文章目录
- 1. 线程的使用场景
- 2. 线程池创建
- 3. 参数的配置建议
- 常见的拒绝策略
- 其他的拒绝策略
- 4. 线程池的任务处理流程
- 5. 线程的状态
- 6. 线程池的监控
1. 线程的使用场景
异步任务
简单来说就是某些不需要同步返回业务处理结果的场景,比如:短信、邮件等通知类业务,评论、点赞等互动性业务。
并行计算
就像MapReduce一样,充分利用多线程的并行计算能力,将大任务拆分为多个子任务,最后再将所有子任务计算后的结果进行汇总,ForkJoinPool就是JDK中典型的并行计算框架。
串行任务
很简单,假设某个方法需要经过,A、B、C三个步骤,A步骤耗时1秒,B步骤耗时2秒,C步骤耗时3秒,那么如果是串行处理,则该方法最终需要耗时6秒,但如果A、B、C三个步骤互相之间是没有依赖的,那么就可以利用多线程的方式,同时处理三个步骤,这样该方法只需要等待耗时最长的步骤结束即可。
2. 线程池创建
不要直接使用Executors创建线程池,应通过ThreadPoolExecutor的方式,主动明确线程池的参数,避免产生意外。
每个参数都要显示设置,例如像下面这样:
private static final ExecutorService executor = new ThreadPoolExecutor(
2,
4,
1L,
TimeUnit.MINUTES,
new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("common-pool-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
3. 参数的配置建议
CorePoolSize(核心线程数)
一般在配置核心线程数的时候,是需要结合线程池将要处理任务的特性来决定的,而任务的性质一般可以划分为:CPU密集型、I/O密集型。
比较通用的配置方式如下
CPU密集型:一般建议线程的核心数与CPU核心数保持一致。
I/O密集型:一般可以设置2倍的CPU核心数的线程数,因为此类任务CPU比较空闲,可以多分配点线程充分利用CPU资源来提高效率。
通过Runtime.getRuntime().availableProcessors()可以获取核心线程数。
另外还有一个公式可以借鉴
线程核心数 = cpu核心数 / (1-阻塞系数)
阻塞系数 = 阻塞时间/(阻塞时间+使用CPU的时间)
实际上大多数线上业务所消耗的时间主要就是I/O等待,因此一般线程数都可以设置的多一点,比如tomcat中默认的线程数就是200,所以最佳的核心线程数是需要根据特定场景,然后通过实际上线上允许结果分析后,再不断的进行调整。
MaximumPoolSize
maximumPoolSize的设置也是看实际应用场景,如果设置的和corePoolSize一样,那就完全依靠阻塞队列和拒绝策略来控制任务的处理情况,如果设置的比corePoolSize稍微大一点,那可能对于一些突然流量的场景更使用。
KeepAliveTime
由maximumPoolSize创建出来的线程,在经过keepAliveTime时间后进行销毁,依旧突发流量持续的时间来决定。
WorkQueue
那么阻塞队列应该设置多大呢?我们知道当线程池中所有的线程都在工作时,如果再有任务进来,就会被放到阻塞队列中等待,如果阻塞队列设置的太小,可能很快队列就满了,导致任务被丢弃或者异常(由拒绝策略决定),如果队列设置的太大,又可能会带来内存资源的紧张,甚至OOM,以及任务延迟时间过长。
所以阻塞队列的大小,又是要结合实际场景来设置的。
一般会根据处理任务的速度与任务产生的速度进行计算得到一个大概的数值。
假设现在有1个线程,每秒钟可以处理10个任务,正常情况下每秒钟产生的任务数小于10,那么此时队列长度为10就足以。
但是如果高峰时期,每秒产生的任务数会达到20,会持续10秒,且任务又不希望丢弃,那么此时队列的长度就需要设置到100。
监控workQueue中等待任务的数量是非常重要的,只有了解实际的情况,才能做出正确的决定。
ThreadFactory
通过threadFactory我们可以自定义线程组的名字,设置合理的名称将有利于你线上进行问题排查。
Handler
最后拒绝策略,这也是要结合实际的业务场景来决定采用什么样的拒绝方式,例如像过程类的数据,可以直接采用DiscardOldestPolicy策略。
常见的拒绝策略
AbortPolicy
JDK自带线程池中默认的拒绝策略,直接拒绝任务并抛出异常。
CallerRunsPolicy
由当前调用调用者继续执行当前任务。
DiscardPolicy
直接丢弃当前任务
DiscardOldestPolicy
丢弃阻塞队列中最早丢进去的任务
其他的拒绝策略
NewThreadRunsPolicy
这是Netty中的拒绝策略,和CallerRunsPolicy有点像,任务不会丢弃,不同的是Netty中是新建了一个线程继续执行当前任务。
AbortPolicyWithReport
dubbo中的拒绝策略,也是抛出异常,不同的时对于日志内容的输出更加丰富,也是为了我们更好的排查问题。
EsAbortPolicy
针对某种特定场景时,做出不同的处理方式,比如在elasticsearch中只有当isForceExecution为true(isForceExecution是用来判定任务是执行还是拒绝的条件),且阻塞队列是SizeBlockingQueue类型时,才会放入当前队列中,否则抛出异常。
4. 线程池的任务处理流程
阻塞队列的设计起到了良好的缓冲作用,当面对突发流量到来时,先将任务丢到队列中,再慢慢来消费,其原理和MQ是类似的,一旦队列也被打满了,则说明消费能力与你的期望对比,已经严重不足了,此时maximumPoolSize参数的设计,又给了你一次处理的机会,你可以选择再开启一部分线程来应对突发状况,当危机接触后,再主动帮你回收这部分线程,或者选择使用拒绝策略。
一个简单的任务处理,考虑各种实际运行中可能遇到的情况,对于线程池的使用者来说,也应了解线程池的任务处理流程,再结合自身的业务场景充分考虑其中的参数设置。
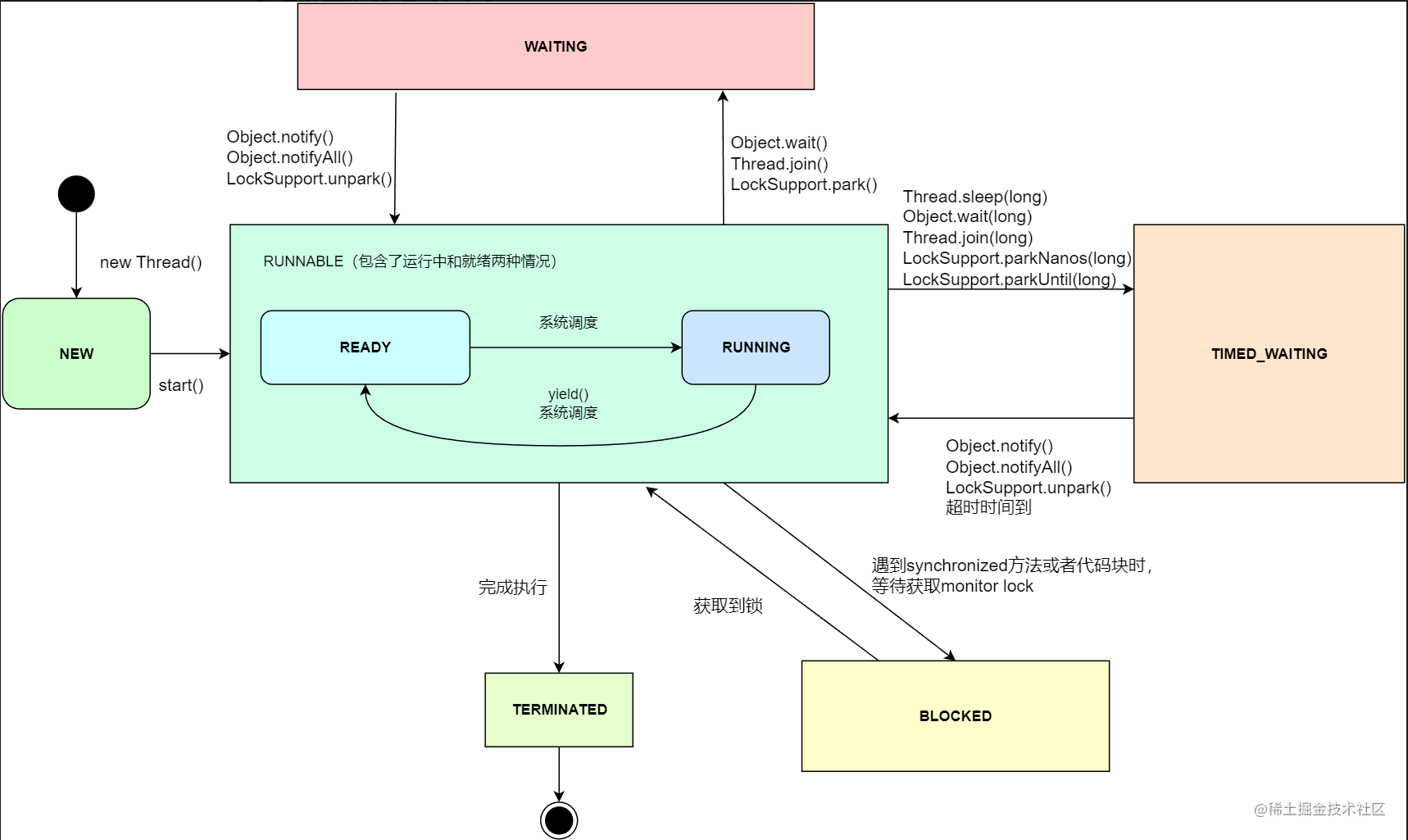
5. 线程的状态
Java中对线程的定义有如下几种状态:RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, NEW, TERMINATED
RUNNABLE
可运行的状态,包含了运行中和准备就绪两种状态,也就是说RUNNABLE状态下线程并不一定已经运行了,可能还在等待CPU资源。
BLOCKED
处于阻塞状态下的线程,并且这个阻塞是因为进入了同步代码块或者方法,需要等待锁的释放。
一旦线上出现blocked状态的线程,是需要排查原因的。
WAITING
处于等待状态下的线程,例如一个线程调用了Object.wait()方法,那么这个线程就会等待另一个线程调用Object.notify()或者Object.notifyAll()。
或者调用thread.join()的线程等待指定线程的终止。
常见的方法有:Object.wait()、Thread.join()、LockSupport.park()
TIMED_WAITING
与WAITING的区别就在于TIMED_WAITING是明确带有具体等待时间的,常见的方法有:Thread.sleep(long)、Object.wait(long)、Thread.join(long)、LockSupport.parkNanos(long)、LockSupport.parkUntil(long)
NEW
创建了一个线程,但还没调用start()方法。
TERMINATED
终止状态,表示线程已经执行完毕。
6. 线程池的监控
线程池自身提供的统计数据
public class ThreadPoolMonitor {
private final static Logger log = LoggerFactory.getLogger(ThreadPoolMonitor.class);
private static final ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 4, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build());
public static void main(String[] args) {
log.info("Pool Size: " + threadPool.getPoolSize());
log.info("Active Thread Count: " + threadPool.getActiveCount());
log.info("Task Queue Size: " + threadPool.getQueue().size());
