目录
- 前言
- 数据偏见对人们的影响
- 衡量偏见
- 活跃偏差或少数人的智慧
- 数据偏见
- 其他
- 参考文献
前言
本文参考Ricardo Baeza-Yates 2018年发表在《Communications of the ACM》的论文Bias on the Web,论文旨在提高人们对网络使用和内容中存在的偏见对我们所有人造成的潜在影响的认识。
也希望对推荐排序方向上的探索有所启发,在为满足人们需求的Web系统设计中考虑这一点。
Bias 在一些文献和博客中也称为偏差,但在此处翻译成偏见更合适一些,后文也会使用偏差一词,两者在英文中的意义是等价的。
数据偏见对人们的影响
自古以来,偏见就植根于人类文化和历史之中。而且,由于数字数据的兴起,它现在可以比以往更快地传播并接触更多的人。大数据中的偏见,影响着我们的每一个人,尽管很多时候我们没有意识到它的存在甚至不知道它如何(正面或负面地)影响我们的判断和行为。对于少数群体而言,数据偏见可能影响到生活的方方面面,小到一次搜索的结果、一个个性化广告的展示,大到抵押贷款的审批。这些结果往往都是由算法控制的,而算法就是基于带有偏见的数据训练和优化的。

衡量偏见
解决偏见的第一个挑战是如何定义和衡量它。 从统计学的角度来看,偏见是由不准确的估计或抽样过程引起的系统性偏差。因此,变量的分布可能相对于原始的、可能未知的分布有偏差。此外,文化偏见可以在我们对共同个人信仰的倾向中找到,而认知偏见会影响我们的行为和决策方式。
重要见解:
- 对偏见的任何补救措施都始于对其存在的认识。
- 网络上的偏见反映了我们内心的偏见,以更微妙的方式表现出来
- 在设计真正满足用户需求的基于Web的系统时,我们必须考虑并说明偏见。
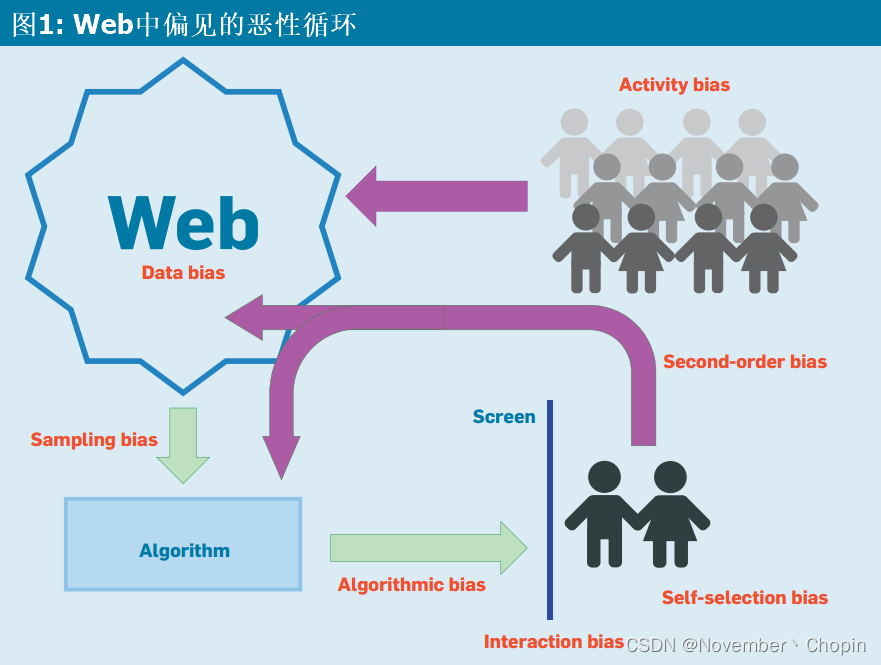
图1显示了偏见(红色)是如何影响网络的发展及其使用的:
- 人们使用网络导致的活跃偏差(Activity bias)和没有互联网接入的人的隐藏偏差。
- 他们产生了网络上的数据偏差(Data bias),这些带有偏见的数据污染了基于这些数据的算法。
- 通过我们与网站的交互,产生了交互偏差、自我选择偏差。
- 内容和使用循环回网络,造成各种类型的二阶偏见。
视频解读地址:CACM June 2018 - Bias on the Web
活跃偏差或少数人的智慧
活跃偏差(Activity Bias)或少数人的智慧(Wisdom of a Few)。
