背景说明:
Mysql调优,是大家日常常见的调优工作。所以,Mysql调优是一个非常、非常核心的面试知识点。在40岁老架构师 尼恩的读者社群(50+)中,其相关面试题是一个非常、非常高频的交流话题。
近段时间,有小伙伴面试京东,说遇到一个去重 调优的面试题:
100W记录去重,是用distinct还是group by,说说理由?
MYsql 设计的时候,如何高性能进行数据去重,也是调优的重点和难点,社群中,还遇到过大概的变种:
形式1:distinct效率更高还是group by效率更高??
形式2:为啥 group by 会导致 慢 mysql 产生?
形式3:…, 后面的变种很多,都会收入 《尼恩Java面试宝典》。
这里尼恩给大家 对数据去重的 调优,做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个 题目以及参考答案,收入咱们的《尼恩Java面试宝典》V73,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》、《尼恩Java面试宝典》 的PDF文件,请到文末公号【技术自由圈】获取
接下来,我们先来看一下distinct和group by的功能、使用和底层原理。
文章目录
- 背景说明:
- 首先:来看distinct功能和用法
- distinct用法
- distinct多列去重
- 其次:来看GROUP BY 的使用场景
- Group by底层原理
- group by在去重场景的使用
- 单列去重
- 多列去重
- group by 多列去重 和 单列去重的区别
- distinct和group by去重原理分析
- Group by的隐式排序
- 那么,为啥要优先推荐group by呢?
- 说在最后
- 技术自由的实现路径 PDF:
- 实现你的 架构自由:
- 实现你的 响应式 自由:
- 实现你的 spring cloud 自由:
- 实现你的 linux 自由:
- 实现你的 网络 自由:
- 实现你的 分布式锁 自由:
- 实现你的 王者组件 自由:
- 实现你的 面试题 自由:
首先:来看distinct功能和用法
DISTINCT 是一种用于去除 SELECT 语句返回结果中重复行的关键字。在使用 SELECT 语句查询数据时,如果结果集中包含重复的行,可以使用 SELECT DISTINCT 语句来去除这些重复的行。例如,以下语句返回一个包含重复行的结果集:
SELECT name FROM users;
可以使用以下语句来去除重复的行:
SELECT DISTINCT name FROM users;
这样就可以得到一个不包含重复行的结果集。需要注意的是,DISTINCT 关键字会对查询的性能产生一定的影响,因为它需要对结果集进行排序和去重的操作。因此,在使用 DISTINCT 关键字时需要谨慎,尽可能地使用索引来优化查询,以提高查询的性能。
distinct用法
SELECT DISTINCT columns FROM table_name WHERE where_conditions;
例如:
mysql> select distinct age from student;
+------+
| age |
+------+
| 10 |
| 12 |
| 11 |
| NULL |
+------+
4 rows in set (0.01 sec)
DISTINCT 关键词用于返回唯一不同的值。放在查询语句中的第一个字段前使用,且作用于主句所有列。
注意:DISTINCT子句将所有NULL值视为相同的值
如果列具有NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值。
distinct多列去重
distinct多列的去重,则是根据指定的去重的列信息来进行,
即只有所有指定的列信息都相同,才会被认为是重复的信息。
SELECT DISTINCT column1,column2 FROM table_name WHERE where_conditions;
mysql> select distinct sex,age from student;
+--------+------+
| sex | age |
+--------+------+
| male | 10 |
| female | 12 |
| male | 11 |
| male | NULL |
| female | 11 |
+--------+------+
5 rows in set (0.02 sec)
其次:来看GROUP BY 的使用场景
GROUP BY 主要的使用场景是 在分组 聚合。
具体来说,GROUP BY 子句通常用于将查询结果按照一个或多个列进行分组,然后对每个组进行聚合计算。
例如,假设一个表存储了每个人的姓名、年龄和所在城市,可以使用 GROUP BY 子句按照城市对人进行分组,并计算每个城市的平均年龄或人口数量等统计信息。
