
第二步:查看有哪些数据库
show databases;(这个不是SQL语句,属于MySQL的命令)
+--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ -
第三步:创建属于我们自己的数据库
create database datas;(这个不是SQL语句,属于MySQL的命令)
show database; 👇
+--------------------+ | Database | +--------------------+ | datas | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ -
第四步:使用datas数据库
use datas;(这个不是SQL语句,属于MySQL的命令)
-
第五步:查看当前使用的数据库中有哪些表
show tables;(MySQL命令)
-
第六步:初始化数据
mysql> source C:\Users\qishi\Desktop\typora markdown学习\MySQL\01-MySQL\数据脚本\datas.sql
注意:数据初始化完成之后,有三张表:
+-----------------+ | Tables_in_datas | +-----------------+ | dept | | emp | | salgrade | +-----------------+
-
-
datas.sql,这个文件以sql结尾,这样的文件被称为:“sql脚本”。什么是sql脚本呢?
当一个文件的扩展名是:.sql,并且该文件中编写了大量的SQL语句,我们成这样的文件为sql脚本。
注意:直接使用source命令可以执行sql脚本。
sql脚本中的数据量太大的时候,无法打开,请使用source命令完成初始化
-
删除数据库:drop database datas;
-
查看表结构:
+-----------------+ | Tables_in_datas | +-----------------+ | dept |(部门表) | emp |(员工表) | salgrade |(工资等级表) +-----------------+ mysql> desc dept; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | DEPTNO | int | NO | PRI | NULL | | 部门编号 | DNAME | varchar(14) | YES | | NULL | | 部门名称 | LOC | varchar(13) | YES | | NULL | | 部门位置 +--------+-------------+------+-----+---------+-------+ mysql> desc emp; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | EMPNO | int | NO | PRI | NULL | | 员工编号 | ENAME | varchar(10) | YES | | NULL | | 员工姓名 | JOB | varchar(9) | YES | | NULL | | 工作岗位 | MGR | int | YES | | NULL | | 上级领导编号 | HIREDATE | date | YES | | NULL | | 入职日期 | SAL | double(7,2) | YES | | NULL | | 月薪 | COMM | double(7,2) | YES | | NULL | | 补助/津贴 | DEPTNO | int | YES | | NULL | | 部门编号 +----------+-------------+------+-----+---------+-------+ mysql> desc salgrade; +-------+------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------+------+-----+---------+-------+ | GRADE | int | YES | | NULL | | 等级 | LOSAL | int | YES | | NULL | | 最低薪资 | HISAL | int | YES | | NULL | | 最高薪资 +-------+------+------+-----+---------+-------+ -
表中的数据
mysql> select * from dept; +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | +--------+------------+----------+ mysql> select * from emp; +-------+--------+-----------+------+------------+---------+---------+--------+ | EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+---------+--------+ mysql> select * from salgrade; +-------+-------+-------+ | GRADE | LOSAL | HISAL | +-------+-------+-------+ | 1 | 700 | 1200 | | 2 | 1201 | 1400 | | 3 | 1401 | 2000 | | 4 | 2001 | 3000 | | 5 | 3001 | 9999 | +-------+-------+-------+ -
常用命令
mysql> select database(); 查看当前使用的是哪个数据库 +------------+ | database() | +------------+ | datas | +------------+ mysql> select version(); 查看mysql的版本号 +-----------+ | version() | +-----------+ | 8.0.23 | +-----------+ \c 命令 ,结束一条语句 exit 命令,退出mysql -
查看创建表的语句:
show create table emp;
-
简单的查询语句(DQL)
-
语法格式:select 字段名1,字段名2… from 表名;
-
提示:
- 任何一条sql语句以 “ ; ” 结尾
- sql语句不区分大小写
-
查询员工的年薪(字段可以参与数学运算)
select ename,sal*12 from emp; +--------+----------+ | ename | sal*12 | +--------+----------+ | SMITH | 9600.00 | | ALLEN | 19200.00 | | WARD | 15000.00 | | JONES | 35700.00 | | MARTIN | 15000.00 | | BLAKE | 34200.00 | | CLARK | 29400.00 | | SCOTT | 36000.00 | | KING | 60000.00 | | TURNER | 18000.00 | | ADAMS | 13200.00 | | JAMES | 11400.00 | | FORD | 36000.00 | | MILLER | 15600.00 | +--------+----------+ -
查询结果的列重命名
select ename,sal*12 as yearsal from emp; 别名中有中文? select ename,sal*12 as 年薪 from emp; //错误 select ename,sal*12 as '年薪' from emp; 注意: mysql里的字符串用单引号括起来,这里用双引号也可以,但是如果到了oracle和SQL Server中,双引号就报错,所以统一都用单引号括起来('字符串') 标准sql语句中要求字符串使用单引号括起来 +--------+----------+ | ename | 年薪 | +--------+----------+ | SMITH | 9600.00 | | ALLEN | 19200.00 | | WARD | 15000.00 | | JONES | 35700.00 | | MARTIN | 15000.00 | | BLAKE | 34200.00 | | CLARK | 29400.00 | | SCOTT | 36000.00 | | KING | 60000.00 | | TURNER | 18000.00 | | ADAMS | 13200.00 | | JAMES | 11400.00 | | FORD | 36000.00 | | MILLER | 15600.00 | +--------+----------+ -
as关键字可以省略
select empno,sal*12 '年薪' from emp; +-------+----------+ | empno | 年薪 | +-------+----------+ | 7369 | 9600.00 | | 7499 | 19200.00 | | 7521 | 15000.00 | | 7566 | 35700.00 | | 7654 | 15000.00 | | 7698 | 34200.00 | | 7782 | 29400.00 | | 7788 | 36000.00 | | 7839 | 60000.00 | | 7844 | 18000.00 | | 7876 | 13200.00 | | 7900 | 11400.00 | | 7902 | 36000.00 | | 7934 | 15600.00 | +-------+----------+ -
查询全部字段
select * from emp; //实际开发中不建议使用*,效率较低。根据实际需求。
-
-
条件查询
-
语法格式:
select 字段,字段..... form 表名 where 条件; -
执行顺序:先from,然后where,最后select。
查询工资等于5000的员工姓名?
select ename from emp where sal=5000; +-------+ | ename | +-------+ | KING | +-------+查询SMITH的工资
select sal from emp where ename ='smith'; +--------+ | sal | +--------+ | 800.00 | +--------+找出工资高于或等于3000的员工
select ename ,sal from emp where sal >=3000; +-------+---------+ | ename | sal | +-------+---------+ | SCOTT | 3000.00 | | KING | 5000.00 | | FORD | 3000.00 | +-------+---------+ 低于3000 select ename ,sal from emp where sal<3000;找出工资不等于3000的
select ename,sal from emp where sal<>3000; select ename,sal from emp where sal!=3000;找出工资在1100和3000之间的员工,包括1100和3000
select ename,sal from emp where sal>=1100 and sal <=3000; select ename,sal from emp where sal between 1100 and 3000; //between...and... [1100,3000],并且between。。and使用时必须左小右大 -
between…and 除了可以使用在数字方面,也可以使用在字符串方面。
注意:使用在字符串方面可以返回以某个字母开头到另一个字母开头的,其中不包括以最后那个字母开头的。
select ename from emp where ename between 'A' and 'C'; +-------+ | ename | +-------+ | ALLEN | | BLAKE | | ADAMS | +-------+ select ename from emp where ename between 'A' and 'D'; +-------+ | ename | +-------+ | ALLEN | | BLAKE | | CLARK | | ADAMS | +-------+ -
找出哪些人津贴为NULL?
在数据库当中NULL不是一个值,代表什么也没有,为空。空不是一个值,不能用=衡量。
必须用is null 或 is not null
select ename,sal,comm from emp where comm is null; +--------+---------+------+ | ename | sal | comm | +--------+---------+------+ | SMITH | 800.00 | NULL | | JONES | 2975.00 | NULL | | BLAKE | 2850.00 | NULL | | CLARK | 2450.00 | NULL | | SCOTT | 3000.00 | NULL | | KING | 5000.00 | NULL | | ADAMS | 1100.00 | NULL | | JAMES | 950.00 | NULL | | FORD | 3000.00 | NULL | | MILLER | 1300.00 | NULL | +--------+---------+------+ -
找出哪些人津贴不为NULL?
select ename,sal,comm from emp where comm is not null; +--------+---------+---------+ | ename | sal | comm | +--------+---------+---------+ | ALLEN | 1600.00 | 300.00 | | WARD | 1250.00 | 500.00 | | MARTIN | 1250.00 | 1400.00 | | TURNER | 1500.00 | 0.00 | //0.00不是NULL,null代表什么都没有 +--------+---------+---------+ -
找出哪些人没有津贴?
