问题现象和说明
真实的场景比较复杂,抽象起来可以用下面的图表示,
图示说明
server1 和server2 分别部署keepalived,有一个虚拟IP (VIP).
Router和switch 是路由交换设备,这里用的功能都是一样的,并不做区别.
正常现象
正常情况下,client1 可以访问VIP,server3也可以访问VIP,这里访问采用ping方式,下同。
keepalived 切换情况下,client1 可以访问VIP,server3也可以访问VIP。
异常现象
- server3 可以访问 VIP
- client1 不能访问VIP,不做任何修改,大约20分钟后,client1又可以访问VIP了
- 异常前的keeplived日志(/var/log/message)有脑裂发生。
背景知识,Keepalived通过VRRP实现高可用性
keepalived基础入门可以参考一文带你浅入浅出Keepalived
VRRP协议了解可以VRRP简单概述
https://www.cnblogs.com/patrick-yeh/p/14428508.html
核心参考keepalived官网
问题复现
家里正好有几个ARM板子,一个TP-link交换机(二层),一个华为AR路由器,一台服务器,可以实现如下的场景搭建。模拟脑裂到恢复的过程
背景说明
- 抓包主要在server3上进行
- 路由器Router的wan口配置的IP是192.168.1.3
- 路由器Router的lan口分别接入server1,server2,和server3
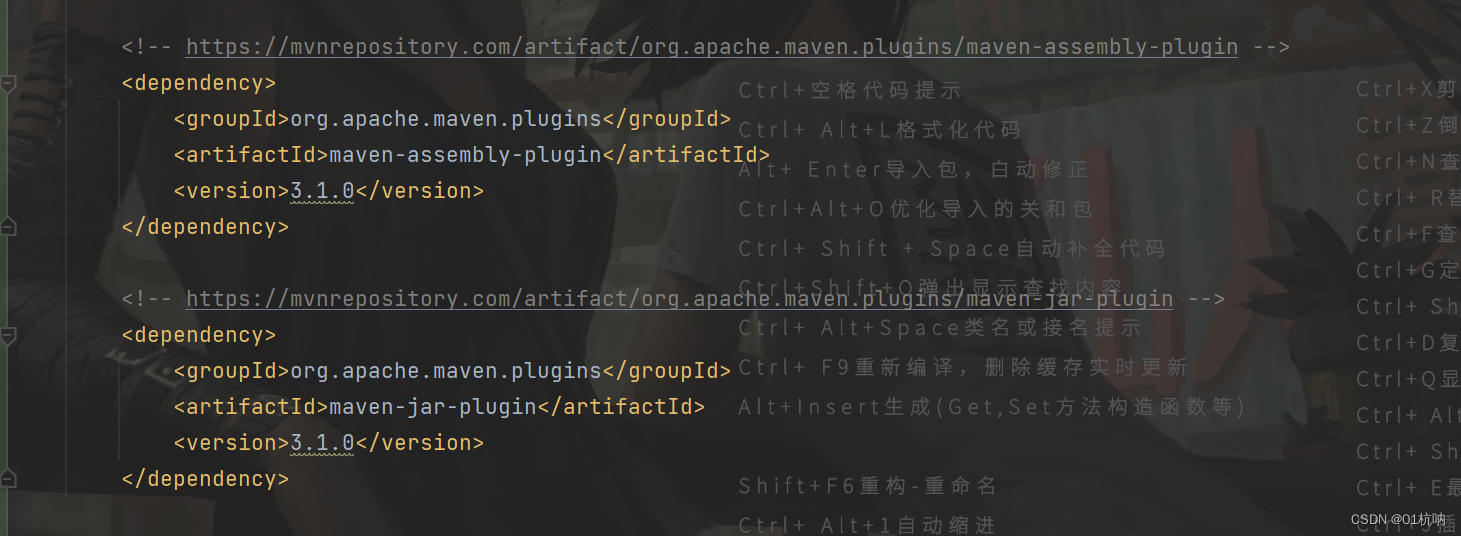
- server1 和server2 的keepalived配置如下
server1 上keepalived.conf
! Configuration File for keepalived
global_defs {
router_id swaram02
script_user root
}
vrrp_script chk_http_port {
script "/etc/keepalived/check.sh"
interval 10
user root
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
nopreempt #非抢占模式
virtual_router_id 31 #通过vid参数识别同一个虚拟路由器,所以两者一定要一致
priority 100
advert_int 3 #通告时间
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.31/26
}
track_script {
chk_http_port
}
