文章目录
- 前言
- 一、ThreadLocal是什么?
- 二、synchronized 和 ReentrantLock 都是 Java 中提供的可重入锁,二者的主要区别有以下 5 个:
- 三、线程安全的集合类有哪些?
- 四、说一下你对CompletableFuture的理解
- 四、项目中是如何创建线程池的,为什么不用Executors 去创建线程池
- 六、ThreadPoolExecutor 参数说明
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、ThreadLocal是什么?
ThreadLocal是用来维护线程中的变量不被其他线程干扰而出现的一个结构,
内部包含一个ThreadLocalMap类,该类为Thread类的一个局部变量,该Map存储的key为ThreadLocal对象自身,value为我们要存储的对象
这样一来,在不同线程中,持有的其实都是当前线程的变量副本,与其他线程完全隔离,以此来保证线程执行过程中不受其他线程的影响。
ThreadLocal又叫做线程局部变量,全称thread local variable,它的使用场合主要是为了解决多线程中因为数据并发产生不一致的问题。
ThreadLocal为每一个线程都提供了变量的副本,使得每一个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享,这样的结果无非是耗费了内存,也大大减少了线程同步所带来的性能消耗,也减少了线程并发控制的复杂度。
既然这个Entry的key为一个弱引用的threadLocal,那会有什么问题?
关于这个弱应用,当发生gc的时候会将这个弱引用回收掉
当jvm发生gc时,我们的key变为null,相当与下回这个坑位一直被占用,而里面的value为强引用,导致value内存一直占用,产生内存泄漏的问题
为什么ThreadLocal 会发生内存泄漏?
因为ThreadLocal中的key是弱引用,而value是强引用。当ThreadLocal没有被强引用时,在进行垃圾回收时,key会被清理掉,而value 不会被清理掉,这时如果不做任何处理,value将永远不会被回收,产生内存泄漏。
如何解决ThreadLocal的内存泄漏?
其实在ThreadLocal在设计的时候已经考虑到了这种情况,在调用set()、get() 、remove()等方法时就会清理掉key为null 的记录,所以在使用完ThreadLocal 后最好手动调用remove()方法。
为什么要将key设计成ThreadLocal的弱引用?
如果ThreadLocal的 key是强引用,是会发生内存泄漏的。如果ThreadLocal的key是强引用,引用的ThreadLocal 的对象被回收了,但是 ThreadLocalMap还持有ThreadLocal 的强引用,如果没有手动删除,ThreadLocal 不会被回收,发生内存泄漏。
如果是弱引用的话,引用的ThreadLocal的对象被回收了,即使没有手动删除,ThreadLocal也会被回收。value也会在ThreadLocalMap调用set() 、get()、remove()的时候会被清除。
所以两种方案比较下来,还是ThreadLoacl 的key为弱引用好一些。
ThreadLocal 内存泄露问题是怎么导致的?
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。
ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后 最好手动调用remove()方法
ThreadLocal 常见应用场景:
使用场景一:代替参数的显式传递 (注意:这个场景其实使用的比较少,一方面显式传参比较容易理解,另一方面我们可以将多个参数封装为对象去传递。)
使用场景二:全局存储用户信息(项目中用到)
使用场景三:解决线程安全问题
数据库连接,连接后存入ThreadLocal中,如此一来,每一个请求线程都保存有一份自己的Connection。于是便解决了线程安全问题
使用场景四:解决SimpleDateFormat线程不安全问题;
二、synchronized 和 ReentrantLock 都是 Java 中提供的可重入锁,二者的主要区别有以下 5 个:
1.用法不同:synchronized 可以用来修饰普通方法、静态方法和代码块,而 ReentrantLock 只能用于代码块。
2.获取锁和释放锁的机制不同:synchronized 是自动加锁和释放锁的,而 ReentrantLock 需要手动加锁和释放锁。
3.锁类型不同:synchronized 是非公平锁,而 ReentrantLock 默认为非公平锁,也可以手动指定为公平锁。
4.响应中断不同:ReentrantLock 可以响应中断,解决死锁的问题,而 synchronized 不能响应中断。
5.底层实现不同:synchronized 是 JVM 层面通过监视器实现的,而 ReentrantLock 是基于 AQS 实现的。
三、线程安全的集合类有哪些?