select ename,sal,comm from emp where comm is null or comm = 0; +--------+---------+------+ | ename | sal | comm | +--------+---------+------+ | SMITH | 800.00 | NULL | | JONES | 2975.00 | NULL | | BLAKE | 2850.00 | NULL | | CLARK | 2450.00 | NULL | | SCOTT | 3000.00 | NULL | | KING | 5000.00 | NULL | | TURNER | 1500.00 | 0.00 | | ADAMS | 1100.00 | NULL | | JAMES | 950.00 | NULL | | FORD | 3000.00 | NULL | | MILLER | 1300.00 | NULL | +--------+---------+------+ -
找出工作岗位是manager和salesman的员工
select ename,job from emp where job ='manager' or job ='salesman'; +--------+----------+ | ename | job | +--------+----------+ | ALLEN | SALESMAN | | WARD | SALESMAN | | JONES | MANAGER | | MARTIN | SALESMAN | | BLAKE | MANAGER | | CLARK | MANAGER | | TURNER | SALESMAN | +--------+----------+ -
and和or联合使用:找出薪资大于1000的并且部门编号是20和30部门的员工
select ename,sal,deptno from emp where sal>1000 and deptno=20 or deptno=30; +--------+---------+--------+ | ename | sal | deptno | +--------+---------+--------+ | ALLEN | 1600.00 | 30 | | WARD | 1250.00 | 30 | | JONES | 2975.00 | 20 | | MARTIN | 1250.00 | 30 | | BLAKE | 2850.00 | 30 | | SCOTT | 3000.00 | 20 | | TURNER | 1500.00 | 30 | | ADAMS | 1100.00 | 20 | | JAMES | 950.00 | 30 | | FORD | 3000.00 | 20 | +--------+---------+--------+ sal有一个小于1000的原因:and的优先级高,sal>1000 and deptno=20 联合在一起了 解决方法:当运算符优先级不确定的时候加个小括号。 select ename,sal,deptno from emp where sal>1000 and (deptno=20 or deptno=30); +--------+---------+--------+ | ename | sal | deptno | +--------+---------+--------+ | ALLEN | 1600.00 | 30 | | WARD | 1250.00 | 30 | | JONES | 2975.00 | 20 | | MARTIN | 1250.00 | 30 | | BLAKE | 2850.00 | 30 | | SCOTT | 3000.00 | 20 | | TURNER | 1500.00 | 30 | | ADAMS | 1100.00 | 20 | | FORD | 3000.00 | 20 | +--------+---------+--------+ -
in等同于or:找出工作岗位是manager和salesman的员工
select ename,job from emp where job='salesman' or job='manager'; select ename,job from emp where job in('manager','salesman'); //找出薪资是800或5000的员工 select ename,job from emp where sal in(800,5000); //in后面的值是具体的值 -
not in :不在这几个值当中。
select ename,job from emp where sal not in(800,5000);
-
-
模糊查询
-
找出名字当中含有o的。(在模糊查询中,两个特殊符号:%、_)
%代表:任意多个字符。_代表:任意一个字符
select ename from emp where ename like '%o%'; +-------+ | ename | +-------+ | JONES | | SCOTT | | FORD | +-------+ -
找出第二个字母是A的
select ename from emp where ename like '_a%'; +--------+ | ename | +--------+ | WARD | | MARTIN | | JAMES | +--------+ -
找出名字中含有下划线的
select name from user where name like '%_%'; //这个是错的,相当于查询出全部的名字 select name from user where name like '%\_%' //使用\使_不再具有特殊含义,转换成下划线,这样就可以找出名字中含有下划线的。 -
找出名字中最后一个字母是t的
select ename from emp where ename like '%t'; +-------+ | ename | +-------+ | SCOTT | +-------+
-
-
排序(升序、降序)
按照工资升序,找出员工名和薪资
select ename,sal from emp order by sal; +--------+---------+ | ename | sal | +--------+---------+ | SMITH | 800.00 | | JAMES | 950.00 | | ADAMS | 1100.00 | | WARD | 1250.00 | | MARTIN | 1250.00 | | MILLER | 1300.00 | | TURNER | 1500.00 | | ALLEN | 1600.00 | | CLARK | 2450.00 | | BLAKE | 2850.00 | | JONES | 2975.00 | | SCOTT | 3000.00 | | FORD | 3000.00 | | KING | 5000.00 | +--------+---------+注意:默认是升序,怎么执行升序或是降序?asc表示升序,desc表示降序
select ename,sal from emp order by sal; //升序 select ename,sal from emp order by sal asc; //升序 select ename,sal from emp order by sal desc; //降序按照工资的降序排列,当工资相同时再按照名字升序排列。
注意:越靠前的字段越能起到主导作用,只有当前面的字段无法完成排序的时候,才会启用后面的字段
select ename,sal from emp order by sal desc; //先按照工资降序排 select ename,sal from emp order by sal desc,ename asc; //在工资降序排的基础上加上姓名升序排找出工作岗位是salesman的员工,并且要求按照薪资的降序排列
select ename,job,sal from emp where job='salesman' order by sal desc; +--------+----------+---------+ | ename | job | sal | +--------+----------+---------+ | ALLEN | SALESMAN | 1600.00 | | TURNER | SALESMAN | 1500.00 | | WARD | SALESMAN | 1250.00 | | MARTIN | SALESMAN | 1250.00 | +--------+----------+---------+注意:order by是最后执行的
select 字段 from 表名 where 条件 order by ... order by是最后执行的 -
分组函数
-
count:计数
sum:求和
avg:平均值
max:最大值
min:最小值
-
注意:所有的分组函数都是对”某一组“数据进行操作的
找出工资共和 select sum(sal) from emp; 找出最高工资 select max(sal) from emp; 找出最低工资 select min(sal) from emp; 找出平均工资 select avg(sal) from emp; 找出总人数 select count(*) from emp; select count(ename) from emp; -
分组函数一共有5个。分组函数还有另一个名字:多行处理函数。
多行处理函数的特点:输入多行,最终输出的结果是1行。
-
分组函数自动忽略NULL
select count(comm) from emp; +-------------+ | count(comm) | +-------------+ | 4 | +-------------+select sum(comm) from emp; +-----------+ | sum(comm) | +-----------+ | 2200.00 | +-----------+ 注意:所有分组函数自动忽略NULL select sum(comm) from emp where comm is not null;//不需要额外添加这个过滤条件 //sum函数自动忽略null -
找出工资高于平均工资的员工
select avg(sal) from emp; //平均工资 //查询 select avg(sal) from emp where sal>avg(sal); //报错:ERROR 1111 (HY000): Invalid use of group function //思考报错的原因:无效使用了分组函数? // 原因:SQL语句当中有一个语法规则,分组函数不可直接使用在where字句当中。 why?? //解释:因为group by 是在where执行之后才会执行的。 -
count(*)和count(具体的某个字段),有什么区别?
count(*):不是统计某个字段中数据的个数,而是统计该表中总记录数的条数(与某个字段无关)
count(某个字段(例如:comm)):表示统计comm字段中不为NULL的数据总数量
select count(*) from emp; +----------+ | count(*) | +----------+ | 14 | +----------+ select count(comm) from emp; +-------------+ | count(comm) | +-------------+ | 4 | +-------------+ -
分组函数也能组合起来使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp; +----------+----------+-------------+----------+----------+ | count(*) | sum(sal) | avg(sal) | max(sal) | min(sal) | +----------+----------+-------------+----------+----------+ | 14 | 29025.00 | 2073.214286 | 5000.00 | 800.00 | +----------+----------+-------------+----------+----------+ -
找出工资高于平均工资的员工
第一步:找出平均工资 select avg(sal) from emp; +-------------+ | avg(sal) | +-------------+ | 2073.214286 | +-------------+ 第二部:找出高于平均工资的员工 select ename,sal from emp where sal>2073.214286; +-------+---------+ | ename | sal | +-------+---------+ | JONES | 2975.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 | | SCOTT | 3000.00 | | KING | 5000.00 | | FORD | 3000.00 | +-------+---------+ 合并 select ename,sal from emp where sal >(select avg(sal) from emp);
-
-
单行处理函数
-
什么是单行处理函数?
输入一行,输出一行。
-
计算每个员工的年薪
select ename,(sal+comm)*12 as yearsal from emp; +--------+----------+ | ename | yearsal | +--------+----------+ | SMITH | NULL | | ALLEN | 22800.00 | | WARD | 21000.00 | | JONES | NULL | | MARTIN | 31800.00 | | BLAKE | NULL | | CLARK | NULL | | SCOTT | NULL | | KING | NULL | | TURNER | 18000.00 | | ADAMS | NULL | | JAMES | NULL | | FORD | NULL | | MILLER | NULL | +--------+----------+重点:所有数据库都是这样规定的,只要有null参与的运算结果一定是null
ifnull()空处理函数?
