1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| Prefix-Tuning:Optimizing Continuous Prompts for Generation | Xiang Lisa Li等 Stanford University | Annual Meeting of the Association for Computational Linguistics | 2021 |
Citations 1009, References
论文链接:https://aclanthology.org/2021.acl-long.353.pdf
论文代码:Code XiangLi1999/PrefixTuning + additional community code
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| 语言大模型微调 | 大模型,针对一个任务一个大模型的问题。 | 冻结语言模型参数,优化一个小的连续特定的向量(称为prefifix), Prefifix-tuning的启发于prompting, 使得这个Prefifix像是虚拟的字符。 | 对于每个任务只调试prefix并保存这些调试的参数就可以,区别于之前的全参微调。 | E2E (Novikova et al., 2017), WebNLG (Gardent et al., 2017), and DART (Radev et al., 2020), XSUM | 以0.1% 的训练参数的训练结果与全参训练相当。 | 模型方法 | prefifix-tuning |
Prefix-tuning与Fine-tuning区别:
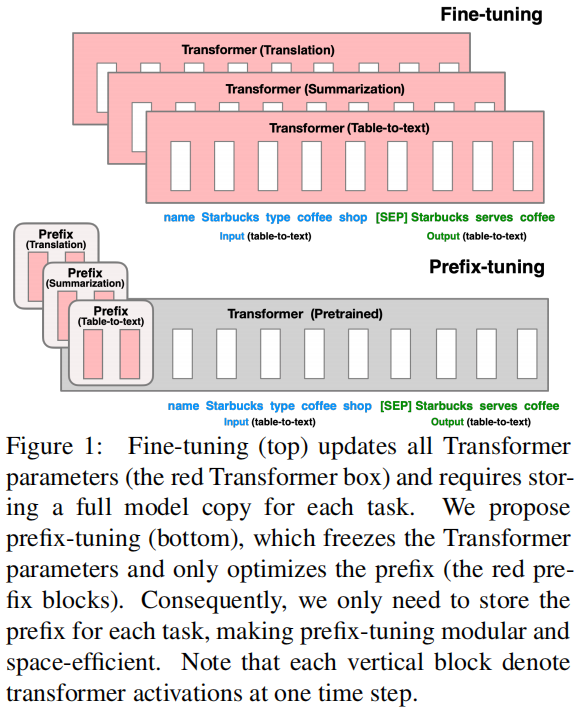
3. 模型(核心内容)
假设拥有一个适当的上下文可以在不改变LM参数的情况下引导LM。
不是优化离散标记,而是将指令优化为连续的单词嵌入。
以一些例子来说明这个模型:
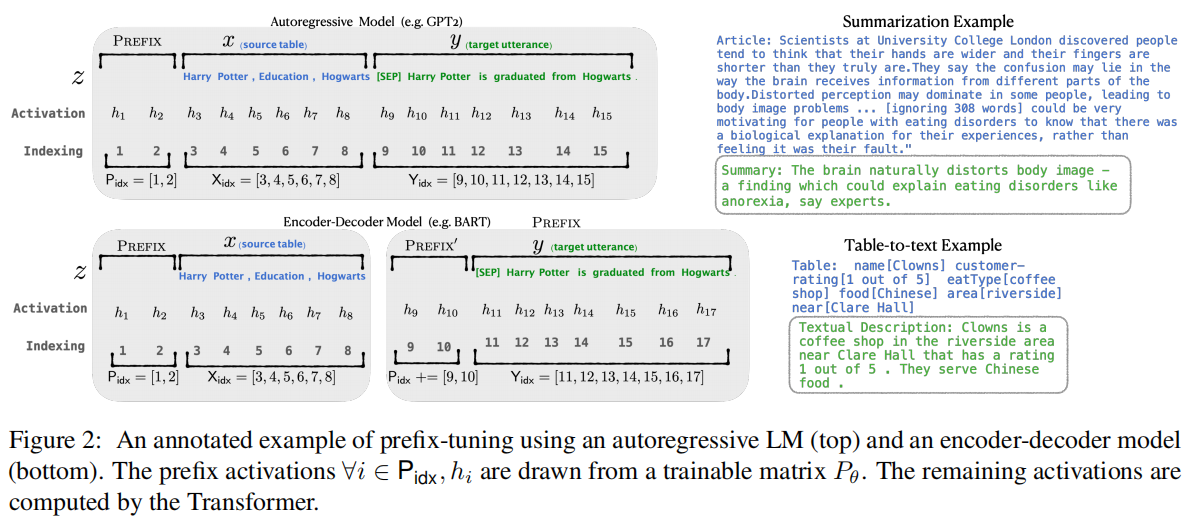
对于一个自回归的LM: **z = [PREFIX; **x; y]
