英文题目:Anomaly Detection in Quasi-Periodic Time Series based on Automatic Data
Segmentation and Attentional LSTM-CNN
论文地址:Anomaly Detection in Quasi-Periodic Time Series Based on Automatic Data Segmentation and Attentional LSTM-CNN | IEEE Journals & Magazine | IEEE Xplore
期刊:CCF-A

摘要
准周期时间序列(QTS)在现实世界中广泛存在,检测QTS的异常是非常重要的。在本文提出了一种由基于二级聚类的QTS异常检测框架(AQADF)。分割算法(TCQSA)和混合注意LSTM-CNN模型(HALCM)。TCQSA首先自动拆分QTS进入准周期,然后通过HALCM将其分类为正常周期或异常。值得注意的是,TCQSA集成了集群技术和k-均值技术,使其具有高度通用性和抗噪性。HALCM将LSTM和CNN杂交到同时提取QTS的总体变化趋势和局部特征,以建立其波动模式。此外,我们在LSTM中嵌入趋势关注门(TAG)、特征关注机制(FAM)和位置关注机制(LAM)进入CNN,根据提取的变异趋势和局部特征的真正重要性,对其进行精细调整,以实现更好地表示QTS的波动模式。在四个公共数据集上,HALCM超过了四个最先进的基准并且获得至少97.3%的精度,TCQSA优于两种尖端QTS分割算法,可应用于不同类型的QTS。此外,注意力机制的有效性被定量和定性地证明。
引言
大多数现有QTS异常检测方法的核心思想是是把QTS的异常检测变成一个监督分类问题。他们通常包括两个步骤:1) 将QTS分割成一组准周期,2 )将准周期分为正常周期和异常周期。第一步通常采用基于聚类的QTS分区策略。具体来说,他们首先提取QTS的临界点作为候选点,然后将它们聚类成几个簇。最后,选择最佳聚类中的候选点作为分裂点(即周期点),在此基础上将QTS划分为准周期。第二步,通常从准周期中提取一组特征,然后将其输入到随机森林、AdaBoost、Naï、贝叶斯、支持向量机(SVM)等监督分类器中,以区分异常和正常周期。
现有的方法虽然取得了良好的性能,但仍然存在以下两个问题。
问题1:现有的基于聚类的QTS分区方法难以在相同设置下自动有效地分割不同类型的QTS。在对候选点进行聚类之前,通常需要手动设置簇数,但在不知道QTS波形的情况下,显然很难预设合适的值。此外,对于不同类型的qts,在一个准周期内的候选点数量通常是不同的。图1表明,一个ECG准周期和一个步态准周期分别包含4个和5个候选点。因此,只有将这两种qts的簇数分别预设为4和5时,我们才能得到最佳的分裂点。因此,现有方法很难同时在相同簇数下的不同类型QTS上顺利工作。此外,来自现实世界的qts通常包含许多异常值,因为各种原因,如环境噪声和传感器故障。重要的是,异常值与正常样本相距甚远,因此容易被归为异常集群。此外,异常值的数量是不可预测的,因此,即使预设的集群数量在某些QTSs上运行良好,它也可能在相同类型的其他QTSs上运行不佳。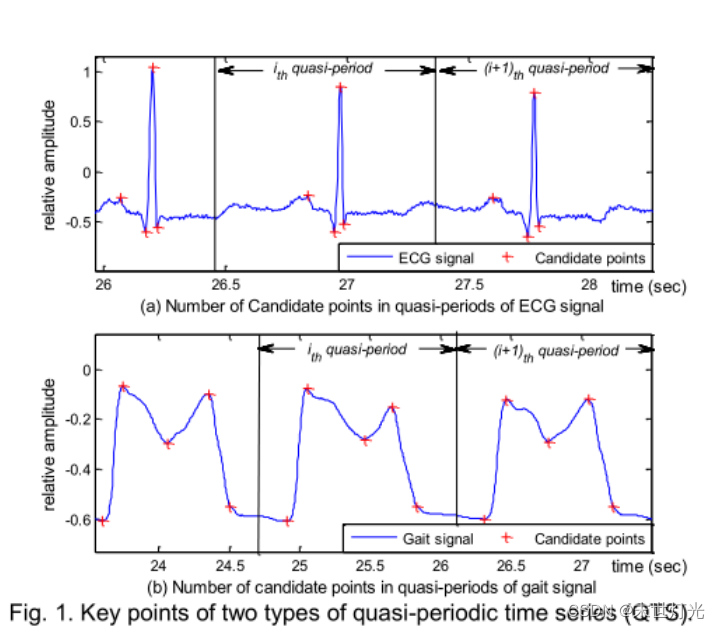