ifnull(可能为null的数据,被当作什么处理?):属于单行处理函数
select ename,ifnull(comm,0) as comm from emp; +--------+---------+ | ename | comm | +--------+---------+ | SMITH | 0.00 | | ALLEN | 300.00 | | WARD | 500.00 | | JONES | 0.00 | | MARTIN | 1400.00 | | BLAKE | 0.00 | | CLARK | 0.00 | | SCOTT | 0.00 | | KING | 0.00 | | TURNER | 0.00 | | ADAMS | 0.00 | | JAMES | 0.00 | | FORD | 0.00 | | MILLER | 0.00 | +--------+---------+再次计算年薪
select ename,(sal+ifnull(comm,0))*12 as yearsal from emp; +--------+----------+ | ename | yearsal | +--------+----------+ | SMITH | 9600.00 | | ALLEN | 22800.00 | | WARD | 21000.00 | | JONES | 35700.00 | | MARTIN | 31800.00 | | BLAKE | 34200.00 | | CLARK | 29400.00 | | SCOTT | 36000.00 | | KING | 60000.00 | | TURNER | 18000.00 | | ADAMS | 13200.00 | | JAMES | 11400.00 | | FORD | 36000.00 | | MILLER | 15600.00 | +--------+----------+
-
-
group by 和 having
-
group by :按照某个字段或者某些字段进行分组
-
having:对分组之后的数据进行再次过滤
-
找出每个工作岗位的最高薪资
select job,max(sal) from emp group by job; +-----------+----------+ | job | max(sal) | +-----------+----------+ | CLERK | 1300.00 | | SALESMAN | 1600.00 | | MANAGER | 2975.00 | | ANALYST | 3000.00 | | PRESIDENT | 5000.00 | +-----------+----------+ -
注意:分组函数一般都会和group by 联合使用,这也是为什么他被称为分组函数的原因,并且任何一个分组函数(count,sum,avg,max,min)都是在group by语句执行之后才会执行的。当一条sql语句没有group by的话,整张表的数据会自成一组。
select .. 5、having过滤之后查询出来 from .. 1、先从这张表里查 where .. 2、通过where条件过滤 group by .. 3、条件过滤后再分组 having .. 4、分组后还可以进行过滤 order by .. 6、查询完之后再排序 select sum(sal) from emp; //整张表自成一组 //相当于 select sum(sal) from emp group by; //缺省group by。 注意: 当一套sql语句中有group by的时候,select后面只能跟参与分组的字段以及分组函数,其他的字段不允许出现。 select enmae,max(sal),job from emp group by job; 以上在mysql当中,查询结果是有的,但是结果没意义,在oracle数据库当中会报错。语法错误。oracle的语法规则比mysql语法规则严谨 -
每个工作岗位的平均薪资
select job,avg(sal) from emp group by job; +-----------+-------------+ | job | avg(sal) | +-----------+-------------+ | CLERK | 1037.500000 | | SALESMAN | 1400.000000 | | MANAGER | 2758.333333 | | ANALYST | 3000.000000 | | PRESIDENT | 5000.000000 | +-----------+-------------+ -
多个字段联合起来分组。找出每个部门不同工作岗位的最高薪资
select job,deptno,max(sal) from emp group by deptno,job; +-----------+--------+----------+ | job | deptno | max(sal) | +-----------+--------+----------+ | CLERK | 20 | 1100.00 | | SALESMAN | 30 | 1600.00 | | MANAGER | 20 | 2975.00 | | MANAGER | 30 | 2850.00 | | MANAGER | 10 | 2450.00 | | ANALYST | 20 | 3000.00 | | PRESIDENT | 10 | 5000.00 | | CLERK | 30 | 950.00 | | CLERK | 10 | 1300.00 | +-----------+--------+----------+ -
找出每个部门的最高薪资,要求显示薪资大于2900的数据
第一步:找出每个部门的最高薪资 select deptno,max(sal) from emp group by deptno; +--------+----------+ | deptno | max(sal) | +--------+----------+ | 20 | 3000.00 | | 30 | 2850.00 | | 10 | 5000.00 | +--------+----------+ 第二步:找出薪资大于2900的 select deptno,max(sal) from emp group by deptno having max(sal) >2900; //这种方式效率低 +--------+----------+ | deptno | max(sal) | +--------+----------+ | 20 | 3000.00 | | 10 | 5000.00 | +--------+----------+ select deptno,max(sal) from emp where sal>2900 group by deptno; //效率较高,建议能够使用where过滤的尽量使用where +--------+----------+ | deptno | max(sal) | +--------+----------+ | 20 | 3000.00 | | 10 | 5000.00 | +--------+----------+ -
找出每个部门的平均薪资,要求显示薪资大于2000的数据
第一步:找出每个部门的平均薪资 select deptno,avg(sal) from emp group by deptno; 第二步:显示大于2000的数据 select deptno,avg(sal) from emp group by deptno having avg(sal)>2000; +--------+-------------+ | deptno | avg(sal) | +--------+-------------+ | 20 | 2175.000000 | | 10 | 2916.666667 | +--------+-------------+
-
-
总结一个完整的DQL语句怎么写?
select .. 5 from .. 1 where .. 2 group by.. 3 having .. 4 order by.. 6 注意:where后不能出现分组函数 -
关于查询结果的去重
select distinct job from emp; //distinct关键字去除重复记录 +-----------+ | job | +-----------+ | CLERK | | SALESMAN | | MANAGER | | ANALYST | | PRESIDENT | +-----------+注意:distinct只能出现在所有字段的最前面。
select distinct deptno,job from emp; //这里的distinct表示后面两个字段联合起来去重 +--------+-----------+ | deptno | job | +--------+-----------+ | 20 | CLERK | | 30 | SALESMAN | | 20 | MANAGER | | 30 | MANAGER | | 10 | MANAGER | | 20 | ANALYST | | 10 | PRESIDENT | | 30 | CLERK | | 10 | CLERK | +--------+-----------+统计岗位的数量
select count(distinct job) from emp; +---------------------+ | count(distinct job) | +---------------------+ | 5 | +---------------------+
连接查询
-
什么是连接查询?
在实际开发中,大部分的情况下都不是从单表中查询数据,一般都是多张表联合查询取出最终的结果。
在实际开发中,一般一个业务都会对应多张表,比如:学生和班级,最少要两张表。如果学生和班级信息存储到一张表中,数据会存在大量的重复,导致数据的冗余
-
连接查询的分类
-
根据语法出现的年代来划分,包括:
SQL92(一些老的DBA可能还在使用这种语法。DBA:DataBase Administrator ,数据库管理员)
SQL99(比较新的语法)
-
根据表的连接方式划分,包括:
内连接
等值连接
非等值连接
自连接
外连接
左外连接(左连接)
右外连接(右连接)
全连接(这个很少用,不讲)
-
-
在表的连接查询方面有一种现象被称为:笛卡尔积现象。(笛卡尔乘积现象)
-
找出每一个员工的部门名称,要求显示员工名和部门名
select ename,dname from emp,dept; //ename和dname要联合起来一块显示,粘到一块 +--------+------------+ | ename | dname | +--------+------------+ | SMITH | OPERATIONS | | SMITH | SALES | | SMITH | RESEARCH | | SMITH | ACCOUNTING | | ALLEN | OPERATIONS | | ALLEN | SALES | | ALLEN | RESEARCH | | ALLEN | ACCOUNTING | | WARD | OPERATIONS | | WARD | SALES | | WARD | RESEARCH | | WARD | ACCOUNTING | .......... 56 rows in set (0.01 sec)笛卡尔乘积现象:当两张表进行连接查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积
关于表的别名
select e.ename,d.dname from emp e,dept d; 表的别名的好处: 第一:执行效率高 第二:可读性好 -
怎么避免笛卡尔积现象?加条件进行过滤
思考:避免了笛卡尔积现象,会减少记录的匹配次数吗?
不会,还是56次,只不过显示的是有效记录
找出每一个员工的部门名称,要求显示员工名和部门名
select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno; //SQL92,以后不用 +--------+------------+ | ename | dname | +--------+------------+ | SMITH | RESEARCH | | ALLEN | SALES | | WARD | SALES | | JONES | RESEARCH | | MARTIN | SALES | | BLAKE | SALES | | CLARK | ACCOUNTING | | SCOTT | RESEARCH | | KING | ACCOUNTING | | TURNER | SALES | | ADAMS | RESEARCH | | JAMES | SALES | | FORD | RESEARCH | | MILLER | ACCOUNTING | +--------+------------+
-
-
内连接之等值连接:最大的特点:条件是等量关系。
-
查询每个员工的部门名称,要求显示员工名和部门名。
SQL92:(太老了,不用了) select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno; SQL99:(常用的) //inner可以省略,加inner的目的是:可读性更好 select e.ename,d.dname from emp e inner join dept d on e.deptno=d.deptno; +--------+------------+ | ename | dname | +--------+------------+ | SMITH | RESEARCH | | ALLEN | SALES | | WARD | SALES | | JONES | RESEARCH | | MARTIN | SALES | | BLAKE | SALES | | CLARK | ACCOUNTING | | SCOTT | RESEARCH | | KING | ACCOUNTING | | TURNER | SALES | | ADAMS | RESEARCH | | JAMES | SALES | | FORD | RESEARCH | | MILLER | ACCOUNTING | +--------+------------+ 语法: ··· 表A inner join 表B on 连接条件 where ... SQL99的语法结构更清晰一些:表的连接条件和后来的where条件分离了。
-
-
内连接之非等值连接:最大的特点是:连接条件中的关系是非等量关系
-
找出每个员工的工资等级,要求显示员工姓名、工资、工资等级。
select e.ename,e.sal,s.grade from emp e inner join salgrade s on e.sal between s.losal and s.hisal; +--------+---------+-------+ | ename | sal | grade | +--------+---------+-------+ | SMITH | 800.00 | 1 | | ALLEN | 1600.00 | 3 | | WARD | 1250.00 | 2 | | JONES | 2975.00 | 4 | | MARTIN | 1250.00 | 2 | | BLAKE | 2850.00 | 4 | | CLARK | 2450.00 | 4 | | SCOTT | 3000.00 | 4 | | KING | 5000.00 | 5 | | TURNER | 1500.00 | 3 | | ADAMS | 1100.00 | 1 | | JAMES | 950.00 | 1 | | FORD | 3000.00 | 4 | | MILLER | 1300.00 | 2 | +--------+---------+-------+
-
-
自连接:最大的特点:一张表看作两张表,自己连接自己。
-
找出每个领导的上级领导,要求显示员工名和对应的领导名
//员工的领导编号=领导的员工编号 select a.ename as '员工名',b.ename as '领导名' from emp a inner join emp b on a.mgr=b.empno; +--------+--------+ | 员工名 | 领导名 | +--------+--------+ | SMITH | FORD | | ALLEN | BLAKE | | WARD | BLAKE | | JONES | KING | | MARTIN | BLAKE | | BLAKE | KING | | CLARK | KING | | SCOTT | JONES | | TURNER | BLAKE | | ADAMS | SCOTT | | JAMES | BLAKE | | FORD | JONES | | MILLER | CLARK | +--------+--------+
-
-
外连接
-
什么是外连接,和内连接有什么区别?