2011年,吴等人[28]关于人们如何在推特上关注其他人的研究发现,0.05%的最受欢迎的人吸引了几乎50%的参与者,也就是说,数据集中一半的推特用户只关注少数精选的名人。沉默的大多数网络用户,他们只看网络而不贡献,这本身就是一种自我选择偏见。[14]
Ricardo Baeza-Yates 和 Saez-Trumper 分析了四个数据集,结果是令人吃惊的:
- 在2009年的Facebook数据集中,7%的活跃用户发布了50%的帖子。
- 在2013年更大的亚马逊评论数据集中,4%的活跃用户撰写了一半的评论。
- 在2011年的一个非常大的数据集中,有1200万活跃的推特用户,2%的用户发表了一半的帖子。
- 英文维基百科一半条目的第一个版本是由0.04%的注册编辑(约2000人)研究和发布的,这表明只有一小部分用户为网络做出了贡献,认为它代表了整个人群的智慧是一种错觉。
只有4%的人自愿写亚马逊数据集中所有评论的一半是没有意义的,也是很奇怪的。因此2015年10月,亚马逊开始了一场反付费虚假评论的企业运动,该运动在2016年继续进行,起诉了近1000名被指控撰写评论的人。
当然,偏差也有有益的一面:
虽然英文维基百科的例子是最有偏见的,但它代表了积极的偏见。英文维基百科开始时的2000人可能引发了雪球效应,帮助维基百科成为今天的巨大百科全书资源。
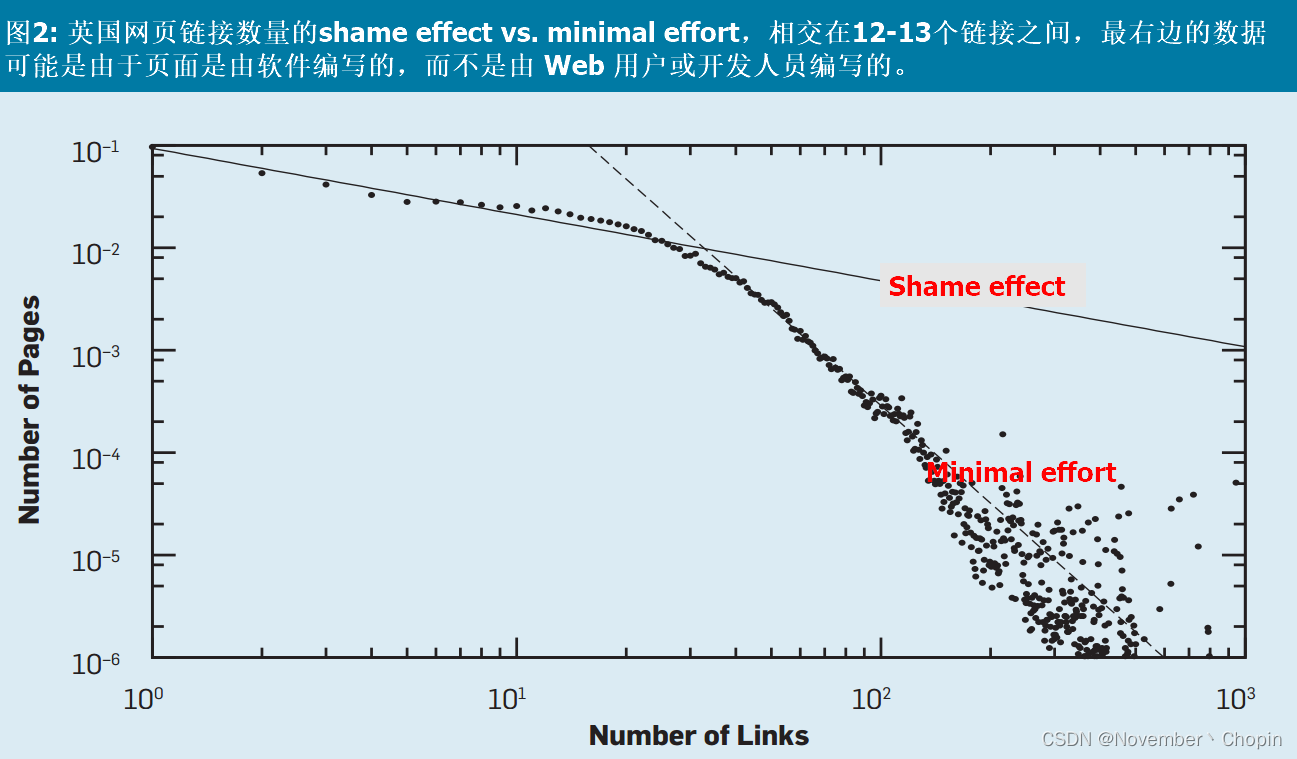
Zipf Law,也称为最小努力原则,即做最少的事来达到目的。认为许多人只做很少,而很少有人做很多,这可能有助于解释很大一部分活动偏见。然而,经济和社会激励也在产生这一结果方面发挥了作用。例如,Zipf Law可以在大多数Web度量中看到(例如每个网站的页数或每个网页的链接数)。图2的x-轴表示英国网页的链接数量,y-轴表示拥有相应链接数的网页的数量。然而,在x轴的开头有一股强大的社会力量,作者称之为“shame effect”,它使斜率不那么负。它还表明,许多人更喜欢付出最少的努力,尽管大多数人也需要感觉他们做了足够多的事情来避免对自己的努力感到羞耻。 这两种影响是人们在网络上活动的共同特征。
数字沙漠(digital desert)。诺贝尔奖获得者Herbert Simon说,“丰富的信息造成了注意力的匮乏。” 因此,活跃偏差在网络上产生了一个“digital desert”,或者说没人见过的网络内容。一个下限来自推特数据,Ricardo Baeza-Yates 和 Saez-Trumper 发现1.1%的推文是由没有追随者的人撰写和发布的。回顾维基百科使用统计数据给了我们一个上限,即2014年5月添加或修改的文章中有31%在6月份从未被访问过。网络上数字沙漠的实际规模可能在1%到31%范围的前一半。
偏差并不总是负面的。 由于活跃偏差,所有级别的Web缓存在保持最常用的内容随时可用方面都非常有效,网站和Internet网络的负载总体上比可能的要低得多。此外,正面的偏差还包括 Inductive Bias。
数据偏见
其他
rich-get-richer。Web数据中的Bias及使用这些数据,会污染基于Web应用背后的算法,从而提供同样有偏见的结果。
参考文献
[8] Baeza-Yates, R. and Saez-Trumper, D. Wisdom of the crowd or wisdom of a few? An analysis of users’ content generation. In Proceedings of the 26th ACM Conference on Hypertext and Social Media (Guzelyurt, TRNC, Cyprus, Sept. 1–4). ACM Press, New York, 2015, 69–74.
[14] Gong, W., Lim, E.-P., and Zhu, F. Characterizing silent users in social media communities. In Proceedings of the Ninth International AAAI Conference on Web and Social Media (Oxford, U.K., May 26–29). AAAI, Fremont, CA, 2015, 140–149.
[28] Wu, S., Hofman, J.M., Mason, W.A., and Watts, D.J. Who says what to whom on Twitter. In Proceedings of the 20th International Conference on the World Wide Web (Hyderabad, India, Mar. 28–Apr. 1). ACM Press, New York, 2011, 705–714
![[附源码]Python计算机毕业设计SSM竞赛报名管理系统(程序+LW)](https://img-blog.csdnimg.cn/64ae3c31059040209ee0e959d902f434.png)