1.前言
RandLA-Net(Random Sampling and Local Feature Aggregator Network)是一种处理点云数据的神经网络结构,采用随机采样(Random Sampling, RS)以降低点云密度并减少计算量。尽管随机采样可能会丢掉一些有用的信息,但通过局部空间编码和基于注意力机制的池化中提取和保留关键信息得到了缓解。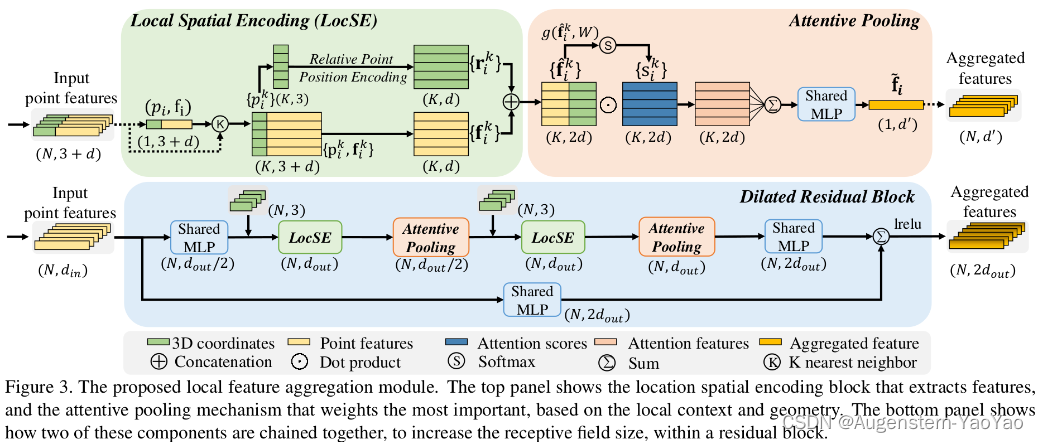
RandLA-Net利用局部特征整合(Local Feature Aggregator,LFA)来提取和增强点特征,包括两个关键部分:局部空间编码(Local Spatial Encoding)和注意力池化(Attentive Pooling)。局部空间编码在每个点周围创建一个局部坐标系统,增加了网络对于点云的几何结构的理解。注意力池化则根据每个点的重要性对特征进行动态加权。这样的设计允许网络关注那些对任务更重要的点,从而提高了特征提取的精度。RandLA-Net中另一个关键的模块是扩张残差模块(Dilated Residual Block),模块通过引入不同扩张率的卷积层来增加感受野,进一步提高了网络对点云数据的理解能力。
RandLA-Net通过随机采样、局部特征整合和扩张残差模块的设计,有效地处理了大规模点云数据,不仅降低了计算复杂度,同时也保持了较高的准确性和鲁棒性。
2.环境配置
RandLA-Net源工程的GitHub链接如下:
https://github.com/QingyongHu/RandLA-Net![]() https://github.com/QingyongHu/RandLA-Net
https://github.com/QingyongHu/RandLA-Net
上面为QingyongHu/RandLA-Net的tensorflow实现代码。QingyongHu本人在知乎的博客链接如下:
[CVPR 2020 Oral] RandLA-Net:大场景三维点云语义分割新框架(已开源) - 知乎PS:【如需转载,请通过评论或者私信联系我】 论文链接: RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point CloudsTensorFlow代码: QingyongHu/RandLA-Net先上效果图: Introduction实现高效、准确…![]() https://zhuanlan.zhihu.com/p/105433460本CSDN博客是复现一个基于tf2的工程(适用于RTX3090等较新的GPU软硬件环境,笔者的硬件环境为RTX2080Ti):
https://zhuanlan.zhihu.com/p/105433460本CSDN博客是复现一个基于tf2的工程(适用于RTX3090等较新的GPU软硬件环境,笔者的硬件环境为RTX2080Ti):
https://github.com/luckyluckydadada/randla-net-tf2![]() https://github.com/luckyluckydadada/randla-net-tf2所用数据集为KITTI Odometry Benchmark Velodyne point clouds (80 GB), KITTI Odometry Benchmark calibration data (1 MB) 和 SemanticKITTI label data (179MB),链接如下:
https://github.com/luckyluckydadada/randla-net-tf2所用数据集为KITTI Odometry Benchmark Velodyne point clouds (80 GB), KITTI Odometry Benchmark calibration data (1 MB) 和 SemanticKITTI label data (179MB),链接如下:
SemanticKITTI - A Dataset for LiDAR-based Semantic Scene Understanding![]() http://semantic-kitti.org/dataset.html#download
http://semantic-kitti.org/dataset.html#download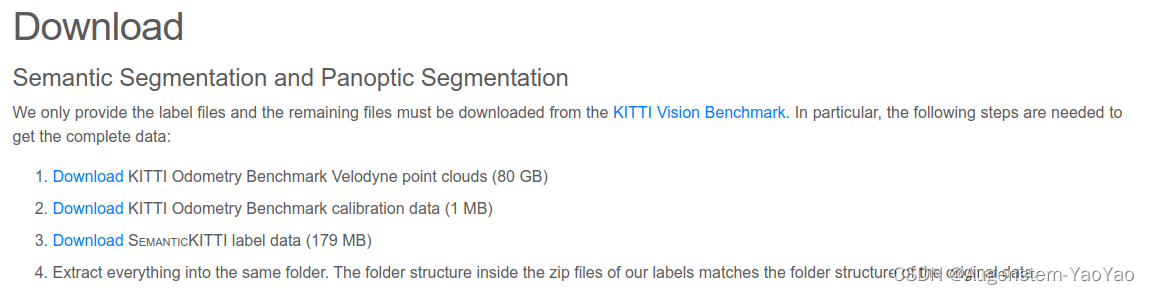
或通过以下云盘链接下载:
KITTI Semantic百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间
笔者的训练环境Ubuntu20.04+ Tensorflow-gpu2.6,硬件为RTX2080Ti(22G显存)。GPU驱动配置请参考:
《环境感知算法——1.简介与GPU驱动、CUDA和cudnn配置》![]() https://blog.csdn.net/wenquantongxin/article/details/130858818
https://blog.csdn.net/wenquantongxin/article/details/130858818
1)创建RandLA-Net虚拟环境
请在合适的文件夹内,使用终端运行以下命令,通过git获得randlanet工程文件,并创建名为randlanet的conda虚拟环境。
git clone --depth=1 https://github.com/luckyluckydadada/randla-net-tf2.git
conda create -n randlanet python=3.6
conda activate randlanet定位至git获得的randla-net-tf2文件夹目录,修改helper_requirements.txt 中h5py的版本信息,从h5py==2.10.0修改为h5py~=3.1.0,即helper_requirements.txt修改为如下内容,以避免与TensorFlow的版本冲突错误。
numpy
h5py~=3.1.0 # 原为h5py==2.10.0
cython==0.29.15
open3d-python==0.3.0
pandas
scikit-learn==0.21.3
scipy
PyYAML接下来,运行以下命令,以在conda中安装TF2、CUDA与其他必要Python包:
pip install tensorflow-gpu==2.6 -i https://pypi.tuna.tsinghua.edu.cn/simple --timeout=120
conda install cudatoolkit=11.2 cudnn=8.1 -c=conda-forge
pip install -r helper_requirements.txt --timeout=120
sh compile_op.s
pip install keras==2.6.02)准备数据集
将前述KITTI Odometry Benchmark Velodyne point clouds (80 GB), KITTI Odometry Benchmark calibration data (1 MB) 和 SemanticKITTI label data (179MB)等数据集整理为如下工程脚手架形式:
semantic_kitti_dataset
├── sequences
│ ├── 00
│ │ ├── velodyne
│ │ │ ├── 000000.bin
│ │ │ ├── 000001.bin
│ │ │ └── ...
│ │ ├── labels
│ │ │ ├── 000000.label
│ │ │ ├── 000001.label
│ │ │ └── ...
│ │ ├── calib.txt
│ │ ├── poses.txt
│ │ └── times.txt
│ ├── 01
│ │ ├── velodyne
│ │ ├── labels
│ │ ├── calib.txt
│ │ ├── poses.txt
│ │ └── times.txt
│ └── ...