内连接:
假设A和B进行连接,使用内连接,凡是A表和B表能够匹配上的记录查询出来。
A表和B表没有主副之分,两张表是平等的
外连接:
AB两张表中有一张表是主表,一张表是副表。主要查询主表中的数据,捎带查询副表,当副表中的数据没有和主表中的数据匹配上时,副表自动模拟出NULL与之匹配。
-
外连接的分类
左外连接(左连接):表示左边的表是主表
右外连接(右连接):表示右边的表是主表
-
找出每个员工的上级领导(所有员工必须查询出来)
//左连接: select a.ename '员工',b.ename '领导' from emp a left join emp b on a.mgr=b.empno; +--------+-------+ | 员工 | 领导 | +--------+-------+ | SMITH | FORD | | ALLEN | BLAKE | | WARD | BLAKE | | JONES | KING | | MARTIN | BLAKE | | BLAKE | KING | | CLARK | KING | | SCOTT | JONES | | KING | NULL | | TURNER | BLAKE | | ADAMS | SCOTT | | JAMES | BLAKE | | FORD | JONES | | MILLER | CLARK | +--------+-------+ //右连接: select a.ename '员工',b.ename '领导' from emp b right outer join emp a on a.mgr=b.empno; //outer 可以省略 select a.ename '员工',b.ename '领导' from emp b right join emp a on a.mgr=b.empno; +--------+-------+ | 员工 | 领导 | +--------+-------+ | SMITH | FORD | | ALLEN | BLAKE | | WARD | BLAKE | | JONES | KING | | MARTIN | BLAKE | | BLAKE | KING | | CLARK | KING | | SCOTT | JONES | | KING | NULL | | TURNER | BLAKE | | ADAMS | SCOTT | | JAMES | BLAKE | | FORD | JONES | | MILLER | CLARK | +--------+-------+ -
外连接最重要的特点是:主表的数据无条件的全部查询出来
找出哪个部门没有员工?
select d.* from emp e right join dept d on e.deptno=d.deptno where e.empno is null; +--------+------------+--------+ | DEPTNO | DNAME | LOC | +--------+------------+--------+ | 40 | OPERATIONS | BOSTON | +--------+------------+--------+
-
-
三张表怎么连接查询?
.... A join B join C on ... 表示:A表B表先进行表连接,连接之后A表再继续和c表进行连接-
找出每一个员工的部门名称以及工资等级
select e.ename,d.dname,s.grade from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal; -
找出每一个员工的部门名称、工资等级、以及上级领导
select e.ename '员工',d.dname,s.grade,m.ename '领导' from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal left join emp m on e.mgr =m.empno; +--------+------------+-------+-------+ | 员工 | dname | grade | 领导 | +--------+------------+-------+-------+ | SMITH | RESEARCH | 1 | FORD | | ALLEN | SALES | 3 | BLAKE | | WARD | SALES | 2 | BLAKE | | JONES | RESEARCH | 4 | KING | | MARTIN | SALES | 2 | BLAKE | | BLAKE | SALES | 4 | KING | | CLARK | ACCOUNTING | 4 | KING | | SCOTT | RESEARCH | 4 | JONES | | KING | ACCOUNTING | 5 | NULL | | TURNER | SALES | 3 | BLAKE | | ADAMS | RESEARCH | 1 | SCOTT | | JAMES | SALES | 1 | BLAKE | | FORD | RESEARCH | 4 | JONES | | MILLER | ACCOUNTING | 2 | CLARK | +--------+------------+-------+-------+
-
-
什么是子查询?子查询都可以出现在哪里?
select语句当中嵌套select语句,被嵌套的select语句是子查询
-
子查询可以出现在哪里?
select ..这里可以是select.. from ..这里也可以是select.. where ..这里也可以是select.. -
找出高于平均薪资的员工
第一步:找出平均薪资 select avg(sal) from emp; +-------------+ | avg(sal) | +-------------+ | 2073.214286 | +-------------+ 第二步: select * from emp where sal>2073.214286; 合并: select * from emp where sal>(select avg(sal) from emp); +-------+-------+-----------+------+------------+---------+------+--------+ | EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO | +-------+-------+-----------+------+------------+---------+------+--------+ | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | +-------+-------+-----------+------+------------+---------+------+--------+
-
-
from后面嵌套子查询
-
找出每个部门平均薪水的薪资等级
第一步:找出每个部门平均薪水(按照部门编号分组,求sal的平均值) select deptno,avg(sal) 'avgsal' from emp group by deptno; +--------+-------------+ | deptno | avgsal | +--------+-------------+ | 20 | 2175.000000 | | 30 | 1566.666667 | | 10 | 2916.666667 | +--------+-------------+ 第二步:将以上的查询结果当作临时表t,让t表和salgrade s连接, 条件是t.avgsal between s.losal and hisal。 将(select deptno,avg(sal) 'avgsal' from emp group by deptno)嵌套在from中, 别名:t,其中avgsal是avg(sal)的别名 select t.*,grade from (select deptno,avg(sal) 'avgsal' from emp group by deptno) t join salgrade s on t.avgsal between s.losal and s.hisal; +--------+-------------+-------+ | deptno | avgsal | grade | +--------+-------------+-------+ | 20 | 2175.000000 | 4 | | 30 | 1566.666667 | 3 | | 10 | 2916.666667 | 4 | +--------+-------------+-------+ -
找出每个部门员工薪水等级的平均等级。
第一步:找出每个员工的薪水等级 select e.deptno,ename,sal,grade from emp e join salgrade s on e.sal between s.losal and s.hisal; +--------+--------+---------+-------+ | deptno | ename | sal | grade | +--------+--------+---------+-------+ | 20 | SMITH | 800.00 | 1 | | 30 | ALLEN | 1600.00 | 3 | | 30 | WARD | 1250.00 | 2 | | 20 | JONES | 2975.00 | 4 | | 30 | MARTIN | 1250.00 | 2 | | 30 | BLAKE | 2850.00 | 4 | | 10 | CLARK | 2450.00 | 4 | | 20 | SCOTT | 3000.00 | 4 | | 10 | KING | 5000.00 | 5 | | 30 | TURNER | 1500.00 | 3 | | 20 | ADAMS | 1100.00 | 1 | | 30 | JAMES | 950.00 | 1 | | 20 | FORD | 3000.00 | 4 | | 10 | MILLER | 1300.00 | 2 | +--------+--------+---------+-------+ 第二步:求薪资等级的平均值 select e.deptno,avg(grade) from emp e join salgrade s on e.sal between s.losal and s.hisal group by e.deptno; +--------+------------+ | deptno | avg(grade) | +--------+------------+ | 20 | 2.8000 | | 30 | 2.5000 | | 10 | 3.6667 | +--------+------------+
-
-
在select后面嵌套子查询
-
找出每个员工所在的部门名称,要求显示员工名称和部门名。
select ename,(select dname from dept d where d.deptno =e.deptno) as dname from emp e; +--------+------------+ | ename | dname | +--------+------------+ | SMITH | RESEARCH | | ALLEN | SALES | | WARD | SALES | | JONES | RESEARCH | | MARTIN | SALES | | BLAKE | SALES | | CLARK | ACCOUNTING | | SCOTT | RESEARCH | | KING | ACCOUNTING | | TURNER | SALES | | ADAMS | RESEARCH | | JAMES | SALES | | FORD | RESEARCH | | MILLER | ACCOUNTING | +--------+------------+
-
-
union(可以将查询结果集相加)
-
找出工作岗位是salesman和manager的员工
select ename,job from emp where job='manager' union select ename,job from emp where job='salesman'; +--------+----------+ | ename | job | +--------+----------+ | JONES | MANAGER | | BLAKE | MANAGER | | CLARK | MANAGER | | ALLEN | SALESMAN | | WARD | SALESMAN | | MARTIN | SALESMAN | | TURNER | SALESMAN | +--------+----------+ -
两张不相干的表中的数据拼接在一起显示
select ename from emp union select dname from dept; +------------+ | ename | +------------+ | SMITH | | ALLEN | | WARD | | JONES | | MARTIN | | BLAKE | | CLARK | | SCOTT | | KING | | TURNER | | ADAMS | | JAMES | | FORD | | MILLER | | ACCOUNTING | | RESEARCH | | SALES | | OPERATIONS | +------------+ 注意: 合并查询时,列数必须相同,列属性也要相同,如果两列所存储数据属性相同,列数序可以不同,但是不建议这样使用 最好相匹配 列名可以改,但必须是第一条语句中的别名
-
-
limit(重点中的重点,以后分页查询全靠它了)
-
limit是mysql中特有的,其他数据库中没有,不通用。(Oracle中有一个相同的机制,叫做rownum)
-
limit取结果集中的部分数据,这是他的作用。
-
语法机制:
limit startIndex,length startIndex表示起始位置。从0开始,0表示第一条数据 length表示取几个。 -
取出工资前五名的员工(思路:降序取前五个)
select ename,sal from emp order by sal desc; 取前五个 select ename,sal from emp order by sal desc limit 0,5; select ename,sal from emp order by sal desc limit 5; -
limit是sql语句最后执行的一个环节
select... 5 from... 1 where... 2 group by... 3 having... 4 order by... 6 limit... 7 -
找出工资排名在第四到第9名的员工
select ename,sal from emp order by sal desc limit 3,6; //从下标为3的开始取,取6个。 +--------+---------+ | ename | sal | +--------+---------+ | JONES | 2975.00 | | BLAKE | 2850.00 | | CLARK | 2450.00 | | ALLEN | 1600.00 | | TURNER | 1500.00 | | MILLER | 1300.00 | +--------+---------+ -
通用的标准分页sql
每页显示3条记录: 第1页:0,3 第2页:3,3 第3页:6,3 第4页:9,3 第5页:12,3 每页显示pageSize条记录: 第pageNo页:(pageNo-1)*pageSize,pageSize pageSize:每页显示多少天记录 pageNo:显示的第几页 java代码{ int pageNo = 2; //页码是2 int pageSize = 10; //每页显示10条 limit (pageNo - 1)*pageSize,pageSize }
-
表
-
创建表。
-
建表的语法格式:
create table 表名( 字段名 数据类型, 字段名 数据类型 ..... ); -
关于MySQL当中字段的数据类型,常见的:
int 整数型 (java中的int) bigint 长整型 (java中的long) float 浮点型 (java中的float ,double) char 定长字符串 (String) varchar 可变长字符串 (最多存255个字符)(StringBuffer/StringBuilder) date 日期类型 (对应java中的java.sql.Date类型) 以下两个对应:java中的Object BLOB 二进制大对象 (存储图片、视频等流媒体信息) Binary Large OBject CLOB 字符大对象(存储较大文本,比如:可以存储4G的字符串)Character Large OBject ...... -
char和varchar怎么选择?
