目录
一、整体概要
二、生成器
三、判别器
四、模型训练
五、其它改进
一、整体概要
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)采用了一种“生成器——判别器”结构,其与生成式对抗网络(Generative Adversarial Net,GAN)的结构非常相似。ELECTRA的整体模型结构如下图所示。

图中可以看到ELECTRA是由生成器(Generator)和判别器(Discriminator)串联起来的一个模型。这两个部分的作用如下。
(1)生成器。一个小的掩码语言模型(MLM),即在 [MASK]的位置预测原来的词;
(2)判别器。判断输入句子中的每个词是否被替换,即使用替换词检测(Replaced Token Detection,RTD)预训练任务,取代了BERT模型原始的MLM。需要注意的是这里并没有使用下一个句子预测(NSP)任务。
接下来,我们将结合图中的例子,详细介绍生成器和判别器的建模方法。
二、生成器
对于生成器来说,其目的是将带有掩码的输入文本x= x
1,
···,xn
,通过多层Transformer模型学习到上下文语义表示
h
=
h
1,
···,
h
n,并还原掩码位置的文本,即BERT中的MLM任务。需要注意的是,这里只预测经过掩码的词,即对于某个掩码位置t,生成器输出对应原文本 xt 的概率 (|V|是词表大小):
(|V|是词表大小):

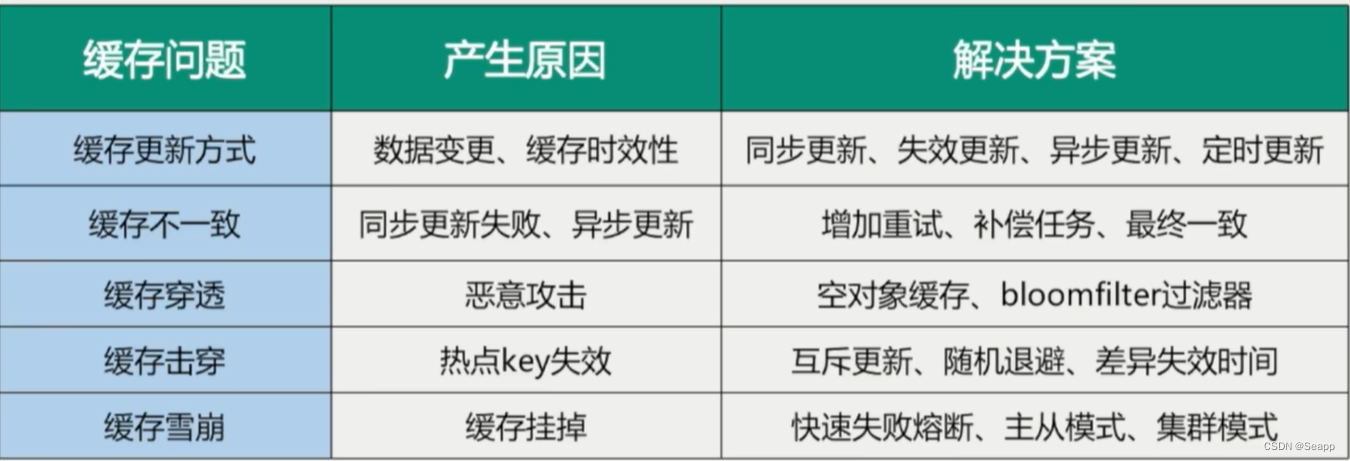
式中, 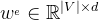 表示词向量矩阵;
表示词向量矩阵; 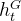 表示原文本xt
对应的隐含层表示。
表示原文本xt
对应的隐含层表示。
还是以上图为例,原始句子 x = x
1
x
2
x
3
x
4
x
5
如下:
the chef cooked the meal
经过随机掩码后的句子如下,记 M = {1, 3} 为所有经过掩码的单词位置的下标,记 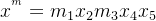 为经过掩码后的输入句子,如下所示:
为经过掩码后的输入句子,如下所示:
[MASK] chef [MASK] the meal
那么生成器的目标是将m
1
还原为x
1
(即the),将m
3
还原为x
3
(即cooked)。在理想情况下,即当生成器的准确率为100%时,掩码标记 [MASK] 能够准确还原为原始句子中的对应单词。然而,在实际情况下,MLM的准确率并没有那么高。如果直接将掩码后的句子  输入生成器中,将产生采样后的句子
输入生成器中,将产生采样后的句子  :
:
the chef ate the meal
从上面的例子可以看到,m
1
通过生成器成功地还原出单词the,而m3
采样(或预测)出的单词是ate,而不是原始句子中的cooked。
生成器生成的句子将会作为判别器的输入。由于通过生成器改写后的句子中不包含任何人为预先设置的符号(如 [MASK]),ELECTRA通过这种方法解决了预训练和下游任务输入不一致的问题。
三、判别器
受MLM准确率的影响,通过生成器采样后的句子 与原始句子有一定的差别。接下来,判别器的目标是从采样后的句子中识别出哪些单词是和原始句子 x 对应位置的单词一样的,即
替换词检测
任务。上述任务
可以通过二分类方法实现。
对于给定的采样句子 ,通过Transformers模型得到对应的隐含层表示 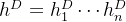 。随后,通过一个全连接层对每个时刻的隐含层表示映射成概率。
。随后,通过一个全连接层对每个时刻的隐含层表示映射成概率。