notify_master "/etc/keepalived/arp1.sh" #当切换到MASTER时,运行的脚本
}
server2上keepalived.conf配置
! Configuration File for keepalived
global_defs {
router_id swaram02
script_user root
}
vrrp_script chk_http_port {
script "/etc/keepalived/check.sh"
interval 10
user root
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
nopreempt #非抢占模式
virtual_router_id 31 #通过vid参数识别同一个虚拟路由器,所以两者一定要一致
priority 90
advert_int 3 # 通告周期
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.31/26
}
track_script {
chk_http_port
}
notify_master "/etc/keepalived/arp1.sh" #当切换到MASTER时,运行的脚本
}
其中用到两个脚本,一个是check,检查后端程序,没有写,直接使用ls代替脚本内容
还有一个arp1.sh的脚本
#!/bin/bash
VIP=172.16.22.31
GATEWAY=172.16.22.1
/sbin/arping -I eth0 -c 5 -s $VIP $GATEWAY &>/dev/null
正常情况下在server3上抓包,可以看到只有maser节点146发的vrrp报文
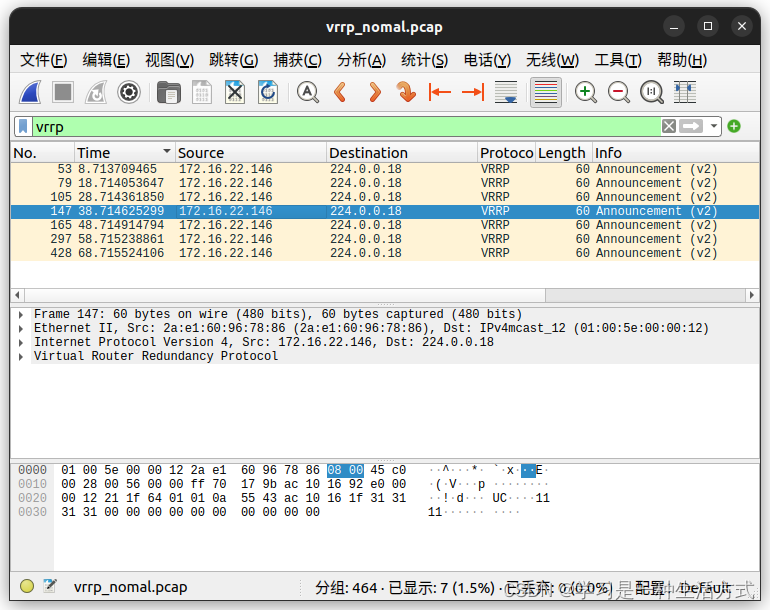
client1 保证正常情况下的通信
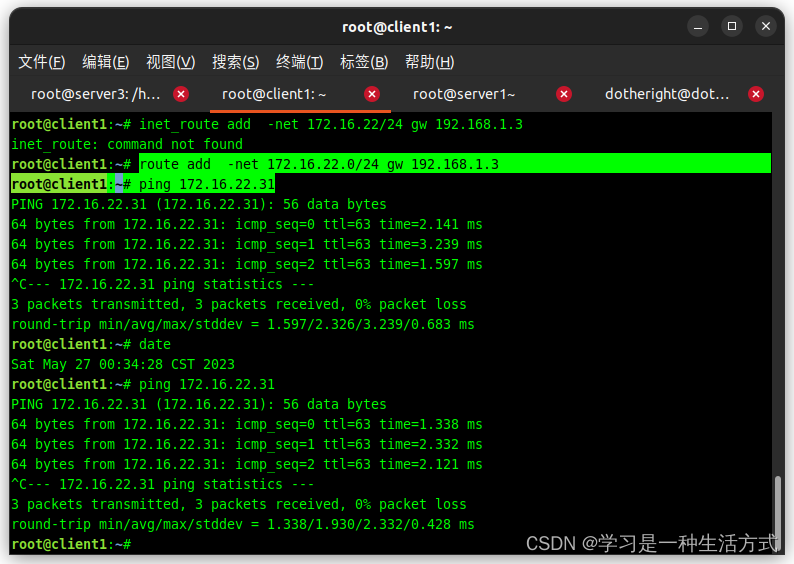
server3保证正常情况下的通信

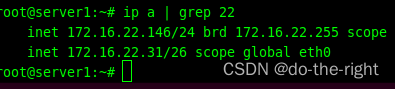
server1上IP 和虚拟IP情况

server2上的IP和虚拟IP情况

模拟故障
-
在server2上配置不接收VRRP报文,等待30秒中,此时可以查看keepalived变成master(此时发生了脑裂) ,并和172.16.22.31绑定
iptables -I INPUT -p vrrp -j REJECT执行丢弃vrrp丢弃的报文节点并没有选择
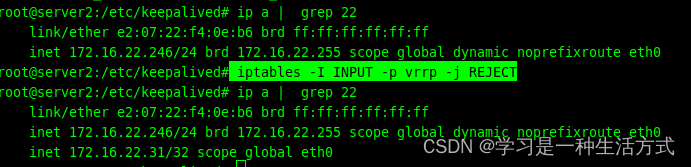
此时从client1和server3上都可以ping 通172.16.22.31 -
删除 不接受vrrp的规则(iptables -F) 系统脑裂