问题2:现有的准周期分类模型通常适用性较低或精度有限。从图1可以看出,不同类型的qts的波形通常相差很大,因此传统的基于特征工程的分类器很难同时准确地利用完全相同的特征对它们进行建模,适用性较低。
本文设计了一个QTS自动异常检测框架(AQADF)来解决上述问题。
AQADF由基于两级聚类的QTS分割算法(TCQSA)和混合注意LSTM-CNN模型(HALCM)组成。具体而言,TCQSA旨在自动准确地将qts划分为连续的准周期。HALCM的目的是同时利用准周期的整体变化趋势和局部特征,准确地模拟准周期的波动模式,并进一步将准周期划分为正常准周期或异常。值得注意的是,AQADF异常检测精度高,通用性强,抗噪性好,可直接应用于不同类型的qts。这项工作的贡献有四个方面:
首先,我们提出了能够自动有效地将不同类型的qts划分为高质量准周期的TCQSA。TCQSA包含两个级别的聚类。其中,第一次聚类采用层次聚类,旨在使TCQSA具有高度通用性,能够在不需要人工干预的情况下自动聚类qts候选点。第二次聚类专门用于消除qts异常值引起的聚类,使TCQSA具有抗噪声性。
其次,为了准确检测qts的异常,我们将堆叠的双向LSTM (SB-LSTM)和二维CNN (TD-CNN)杂交在一起构建HALCM。其中,利用SB-LSTM和TD-CNN分别提取QTS的整体变化趋势和局部特征,可以更准确地表征QTS的波动规律。实验结果表明,与9种同类网络相比,HALCM具有更高的异常检测精度。
第三,为了进一步提高异常检测性能,我们设计了三种关注机制。具体而言,我们在LSTM中嵌入趋势注意门(TAG),根据qts的真实重要性对从不同部分提取的变化趋势进行精细调整。在CNN中,嵌入特征注意机制(FAM)和位置注意机制(LAM),以增强在qts特定部位提取的关键特征的效果。结果表明,HALCM可以更准确地表征qts的波动模式。
第四,在4个公开数据集上的实验结果表明,HALCM超过了4个最先进的QTS分类模型,达到了97.3%的准确率、98.5%的灵敏度和96.3%的特异性。此外,TCQSA超越了两种前沿的QTS分割算法,能够获得更高质量的准周期。此外,与同类的9种结构相比,该结构是最优的。同时,从定量和定性两方面验证了注意机制的有效性。
相关工作
QTS分割方法
现有的QTS分割算法可以分为两类。第一类是利用滑动窗口技术,将qts划分为一组等长子序列(即准周期)。虽然这种方法不需要太多的时间和空间开销,它完全破坏了QTSs的准周期性,从而使得到的子序列不对齐,特别是当准周期长度变化较大时。此外,如果子序列的长度远远大于异常的长度,则很难检测到轻微的异常,因为在这种情况下,正常子序列和异常子序列不会出现太大的差异。第二类是基于聚类技术,通过选择一组分裂点将qts划分为连续的准周期。它避免了第一种方法的缺点。Huang等人将QTS峰值点的顶点角聚为一组聚类,然后将聚类中差值最小的点作为分裂点。