GROUP BY 子句通常与聚合函数(例如 COUNT、SUM、AVG、MAX 和 MIN)一起使用,以计算每个组的聚合值。例如,可以使用 GROUP BY 子句和 COUNT 函数来计算每个城市中的人数。
但是,除了分组 聚合,GROUP BY 还可以用来 进行数据去重,并且在某些特定场景下,性能超过 distinct
需要注意的是:GROUP BY 子句会对结果集进行排序,因此可能会导致使用临时文件排序。如果查询中包含 ORDER BY 子句,使用不当会产生临时文件排序,容易产生慢 SQL 问题。
具体该怎么优化呢? 请持续 跟踪 尼恩 的《尼恩Java面试宝典》,后面结合其他的面试题进行介绍。
Group by底层原理
group by语句根据一个或多个列对结果集进行分组。在分组的列上通常配合 COUNT, SUM, AVG等函数一起使用。
假定有个需求:统计每个城市的用户数量。
对应的 SQL 语句如下:
select city ,count(*) as num from user group by city;
执行部分结果如下:

先用Explain查看一下执行计划
explain select city ,count(*) as num from user group by city;

在 Extra 字段里面,我们可以看到以下信息:
- 用到了Using temporary, 表示执行时创建了一个内部临时表。
注意这里的临时表可能是内存上的临时表,也有可能是硬盘上的临时表,当然,如果临时表比较小,就是基于内存的,可以肯定的是: 基于内存的临时表的性能高,时间消耗肯定要比基于硬盘的临时表的实际消耗小。 - 用到了Using filesort, 表示执行过程中没有使用索引的排序,而是使用临时文件。
"Using filesort"是MySQL的EXPLAIN输出中的一个短语,表示查询需要使用临时文件对结果集进行排序。
这可能发生在查询包括ORDER BY子句或GROUP BY子句时,而数据库无法使用索引满足排序顺序。
使用临时文件对大型结果集进行排序可能会导致磁盘I/O和内存使用方面的昂贵开销,因此最好尽可能避免“Using filesort”。
一些避免文件排序的策略包括使用适当的索引优化查询,限制结果集的大小或修改查询以使用不同的排序算法。
那么group by语句为啥会同时用到临时表和临时文件 排序呢?
首先看下整个执行流程:
- 在执行过程中首先创建内存临时表,表里有
city,num两个字段,city为主键。 - 扫描 user 表,依次取出一行数据,数据中
city字段的值为 c;
- 如果临时表中没有主键为 c 的行, 则插入一条新纪录(c , 1);
- 如果存在,则更新该行为 (c, num + 1);
- 遍历完后,再根据
city进行排序,最后将结果集返回给客户端。
这个流程的执行示意图如下:

然后进入到第二阶段,进行内存排序。 其中对内存临时表的排序执行步骤,本质上和的order by 流程基本一致。
- 数据从内存临时表中拷贝到
sort buffer中 sort buffer进行排序,根据实际情况采用全字段排序或rowid排序,- 排序结果写回到内存临时表中,
- 从内存临时表中返回结果集。
流程示意图如下所示:

group by在去重场景的使用
分为两个去重场景进行介绍:
- 单列去重
- 多列去重
单列去重和多列去重的区别在于去重的依据不同。
单列去重是指针对某一列数据进行去重,即将该列中重复的值只保留一个。例如,如果有一个包含重复数据的姓名列表,可以使用单列去重将重复的姓名去除,只保留一个。
多列去重是指针对多列数据进行去重,即将多列数据中重复的行只保留一行。例如,如果有一个包含姓名、年龄和所在城市的列表,可以使用多列去重将重复的姓名、年龄和城市都相同的行去除,只保留一行。
单列去重
GROUP BY 子句,大部分都是用于单列去重。
例如,假设有一个表包含学生姓名和所在城市,可以使用以下 SQL 语句进行单列去重,以获取不同城市的学生数量:
SELECT city, COUNT(DISTINCT name) FROM student GROUP BY city;
在上述语句中,使用 GROUP BY 子句对城市进行分组,并使用 COUNT 和 DISTINCT 函数计算每个城市中不同姓名的数量。这将返回一个结果集,其中每个行包含一个城市和该城市中不同姓名的数量,从而达到了单列去重的目的。
对于单列去重来说,group by的使用和distinct类似:
单列去重语法:
SELECT columns FROM table_name WHERE where_conditions GROUP BY columns;
执行:
mysql> select age from student group by age;
+------+
| age |
+------+
| 10 |
| 12 |
| 11 |
| NULL |
+------+
4 rows in set (0.02 sec)
注意:和DISTINCT子句一样,group by将所有NULL值视为相同的值
如果列具有NULL值,并且对该列使用group by子句,MySQL将保留一个NULL值,并删除其它的NULL值。
