问题描述
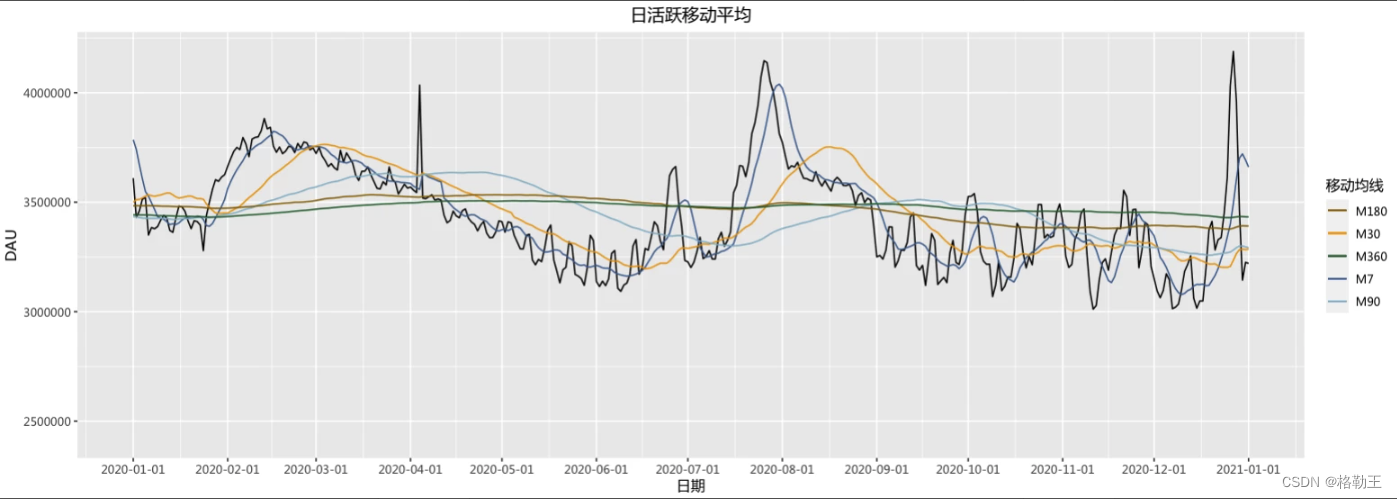
现在有一个分日期记录DAU的数据,现在需要绘制其360,180,90,30,7日移动平均值,来观测消除了波动干扰的DAU趋势
(实际移动在股价趋势图上非常常见)
原始数据格式如下:
| day (character) | dau (int) |
| 2017-01-01 | 3098566 |
| 2017-01-02 | 2986435 |
| ...... | ...... |
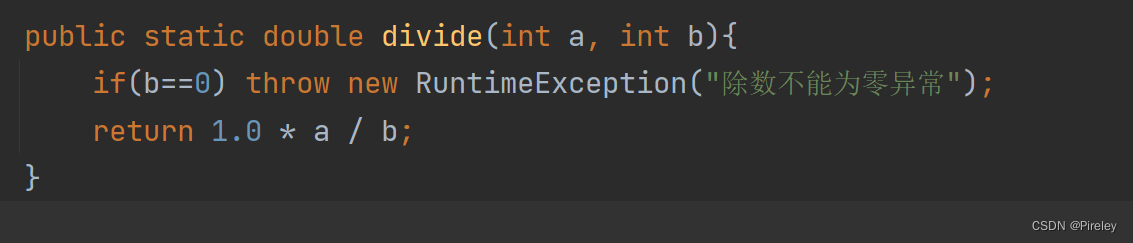
filter函数报错_{Error in UseMethod("filter") : "filter"没有适用于"c('integer', 'numeric')"目标对象的方法}解决方案
filter在文档中的写法会出现报错,说是不支持目标对象
报错:Error in UseMethod("filter") : "filter"没有适用于"c('integer', 'numeric')"目标对象的方法
#原写法
library(dplyr)
x <- 1:100
filter(x, rep(1, 3))
filter(x, rep(1, 3), sides = 1)
filter(x, rep(1, 3), sides = 1, circular = TRUE)
filter(presidents, rep(1, 3))
基于上述问题,我们调用tidyverse包,对原函数进行修正
> library(tidyverse)
── Attaching packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.3.6 ✔ purrr 0.3.4
✔ tibble 3.1.6 ✔ stringr 1.4.0
✔ tidyr 1.2.0 ✔ forcats 0.5.2
✔ readr 2.1.3
── Conflicts ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ plyr::arrange() masks dplyr::arrange()
✖ lubridate::as.difftime() masks base::as.difftime()
✖ purrr::compact() masks plyr::compact()
✖ plyr::count() masks dplyr::count()
✖ lubridate::date() masks base::date()
✖ tidyr::expand() masks reshape::expand()
✖ plyr::failwith() masks dplyr::failwith()
✖ dplyr::filter() masks stats::filter()
✖ plyr::id() masks dplyr::id()
✖ lubridate::intersect() masks base::intersect()
✖ dplyr::lag() masks stats::lag()
✖ plyr::mutate() masks dplyr::mutate()
✖ reshape::rename() masks plyr::rename(), dplyr::rename()
✖ lubridate::setdiff() masks base::setdiff()
✖ reshape::stamp() masks lubridate::stamp()