在实际开发中,当某个字段中的数据长度不发生改变的时候,是定长的,例如:性别、生日等都采用char
当一个字段的数据长度不确定,例如:简介、姓名等都是采用varchar
-
BLOB和CLOB类型的使用
电影表:t_movie
id(int) name(varchar) playtime(date/char) haibao(BLOB) hisstory(CLOB) --------------------------------------------------------------------------- 1 蜘蛛侠 2 3 -
表名在数据库当中一般建议以:t_开始
创建学生表:
学生信息包括:学号、姓名、性别、班级编号、生日 学号:bigint 姓名:varchar 性别:char 班级编号:int 生日:char create table t_student( no bigint, name varchar(255), sex char(1), classno varchar(255), birth char(10) );
-
-
insert语句插入数据
-
语法格式
insert into 表名(字段名1,字段名2,字段名3,...) values(值1,值2,值3,...) 要求:字段的数量和值的数量相同,并且数据类型要对应相同 -
插入数据
insert into t_student(no,name,sex,classno,birth) values(1,'zhangsan','1','gaosan1ban','1950-10-12'); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | 1 | zhangsan | 1 | gaosan1ban | 1950-10-12 | +------+----------+------+------------+------------+ ============================================================================ insert into t_student(name,sex,classno,birth,no) values('lisi','2','gaosan1ban','1985-03-29',2); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | 1 | zhangsan | 1 | gaosan1ban | 1950-10-12 | | 2 | lisi | 2 | gaosan1ban | 1985-03-29 | +------+----------+------+------------+------------+ ============================================================================ insert into t_student(name) values('wangwu'); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | 1 | zhangsan | 1 | gaosan1ban | 1950-10-12 | | 2 | lisi | 2 | gaosan1ban | 1985-03-29 | | NULL | wangwu | NULL | NULL | NULL | +------+----------+------+------------+------------+ ============================================================================ insert into t_student(no) values(3); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | 1 | zhangsan | 1 | gaosan1ban | 1950-10-12 | | 2 | lisi | 2 | gaosan1ban | 1985-03-29 | | NULL | wangwu | NULL | NULL | NULL | | 3 | NULL | NULL | NULL | NULL | +------+----------+------+------------+------------+ -
default 设置默认值
drop table if exists t_student; //当这个表存在的话删除 create table t_student( no bigint, name varchar(255), sex char(1) default 1, //默认值为1 classno varchar(255), birth char(10) ); //插入信息 insert into t_student(name) values('zhangsan'); mysql> select * from t_student; +------+----------+------+---------+-------+ | no | name | sex | classno | birth | +------+----------+------+---------+-------+ | NULL | zhangsan | 1 | NULL | NULL | +------+----------+------+---------+-------+ 注意: 当一条insert语句执行成功之后,表格当中必然会多一条记录。即使多的这一行记录当中的某些字段是null,后期也没有办法再执行insert语句在此记录中插入数据了,只能使用update进行更新 -
插入数据时,字段可以省略不写,但是值必须与创建表时字段的顺序以及数量相对应。不能多也不能少
insert into t_student values(1,'jack','0','gaosan2ban','1986-10-23'); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | NULL | zhangsan | 1 | NULL | NULL | | 1 | jack | 0 | gaosan2ban | 1986-10-23 | +------+----------+------+------------+------------+ -
插入数据时一次可以插入多行
insert into t_student(no,name,sex,classno,birth) values (3,'rose','1','gaosi2ban','1988-06-17'), (4,'laotie','0','gaosi3ban','1975-08-24'); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | NULL | zhangsan | 1 | NULL | NULL | | 1 | jack | 0 | gaosan2ban | 1986-10-23 | | 3 | rose | 1 | gaosi2ban | 1988-06-17 | | 4 | laotie | 0 | gaosi3ban | 1975-08-24 | +------+----------+------+------------+------------+ ================================================================= //字段列也可以省略不写 insert into t_student values (5,'rose','1','gaosi2ban','1988-06-17'), (6,'laotie','0','gaosi3ban','1975-08-24'); mysql> select * from t_student; +------+----------+------+------------+------------+ | no | name | sex | classno | birth | +------+----------+------+------------+------------+ | NULL | zhangsan | 1 | NULL | NULL | | 1 | jack | 0 | gaosan2ban | 1986-10-23 | | 3 | rose | 1 | gaosi2ban | 1988-06-17 | | 4 | laotie | 0 | gaosi3ban | 1975-08-24 | | 5 | rose | 1 | gaosi2ban | 1988-06-17 | | 6 | laotie | 0 | gaosi3ban | 1975-08-24 | +------+----------+------+------------+------------+
-
-
表的复制
-
语法:
create table 表名 as select语句; 将查询结果当作表创建出来 create table emp1 as select * from emp; mysql> select * from emp1; +-------+--------+-----------+------+------------+---------+---------+--------+ | EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO | +-------+--------+-----------+------+------------+---------+---------+--------+ | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 | | 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 | | 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 | | 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 | | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 | | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 | | 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 | | 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 | | 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 | +-------+--------+-----------+------+------------+---------+---------+--------+ ================================================================================== create table emp2 as select empno,ename from emp; mysql> select * from emp2; +-------+--------+ | empno | ename | +-------+--------+ | 7369 | SMITH | | 7499 | ALLEN | | 7521 | WARD | | 7566 | JONES | | 7654 | MARTIN | | 7698 | BLAKE | | 7782 | CLARK | | 7788 | SCOTT | | 7839 | KING | | 7844 | TURNER | | 7876 | ADAMS | | 7900 | JAMES | | 7902 | FORD | | 7934 | MILLER | +-------+--------+
-
-
将查询结果插入到一张表中
create table dept1 as select * from dept; mysql> select * from dept1; +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | +--------+------------+----------+ insert into dept1 select * from dept; mysql> select * from dept1; +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | +--------+------------+----------+ -
修改数据:update
-
语法格式
update 表名 set 字段名1 = 值1,字段名2=值2....where 条件; 注意:没有条件整张表数据全部更新。 -
将部门10的LOC修改为SHANGHAI,将部门名称修改为RENSHIBU
update dept1 set LOC='SHANGHAI',DNAME='RENSHIBU' where deptno =10; mysql> select * from dept1; +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | RENSHIBU | SHANGHAI | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | | 10 | RENSHIBU | SHANGHAI | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | +--------+------------+----------+ -
更新所有记录
update dept1 set loc='x', dname='y'; mysql> select * from dept1; +--------+-------+------+ | DEPTNO | DNAME | LOC | +--------+-------+------+ | 10 | y | x | | 20 | y | x | | 30 | y | x | | 40 | y | x | | 10 | y | x | | 20 | y | x | | 30 | y | x | | 40 | y | x | +--------+-------+------+
-
-
删除数据
-
语法格式
delete from 表名 where 条件; 注意:没有条件全部删除 -
删除部门10 的数据
delete from dept1 where deptno=10; mysql> select * from dept1; +--------+-------+------+ | DEPTNO | DNAME | LOC | +--------+-------+------+ | 20 | y | x | | 30 | y | x | | 40 | y | x | | 20 | y | x | | 30 | y | x | | 40 | y | x | +--------+-------+------+ -
删除所有记录
delete from 表名; delete from dept1; mysql> select * from dept1; Empty set (0.00 sec) -
怎么删除大表中的数据(重点)
truncate table 表名; //表被截断,不可回滚。数据永久性丢失。截断表,只剩下表头,即创建表时的字段,数据一下全部丢弃,不可恢复。 mysql> select *from emp1; Empty set (0.00 sec) -
删除表
drop table 表名; //通用 drop table if exists 表名; //oracle不支持这种写法
-
-
对于表结构的修改,实用工具完成。因为在实际开发中表一旦设计好了之后,对表结构的修改也是很少的,修改表结构就是对之前的设计进行了否定,即使需要修改表结构,我们也可以直接使用工具操作。修改表结构的语句不会出现在java代码当中,出现在Java代码中的sql包括:insert、delete、update、select(这些都是表中的数据操作)
增删改查有一个术语:CRUD操作
Create(增)、Retrieve(检索)、Update(修改)、Delete(删除)
约束
-
什么是约束?常见的约束有哪些?