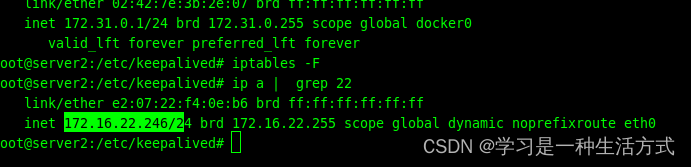
脑裂的直观体现就是两个真实的IP都和虚拟IP绑定了

-
脑裂恢复之后就从 client1 不能ping 通虚拟IP了,server3可以ping通
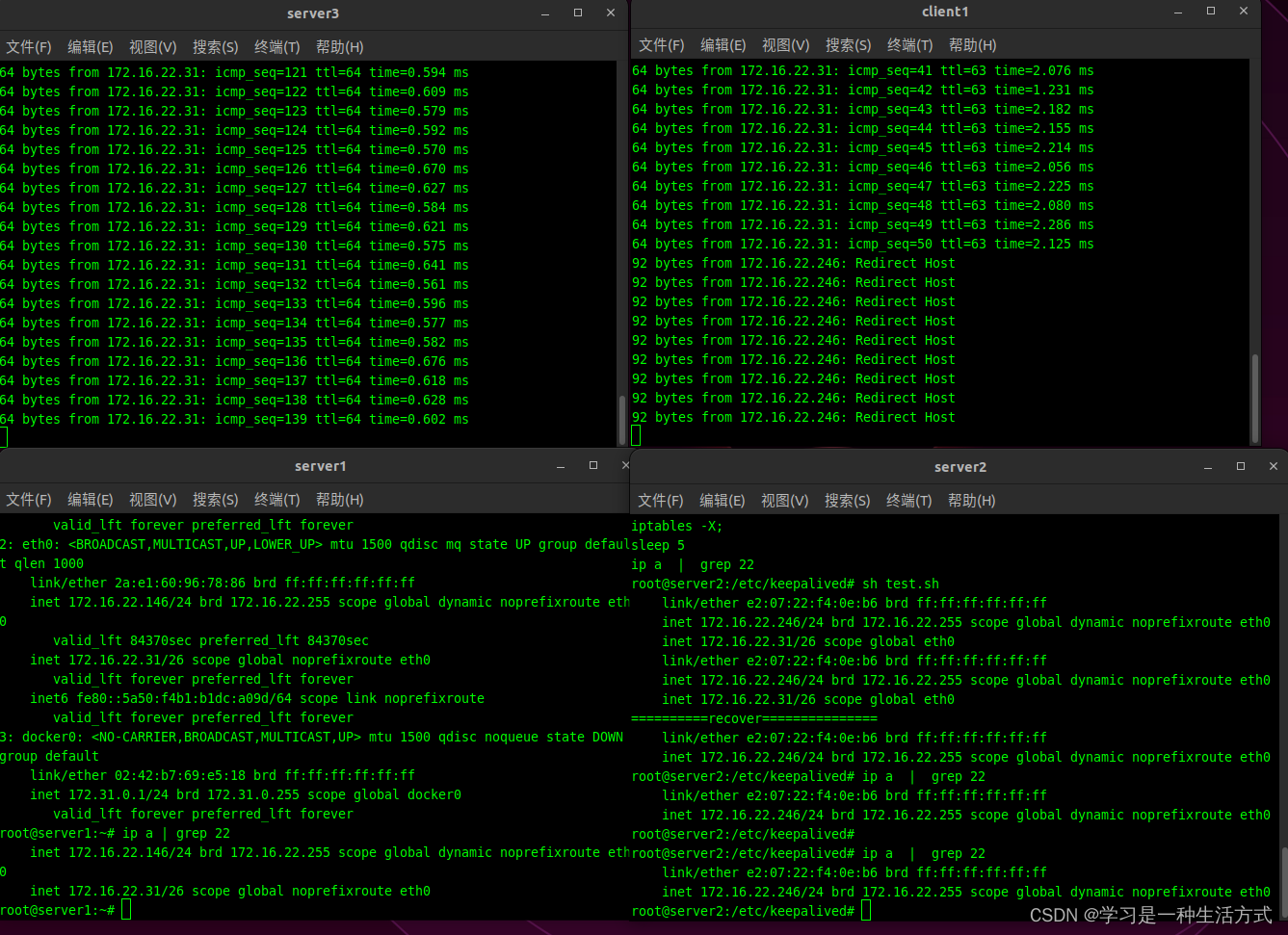
故障复现成功。 -
故障模拟脚本—test.sh
丢弃keepalived 之间确定
iptables -A INPUT -p vrrp -j REJECT;
iptables -A OUTPUT -p vrrp -j REJECT;
sleep 1 ;
ip a | grep 22;
sleep 12;
ip a | grep 22;
echo "==========recover==============="
iptables -F;
iptables -X;
sleep 5
ip a | grep 22
必现条件
上面的模拟如果不是在特定状态,特定节点上的操作不一定会成功
初始状态下,keepalived的vip绑定节点必须是优先级高的那个节点
由于非keepalived设置的是非抢占模式,初始状态下,VIP也可以是优先级地的节点绑定,这种情况下脑裂恢复就不会中断。测试效果如下
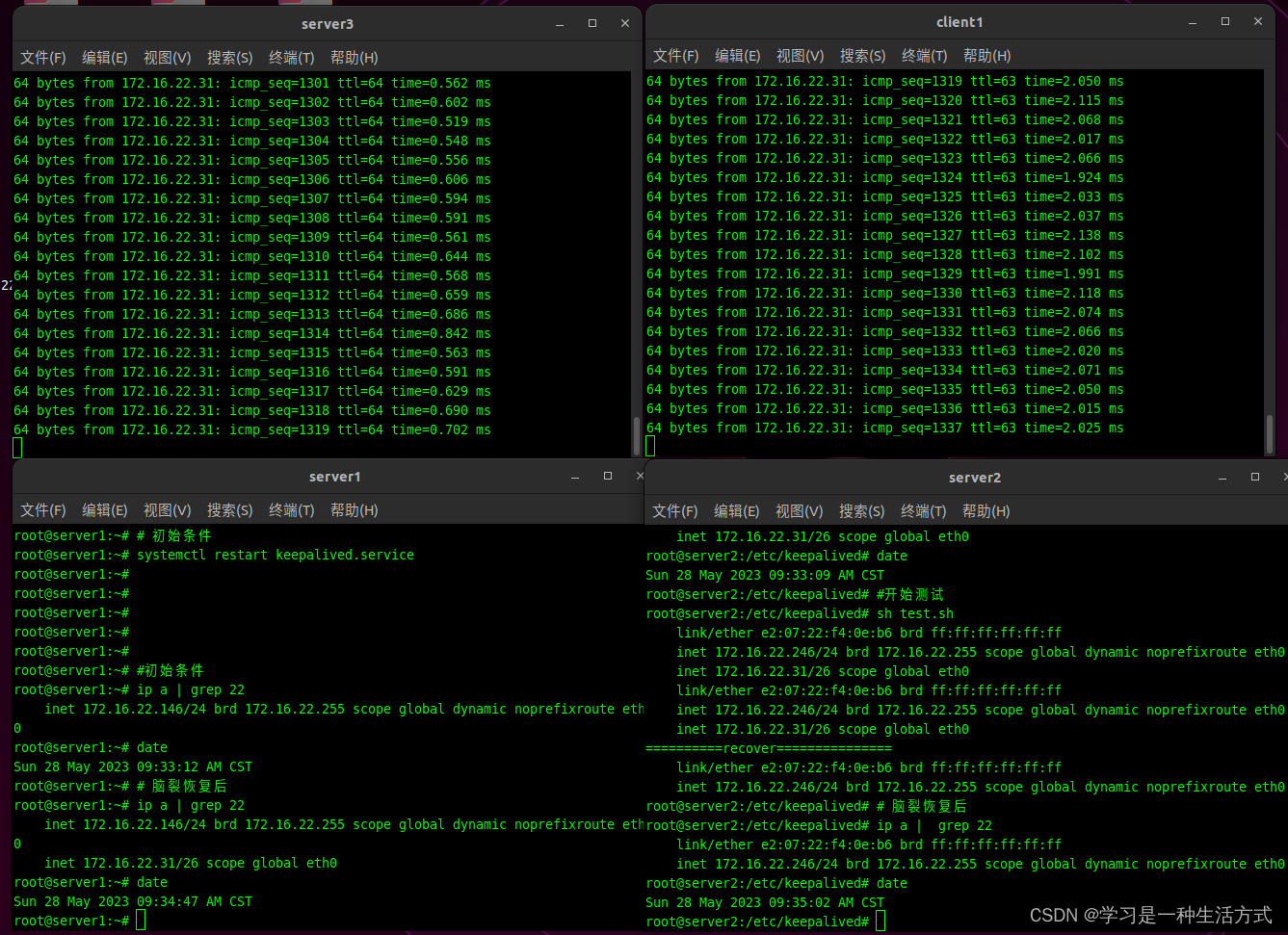
问题分析
问题定界
- server3 可以访问,说明VIP所在的节点至少是在提供服务的。
- client1 不能访问,说明这个访问说明这个异常是和网络有关。
client1 和server3 访问的差异
- server3 和VIP是在同一网段,根据二三层转发可以知, server3 是通过MAC学习得知VIP(172.16.22.31的所在),所以一直访问没有问题。
- client1和VIP不在同一网段,会经过Route,此时在client1上ping server1 或者server2 也是正常的,有问题的只是虚拟IP 的访问
背景知识二三层转发原理
- 二层转发过程:IP和掩码与,属于同一网段,学习目的MAC,根据目的MAC转发。
- 三层转发过程:IP和掩码与,不属于同一网段,走三层转发,给下跳路由继续转发。
参考二三层转发原理介绍, 网络之二三层转发
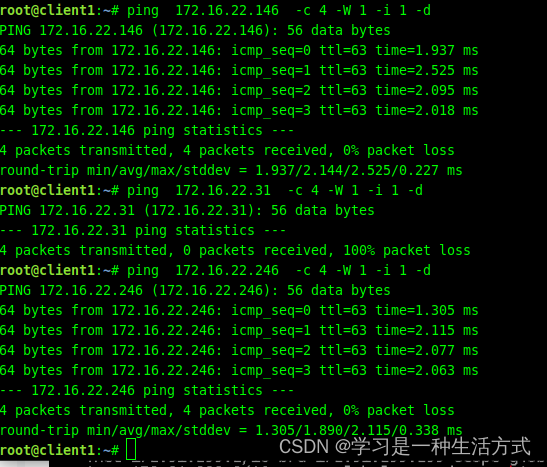
- client1到 VIP不通,整条链路不通的地方是在Router和vip之间,验证过程如下:
从client1不能ping 通虚拟IP(172.168.22.31),client1可以ping通 Router,Router 不能ping 通 VIP,可以ping通 server1和server2
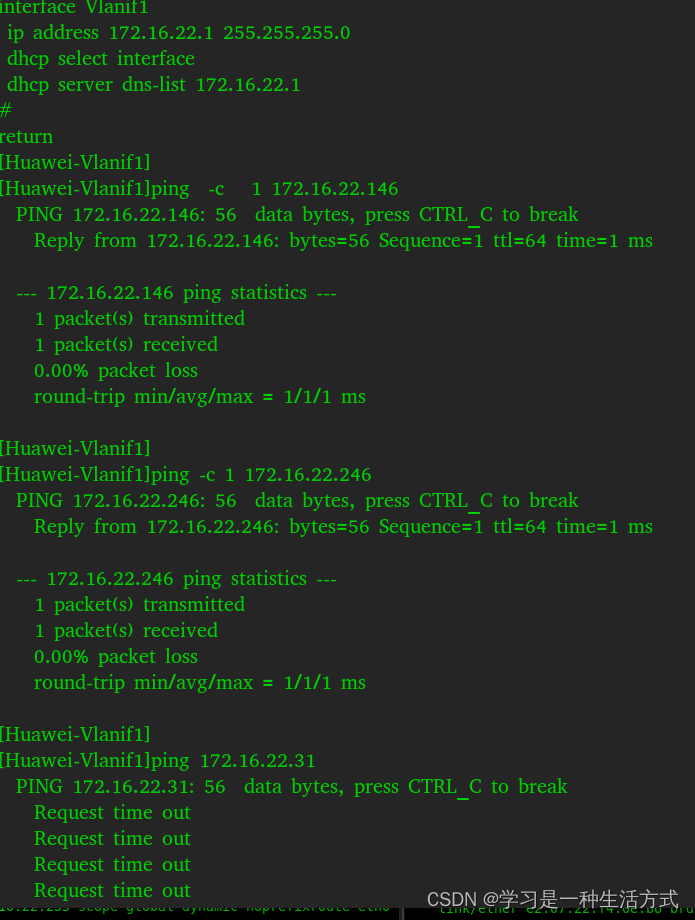
Router为什么不能访问 VIP?