修改randla-net-tf2/utils/data_prepare_semantickitti.py的第22~23行中关于dataset_path和output_path的定义,以与实际数据集目录匹配。
其中,dataset_path为上面工程脚手架的源数据集文件目录,output_path为体素化取值0.06(grid_size=0.06)之后的数据目录。
Tips: 在点云数据处理中,grid_size是指的是在点云的划分网格(或者说是体素化)过程中,每个网格或体素的大小。体素化就是把三维空间划分为一系列的体素(voxel,三维空间中的像素的概念),每个体素都有一个固定的体积,然后可以在每个体素中统计或处理点云数据。这个方法可以大大简化点云处理的复杂度,因为处理每个体素的数据比直接处理原始的点云数据要简单得多。grid_size = 0.06意味着每个体素的大小是0.06m x 0.06m x 0.06m,即每个体素的边长为0.06米。
例如,dataset_path和output_path设置为如下代码段所示,意味着在当前Linux用户的Documents/Documents/randla-net-tf2/Seq_Input目录内储存了原始数据集,处理后的数据集位于.../Documents/randla-net-tf2/Seq_Out_0.06位置。
dataset_path = '/home/'+getpass.getuser()+'/Documents/randla-net-tf2/Seq_Input'
output_path = '/home/'+getpass.getuser()+'/Documents/randla-net-tf2/Seq_Out' + '_' + str(grid_size)
注意,上述代码中不建议出现中文字符,如果数据集储存于含有中文字符的目录内,可以考虑通过ln -s命令链接至全英文目录。
此时,运行utils/data_prepare_semantickitti.py。
python utils/data_prepare_semantickitti.py上述代码处理.bin数据集。处理时长视计算机性能在若干分钟至若干小时不等。
3)修改Batch Size
训练中Batch Size的定义由helper_tool.py定义。实测下列helper_tool.py定义参数用于semantickitti数据集的训练,需要约21G显存占用,可根据显存情况增减batch_size。
class ConfigSemanticKITTI:
k_n = 16 # KNN
num_layers = 4 # Number of layers
num_points = 4096 * 11 # Number of input points
num_classes = 19 # Number of valid classes
sub_grid_size = 0.06 # preprocess_parameter
batch_size = 12 # batch_size during training
val_batch_size = 20 # batch_size during validation and test
train_steps = 250 # Number of steps per epochs
val_steps = 100 # Number of validation steps per epoch
sub_sampling_ratio = [4, 4, 4, 4] # sampling ratio of random sampling at each layer
d_out = [16, 64, 128, 256] # feature dimension
num_sub_points = [num_points // 4, num_points // 16, num_points // 64, num_points // 256]
noise_init = 3.5 # noise initial parameter
max_epoch = 100 # maximum epoch during training
learning_rate = 1e-2 # initial learning rate
lr_decays = {i: 0.95 for i in range(0, 500)} # decay rate of learning rate
train_sum_dir = 'train_log'
saving = True
saving_path = None