✖ plyr::summarise() masks dplyr::summarise()
✖ plyr::summarize() masks dplyr::summarize()
✖ lubridate::union() masks base::union()修正后的函数可以正常运行了
x <- 1:100
x1_3 <- filter(x,rep(1,3))##默认sides=2
stats::filter(x,rep(1,3),sides = 2)##加前一个后一个和当前数
filter函数详解
解决了filter函数报错的问题,我们来看一下filter是怎么实现移动平均的
首先还是1-100的自然数序列x,
filter(目标对象,系数,移动方式)
看下示例
x <- 1:100
x
stats::filter(x,rep(1,3),sides = 2)##加前一个后一个和当前数
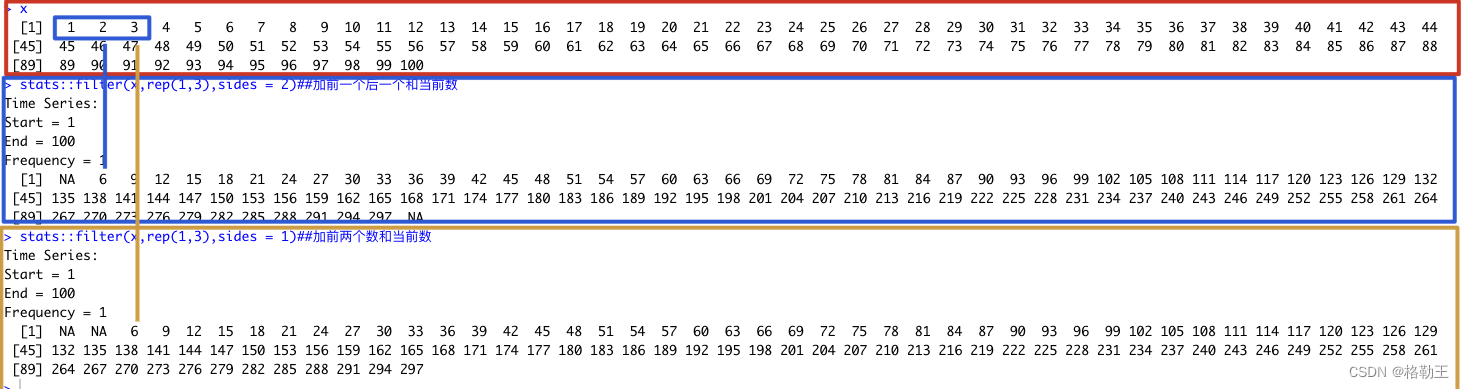
stats::filter(x,rep(1,3),sides = 1)##加前两个数和当前数rep(1,3):是指将1重复3次,得到一个向量> rep(1,3) [1] 1 1 1,也就是说计算移动平均时,每一步的系数都是1
sides表示移动的方式:
sides=1表示只参考当前值之前的数值计算,如图(黄框):第1位和第2位因为前面的数值不足,所以从第3位开始,第3位数值=第1位数值+第2位数值+第三位数值=1+2+3=6
sides=2表示参考当前值前后的数值计算,如图(蓝框):第1位因为前面的数值不足,所以从第2位开始,第2位数值=第1位数值+第2位数值+第三位数值=1+2+3=6
同样,如果不想让前后的顺序都具有相同的权重系数,也可以自行设置,如:
x <- 1:100
x
stats::filter(x,c(0.5,1,1.5),sides = 1)##加前两个数和当前数
sides=1表示只参考当前值及其之前的数值,所以第3位开始计算
5=1*0.5+2*1+3*1.5

当然移动的位数也可以不是3位,例如是偶数位数的时候(如移动系数有4个),sides=1或sides=2时的情况如下:
sides=1时,计算1、2、3、4个数的移动平均,赋值给第4个数
sides=2时,计算1、2、3、4个数的移动平均,赋值给第2个数
x <- 1:100
x
stats::filter(x,rep(1,4),sides = 1)
stats::filter(x,rep(1,4),sides = 2)
实操:计算DAU移动平均值
计数
##案例:计算DAU的7、30、180、360移动平均值
#导入数据
setwd('文件路径')
dau_data <- readxl::read_xlsx("dau数据.xlsx")
head(dau_data)
#调整日期排序
dau_data <- dau_data[order(dau_data$day,decreasing = FALSE),]##时间升序
#导入原始数据的时间变量是字符格式的,需要转换成日期格式
dau_data$day <- as.Date(dau_data$day,"%Y-%m-%d")
#计算移动平均
dau_data$dau_360 <- filter(dau_data$dau/360,rep(1,360),sides = 1)
dau_data$dau_7<- filter(dau_data$dau/7,rep(1,7),sides = 1)
这样写就可以得到N日DAU的移动平均,包含前面N-1日的数据和N日当天的数据
如果不想包含第N日当天的数据,想用第N日之前的数据来计算如何处理呢?