对于Router来书访问VIP,和PC是一样的,先比较 VIP和是否和接口上的某一网段是否相同,和VLAN1上面的IP网段相同,走二层转发,二层转发需要目的MAC,先查自己有没有已经学习此IP对应的MAC,有则把这个MAC作为目的MAC封装成报文发送出去,如果没有则发送ARP请求,学习此VIP对应的MAC,然后记录到ARP表项中,同上把这个VIP对应的MAC,封装成报文发送出去。所以很有必要看一下路由器的MAC表项。
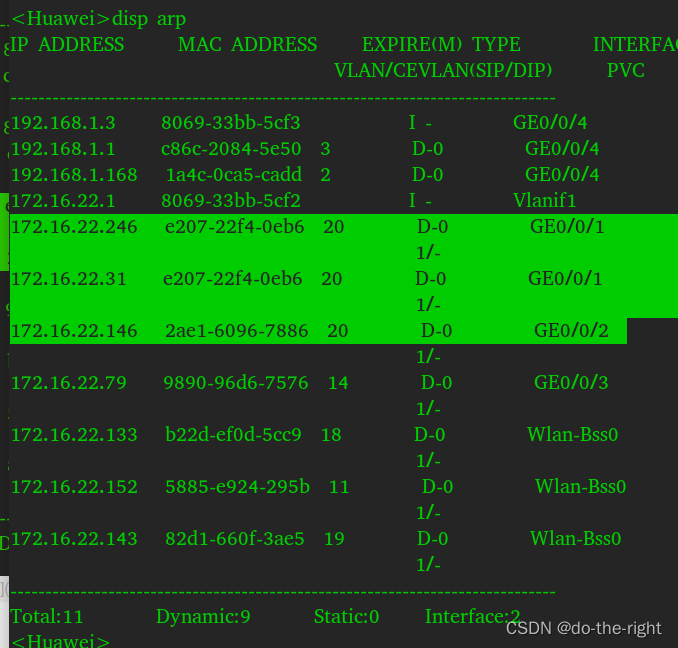
- keepalived脑裂前
MAC表项如下: 虚拟IP 172.16.22.31 对应的MAC地址和 172.16.22.146保持一直

server1 的IP
server2的IP

路由器中VIP(172.16.22.31)对应的MAC是2ae1-6096-7886 ,和实际的绑定关系一致,所以从client1 可以正常ping通
- keepalived脑裂中
路由器的AR表项如下: VIP(172.16.22.31)对应的MAC地址是和server2的地址172.16.22.246的MAC一致,此时server2对应也有172.16.22.31的虚拟IP,所以此时也是可以ping通的。
为什么ARP的表项会刷新,请看server2的分析。
server1 的IP
server2的IP
脑裂后server2的状态由backup变成master,这时候会发送免费ARP报文(gratuitous ARP ,对于IPV6是发送NA message),从配置中看到还会通过脚本方式刷新网关,其实这两种方式都可以刷新网关的ARP表项,最终的效果就是ARP表项被刷新,和server2的MAC地址保持一致
可以参考keepalived官网关于vrrp_min_garp 参数的描述
# By default keepalived sends 5 gratuitions ARP/NA messages at a
# time, and after transitioning to MASTER sends a second block of
# 5 messages 5 seconds later.
# With modern switches this is unnecessary, so setting vrrp_min_garp
# causes only one ARP/NA message to be sent, with no repeat 5 seconds
# later.
vrrp_min_garp
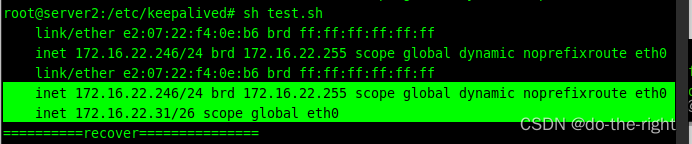
- keepalived脑裂恢复后
路由器中的ARP表项,并未刷新,VIP(172.16.22.31)还是和server2 (172.16.22.246)的MAC 一致。
但是此时 server2 的keepalived状态由master变成了backup,这个过程中会删除掉VIP(172.16.22.31)。
路由器发送,目的IP地址是172.16.22.31,MAC地址是e207-22f4-0eb6的报文后,server2收到了,发现和自己的IP地址不一致,丢弃了报文。所以出现了脑裂恢复后client1不能访问VIP的现象。
server1 的IP
server2的IP

解决方案
手工方案
1. 手工恢复方案1----让节点去适配路由交换设备
由于异常来于ARP表项没有刷新,重启keepalived,就会触发VIP飘逸。
在模拟的场景中,重启server1中的keepalived就可以恢复。
实际过程中有可以使用两个VIP,所以两个节点都要重启。
2. 手工恢复方案2—刷新路由交换设备的ARP表项
使用arping工具,在优先级高节点上面发送免费ARP,具体命令如下
arping -I [IP设备名称] -c [个数] -U [虚拟机IP]
实验环境中的实例
`/sbin/arping -I eth0 -c 5 -U 172.16.22.31`
基础方案
方案实现
在 keepalived的全局配置里面添加 vrrp_garp_master_refresh 20
global_defs {
router_id swaram02
script_user root
vrrp_garp_master_refresh 20
}
两个节点都添加,重启keepalived.