多列去重
GROUP BY 子句也可以用于多列去重。
例如,假设有一个表包含学生姓名、所在城市和年龄,可以使用以下 SQL 语句进行多列去重,以获取不同城市、不同年龄的学生数量:
SELECT city, age, COUNT(DISTINCT name)
FROM student
GROUP BY city, age;
在上述语句中,使用 GROUP BY 子句对城市和年龄进行分组,并使用 COUNT 和 DISTINCT 函数计算每个城市、年龄组合中不同姓名的数量。这将返回一个结果集,其中每个行包含一个城市、一个年龄和该城市、年龄组合中不同姓名的数量,从而达到了多列去重的目的。
多列去重语法:
SELECT column1, column2 FROM table_name WHERE where_conditions GROUP BY column1, column2;
多列去重例子:
mysql> select sex,age from student group by sex,age;
+--------+------+
| sex | age |
+--------+------+
| male | 10 |
| female | 12 |
| male | 11 |
| male | NULL |
| female | 11 |
+--------+------+
5 rows in set (0.03 sec)
group by 多列去重 和 单列去重的区别
GROUP BY 子句用于将结果集按照指定的列进行分组,并对每个组进行聚合操作。在 GROUP BY 子句中指定的列将成为聚合键,用于将结果集中的行分组。在聚合操作之后,可以使用 GROUP BY 子句来去重。
单列去重是指使用 GROUP BY 子句将结果集按照单个列进行分组,并对每个组进行聚合操作。例如,以下查询将返回一个包含不同城市名称的列表:
SELECT city FROM mytable GROUP BY city;
多列去重是指使用 GROUP BY 子句将结果集按照多个列进行分组,并对每个组进行聚合操作。例如,以下查询将返回一个包含不同城市和州的列表:
SELECT city, state FROM mytable GROUP BY city, state;
group by的原理是先对结果进行分组排序,然后返回每组中的第一条数据。所以,区别在于:单列去重只按照一个列进行分组,而多列去重则按照多个列进行分组。
distinct和group by去重原理分析
在大多数例子中,DISTINCT可以被看作是特殊的GROUP BY,它们的实现都基于分组操作,且都可以通过松散索引扫描、紧凑索引扫描来实现。
松散索引扫描和紧凑索引扫描都是 MySQL 中的索引扫描方式。
松散索引扫描(Loose Index Scan)是指 MySQL 在使用索引进行查询时,如果索引中的数据不连续,MySQL 将会扫描整个索引树,直到找到符合条件的记录。这种扫描方式会增加查询的时间复杂度,因为需要扫描整个索引树。
紧凑索引扫描(Tight Index Scan)是指 MySQL 在使用索引进行查询时,如果索引中的数据连续,MySQL 将会按照顺序读取索引数据块,直到找到符合条件的记录。这种扫描方式会减少查询的时间复杂度,因为可以按照顺序读取索引数据块,避免了扫描整个索引树。
通常情况下,如果使用的是 InnoDB 存储引擎,MySQL 会自动选择使用紧凑索引扫描。但是,如果使用的是 MyISAM 存储引擎,或者查询条件中包含了不等于(<>)或不包含(NOT IN)操作符,MySQL 将会使用松散索引扫描。
总的来说,紧凑索引扫描比松散索引扫描更快,因为它可以避免扫描整个索引树。但是,如果使用的是 MyISAM 存储引擎,或者查询条件中包含了不等于或不包含操作符,MySQL 将会使用松散索引扫描,这时候就需要注意查询的效率。
DISTINCT和GROUP BY都是可以使用索引进行扫描搜索的。
例如以下两条sql,我们对这两条sql进行分析,可以看到,在extra中,这两条sql都使用了紧凑索引扫描Using index for group-by。
所以,在一般情况下,对于相同语义的DISTINCT和GROUP BY语句,我们可以对其使用相同的索引优化手段来进行优化。
mysql> explain select int1_index from test_distinct_groupby group by int1_index;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set (0.05 sec)
mysql> explain select distinct int1_index from test_distinct_groupby;
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |
+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+
1 row in set (0.05 sec)