但是,如果在一个准周期中有两个或两个以上具有相似顶点角的峰,则这种方法可能会将一个准周期分裂成碎片。Tang等人设置了一个可自动更新的阈值,将小于阈值的qts谷点作为分割点。然而,阈值容易受到异常值的影响,特别是不规则变化的子序列。Ma等人利用k- means++算法对QTSs的不动子进行聚类,对每个拐点提取四值特征向量,选择聚类中剪影平均值最高的不动子作为分裂点。但是,它需要手动预设簇的数量,并且容易受到qts异常值的影响。相反,我们的TCQSA是完全自动化和抗噪的,可以直接应用于各种类型的qts。
准周期分类模型
准周期分类通常采用传统的模式识别范式。机器学习的分类器。最近,提出了许多基于lstm或基于cnn的准周期分类模型,这些模型不需要手工制作特征。
方法论
框架概述
AQADF的框架如图3所示。由于准周期被视为基本的检测单位,我们首先使用TCQSA将qts分割成一组准周期。然后,利用HALCM将拟周期进一步划分为正常周期和异常周期。具体而言,首先将准周期输入到注意力SB-LSTM中,提取其总体变化趋势。然后,将输出与原始准周期一起输入到注意力TD-CNN中,进一步挖掘其局部特征。最后,AQADF使用两个完全连接层(fcl)和一个softmax函数得到最终的分类结果。

我们发现QTS的临界点继承了QTS的拟周期性,从而周期性地出现在特定的地点。基于这一发现,我们提出了TCQSA,将QTS的划分问题转化为QTS临界点的聚类问题。具体来说,首先利用数据压缩技术提取出QTS的所有临界点作为候选点;然后,采用基于两级聚类的方法将候选点聚成一组聚类,其中同一聚类中的临界点在每个准周期的几乎相同位置;然后,选择最佳聚类中的候选点作为周期点,最终将QTS划分为连续的准周期。特别是,TCQSA是一个完全自动化的方法,不需要任何手动设置。此外,TCQSA具有抗噪声特性,能够从噪声数据中获得高质量的准周期。TCQSA通用性强,可直接应用于相同设置下的各类qts。
候选点的提取
直观地说,最佳候选点应该是包含QTS最关键信息的点。因此,在本文中,我们利用广泛使用的数据压缩技术Douglas-Peucker (DP)算法提取关键点作为候选点。应用DP算法之前,先利用Z-score方法对QTS进行标准化。
之前写的一篇博客可供参考:(8条消息) 道格拉斯普克算法_道格拉斯算法_末世灯光的博客-CSDN博客
选择候选点
现有的方法在对候选点进行聚类时,通常需要预先设定聚类的数量,这导致其通用性较低。此外,得到的周期点的质量很容易受到数据噪声的影响。为了解决这个问题,我们提出了一种基于两级聚类的方法。其中,一级聚类采用分层聚类的方式,将候选点主要聚为一组聚类,不仅不需要人工设置,而且使得TCQSA可以直接应用于不同类型的qts,无需修改任何参数。此外,为了使TCQSA具有抗噪声性,还专门采用二级聚类来消除qts的离群值形成的聚类。
对QTS候选点进行聚类。为了避免预先设定聚类数量,使TCQSA具有高度通用性,我们使用Louvain算法对候选点进行聚类。它是一种著名的社区检测技术,由于其模块化高、收敛速度快,特别是不需要预设任何参数等特点,被广泛应用于社交网络服务、人机交互等各个领域。