修改训练参数时请注意,由于多个数据集的class定义都比较相似,请仔细查看所修改的class,例如SemanticKITTI数据集就只需修改class ConfigSemanticKITTI。
4)模型训练
在开始模型训练之前,还需要修改main_SemanticKITTI.py中dataset_path的定义。dataset_path应修改为准备数据集过程中data_prepare_semantickitti.py的output_path完整目录。例如,如果在data_prepare_semantickitti.py中定义:
output_path = '/home/'+getpass.getuser()+'/Documents/randla-net-tf2/Seq_Out' + '_' + str(grid_size)那么,main_SemanticKITTI.py的self.dataset_path应修改为对应的文件目录:
self.dataset_path = '/home/username/Documents/randla-net-tf2/Seq_Out_0.06'
以上为全部准备工作。
使用以下代码开始训练:
python main_SemanticKITTI.py --mode train --gpu 1 训练过程中,可以另起终端,运行以下代码查看GPU占用情况。
watch -n 2 nvidia-smi完成训练后,代码会自动进行一次评估:
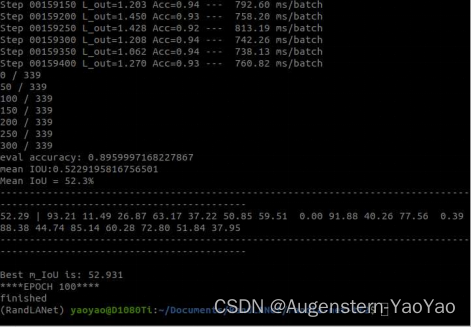
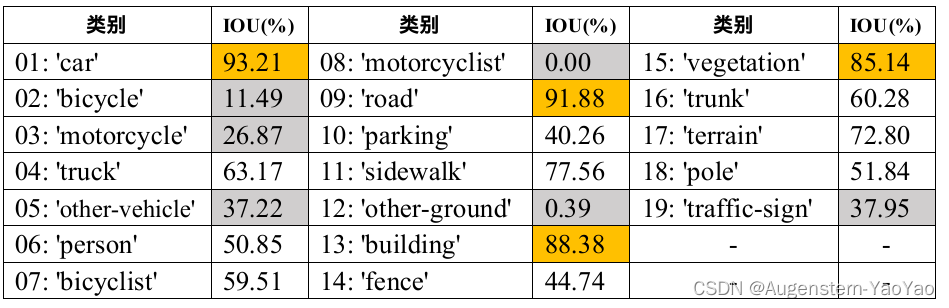
例如上图,训练获得的模型主要指标为:mIOU=52.3%,平均准确率为89.60%。
整理每个子类别IOU如下:
指定数据集测试可使用以下代码:
# 对21号数据集进行评估
python main_SemanticKITTI.py --gpu 0 --mode test --test_area 21 3.结果分析
根据IOU评估表,car、truck、vegetation、building等空间体积较大、数据集出现次数较多的类别准确性最高;motorcyclist、bicycle、traffic-sign等激光雷达反射面积较小,数据集标注较少、特征不明显的这些类别表现较差。
通过以下代码进行可视化:
python main_SemanticKITTI.py --gpu 0 --mode VIS --test_area 16给出一些识别结果:

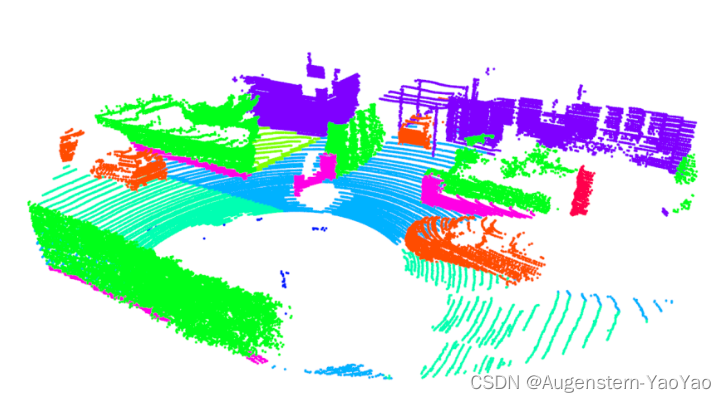
在较为开阔的运行环境中,由于反射回的点云很少,点云图非常稀疏并出现了断层分布,无法有效判断周围的运行环境:

由于在训练数据集中,行人、骑自行车的人等小众类别样本数量可能相对较少,导致模型在这些类别上的识别能力较弱。某些类别在形状或特征上可能非常相似,同时出现体积上的重叠,这会使得模型难以区分这些相似的类别,或被NMS网络错误过滤。
4. 总结
RandLA-Net是一种用于处理大规模3D点云数据的神经网络模型,其主要特点、优点和不足如下:
- 特点
随机抽样策略:RandLA-Net采用了一种随机抽样策略,通过随机选择点云数据中的点以减少输入数据的规模,从而提高处理速度。
局部特征学习:RandLA-Net设计了一种局部特征学习策略,能够在临近点间捕获丰富的特征信息。
轻量级聚合:RandLA-Net引入了一种轻量级的特征聚合策略,在多个尺度上进行特征学习和融合,然后将这些多尺度特征整合到一起以形成全局描述。这样可以大大降低处理大规模3D点云数据所需的计算资源,从而提高模型的效率和可扩展性,能够在不影响性能的情况下,减少模型的计算量和内存需求。
- 优点
高效性:由于其随机抽样策略和轻量级的特征聚合,RandLA-Net能够在处理大规模3D点云数据时,实现更高的效率。
准确性:尽管RandLA-Net减少了输入数据的规模,但其局部特征学习和轻量级的特征聚合策略使得模型在准确性上仍然具有竞争力。
- 不足
随机抽样的限制:尽管随机抽样策略可以提高处理速度,但这种方法可能会导致一些重要特征的丢失,特别是在点云数据中有细微结构或复杂形状时。局限于点云数据:RandLA-Net是专门为处理3D点云数据设计的,这意味着它可能不适用于其他类型的数据。
需要大量数据:为了充分训练和优化RandLA-Net,需要大量的标注过的3D点云数据。然而,获取和标注这种数据通常是昂贵和耗时的。
在这些优点和不足的基础上,RandLA-Net可以为许多现实世界的问题提供解决方案,如自动驾驶汽车的环境感知、机器人导航、以及城市规划等。