元宇宙时代的娱乐场景下,通过高精度的AI驱动模型还原真人的歌舞表演,有着更低成本、更多创造性、精彩度、实时互动性的综合优势,是虚拟数字人驱动的最终形态。LiveVideoStackCon 2022北京站邀请到腾讯音乐天琴实验室计算机视觉负责人——董治,为大家介绍TME天琴实验室在音乐驱动领域的 Music XR Maker 系统,包括虚拟人舞蹈生成、歌唱表演生成、音乐灯光秀等方面的最新进展。
文/董治
编辑/LiveVideoStack
本次分享的主题是“音乐驱动虚拟人”,重点关注到娱乐场景下的虚拟人AI驱动方案。

这是天琴实验室的虚拟人——小琴,她在QQ音乐有专门的歌手页,会发歌、发视频,未来在站内或站外都会发布作品。
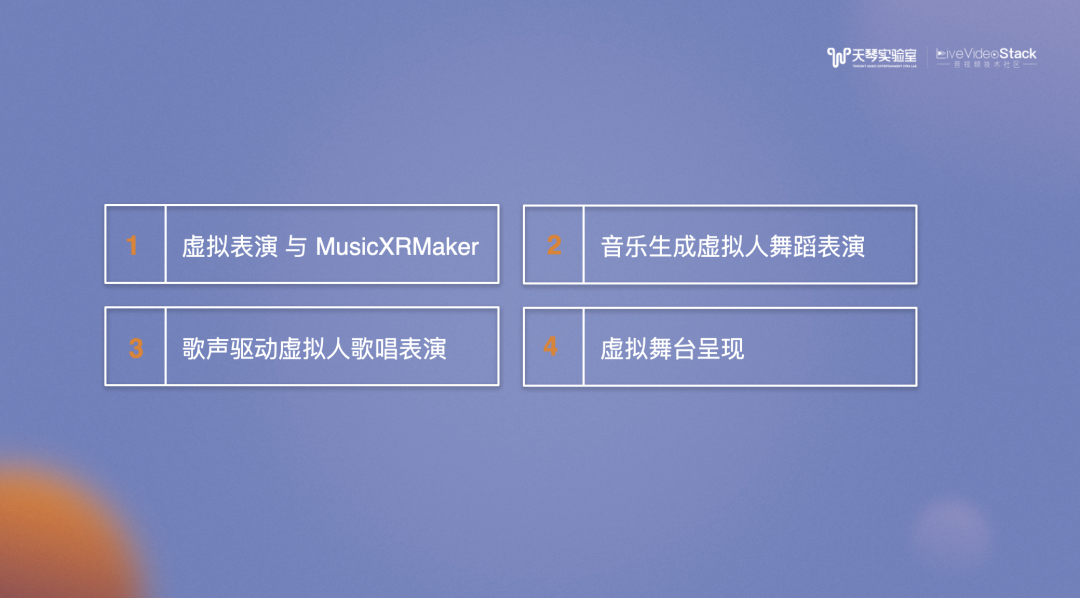
本次分享主要包括四部分:
-01-
虚拟表演与MusicXRMaker

虚拟人业务场景可以分为三块技术栈:建模、驱动和渲染。
建模阶段有许多品类的虚拟形象,图中是TME旗下的四位虚拟人:2D的安可、3D的扇宝、部分写实的小琴和超写实的Lucy。
创造虚拟人成本开销大部分在于建模,目前有许多技术手段能够降低建模成本,主要是2D或3D的拍照捏脸技术,拍摄图片后建立相似的虚拟形象。

MetaHuman能够快速建立超写实的虚拟人头像,并且已经在游戏、虚拟人的场景中有着广泛的应用。如果要建立完善的、商业化的、虚拟偶像级别的虚拟人,则更偏向于用相机的阵列环境,拍照采集更多信息,或是直接人工通过美术操作建模,但这成本相对更高。

建模环节使用较多的工具是MAYA,以上四种工具渲染的模型中,MAYA的渲染效果最写实漂亮。
如果要做CG,会将模型转到C4D,从MAYA转到C4D是可控的操作,但用C4D做CG会造成到更多的人力成本。
此外,还可以通过实时的渲染引擎来驱动,包括UNREAL和unity两个途径,存在的gap是并不能直接通过工具将MAYA转为UNREAL或是unity,如果要做到好的效果,需要涉及到非常多的细节重现。
转换后在实时渲染引擎的展现效果可以达到MAYA的90%左右,但无法完全超越MAYA。
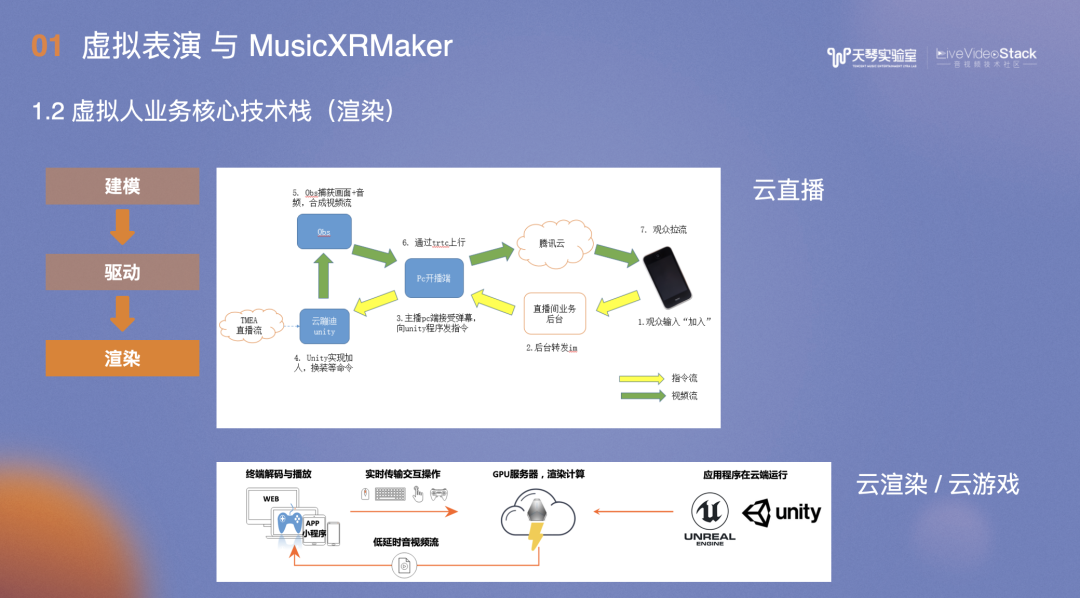
渲染后如何呈现?最简单的方法是在UNREAL或unity中渲染为离线视频进行播放,实时播放常用的途径是云直播,在后端PC开一台PC机,将虚拟引擎渲染的画面传到CDN的直播流,观众端可以像看普通直播一样观看虚拟人的表演。若要进行互动如输入文字、送礼,可以传到后台PC的渲染端,在渲染画面中得到对应的反馈。更高级的做法是通过云渲染,云游戏方式,云直播方式下所有人看到的画面是一致的,云渲染或云游戏方式下,每个人可以操控自己的视觉,画面具有可控性。目前云游戏方案存在的问题是成本较高,不可能在广泛的场景中推动。

除了建模和渲染,虚拟人业务最核心的是如何驱动虚拟人,主要分为两条线路,第一条是通过中之人表演,利用实时驱动技术驱动虚拟人,其痛点在于必须依赖中之人的表演。

第二条是AI驱动,业内大家较熟悉的是客服AI数字人、数字播报,但娱乐类和工具类的虚拟人不同,细分下去,我们属于AI驱动中的音乐驱动,驱动根源是歌曲,让虚拟人唱歌、舞蹈。会涉及到歌声口型、舞蹈动作、乐器手势、歌唱表情等。
实现娱乐场景下的虚拟人,不仅需要考虑到“动起来”,还需要综合考虑表演、舞美、运镜,编导和灯光。
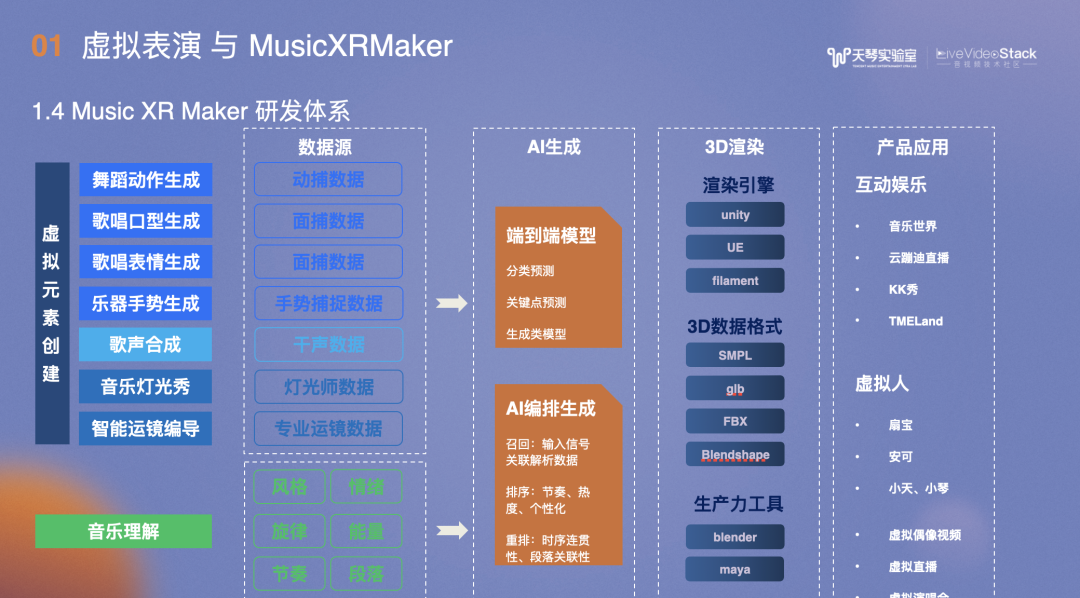
综合以上便是Music XR Maker研发体系,图中是虚拟元素创建的具体工作,通过各种途径拿到数据源,基于对音乐的理解,风格旋律情绪能量节奏段落等,实现AI生成。大体分为两类:
1、端到端模型,包括分类预测、关键点预测和生成类模型;
2、AI编排生成,包括召回、排序和重排。最终通过3D渲染手段应用在产品端,主要是互动场景,包括音乐世界、云蹦迪直播、KK秀和TMELand,及专门的虚拟人,包括扇宝、安可、小天、小琴等,在虚拟人方面还可以延伸出虚拟偶像视频、虚拟直播和虚拟演唱会。
-02-
音乐生成虚拟人舞蹈表演

虚拟人物到舞蹈生成以分为三种方式:动捕棚,视频复刻和基于音乐生成。
1、动捕棚。图中是腾讯搭建的较专业的动捕棚,包括多目动捕、惯性动捕。其效果最佳,但价格昂贵,人力、设备成本高,主要用于精品视频输出。
2、视频复刻。识别视频人物的骨骼动作,现有阶段,单目动捕能容纳的信息有限,易造成效果上的细节缺失,但其人力成本低,适合低精度场景及抓热点场景。
3、基于音乐生成,也是纯算法生成。效果依赖于数据和算法的性能,困难在于数据获取。适用于批量生产场景,如为几千万或上亿曲库中的每首歌适配较好的舞蹈,类似于AIGC途径。
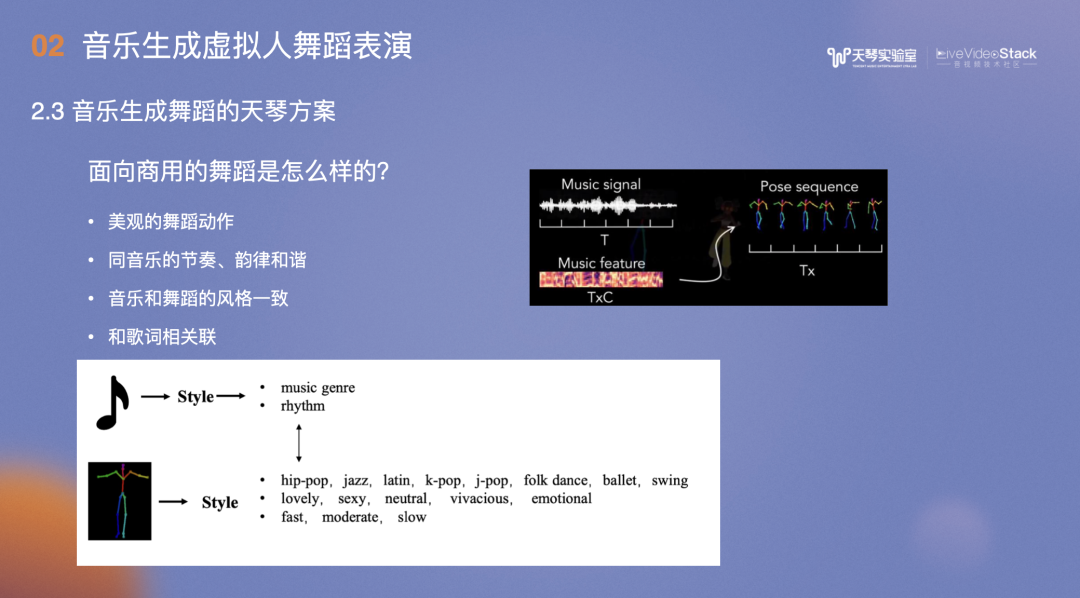
生成商用舞蹈主要考虑以下几点:首先,生成的舞蹈至少是好看的,在此前提下,还需与音乐的节奏、韵律、和弦及风格保持一致。其次,许多新出的歌曲,其舞蹈动作和歌词相关联。
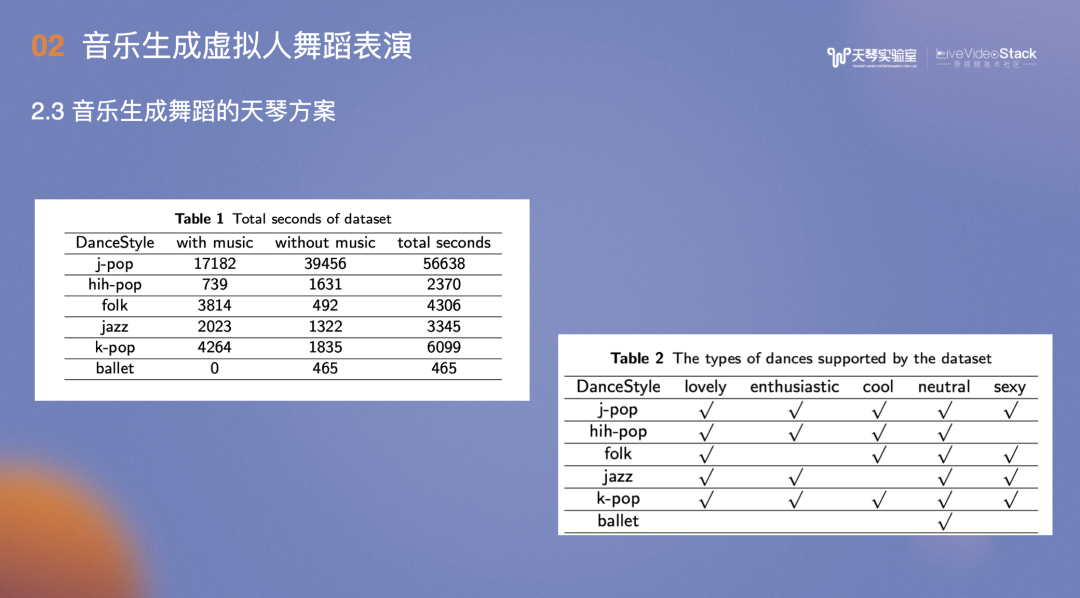
我们综合动捕手段和开源数据集生成了天琴舞蹈数据集,包含20小时、不同情绪下的舞蹈数据,其中不乏K-POP、J-POP等舞种。
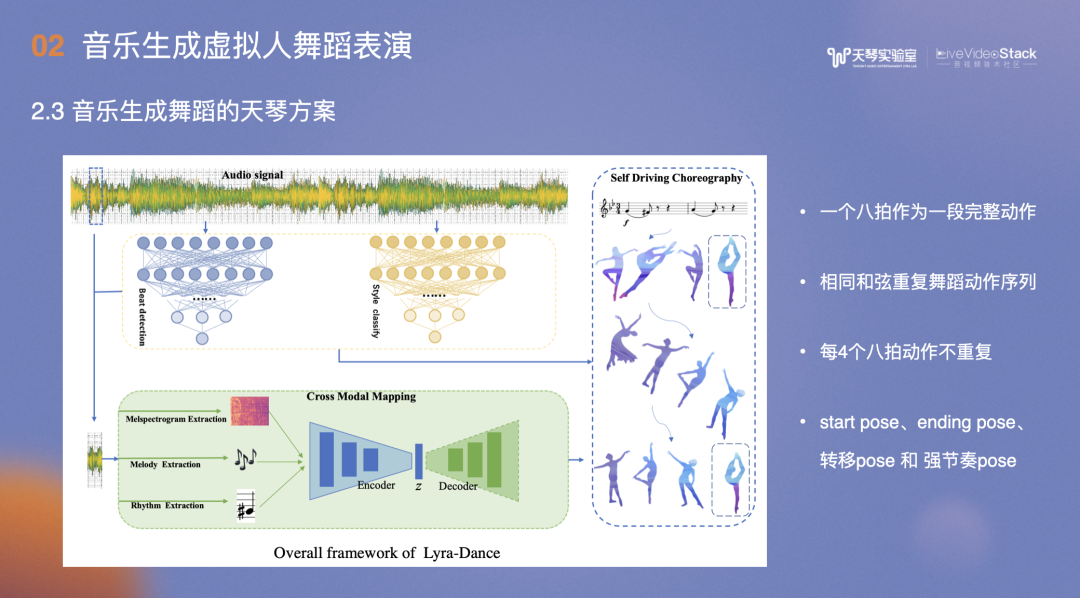
天琴方案主要是将一段音乐数据进行切片,对应的舞蹈数据按一个八拍作为一段完整动作,选取一个八拍是因为一个八拍接一个八拍的舞蹈动作相对流畅,若切分一个八拍,其流畅度会下降。
得到音频数据后,分析其音乐特征,包括Melody、Mel spectrogram、Rhythm,最后通过Encoder和Decoder网络找到匹配的舞蹈片段。
以上涉及到几点:首先是召回的动作,一小段一个八拍的音频可以在动作库中挑选到合适的动作集,一段音乐挑十个动作集,如何串联每段音乐挑选的动作集,形成连贯动作?需要考虑音乐的beat,计算前后动作的转移概率,也就是一个动作完成后接另一个动作的概率、前后两个动作的朝向和速度,如果前一个动作过快,而后一个过慢,间隔时间较长,那么整体看起来会不协调。最后综合歌词文本信息,形成串联方案,完成整首歌曲的舞蹈编排。
此外,专业意见包括:相同的和弦重复舞蹈动作序列、每4个八拍的舞蹈最好不要重复、设计start pose和ending pose,这些会在舞蹈片段中特别标记。
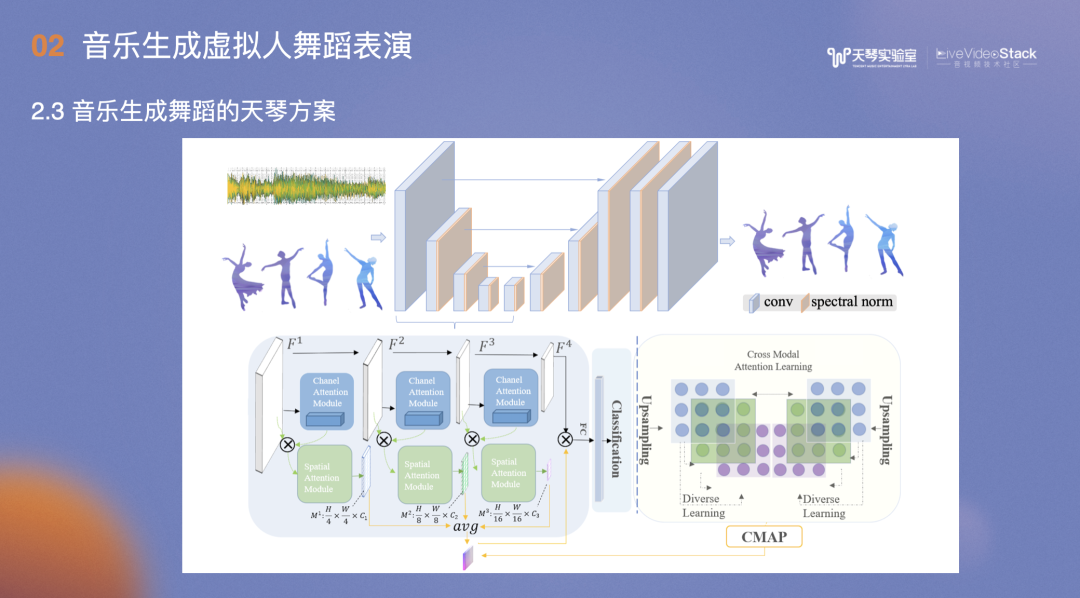
我们同时测试了一套纯生成,没有用到编排的方案,其效果较差。原因大致是数据集偏少。舞蹈项目的数据收集成本很高,因为要用到动捕棚,还需要专业人员反复表演,才能达到较好的效果。我们也尝试输入音频舞蹈动作,通过Encoder和Decoder网络直接输出舞蹈动作,在网络里尽量拉齐模态向量。

这是舞蹈生成效果展示。
BGM是合成的,涉及到音频的歌声合成技术,采用的是搜集到的小琴的专有音色。
舞蹈生成主观评测打分包括两种方式:
1、生成结果vs手K结果;2、用户分别为生成结果和手K结果打分。
最终结论是生成的总体质量均分已经接近手K。
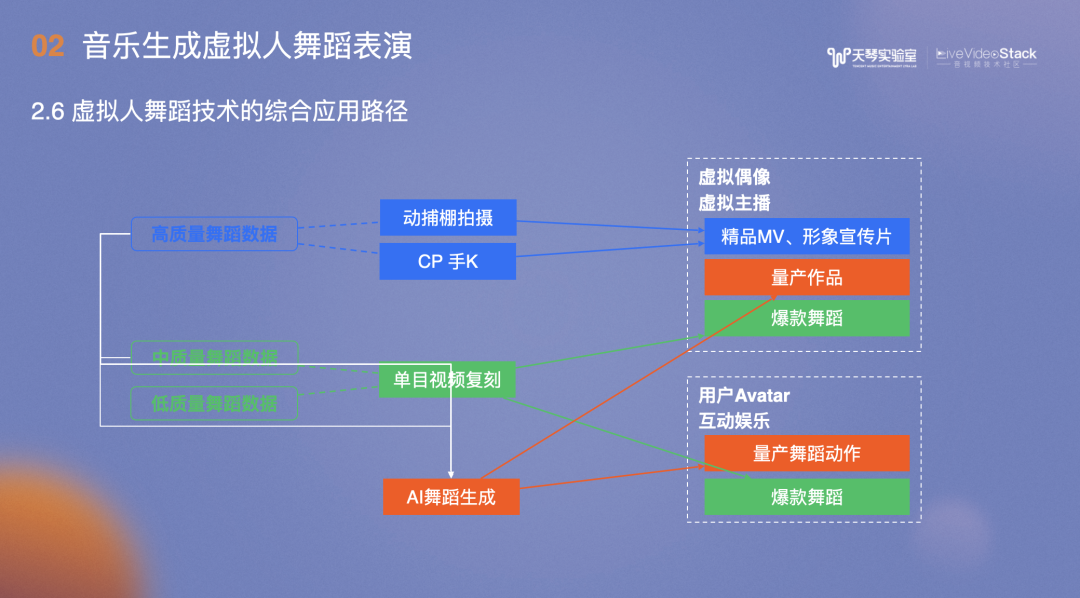
总结一下以上手段的应用。
动捕棚拍摄和CP手K的成本相当高,生成的高质量舞蹈数据用于精品MV和形象宣传片,数据会收入AI舞蹈数据库中。
单目视频复刻适用于爆款舞蹈,对生成的动作进行分类后,中质量舞蹈数据会收入AI舞蹈数据库,低质量的数据直接丢弃。
AI舞蹈生成用于量产动作及用户Avatar。虚拟偶像较多用于直播场景,比如用户点一首歌,在想跳某首歌的舞蹈时,无论是哪首歌都能跳起来。另一个用处是,虚拟主播表演时,在前一阶段只需聊天,无需歌唱、舞蹈才艺,需要的时候可以直接用生成方式。即使用中之人,对其要求也只是能够聊天沟通,在舞蹈技能方面的要求大幅度降低。
-03-
歌声驱动虚拟人歌唱表演

虚拟人歌唱涉及到口型和表情,超写实虚拟人配备了专业的设备及面捕方案。普通虚拟人则能够直接使用普通手机摄像头,实时驱动52BS的面部表情,包括Unity 兼容的 ARKit、Unreal的Livelink。

这里展示的是虚拟人歌唱和说话驱动的差别,主要区别在于口型。说话时,口型改变频率加快,而歌唱时,一句歌词的口型变化是连贯的动作。
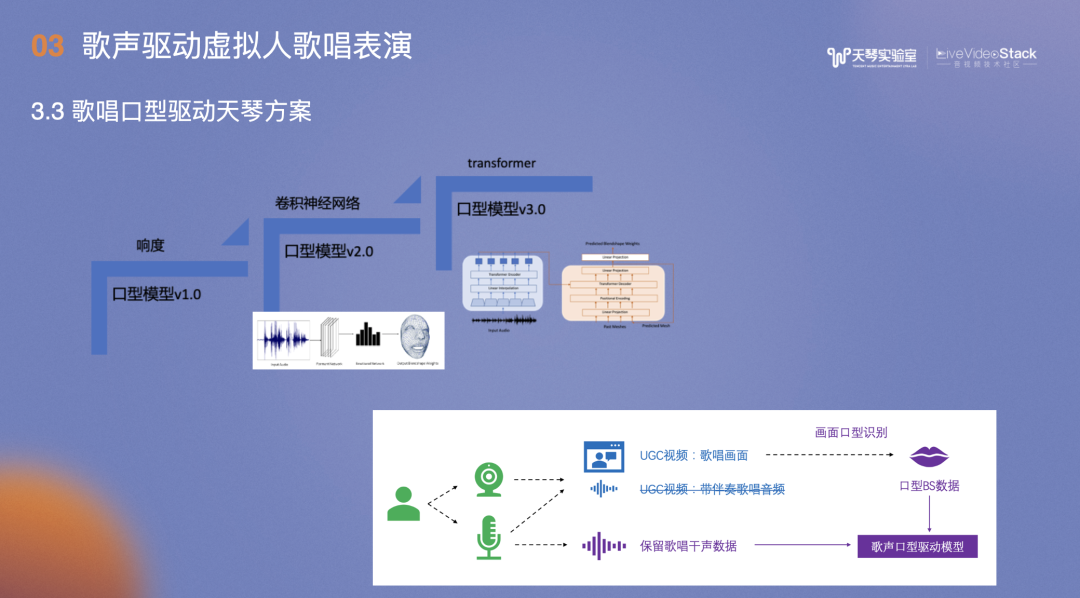
歌唱口型的建模经历了三次迭代。1.0版本通过歌声响度即可实现,2.0版本通过卷积神经网络,在输入音频后能够直接预测面部的BS信息,3.0版本考虑到前后数据信息,采用Transformer架构。数据方面,受益于K歌较好的带画面的歌词数据,客户生成UGC带画面的歌唱作品时,通过视频面捕识别出唱歌时的口型BS数据和唱歌时的干声,再将口型BS数据和干声数据输入到歌声口型驱动模型,形成歌唱口型方案数据。
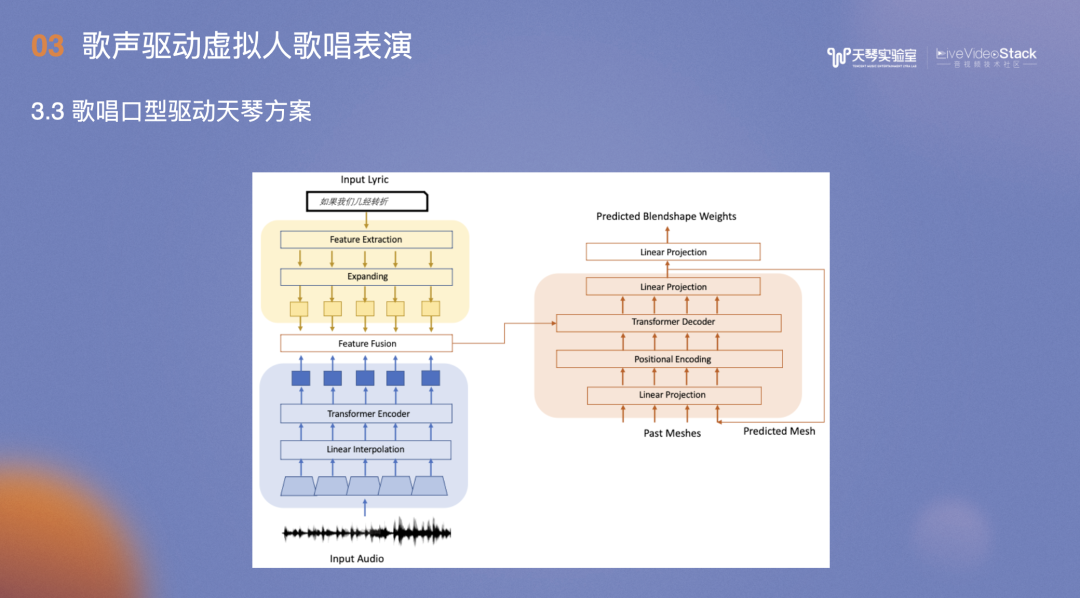
在基于Transformer的模型中,输入用户演唱歌曲的歌词及音频信息,提取两者特征并进行特征融合后输入框架,经过几轮的迭代后,最终输出虚拟人的Blendshape权重。
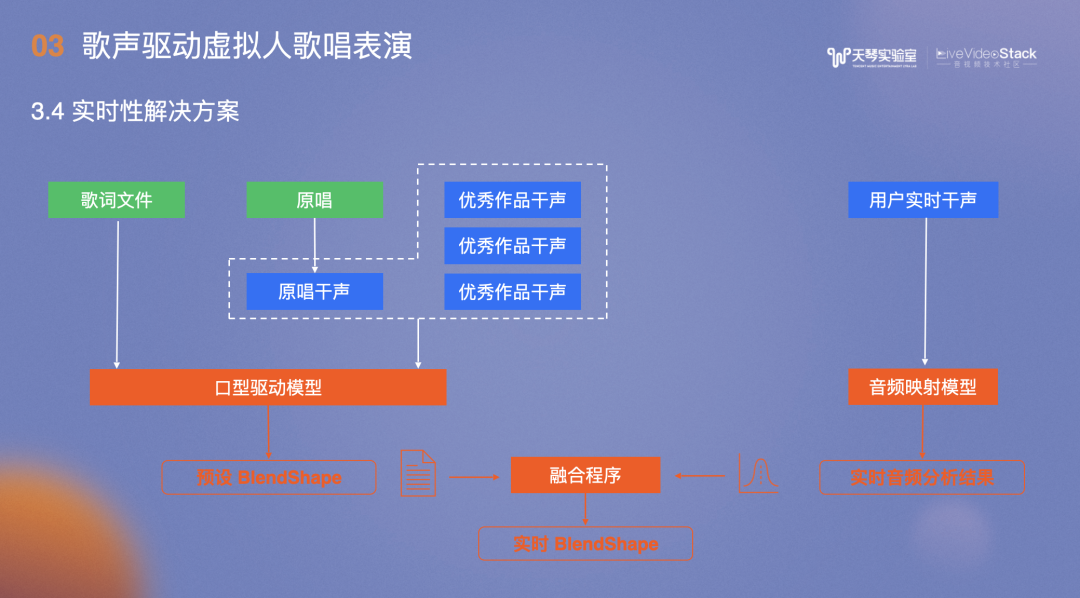
上文介绍的是异步方案,实时性解决方案则是通过原唱和优秀的干声,根据歌词文件生成标准的口型驱动模型,作为预测BlendShape,再通过用户的实时干声得到当前情况,融合两者形成BlendShape。
计算量最大部分放在了异步处理。
另一套方案不涉及模型,即音素转视素,在TTS实时产生音素信息,根据得到的相应视素调整口型。

这是K歌8.0版本以上的“KK秀”功能,用户在唱歌时既有歌词在跑,也有KK秀的小人表演。
左侧是录唱场景,右侧是歌房场景。


最终的生成效果不仅包括歌唱口型。在观察了许多真实歌唱表演后,我们认为一场好的演出除了口型需要和歌曲匹配之外,还需要综合生动的表情、手势、身形。
在实际应用中,真实的歌唱模型包括口型模型及对应的表情、动作和手势输出。

具体方案首先收集带表情演唱视频,类似口型做法,通过面捕拿到表情数据,动捕拿到动作数据,手捕拿到手势数据,再将三者结合作为歌唱表情段,输入歌唱表情库。
右侧是使用小琴模型输出的各种眼神效果。
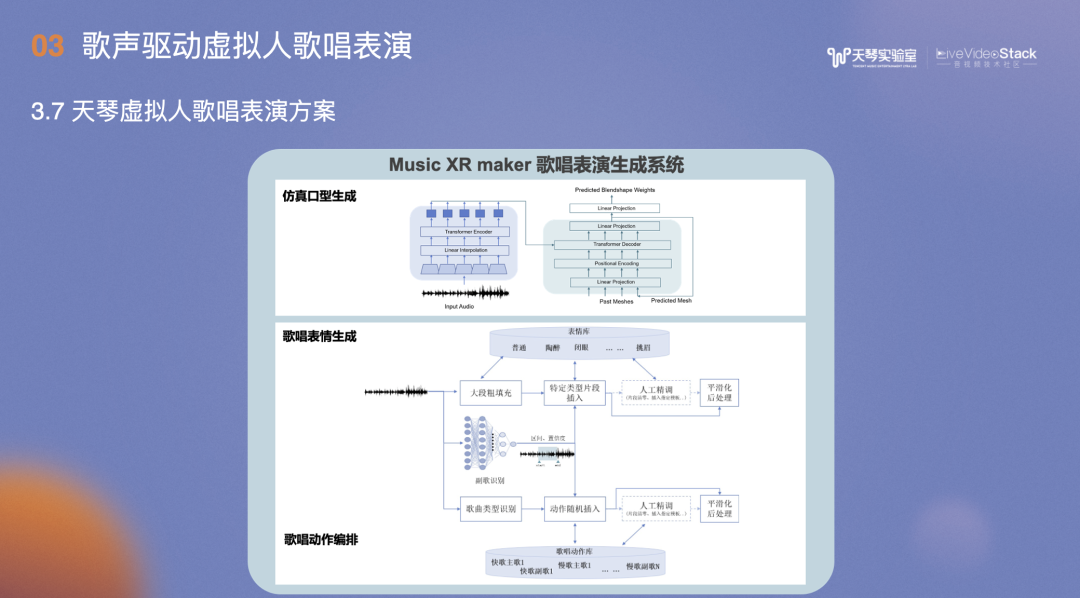
在歌唱表演生成系统中,前面是仿真口型生成,后面是表情和动作生成。
同样是解析音频,提取歌曲类型和高潮时间点、歌曲情感,在特定类型的片段和位置插入对应表情库中的表情,如陶醉、闭眼、挑眉等及歌唱动作。
此外,还要对插入的片段进行平滑处理。

以上表情歌唱的表演会应用在天琴虚拟人的表演和演讲方案中。
这是TME财报小型表现的片段:
这是小琴在《你好,大学声》中做的自我介绍:
-04-
虚拟舞台呈现

完整的虚拟舞台的呈现,除了包括虚拟人的人物表情、口型动作之外,还需要两方面:
灯光舞美和运镜编导,相对于舞台动作的数据,这二者更小众专业。
目前的方案通过专业的灯光老师及摄影老师自己的专业经验和传统手段,并没有涉及到太多自动化动作,于是我们思考通过算法实现这部分工作,从而降低表演成本。
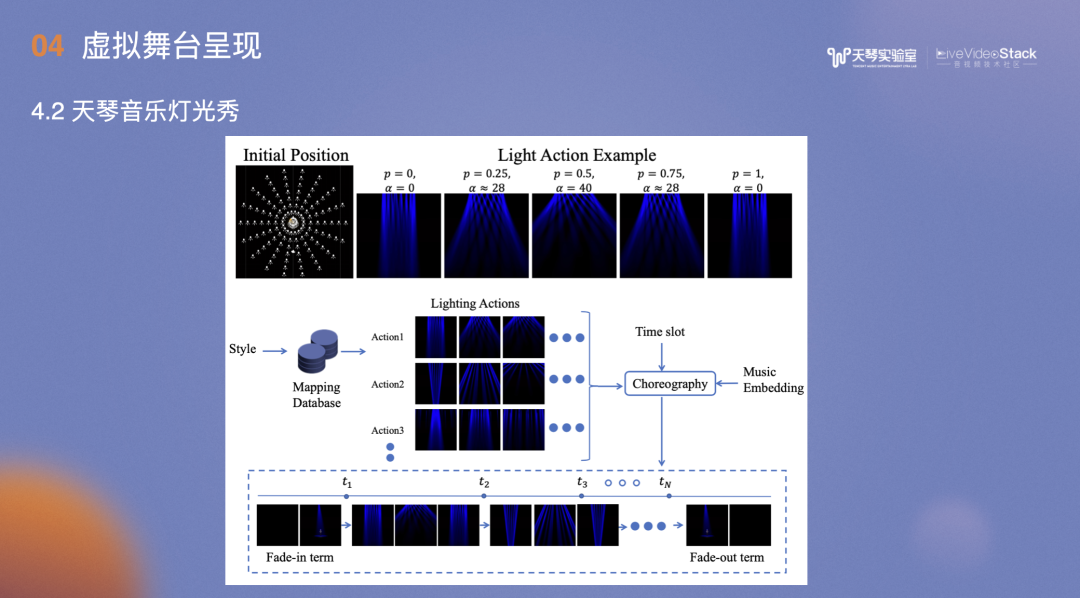
图中是音乐灯光秀流程:
首先为场景设计灯光,包括类型、数量等,布置完之后,每个灯要有相应的动作,亮或不亮、转动方向、颜色,灯光属性等,这是一个灯的动作,那么将所有灯的轨迹动作连贯起来,就形成了一套灯光展现的方案。
输入音乐信号,在预设灯光库中找到一个个的Action,最后通过时间序列拼接所有Action。
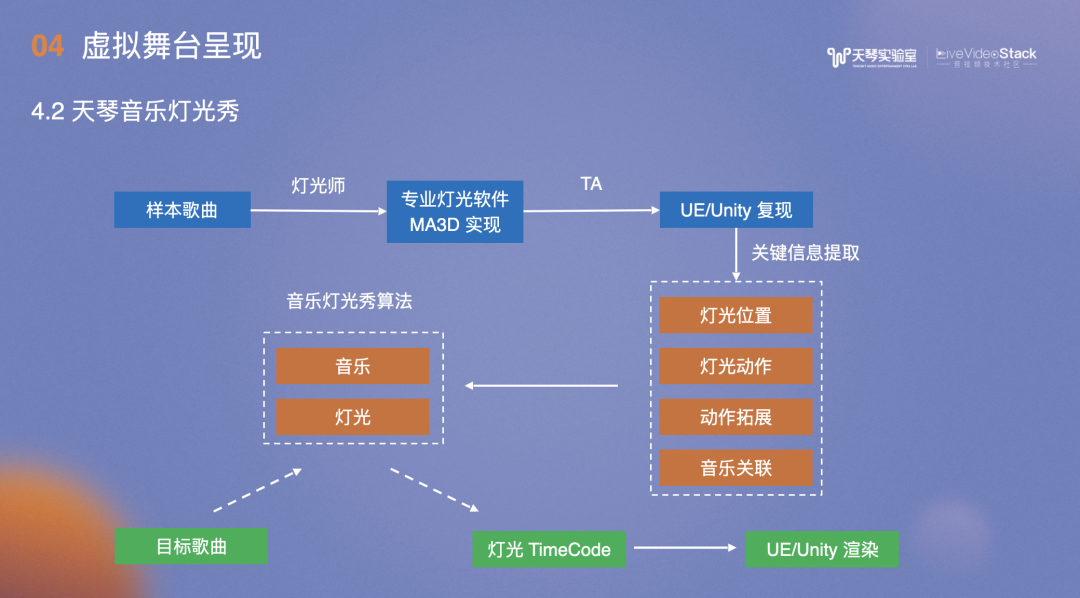
灯光秀的数据收集非常麻烦,样本歌曲可以通过专业的灯光师操作专业的灯光软件实现,但实现效果无法直接应用到Unity/UE,需要用到TA的同学在Unity/UE复现。复现的同时,提取关键信息包括灯光位置、动作、和音乐的关联信息等,此外,还要输入音乐灯光秀算法。最终,输入的目标歌曲经过算法得到TimeCode,并在Unity/UE中渲染。

自动运镜时需要跟踪任务的动作、手势、快慢,旋转角度等。编导还需要考虑到音乐、灯光,如灯光好看时应该呈现全局的表现、人物表现,如在人物陶醉时给面部特写,动作精美时给全身特写。


专业灯光老师操作灯光软件的渲染效果:
用Unity/UE将专业灯光老师的知识复刻之后,在云蹦迪实现的业务效果:

音乐世界的蹦迪场景和3D KK秀场景也应用了专业的灯光技术手段,让互动舞台有更好的灯光效果。

这是带了灯光及运镜的舞台效果:
BGM也是使用小琴的音色合成的,能在小琴的QQ音乐主页观看。
-05-
总结与展望
最后总结如下:
当前,虚拟人在娱乐公司、明星、主播、及普通用户中都有应用。中之人驱动面临着成本、管理、灵魂归属相关问题。
TME天琴实验室主要专注在娱乐场景下的AI驱动及音乐驱动方案,当前技术也在快速升级,包括形象创建、视觉驱动、音频合成。形象创建在最新的3D AIGC有很多进展,Unity/UE都有自己的3D AIGC工作。我们也在实时跟踪,判断是否能广泛应用。
最终我们的核心解决方案是为虚拟人提供专业的虚拟演唱方案&Music XR Maker。
下方是TME已有的虚拟偶像场景和成果,包括TMELand、小琴、扇宝、安可、Lucy、K歌8.0及酷狗的超越AI等。

以上是本次的分享,谢谢!

▲扫描图中二维码或点击“阅读原文” ▲
查看更多LiveVideoStackCon 2023上海站精彩话题