Vector:Vector是一个可变长度的数组,它会给几乎所有的public方法都加上synchronized关键字。但由于加锁会导致性能降低到一定程度。
HashTable:
CopyOnWriteArrayList 适合读多写少的场景,写多的情况下,频繁地加锁和复制,也是一笔很大的开销。
ConcurrentHashMap:
Collections针对了各种集合来声明了一个线程安全的包装类,它在原集合的基础上添加了锁对象,这样就使得集合中的每个方法都能够通过这个锁对象来实现同步。
四、说一下你对CompletableFuture的理解
CompletableFuture是JDK1.8里面引入的一个基于事件驱动的异步回调类。
简单来说,就是当使用异步线程去执行一个任务的时候,我们希望在任务结束以后触发一个后续的动作。 可以将多个异步任务串联起来,组成一个完整的链式调用。
比如说。我们做数据挖掘分析时,先把前端传过来的数据入库,再调用R语言函数获取分析结果,再返回给前端,调用R语言函数可能设计到多个接口。故使用CompletableFuture 开启一个异步任务。执行完后异步触发其他接口的调用
CompletableFuture 与 Future 区别:
Future 在实际使用过程中存在一些局限性,例如不支持异步任务的编排组合、获取计算结果的 get() 方法为阻塞调用等
四、项目中是如何创建线程池的,为什么不用Executors 去创建线程池
引用阿里巴巴Java开发手册上的一句话
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样 的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool: 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool和 ScheduledThreadPool: 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
通过Executors创建一个定长线程池,示例(不要使用)
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
严格来说,使用此代码创建线程池时,是不符合编程规范的。
因为主要问题是定长线程池允许的请求队列长度为 Integer.MAX_VALUE,堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
通过手动调用ThreadPoolExecutor去创建线程池
比如我们在Executors.newFixedThreadPool基础上给LinkedBlockingQueue加一个容量,当队列已经满了,而仍需要添加新的请求会抛出相应异常,我们可以根据异常做相应处理。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10)); //添加容量大小
}
六、ThreadPoolExecutor 参数说明
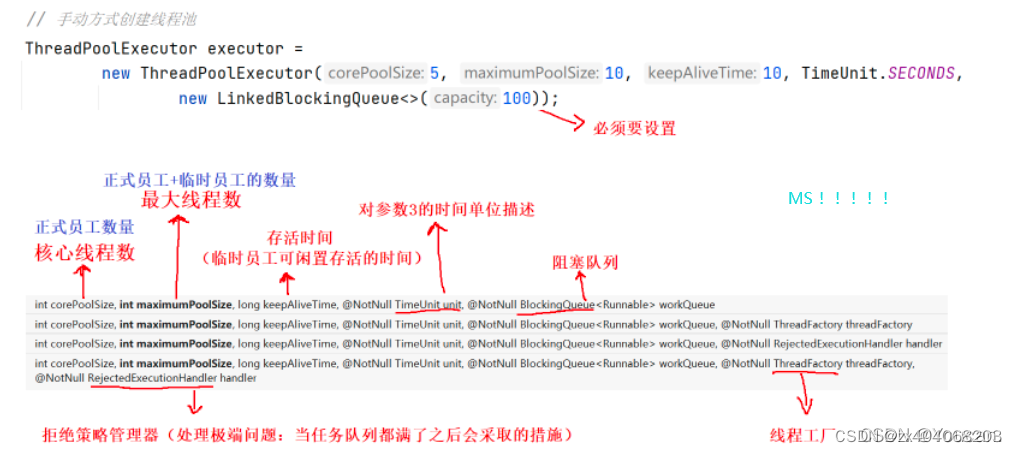
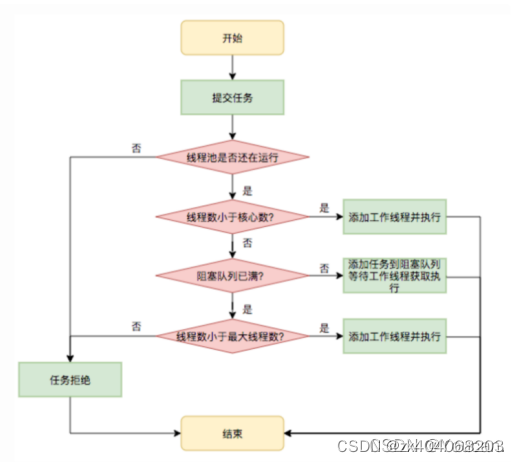
线程池的重要执行节点:
- 当任务来了之后,判断线程池中实际线程数是否小于核心线程数,如果小于就直接创建并执行任务。
- 当实际线程数大于核心线程数(正式员工),他就会判断任务队列是否已满,如果未满就将任务存放队列即可。
- 判断线程池的实际线程数是否大于最大线程数(正式员工 + 临时员工),如果小于最大线程数,直接创建线程执行任务;实际线程数已经等于最大线程数,则会直接执行拒绝策略。
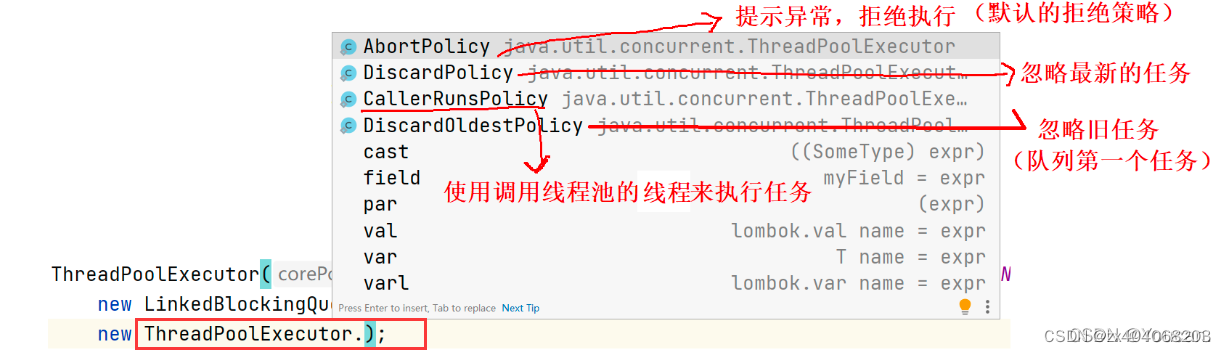
拒绝策略
(4种 JDK 提供的拒绝策略 + 1 种 自定义拒绝策略)
线程状态
-
RUNNING:这个没什么好说的,这是最正常的状态:接受新的任务,处理等待队列中的任务;
SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务; -
STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执⾏任务的线程;
-
TIDYING:所有的任务都销毁了,workCount 为 0。线程池的状态在转换为 TIDYING 状态时,会执 ⾏钩⼦⽅法 terminated();
-
TERMINATED:terminated() ⽅法结束后,线程池的状态就会变成这个。
原文链接:https://blog.csdn.net/m0_48273471/article/details/124171220
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。


![[C语言实现]带你手撕带头循环双链表](https://img-blog.csdnimg.cn/bfff2b7cb93b4989aedf00e4ddb90a5d.png)