移除由离群值引起的群集。由于实际问题的复杂性,qts通常充满了异常值。问题是,这些异常值往往被提取为候选点,并进一步聚类为仅包含少量候选点的聚类,这使得难以选择最佳聚类。具体来说,由离群点引起的聚类通常只有很少的顶点,因此当使用MOD和轮廓值等常用指标进行评估时,它们更容易获得比普通聚类更高的质量,这将导致次优甚至错误的周期点。为了解决这个问题,我们提出了二级聚类来消除由离群值引起的聚类,算法(第14-21行)给出了二级聚类的描述。

混合注意LSTM-CNN模型(HALCM)
为了更准确地模拟准周期的波动模式,从而获得更高的异常检测性能,我们设计了一种混合LSTM-CNN模型,以同时挖掘QTS的整体变化趋势和局部特征。进一步,我们设计了TAG、FAM和LAM三种注意力机制,分别嵌入到LSTM和CNN中,对它们的输出进行微调,使HALCM得到的特征表示能够更好地表征QTS的波动模式。
实验
数据集


实验数据

为了评估分类结果,采用了3个常用指标,即准确性(ACC)、敏感性(SEN)和特异性(SPE)。特别是,ACC越大,总体分类性能越好。SEN越大,说明该模型善于发现积极实例,SPE越大,说明该模型识别消极实例的能力越强。
为了评估聚类的质量,使用平均轮廓值(MSV)作为度量标准,因为MSV的计算只依赖于候选点的原始特征,避免了特征转换的影响。对于一个簇来说,如果它本身的点彼此更近,但离其他簇中的点更远,那么它被认为是一个好的簇,并且将获得更大的MSV。

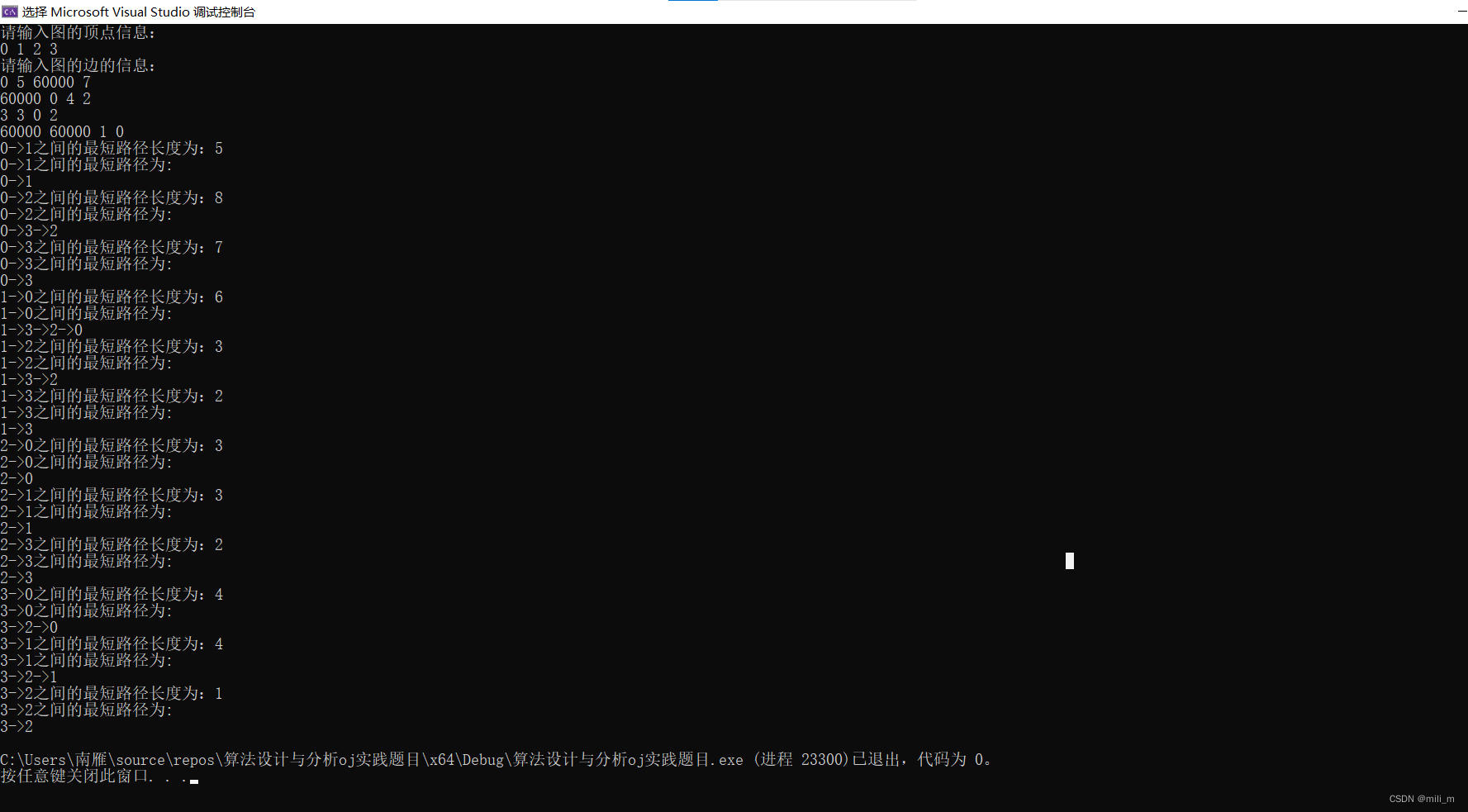
我们评估了QTS分割算法对表4中准周期分类结果的影响,其中准周期是使用不同的QTS分割算法创建的。总的来说,无论采用哪种QTS分割算法,最终的分类性能肯定会下降,这是合理的,因为人工标记的周期点比计算机检测的周期点具有更高的精度。然而,与kmeans++和COPL相比,TCQSA的使用产生的性能降低最小。具体而言,在所有数据集上,TCQSA对ACC、SEN和SPE的降低分别小于1.9%、2%和0.9%。此外,我们观察到COPL在大多数情况下比k- meme++表现更差,这证实了表3的结果。特别是,COPL比TCQSA落后3.3%的ACC, 3.2%的SEN和3.2%的SPE,这表明TCQSA可以更一致地从每个准周期中识别出最具代表性的点作为最终周期点。
总结与展望
为了检测qts的异常,我们结合TCQSA和HALCM设计了AQADF。TCQSA采用分层聚类,因此可以应用于不同类型的qts。此外,去除异常值使TCQSA更加稳健。LSTM和CNN的结合使HALCM能够更全面地模拟QTSs的变化模式。此外,三种注意机制的使用有助于更好地表征qts的变化模式。在公共数据集上的实验表明,TCQSA在MSV中超过了两条前沿基线。
HALCM在4个数据集上获得了至少97.3%的ACC,比4个基线中的最佳值高出3.1%。未来的工作旨在设计结构更简单但性能更高的注意机制。