但对于GROUP BY来说,在MYSQL8.0之前,GROUP Y默认会依据字段进行隐式排序。
可以看到,下面这条sql语句在使用了临时表的同时,还进行了filesort。
mysql> explain select int6_bigger_random from test_distinct_groupby GROUP BY int6_bigger_random;
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
| 1 | SIMPLE | test_distinct_groupby | NULL | ALL | NULL | NULL | NULL | NULL | 97402 | 100.00 | Using temporary; Using filesort |
+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+
1 row in set (0.04 sec)
Group by的隐式排序
对于隐式排序,我们可以参考Mysql官方的解释:
GROUP BY 默认隐式排序(指在 GROUP BY 列没有 ASC 或 DESC 指示符的情况下也会进行排序)。然而,GROUP BY进行显式或隐式排序已经过时(deprecated)了,要生成给定的排序顺序,请提供 ORDER BY 子句。
参考连接:
MySQL :: MySQL 5.7 Reference Manual :: 8.2.1.14 ORDER BY Optimization
所以,在Mysql8.0之前,Group by会默认根据作用字段(Group by的后接字段)对结果进行排序。在能利用索引的情况下,Group by不需要额外进行排序操作;但当无法利用索引排序时,Mysql优化器就不得不选择通过使用临时表然后再排序的方式来实现GROUP BY了。要命的是,当临时结果集的大小超出系统设置临时表大小时,Mysql会将临时表数据copy到磁盘上面再进行操作,语句的执行效率会变得极低。这也是Mysql选择将此操作(隐式排序)弃用的原因。
基于上述原因,Mysql在8.0时,对此进行了优化更新:
从前(Mysql5.7版本之前),Group by会根据确定的条件进行隐式排序。
在mysql 8.0中,已经移除了这个功能,所以不再需要通过添加order by null 来禁止隐式排序了,但是,查询结果可能与以前的 MySQL 版本不同。
如果要生成给定顺序的结果,请按通过ORDER BY指定需要进行排序的字段。
MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.16 ORDER BY Optimization
因此,我们的结论也出来了:
- 在语义相同,有索引的情况下:group by和distinct都能使用索引,效率相同。因为group by和distinct近乎等价,distinct可以被看做是特殊的group by。
- 在语义相同,无索引的情况下:distinct效率高于group by。原因是: distinct 和 group by都会进行分组操作,但在Mysql8.0之前group by会进行隐式排序,导致触发filesort,sql执行效率低下。从Mysql8.0开始,Mysql就删除了隐式排序,所以,此时在语义相同,无索引的情况下,group by和distinct的执行效率也是近乎等价的。
总之,从Mysql8.0 开始, 不管有索引 、还是索引, group by和distinct的执行效率也是近乎等价的
但是, 100W级数据去重场景,优先推荐使用 group by。
那么,为啥要优先推荐group by呢?
相比于distinct来说,group by的语义明确。
- group by语义更为清晰
- group by可对数据进行更为复杂的一些处理
- 由于distinct关键字会对所有字段生效,在进行复合业务处理时,group by的使用灵活性更高,
- group by能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。
所以,不论是100W级数据去重场景,还是普通数据去重场景,建议优先选用 group by
说在最后
本文收录于 《尼恩Java面试宝典》 V73版PDF,请到文末公号【技术自由圈】获取
基本上,把尼恩的 《尼恩Java面试宝典》吃透,大厂offer很容易拿到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
学习过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
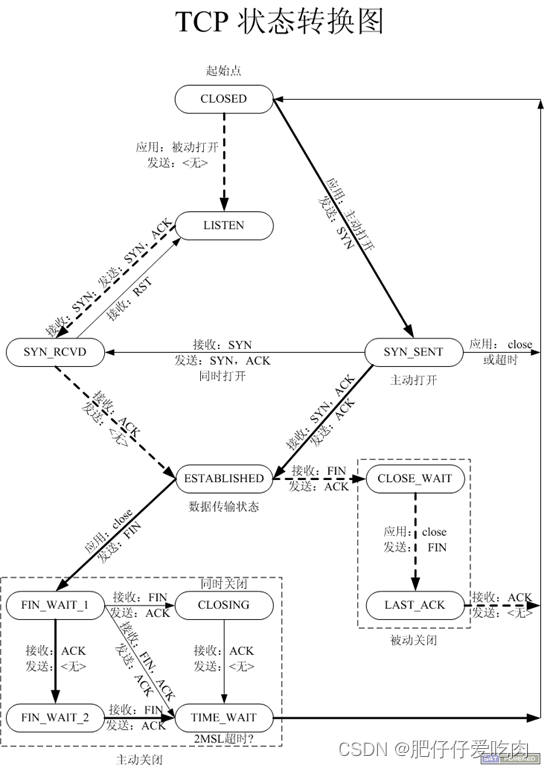
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
4000页《尼恩Java面试宝典 》 40个专题
以上尼恩 架构笔记、面试题 的PDF文件更新,▼请到下面【技术自由圈】公号取 ▼