在创建表的时候,可以给表的字段添加相应的约束,添加约束的目的是为了保证表中数据的合法性、有效性、完整性。
常见的约束有哪些?
- 非空约束(not null):约束的字段不能为NULL
- 唯一约束(unique):约束的字段不能重复
- 主键约束(Primary Key):约束的字段既不能为NULL,也不能重复(简称PK)
- 外键约束(Foreign Key):(简称FK)
- 检查约束(check):注意Oracle数据库中有check约束,但是MySQL没有,目前MySQL不支持该约束。
-
非空约束 not null
drop table if exists t_user; create table t_user ( id int, username varchar(255) not null, password varchar(255) ); insert into t_user(id,username,password) values(1,'lisi','123'); 注意:not null 约束只有列级约束,只能添加到列后面。没有表级约束 -
唯一性约束
-
唯一约束修饰的字段具有唯一性,不能重复,但可以为NULL
-
案例:给某一列添加unique
drop table if exists t_user; create table t_user( id int, username varchar(255) unique ); --插入信息 insert into t_user values(1,'zhangsan'); insert into t_user values(2,'zhangsan'); --ERROR 1062 (23000): Duplicate entry 'zhangsan' for key 't_user.username' insert into t_user(id) values(2); insert into t_user(id) values(3); insert into t_user(id) values(4); -
给两个列或多个列添加unqiue
在列后面添加的约束叫:列级约束。id int unique。 声明完字段之后,再添加约束。如:unique(id,name)是表级约束。多个字段联合约束才需要用表级约束 drop table if exists t_user; create table t_user( id int, usercode varchar(255), username varchar(255), unique(usercode,username) --【表级约束】 ); insert into t_user values(1,'111','zs'); insert into t_user values(2,'111','ls'); insert into t_user values(3,'222','zs'); select * from t_user; +------+----------+----------+ | id | usercode | username | +------+----------+----------+ | 1 | 111 | zs | | 2 | 111 | ls | | 3 | 222 | zs | +------+----------+----------+ 注意:unique(列,列....),这种方式的唯一约束是如果这两个或几个列,则这几个值都相同时,才会触发。 是多个字段联合起来添加一个约束unique drop table if exists t_user; create table t_user( id int, usercode varchar(255) unique, --列级约束 username varchar(255) unique ); insert into t_user values(1,'111','zs'); insert into t_user values(2,'111','ls'); insert into t_user values(3,'222','zs'); select * from t_user; +------+----------+----------+ | id | usercode | username | +------+----------+----------+ | 1 | 111 | zs | +------+----------+----------+ 注意:这种方式是添加了两个约束,只要某个列中有重复的就报错
-
-
主键约束
-
怎么给一张表添加主键约束
drop table if exists t_user; create table t_user( id int primary key, username varchar(255), email varchar(255) ); insert into t_user values(1,'zs','zs@123.com'); insert into t_user values(2,'ls','ls@123.com'); insert into t_user values(3,'ww','ww@123.com'); select * from t_user; +----+----------+------------+ | id | username | email | +----+----------+------------+ | 1 | zs | zs@123.com | | 2 | ls | ls@123.com | | 3 | ww | ww@123.com | +----+----------+------------+ insert into t_user(id,username,email) values(1,'jack','jack@123.com'); --ERROR 1062 (23000): Duplicate entry '1' for key 't_user.PRIMARY' insert into t_user(username,email) values('jack','jack@123.com'); --ERROR 1364 (HY000): Field 'id' doesn't have a default value 根据以上的测试得出:id是主键,因为添加了主键约束,主键中的数据不能为NULL,也不能重复。 主键的特点:不能为NULL,也不能重复 -
主键的专业术语
主键约束:primary key 主键字段:id字段添加primary key之后,id叫做主键字段 主键值:id字段中每一个值都是主键值。 -
主键有什么作用?
--表的设计三范式中有要求,第一范式就要求任何一张表都应该有主键 --主键的作用:主键值是这行记录再这张表当中的唯一标识(就像一个人的身份证号码一样) -
主键的分类?
-
根据主键字段的字段数量来划分:
单一主键(推荐使用、常用)
复合主键(多个字段联合起来添加一个主键约束,复合主键不建议使用,因为复合主键违背三范式)
-
根据主键性质来划分:
自然主键:主键值最好就是一个和业务没有任何关系的自然数。(这种方式是推荐的)
业务主键:主键值和系统的业务挂钩,例如:拿着银行卡的卡号做主键,拿着身份证号码作为主键。(不推荐使用)。最好不要拿着和业务挂钩的字段作为主键。因为以后的业务一旦发生改变的时候,主键值可能也需要随之发生变化,但有的时候没有办法发生变化,因为变化可能会导致主键值重复。
-
-
一张表的主键约束只能有一个。
-
使用表级约束方式定义主键
drop table if exists t_user; create table t_user( id int, username varchar(255), primary key(id) ); insert into t_user(id,username) values(1,'zs'); insert into t_user(id,username) values(2,'ls'); insert into t_user(id,username) values(3,'ws'); insert into t_user(id,username) values(4,'cs'); select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 2 | ls | | 3 | ws | | 4 | cs | +----+----------+ insert into t_user(id,username) values(4,'cx'); --ERROR 1062 (23000): Duplicate entry '4' for key 't_user.PRIMARY' 复合主键,不需要掌握 drop table if exists t_user; create table t_user( id int, username varchar(255), password varchar(255), primary key(id,username) ); -
mysql提供主键自增:(非常重要)
drop table if exists t_user; create table t_user( id int primary key auto_increment,--id字段自动维护一个自增的数字,从1开始,以1递增 username varchar(255) ); insert into t_user(username) values('a'); insert into t_user(username) values('b'); insert into t_user(username) values('c'); insert into t_user(username) values('d'); insert into t_user(username) values('e'); insert into t_user(username) values('f'); select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | a | | 2 | b | | 3 | c | | 4 | d | | 5 | e | | 6 | f | +----+----------+ --提示:oracle当中也提供了一个自增机制,叫做:序列(sequence)对象
-
-
外键约束
-
关于外键约束的专业术语:
外键约束:foreign key 外键字段:添加有外键约束的字段 外键值:外键字段中的每一个值
业务背景:请设计数据库表,用来维护学生和班级的信息
-
第一张方案:一张表存储所有数据
no(pk) name classno classname ----------------------------------------------------------------------- 1 zs1 101 大兴区经济技术开发区亦庄二中高三1班 2 zs2 101 大兴区经济技术开发区亦庄二中高三1班 3 zs3 102 大兴区经济技术开发区亦庄二中高三2班 4 zs4 102 大兴区经济技术开发区亦庄二中高三2班 5 zs5 102 大兴区经济技术开发区亦庄二中高三2班缺点:冗余【不推荐】
-
第二种方案:两张表(班级表和学生表)
t_class 班级表 cno cname -------------------------------------------------- 101 大兴区经济技术开发区亦庄二中高三1班 102 大兴区经济技术开发区亦庄二中高三2班 t_student 学生表 sno sname cno(该字段添加外键约束) --------------------------------------------- 1 zs1 101 2 zs2 101 3 zs3 102 4 zs4 102 5 zs5 102 -
将以上表的建表语句写出来
t_student中的classno字段引用t_class中的cno字段,此时t_student表叫做子表,t_class叫做父表 顺序要求: 删除数据的时候,先删除子表,再删除父表 添加数据的时候,先添加父表,再添加子表。 创建表的时候,先创建父表,再创建子表 删除表的时候,先删除子表,再删除父表 drop table if exists t_student; drop table if exists t_class; create table t_class( cno int primary key, cname varchar(255) ); create table t_student( sno int, sname varchar(255), classno int, primary key(sno), foreign key(classno) references t_class(cno) ); insert into t_class values(101,'xxxxxxxxxxxxxxxx'); insert into t_class values(102,'yyyyyyyyyyyyyyyy'); insert into t_student values(1,'zs1','101'); insert into t_student values(2,'zs2','101'); insert into t_student values(3,'zs3','102'); insert into t_student values(4,'zs4','102'); insert into t_student values(5,'zs5','102'); select * from t_student; select * from t_class; -
外键值可以为NULL吗?
外键可以为null
-
外键字段引用其他表的某个字段的时候,被引用的字段必须是主键吗?
注意:被引用的字段不一定是主键,但至少具有unique约束。即:此列值不能重复。但一般是引用主键字段
-
存储引擎
-
完整的建表语句
CREATE TABLE `t_x`( `id` int(11) DEFAULT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8;注意:在MySQL当中,凡是标识符时可以使用飘号(`)括起来的,最好别用,不通用。
建表的时候可以指定存储引擎,也可以指定字符集。
mysql默认使用的存储引擎是InnoDB方式。默认采用的字符集是:utf8
-
什么是存储引擎呢?