我们可以在常规移动平均的结果之前加上一行NA值,实现整体数据向下平移的效果,但是因为多了一行,所以就算出来的结果无法与原数据框合并,所以需要再将最后一行数据删除即可,操作如下
dau_7 <- c(NA,filter(dau_data$dau/7,rep(1,7),sides=1))
dau_data$dau_7 <- dau_7[-length(dau_7)]##删除最后一行的数据,length(dau_7)得到的是向量的个数
dau_30 <- c(NA,filter(dau_data$dau/30,rep(1,30),sides=1))
dau_data$dau_30 <- dau_30[-length(dau_30)]
dau_90 <- c(NA,filter(dau_data$dau/90,rep(1,90),sides=1))
dau_data$dau_90 <- dau_90[-length(dau_90)]
dau_180 <- c(NA,filter(dau_data$dau/180,rep(1,180),sides=1))
dau_data$dau_180 <- dau_180[-length(dau_180)]
dau_360 <- c(NA,filter(dau_data$dau/360,rep(1,360),sides=1))
dau_data$dau_360 <- dau_360[-length(dau_360)]
dau_data数据结果如下:
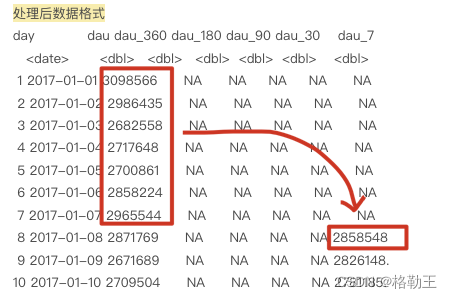
绘图
ggplot()的参数
基础图表:ggplot(数据框,aes(X轴字段,Y轴字段))+geom_line()
叠加折线图:+geom_line(aes(x=day,y=dau_7),colour="#336699")
以此类推,叠加dau_30,dau_90等趋势线
##绘制图形
library(ggplot2)
picture <- ggplot(dau_data,aes(x=day,y=dau))+geom_line()+geom_line(aes(x=day,y=dau_7),colour="#336699")+geom_line(aes(x=day,y=dau_30),colour="#FF9900")+geom_line(aes(x=day,y=dau_90),colour="#7ab8cc")+geom_line(aes(x=day,y=dau_180),colour="#996600")+geom_line(aes(x=day,y=dau_360),colour="#006633")
##添加趋势线
picture+scale_x_date(labels = date_format("%Y-%m-%d"),breaks = date_breaks("1 months"),limits =as.Date(c("2020-01-01","2021-01-01"
结果如下:

但是这样做出来的图是没有图例的,而且坐标轴和标题都是默认生成,可以稍微调整一下
调整X轴坐标:scale_x_date(),参数如下:
X轴标签:labels = date_format("%Y-%m-%d")
X轴标签间隔:breaks
X轴数据范围:limits
设置一个颜色字典:scale_colour_manual(),参数如下:
values=c("颜色名称"="实际颜色16进制数字")
##绘制基础图形
picture <- ggplot(dau_data,aes(x=day,y=dau))+geom_line()
##修改横坐标格式、范围和标识粒度
picture <- picture+scale_x_date(labels = date_format("%Y-%m-%d"),
breaks = date_breaks("1 months"),
limits =as.Date(c("2020-01-01","2021-01-01")))
##修改图标标题和坐标标题
picture <- picture+theme_grey(base_family="MicrosoftYaHei")
+xlab("日期")
+ylab("DAU")
+ggtitle("日活跃移动平均")
+theme(plot.title = element_text(hjust = 0.5))
##theme(plot.title = element_text(hjust = 0.5))是为了保证标题居中
##添加移动均线和图例
picture <- picture+geom_line(aes(y=dau_7,colour="M7"))+geom_line(aes(y=dau_30,colour="M30"))+geom_line(aes(y=dau_90,colour="M90"))+geom_line(aes(y=dau_180,colour="M180"))+geom_line(aes(y=dau_360,colour="M360"))
+scale_colour_manual(values = c("M7"="#336699","M30"="#FF9900","M90"="#7ab8cc","M180"="#996600","M360"="#006633"))
picture
##修改图例的标题
picture <- picture+theme_grey(base_family="MicrosoftYaHei")+labs(colour="移动均线")
picture最终结果如下: