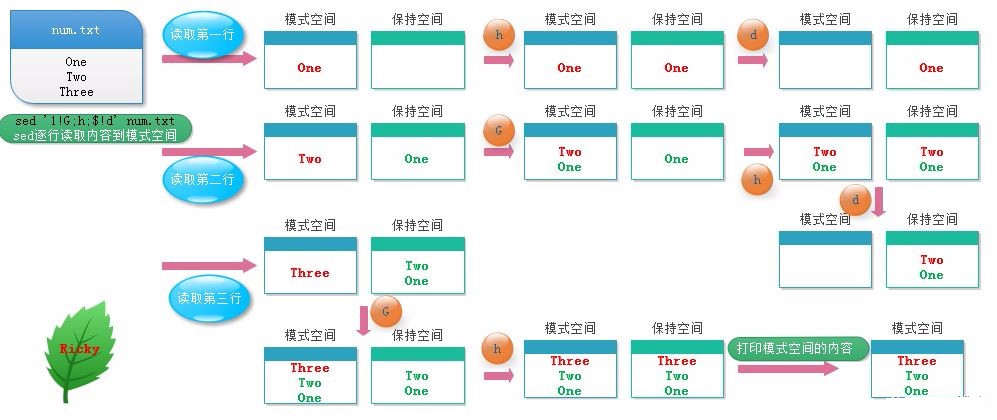
1、认识索引
假设现在大家要去 MySQL 书中找索引的内容,大家应该不会拿着 MySQL 的书一张一张去找,而是会看MySQL 书的目录,然后通过目录找到索引对应的页码,再去对应的页码中查看索引的内容
索引的优点:
索引就相当于书的目录,运用索引可以加快查找的速度
索引的缺点:
索引虽然可以加快查找的速度,但是索引也提高了增、删、改的开销,因为进行增、删、改的时候需要调整已经创建好的索引
索引还提高了空间的开销,构造索引也就需要额外的硬盘空间来保存
index 表示 索引,不管是查看索引,还是创建索引,......,只有是关于索引的操作一般都会有 index 这个单词
2、索引的操作
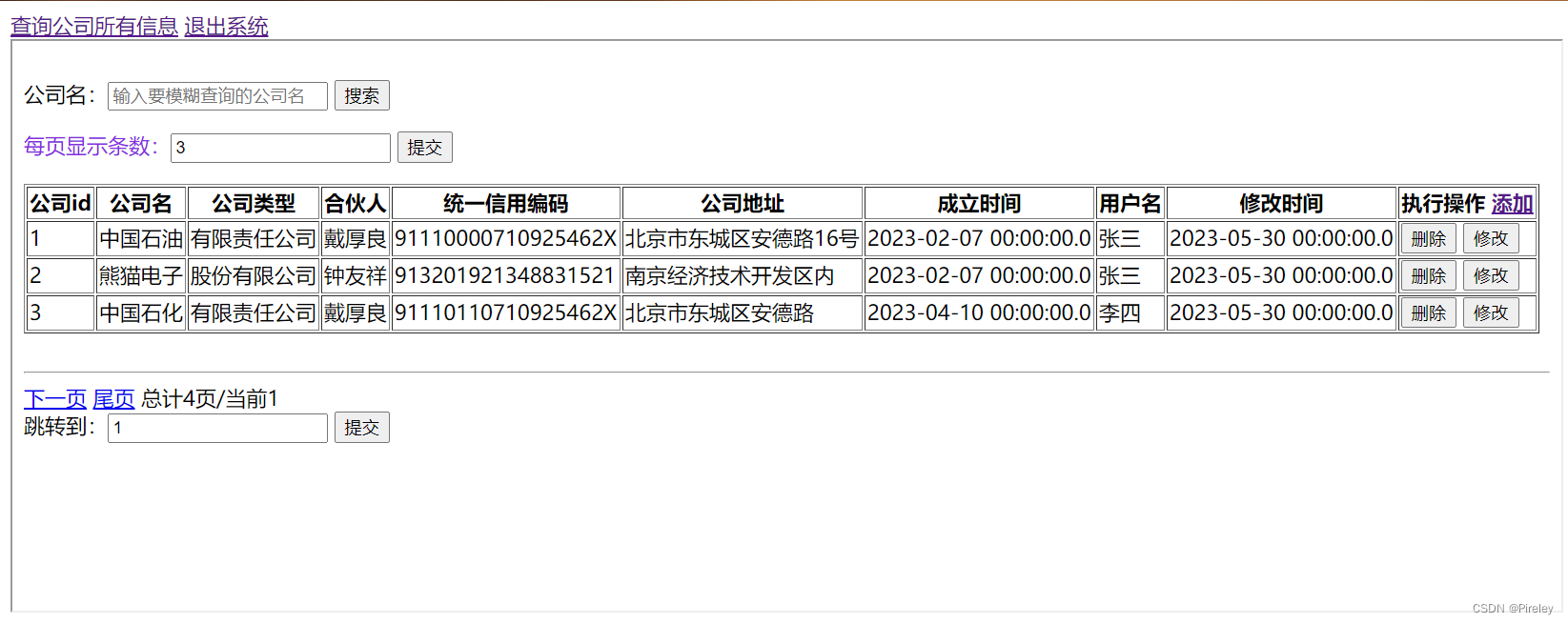
2.1 查看索引
一般创建主键约束、唯一约束、外键约束时,都会自动创建对应列的索引
接下来我们就创建一张学生表查看它的索引
student 表:
create table student(id int primary key,name varchar(20));上述创建的student表中 id 是主键,所以 id 就会自动产生索引,当我们对 student 表进行查询索引的时候就可以查到 id 索引
查看索引:show index from 表名;

2.2 创建索引
当对数据表中的某列或是某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询
该数据表的插入操作、修改操作、删除操作对这些列来说频率较低
索引会占用额外的磁盘空间,考虑磁盘空间是否充足
对应非主键、非唯一约束、非外键的字段可以创建普通索引
创建一张 student 表:
//如果有student表,请先删除在创建
create table student(id int primary key,name varchar(20));创建索引:create index 索引名 no 表名(字段名);
create index index_name on student(name);注:创建索引,最好是在表创建之初就把索引创建好,否则如果是针对一个表中已经有很多很多记录的表,来创建索引也就是个危险操作,这个时候就会吃掉大量IO,花很长时间(可能是几十分钟也可能是几个小时,主要看数据量),那么在这段时间里,数据库就无法正常使用
2.3 删除索引
接下来我们就把 1.3 中添加的索引给删除
删除索引:drop index 索引名 on 表名;
drop index index_name on student;注:删除索引也可能会吃大量的磁盘IO
3、索引在 MySQL 中的数据结构
1.索引在 MySQL 中的数据结构是 哈希表 ?
答:哈希表的查找元素的时间复杂度为 O(1),但是哈希表并不适合做数据库的索引,因为哈希表只能比较相等,无法进行范围查询
2.索引在 MySQL 中的数据结构是 二叉搜索树 ?
答:二叉搜索树查找元素的时间复杂度为 O(n),二叉意味着当元素个数多的时候,树的高度就会比较高。树的高度也就决定了查询时候元素的比较次数
3.索引在 MySQL 中的数据结构是 N叉搜索树 ?
答:N叉搜索树每个节点上有多个值,同时有多个分叉,树的高度就降低了。其中的一种典型实现,叫做B树。比较次数虽然没咋减少,一个节点上可能需要比较多次,但是读写硬盘的次数减少了,每个节点都是在硬盘上的。
B树:

B树是N叉树的一种典型实现,它的特定就是每个节点上有多个值,子节点里面的值都小于父节点的值
B 树已经比二叉搜索树更适合做数据库的索引了,但是还不够。针对这里又引入了 B+树,是对B树的进一步的改进。B+树就是为了索引这个场景,量身定做的数据结构。
B+树的特定:
B+树也是一棵N叉搜索树,每个节点上可能包含了 N 个 key,N个 key 划分出了N个区间,最后一个 key 就相当于是最大值了。
父元素的 key 会在子元素中重复出现,并且是以最大值的姿态出现,这样重复出现,也就让叶子节点包含了所有数据的全集,非叶子节点中的所有值都会在叶子节点中体现出来
会把叶子节点,用类似于链表的方式首尾相连
B+树:
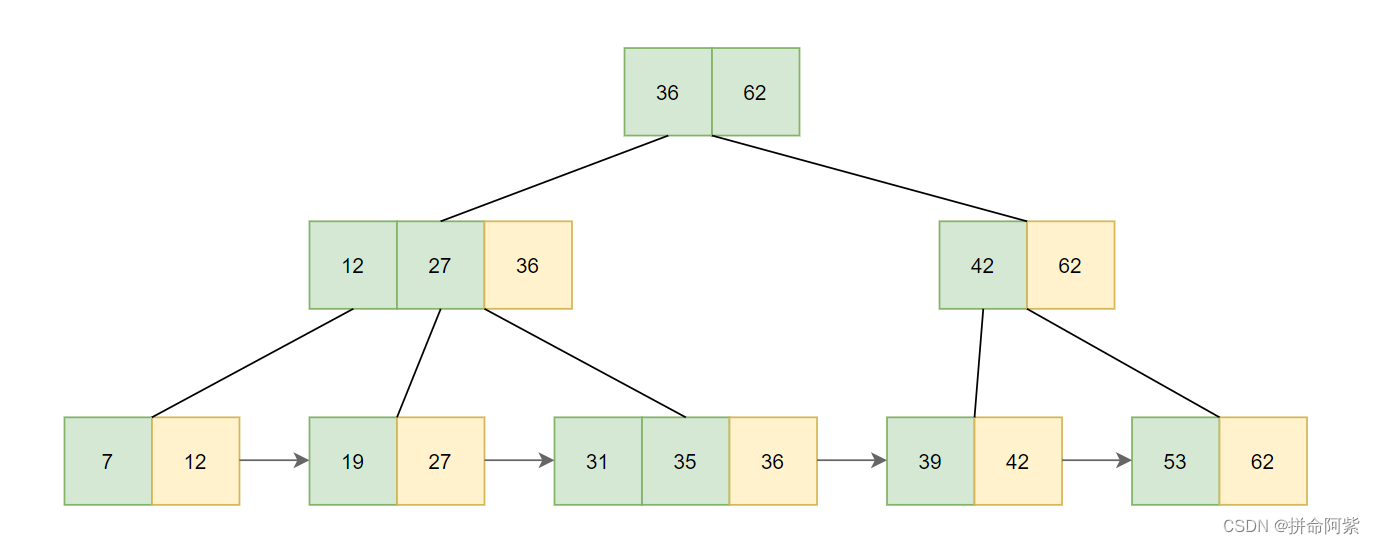
B+树的优点:
作为一棵N叉搜索树,高度降下来了,比较的时候硬盘IO次数就比较少了(同B树)
更适合进行范围查询
所有的查询,都是落在叶子节点上,无论查询哪个元素,中间比较的次数都差不多。对于B树来说,每次查询的速度可能不一样,但是对于B+树来说,每次查询的速度都一样
由于所有的key都会在叶子节点中体现,只需要把所有的数据行放到叶子节点即可。非叶子节点只需要存简单的id,不用存一整行,这就意味着非叶子节点,占用的空间大大降低
有的表不仅有主键索引,还有别的非主键列也可能有索引,此时如何构造B+树?
答:构造一个主键列的B+树,然后再构造一个非主键列的 B+ 树。非主键列有索引的 B+树非叶子节点里面存的都是一些key(比如:一些学生姓名),到了叶子节点这一层,存的并不是完整的数据行,而是存的主键值。如果使用主键列进行查询,只需要查询一次主键列 B+树即可。如果采用非主键列来查询,则需要先查一遍非主键列的B+树,然后再查一遍主键列的B+树
当前B+树这个数据结构,只是针对 MySQL 的 innoDB 这个数据库引擎里面所典型使用的数据结构。不同的数据库,不同的引擎,里面存储数据的结构可能也不同