存储引擎这个名字只有在mysql中存在。(oracle中有对应的机制,没有特殊的名字,就是”表的存储方式“)
mysql支持很多存储引擎,每一个存储引擎都有自己的优缺点,需要在合适的时机选择合适的存储引擎。
-
查看当前mysql支持的存储引擎
show engines \G mysql 8.0.23版本支持的存储引擎有9个: *************************** 1. row *************************** Engine: MEMORY Support: YES Comment: Hash based, stored in memory, useful for temporary tables Transactions: NO XA: NO Savepoints: NO *************************** 2. row *************************** Engine: MRG_MYISAM Support: YES Comment: Collection of identical MyISAM tables Transactions: NO XA: NO Savepoints: NO *************************** 3. row *************************** Engine: CSV Support: YES Comment: CSV storage engine Transactions: NO XA: NO Savepoints: NO *************************** 4. row *************************** Engine: FEDERATED Support: NO Comment: Federated MySQL storage engine Transactions: NULL XA: NULL Savepoints: NULL *************************** 5. row *************************** Engine: PERFORMANCE_SCHEMA Support: YES Comment: Performance Schema Transactions: NO XA: NO Savepoints: NO *************************** 6. row *************************** Engine: MyISAM Support: YES Comment: MyISAM storage engine Transactions: NO XA: NO Savepoints: NO *************************** 7. row *************************** Engine: InnoDB Support: DEFAULT Comment: Supports transactions, row-level locking, and foreign keys Transactions: YES XA: YES Savepoints: YES *************************** 8. row *************************** Engine: BLACKHOLE Support: YES Comment: /dev/null storage engine (anything you write to it disappears) Transactions: NO XA: NO Savepoints: NO *************************** 9. row *************************** Engine: ARCHIVE Support: YES Comment: Archive storage engine Transactions: NO XA: NO Savepoints: NO -
常见的存储引擎
-
MyISAM
Engine: MyISAM Support: YES Comment: MyISAM storage engine Transactions: NO XA: NO Savepoints: NOMyISAM是mysql最常用的存储引擎,但是这种引擎不是默认的。
MyISAM采用三个文件组织一张表:
xxx.frm(存储格式的文件)、xxx.MYD(存储表中的数据文件)、xxx.MYI(存储表中索引的文件)
优点:可被压缩,节省存储空间。并且可以转换为只读表,提高检索效率
缺点:不支持事务。
-
InnoDB
Engine: BLACKHOLE Support: YES Comment: /dev/null storage engine (anything you write to it disappears) Transactions: NO XA: NO Savepoints: NO优点:支持事务、行级锁、外键等。这种存储引擎数据的安全得到保障。
表的结构存储在xxx.frm文件中。数据存储在tablespace这样的表空间中(逻辑概念),无法被压缩,无法转换成只读。
这种InnoDBDB存储引擎在MySQL数据库崩溃之后提供自动恢复机制。
InnoDB支持级联删除和级联更新
级联删除:删除父表中的数据,则子表中引用父表中数据的一起删除 级联更新:父表中被引用的主键值如果更新,则子表中使用外键引用此值的会一起更新 -
MEMORY,以前叫:HEPA引擎
Engine: MEMORY Support: YES Comment: Hash based, stored in memory, useful for temporary tables Transactions: NO XA: NO Savepoints: NO缺点:不支持事务。数据容易丢失,因为所有数据和索引都是存储在内存当中的
优点:查询速度最快
-
事务
-
什么是事务?
一个事务是一个完整的业务逻辑单元,不可再分。
比如:银行账户转账,从A账户向B账户转账10000,需要执行两条update语句:
update t_act set balance = balance - 10000 where actno = 'zhangsan'; update t_act set balance = balance - 10000 where actno = 'lisi';以上两条DML语句必须同时成功,或者同时失败。不允许出现一条成功,一条失败。
要想保证以上两条DML语句同时成功或者同时失败,那么就需要使用数据库的“事务机制”
-
和事务相关的语句只有:DML语句。(insert、delete、update)
为什么?因为他们这三个语句都是和数据库表当中的“数据”相关的。
事务的存在就是为了保证数据的完整性、安全性
-
假设所有的业务都能使用1条DML语句就能搞定,还需要事务机制吗?
一条DML就能完成,就不需要事务了。但实际情况不是这样的,通常一个“事儿(事务/业务)”需要多条DML语句共同联合完成。
-
事务的特性,事务包括四大特性:ACID
A、原子性:事务是最小的工作单元,不可再分
C、一致性:事务必须保证多条DML语句同时成功或者同时失败。
I、隔离性:事务A与事务B之间有隔离。
D、持久性:持久性说的是最终数据必须持久化到硬盘文件中,事务才算成功的结束。
-
关于事务之间的隔离性
事务隔离性存在隔离级别,理论上隔离级别包括4个:
-
第一级别:读未提交(read uncommitted)
对方事务还没有提交,我们当前事务可以读取到对方未提交的数据。
读未提交存在:脏读现象(Dirty Read)现象:读到了脏的数据。
-
第二级别:读已提交(read committed)
对方事务提交之后的数据我方可以读取到。
这种隔离级别解决了:脏读现象。存在的问题:不可重复读。事务执行过程中,如果需要使用的表中的数据一直在被修改,则一直在读取的都是最新的数据。
-
第三级别:可重复读(repeatable read)
解决了:不可重复读问题。存在问题:读取到的数据可能是幻象。即事务执行过程汇中,需要使用的数据被修改了,但读取的还是之前没有被修改前的数据
-
第四级别:序列化读/串行化读
解决所有的问题。效率低,需要事务排队。
-
Oracle数据库默认的隔离级别:读已提交
MySQL数据库默认的隔离级别:可重复读
-
-
演示事务
-
mysql事务默认情况下是自动提交的(什么是自动提交?只要执行任意一条DML语句则提交一次)
如何关闭自动提交?
start transaction -
准备表:
drop table if exists t_user; create table t_user( id int primary key auto_increment, username varchar(255) ); -
演示:mysql中的事务是支持自动提交的,只要执行一条DML,则提交一次。
mysql> insert into t_user(username) values('zs'); Query OK, 1 row affected (0.01 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | +----+----------+ 1 row in set (0.00 sec) mysql> rollback; Query OK, 0 rows affected (0.01 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | +----+----------+ 1 row in set (0.00 sec) -
演示:使用start transaction; 关闭自动提交机制,以及rollback; 回滚机制
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into t_user(username) values('lisi'); Query OK, 1 row affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 2 | lisi | +----+----------+ 2 rows in set (0.00 sec) mysql> insert into t_user(username) values('wangwu'); Query OK, 1 row affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 2 | lisi | | 3 | wangwu | +----+----------+ 3 rows in set (0.00 sec) mysql> rollback; Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | +----+----------+ 1 row in set (0.00 sec) -
演示:提交事务:commit。
mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into t_user(username) values('rose'); Query OK, 1 row affected (0.00 sec) mysql> insert into t_user(username) values('jack'); Query OK, 1 row affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | +----+----------+ 4 rows in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | +----+----------+ 4 rows in set (0.00 sec) mysql> rollback; Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | +----+----------+ 4 rows in set (0.00 sec) -
注意:start transaction后,如果提交/回滚事务,则会恢复自动提交机制。
回滚事务时,只能回滚到上一次保存的那里。
-
-
使用两个事务演示以上的隔离级别
-
第一:演示read uncommitted
设置事务的全局隔离级别:
set global transaction isolation level read uncommitted;--读未提交查看事务的全局隔离级别:
mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | REPEATABLE-READ | +--------------------------------+演示:
事务1: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select username from t_user; --查看表中数据 +----------+ | username | +----------+ | zs | | wangwu | | rose | | jack | | smith | +----------+ 事务2: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into t_user(username) values('alice'); --插入数据 Query OK, 1 row affected (0.00 sec) 事务1继续执行: mysql> select username from t_user; +----------+ | username | +----------+ | zs | | wangwu | | rose | | jack | | smith | | alice | +----------+ 6 rows in set (0.00 sec) 事务2在没有提交的情况下,事务1读取到了事务2未提交的数据,这就是读未提交 -
演示读已提交
设置事务的全局隔离级别为:读已提交
mysql> use datas; --先打开所要使用的数据库 Database changed mysql> set global transaction isolation level read committed;--设置隔离级别 Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation;--查看隔离级别 +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | READ-COMMITTED | +--------------------------------+ 1 row in set (0.00 sec) mysql> exit Bye --设置完后退出重新登入演示
事务1: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; --查看数据 +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | | 7 | smith | | 9 | ben | +----+----------+ 6 rows in set (0.00 sec) 事务2: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into t_user(username) values('jijibao'); --插入数据未提交 Query OK, 1 row affected (0.00 sec) 事务1继续: mysql> select * from t_user; --查看数据,跟之前的数据一样 +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | | 7 | smith | | 9 | ben | +----+----------+ 6 rows in set (0.00 sec) 事务2继续: mysql> commit; Query OK, 0 rows affected (0.01 sec) --事务2提交 事务1继续: mysql> select * from t_user; --事物1执行过程中,事务2提交,再次读取,读取到事物2提交的数据 +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | | 7 | smith | | 9 | ben | | 10 | jijibao | +----+----------+ 7 rows in set (0.00 sec) 通过结果可得出:读已提交:事务1在执行过程中只能读取到另一个事务已经提交的东西,未提交的读取不到。 -
第三:演示repeatable read
设置事务的全局隔离级别为:可重复读
mysql> use datas; Database changed mysql> set global transaction isolation level repeatable read;--可重复读 Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | REPEATABLE-READ | +--------------------------------+ 1 row in set (0.00 sec) mysql> exit Bye演示
事务1: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | | 7 | smith | | 9 | ben | | 10 | jijibao | +----+----------+ 7 rows in set (0.00 sec) 事务2: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> delete from t_user; --删除表 Query OK, 7 rows affected (0.01 sec) mysql> commit; --提交 Query OK, 0 rows affected (0.01 sec) mysql> select * from t_user; --表中已经没有数据了 Empty set (0.00 sec) 事务1: mysql> select * from t_user; --事务1中读取的还是之前的数据 +----+----------+ | id | username | +----+----------+ | 1 | zs | | 4 | wangwu | | 5 | rose | | 6 | jack | | 7 | smith | | 9 | ben | | 10 | jijibao | +----+----------+ 7 rows in set (0.00 sec) mysql> rollback --事务结束后 Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; --再次读取 Empty set (0.00 sec) --没有数据了。 结论:可重复读:读取的是修改之前的数据,是幻象。 -
序列化读
设置事务的全局隔离级别为:序列化读
mysql> use datas; Database changed mysql> set global transaction isolation level serializable; --序列化读 Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | SERIALIZABLE | +--------------------------------+ 1 row in set (0.00 sec)演示:
事务1: mysql> start transaction; Query OK, 0 rows affected (0.01 sec) mysql> select * from t_user; --查看数据 +----+----------+ | id | username | +----+----------+ | 11 | hehe | +----+----------+ 1 row in set (0.00 sec) mysql> insert into t_user(username) values('haha'); --查看后插入一条数据 Query OK, 1 row affected (0.00 sec) 事务2: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from t_user; --执行到这里后事务不再执行,自动进入等待状态 --此时只能等待事务1提交/回滚之后才会继续执行此事务。 事务1: mysql> commit; Query OK, 0 rows affected (0.00 sec) 事务2: +----+----------+ | id | username | +----+----------+ | 11 | hehe | +----+----------+ | 12 | haha | +----+----------+ 4 rows in set (47.79 sec) 结论:序列化读:一个事务执行完之后另一个事务才会继续执行
-
索引
-
什么是索引?索引有什么用?