对于encoder-encoder模型: **z **= [PREFIX; x; PREFIX0’; y]
Pidx表示前缀索引的序列;|Pids|表示前缀的数量。
关于隐变量的定义,LM表示为GPT2,P关于参数的矩阵,维度为:|Pidx| × dim(hi):
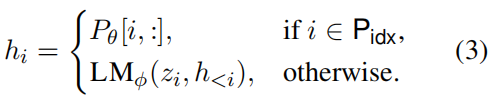
这里的φ是固定的,θ是要训练的参数。
直接优化Pθ问题:直接优化前缀对学习速率和初始化非常敏感。
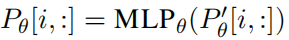
***Pθ与P’θ的行是相同的,但列不相同。训练完成后只有Pθ是保存的。
4. 实验与分析
4.1 数据集
| E2E (Novikova et al., 2017): 一个领域,50K; WebNLG (Gardent et al., 2017):14个领域, 22K;and DART (Radev et al., 2020):开放领域 |
|---|
4.2 效果
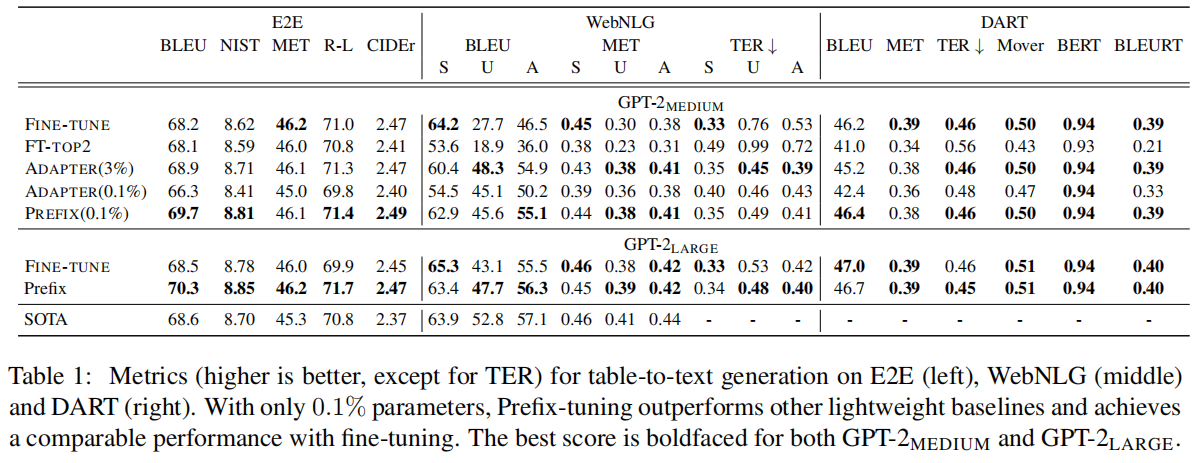
只用0.1%的学习参数比tine-tune还要高。
少样本的情况:
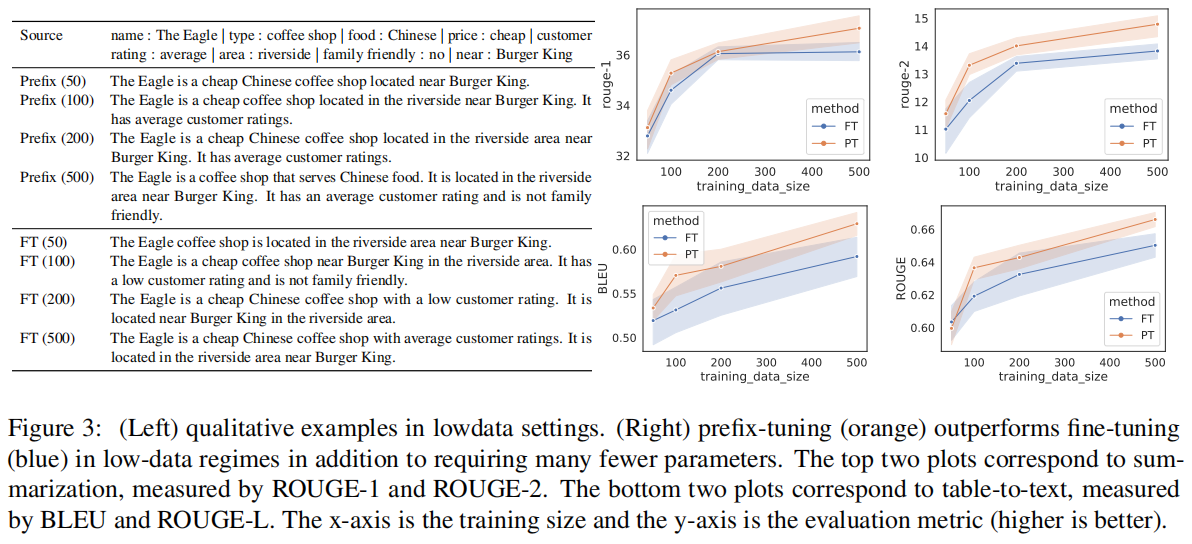
Intrinsic(内在) Evaluation
prefix的长度分析

Full vs Embedding-only
实验结果:discrete prompting *< *embedding-only ablation *< *prefifix-tuning.
Prefifixing vs Infifixing
. [x; INFIX; y] 比[PREFIX; x; y]这种模式稍差。
Initialization(初始值实验): 实验结果显示,用实验相关的词作为prefix会比用不相关的词性能会稍好。
5. 总结
有种做数学题采用辅助线的感觉,保留了原来的东西不变,加入一些内容,让问题更好解决。虽然本质不同,可是真的有点像的。
采用极少的参数去微调任务的适应性;
采用一种连接的方法去挖掘其中的知识,NLP新一代的训练范式已来,软件的新一代的开发模式已来,以后大模型是一种不可或缺的内容。
6. 参考文献
made by happyprince