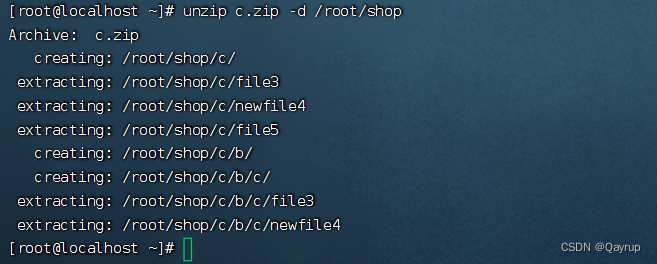
科技创新—人工智能应用技术的出现
人工智能(Artificial Intelligence,AI)研究目的是通过探索智慧的实质,扩展人类智能——促使智能主体会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、专家系统等)、会学习(知识表示,机器学习等)、会行动(机器人、自动驾驶汽车等)。一个经典的AI定义是:“ 智能主体可以理解数据及从中学习,并利用知识实现特定目标和任务的能力。(A system’s ability to correctly interpret external data, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation)
发展历程
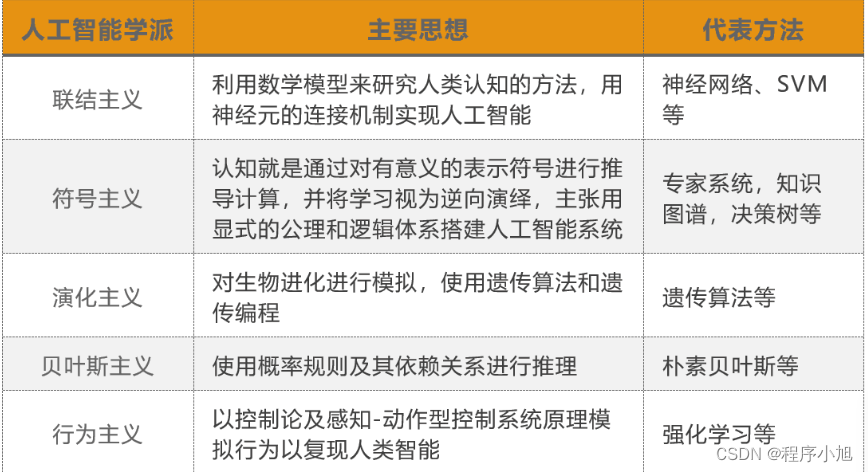
在人工智能的发展过程中,不同时代、学科背景的人对于智慧的理解及其实现方法有着不同的思想主张,并由此衍生了不同的学派,影响较大的学派及其代表方法如下:
- 起步发展期:1943年—20世纪60年代
- 反思发展期:20世纪70年代
- 应用发展期:20世纪80年代
- 平稳发展期:20世纪90年代—2010年
- 蓬勃发展期:2011年至今
应用范围
随着大数据、云计算、互联网、物联网等信息技术的发展,泛在感知数据和图形处理器等计算平台推动以深度神经网络为代表的人工智能技术飞速发展,大幅跨越了科学与应用之间的技术鸿沟,诸如图像分类、语音识别、知识问答、人机对弈、无人驾驶等人工智能技术实现了重大的技术突破,迎来爆发式增长的新高潮。
关键节点
1943年,美国神经科学家麦卡洛克(Warren McCulloch)和逻辑学家皮茨(Water Pitts)提出神经元的数学模型,这是现代人工智能学科的奠基石之一。
1950年,艾伦·麦席森·图灵(Alan Mathison Turing)提出“图灵测试”(测试机器是否能表现出与人无法区分的智能),让机器产生智能这一想法开始进入人们的视野。
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。
感知机可以被视为一种最简单形式的前馈式人工神经网络,是一种二分类的线性分类判别模型,其输入为实例的特征向量想(x1,x2…),神经元的激活函数f为sign,输出为实例的类别(+1或者-1),模型的目标是要将输入实例通过超平面将正负二类分离。
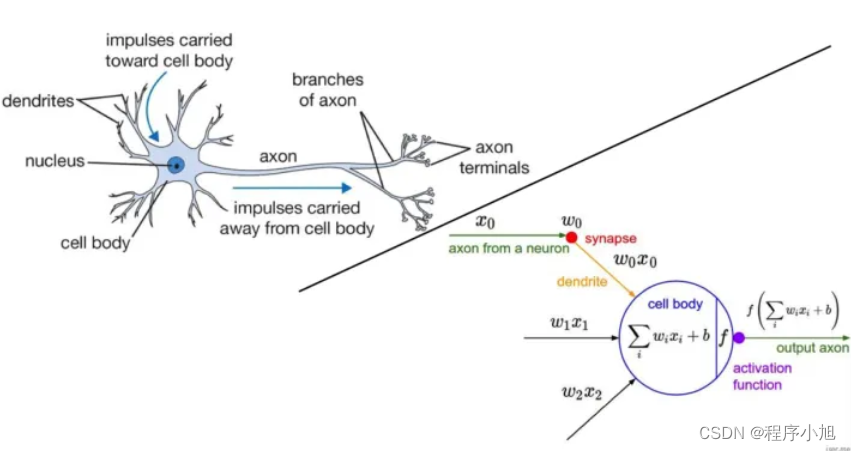
1958年,David Cox提出了logistic regression。
LR是类似于感知机结构的线性分类判别模型,主要不同在于神经元的激活函数f为sigmoid,模型的目标为(最大似然)极大化正确分类概率。
1982年,约翰·霍普菲尔德(John Hopfield) 发明了霍普菲尔德网络,这是最早的RNN的雏形。霍普菲尔德神经网络模型是一种单层反馈神经网络(神经网络结构主要可分为前馈神经网络、反馈神经网络及图网络),从输出到输入有反馈连接。它的出现振奋了神经网络领域,在人工智能之机器学习、联想记忆、模式识别、优化计算、VLSI和光学设备的并行实现等方面有着广泛应用。
1989年,LeCun (CNN之父) 结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络(Convolutional Neural Network,CNN),并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。
卷积神经网络通常由输入层、卷积层、池化(Pooling)层和全连接层组成。卷积层负责提取图像中的局部特征,池化层用来大幅降低参数量级(降维),全连接层类似传统神经网络的部分,用来输出想要的结果。