索引就相当于一本书的目录,通过目录可以快速的找到对应的资源。
-
在数据库方面,查询一张表的时候有两种检索方式
第一种方式:全表扫描。
第二种方式:根据索引检索(效率很高)
-
索引为什么可以提高检索效率呢?
最根本的原理:缩小了扫描的范围
-
索引虽然可以提高检索效率,但是不能随意的添加索引。因为索引也是数据库当中的对象,也需要数据库不断的维护。是有维护成本的,比如:表中的数据经常被修改,这种就不适合添加索引,因为数据一旦修改,索引需要重新排序,进行维护。
-
添加索引是给某一个字段,或者某些字段添加索引
select ename,sal from emp where ename = 'SMITH';当ename字段上没有添加索引的时候,以上sql字句会进行全表扫描,扫描ename字段中所有的值
当ename字段上添加索引后,以上sql语句会根据索引扫描,快速定位。
-
-
怎么创建索引对象?怎么删除索引对象?
-
创建索引对象:
create index 索引名称 on 表名(字段名); -
删除索引对象:
drop index 索引名称 on 表名;
-
-
什么时候考虑给字段添加索引?(满足什么条件)
- 数据量庞大(根据客户的需求、根据线上的环境)
- 该字段很少的DML操作(insert、delete、update)(因为字段进行修改操作,索引也需要维护)
- 该字段经常出现在where子句中(经常根据哪个字段查询)
-
注意:主键和具有unique的约束的字段会自动添加索引。
根据主键查询效率较高,尽量根据主键检索。
-
查看sql语句的执行计划:
mysql> explain select ename,sal from emp where sal = 5000;
给薪资sql字段添加索引:
create index emp_sal_index on emp(sal);添加索引后再次检索

-
索引的底层采用的数据结构是:B+Tree
-
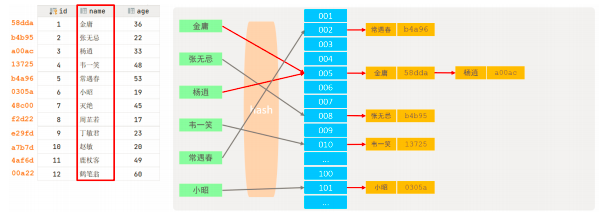
索引的实现原理
通过B Tree 缩小扫描范围,底层索引进行了排序、分区,索引会携带数据在表中的“物理地址”,最终通过索引检索到数据之后,获取到关联的物理地址,通过物理地址定位表中的数据,效率是最高的
select ename from emp where ename = 'SMITH'; 通过索引转换为: select ename from emp where 物理地址 = 0x3;
-
索引的分类
单一索引:给单个字段添加索引
复合索引:给多个字段联合起来添加1个索引
主键索引:主键上会自动添加索引
唯一索引:有unique约束的字段上会自动添加索引
-
索引什么时候失效?
select ename from emp where ename like '%A%';模糊查询的时候,第一个通配符使用的是%,这个时候索引时失效的。
视图(View)
-
什么是视图?
站在不同的角度去看数据。(同一张表的数据,通过不同的角度去看待)
-
怎么创建视图?怎么删除视图?
create view myview as select empno,ename from emp; drop view myview;注意:只有DQL语句才能以视图对象的方式创建出来。
-
对视图进行增删改查操作,会影响到原表数据。(通过视图影响原表数据的,不是直接操作原表)
可以对视图进行CRUD操作。
-
面向视图操作
create table emp1 as select * from emp; create view myview as select empno,ename,sal from emp1; --创建视图 mysql> select * from myview; +-------+--------+---------+ | empno | ename | sal | +-------+--------+---------+ | 7369 | SMITH | 800.00 | | 7499 | ALLEN | 1600.00 | | 7521 | WARD | 1250.00 | | 7566 | JONES | 2975.00 | | 7654 | MARTIN | 1250.00 | | 7698 | BLAKE | 2850.00 | | 7782 | CLARK | 2450.00 | | 7788 | SCOTT | 3000.00 | | 7839 | KING | 5000.00 | | 7844 | TURNER | 1500.00 | | 7876 | ADAMS | 1100.00 | | 7900 | JAMES | 950.00 | | 7902 | FORD | 3000.00 | | 7934 | MILLER | 1300.00 | +-------+--------+---------+ update myview set ename ='hehe',sal =1 where empno =7369; --通过视图修改原表数据 mysql> select * from myview where ename='hehe'; +-------+-------+------+ | empno | ename | sal | +-------+-------+------+ | 7369 | hehe | 1.00 | +-------+-------+------+ 1 row in set (0.01 sec) mysql> select * from emp1 where ename='hehe'; +-------+-------+-------+------+------------+------+------+--------+ | EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO | +-------+-------+-------+------+------------+------+------+--------+ | 7369 | hehe | CLERK | 7902 | 1980-12-17 | 1.00 | NULL | 20 | +-------+-------+-------+------+------------+------+------+--------+ delete from myview where empno =7369; --通过视图删除原表数据 mysql> delete from myview where empno =7369; Query OK, 0 rows affected (0.00 sec) mysql> select * from emp1 where ename='hehe'; Empty set (0.00 sec) -
视图的作用:
视图可以隐藏表的实现细节。保密级别较高的系统,数据库只对外提供相关的视图,java程序员只对视图对象进行CRUD。
数据库的导入导出(DBA命令)
-
将数据库当中的数据导出
在windows的dos命令窗口中执行:(导出整个库)
mysqldump datas>D:\datas.sql -uroot -p101在windows的dos命令窗口中执行:(导出指定数据库中的指定表)
mysqldump datas emp>D:\datas.sql -uroot -p101 -
导入数据
create database datas; --这里的数据库名字可以是别的。 use datas; source D:\datas.sql
数据库设计三范式
-
什么是设计范式
设计表的依据。按照这三个范式设计的表不会出现数据冗余。
-
三范式都是哪些?
-
第一范式:任何一张表都应该有主键,并且每一个字段原子性不可再分。

-
第二范式:建立在第一范式的基础上,所有非主键字段完全依赖主键,不能产生部分依赖

多对多 ——三张表,关系表两个外键
t_student学生表 sno(pk) sname -------------------- 1 张三 2 李四 3 王五 t_teacher 讲师表 tno tname ----------------------- 1 王老师 2 张老师 3 李老师 t_stutea_relation 学生讲师关系表 id(pk) sno(fk) tno(fk) --------------------------------------- 1 1 3 2 1 1 3 2 2 4 2 3 5 3 1 6 3 3 -
第三范式:建立在第二范式的基础上,所有非主键字段直接依赖主键,不能产生传递依赖

一对多?两张表,多的表家外键。
班级t_class cno(pk) cname --------------------- 1 班级a 2 班级b 学生表t_student sno(pk) sname classno(fk) -------------------------------------------- 101 张1 班级a 102 张2 班级a 103 张3 班级b 104 张4 班级b 105 张5 班级b -
提醒:在实际的开发中,以满足客户的需求为主,有时候会拿数据冗余换取执行速度。
-
-
一对一怎么设计
-
一对一设计有两种设计方案:主键共享
t_user_login 用户登陆表 id(pk) username password ------------------------------------------ 1 zs 123 2 ls 456 t_user_detail 用户详细信息表 id(pk+fk) realname tel ··· ----------------------------------------------------- 1 张三 123456 2 李四 654321 -
第二种方案:外键唯一
t_user_login 用户登陆表 id(pk) username password ------------------------------------------ 1 zs 123 2 ls 456 t_user_detail 用户详细信息表 id(pk) realname tel userid(fk+unique)··· ---------------------------------------------------------------------- 1 张三 123456 1 2 李四 654321 2
-







![Linux学习[14]默认文本编辑vi/vim介绍常用指令演示指令汇总](https://img-blog.csdnimg.cn/d78de18e3e2b4b75a3c93eec5de40507.png)