log.info("Completed Task Count: " + threadPool.getCompletedTaskCount());
}
}
通过micrometer API完成统计,这样就可以接入Prometheus了
package com.springboot.micrometer.monitor;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import io.micrometer.core.instrument.Metrics;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.stream.IntStream;
@Component
public class ThreadPoolMonitor {
private static final ThreadPoolExecutor threadPool = new ThreadPoolExecutor(4, 8, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("my_thread_pool_%d").build(), new ThreadPoolExecutor.DiscardOldestPolicy());
/**
* 活跃线程数
*/
private AtomicLong activeThreadCount = new AtomicLong(0);
/**
* 队列任务数
*/
private AtomicLong taskQueueSize = new AtomicLong(0);
/**
* 完成任务数
*/
private AtomicLong completedTaskCount = new AtomicLong(0);
/**
* 线程池中当前线程的数量
*/
private AtomicLong poolSize = new AtomicLong(0);
@PostConstruct
private void init() {
/**
* 通过micrometer API完成统计
*
* gauge最典型的使用场景就是统计:list、Map、线程池、连接池等集合类型的数据
*/
Metrics.gauge("my_thread_pool_active_thread_count", activeThreadCount);
Metrics.gauge("my_thread_pool_task_queue_size", taskQueueSize);
Metrics.gauge("my_thread_pool_completed_task_count", completedTaskCount);
Metrics.gauge("my_thread_pool_size", poolSize);
// 模拟线程池的使用
new Thread(this::runTask).start();
}
private void runTask() {
// 每5秒监控一次线程池的使用情况
monitorThreadPoolState();
// 模拟任务执行
IntStream.rangeClosed(0, 500).forEach(i -> {
// 每500毫秒,执行一个任务
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 每个处理一个任务耗时5秒
threadPool.submit(() -> {
try {
TimeUnit.MILLISECONDS.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
}
private void monitorThreadPoolState() {
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
activeThreadCount.set(threadPool.getActiveCount());
taskQueueSize.set(threadPool.getQueue().size());
poolSize.set(threadPool.getPoolSize());
completedTaskCount.set(threadPool.getCompletedTaskCount());
}, 0, 5, TimeUnit.SECONDS);
}
}