式中, 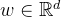 表示全连接层的权重(d表示隐含层维度);M表示所有经过掩码的单词位置下标;σ表示Sigmoid激活函数。 假设1代表被替换过,0代表没有被替换过,则生成器采样生成的句子“the chef ate the meal”对应的预测标签如下,可以记为 y = y1···yn,即:
表示全连接层的权重(d表示隐含层维度);M表示所有经过掩码的单词位置下标;σ表示Sigmoid激活函数。 假设1代表被替换过,0代表没有被替换过,则生成器采样生成的句子“the chef ate the meal”对应的预测标签如下,可以记为 y = y1···yn,即:
00100
四、模型训练
生成器和判别器分别使用以下损失函数训练:
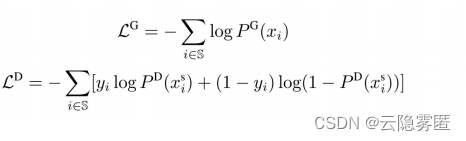
最终,模型通过最小化以下损失学习模型参数:

式中,X 表示整个大规模语料库; 和
和 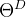 分别表示生成器和判别器的参数。
分别表示生成器和判别器的参数。
注意:由于生成器和判别器衔接的部分涉及采样环节,判别器的损失并不会直接回传到生成器,因为采样操作是不可导的。另外,当预训练结束后,只需要使用判别器进行下游任务精调,而不再使用生成器。
五、其它改进
(1)更小的生成器。通过前面的介绍可以发现,生成器和判别器的主体结构均由BERT组成,因此两者完全可以使用同等大小的参数规模。但这样会导致预训练的时间大约为单个模型的两倍。为了提高预训练的效率,在ELECTRA中生成器的参数量要小于判别器。具体实现时会减小生成器中Transformer的隐含层维度、全连接层维度和注意力头的数目。对于不同模型规模的判别器,其缩放比例也不同,通常在1/4~1/2之间。以ELECTRA-base模型为例,缩放比例是1/3。下表展示了
ELECTRA-base 模型的生成器和判别器的各项参数大小对比。

为什么是减小生成器的大小,而不是判别器的大小?因为上文讲到生成器只会在预训练阶段使用,而在下游任务精调阶段是不使用的,因此减小生成器的大小是合理的。
(2)参数共享
。
为了实现更灵活的建模目的,ELECTRA首先引入了词向量因式分解方法,通过全连接层将词向量维度映射到隐含层维度。由于上面讲到,ELECTRA使用了一个更小的生成器,因此生成器和判别器之间无法直接进行参数共享。在ELECTRA中,参数共享只限于输入层权重,其中包括词向量和位置向量矩阵。