此方案的效果是在设定的时间范围内,可以 保证client1可以访问VIP
方案说明
vrrp_garp_master_refresh 是指 当节点变成master 节点后,循环 发送免费ARP报文,此报文可以刷新网关的ARP表项,虽然keep脑裂的时候,两个节点都会刷新ARP表项,等脑裂结束后,由于一个节点变成了backup,只有真正的master才会刷新ARP表项。
方案优点
- 自动刷新
- 配置简单
方案缺点
- 刷新频率不能太高,因为这是在同一网段内发的广播报文
- 会有可以明显感知的中断
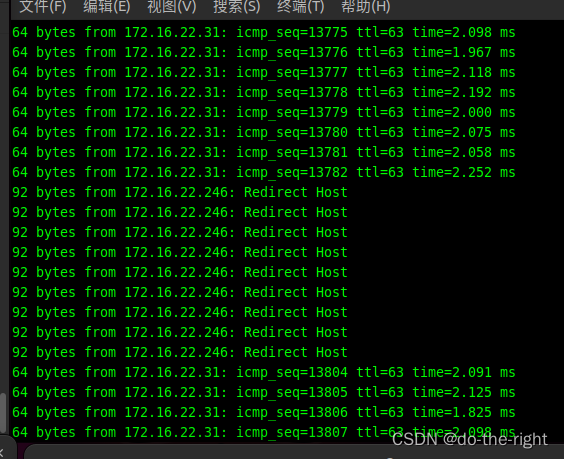
方案效果
这次实验有9秒中中断,正常是在 0-20秒之间
进阶方案
方案实现
在基础方案基础上
- 仅且仅在优先级更高的节点上,添加如下配置
notify_stop “/etc/keepalived/arp1.sh”
- 同时在两个keepalived 节点上
- 在全局区域增加如下配置
vrrp_garp_master_refresh 20
vrrp_garp_master_repeat 2- 删除 notify_master的配置
在配置中的位置
master节点:
root@server1:/etc/keepalived# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id swaram02
script_user root
vrrp_garp_master_refresh 20
vrrp_garp_master_repeat 2
}
vrrp_script chk_http_port {
script "/etc/keepalived/check.sh"
interval 10
user root
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
nopreempt
virtual_router_id 31
priority 100
advert_int 3
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.31/26
}
track_script {
chk_http_port
}
notify_stop "/etc/keepalived/arp1.sh" #当vrrp 停止的时候,执行通知脚本
}
backup 节点
global_defs {
router_id swaram02
script_user root
vrrp_garp_master_refresh 20
vrrp_garp_master_repeat 2
}
vrrp_script chk_http_port {
script "/etc/keepalived/check.sh"
interval 10
user root
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
nopreempt
virtual_router_id 31
priority 90
advert_int 3
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.31/26
}
track_script {
chk_http_port
}
#debug 1
#notify_master "/etc/keepalived/arp1.sh" #当切换到MASTER时,运行的脚本
}
修改完配置之后,分别重启两个节点上的keepalived服务
方案说明
脑裂之后恢复的master节点一定是优先级更高的那一个
所以在脑裂之后,优先级更高的那一个去刷新ARP表项,恢复的时间会更短,甚至不会中断。
vrrp_garp_master_repeat 2 这个参数的含义是backup节点变成master节点之后,发几个免费ARP报文,默认是5个,因为notify_stop 也会去发,这里设置比 notify_stop中少三个,目的是让notify_stop中发送的免费ARP报文最终生效。
方案优点
- 中断时间在5秒内,网络条件好的情况下,无中断
- 实现相对简单
方案缺点
- 概率性的还是会有小于5秒的中断
方案效果
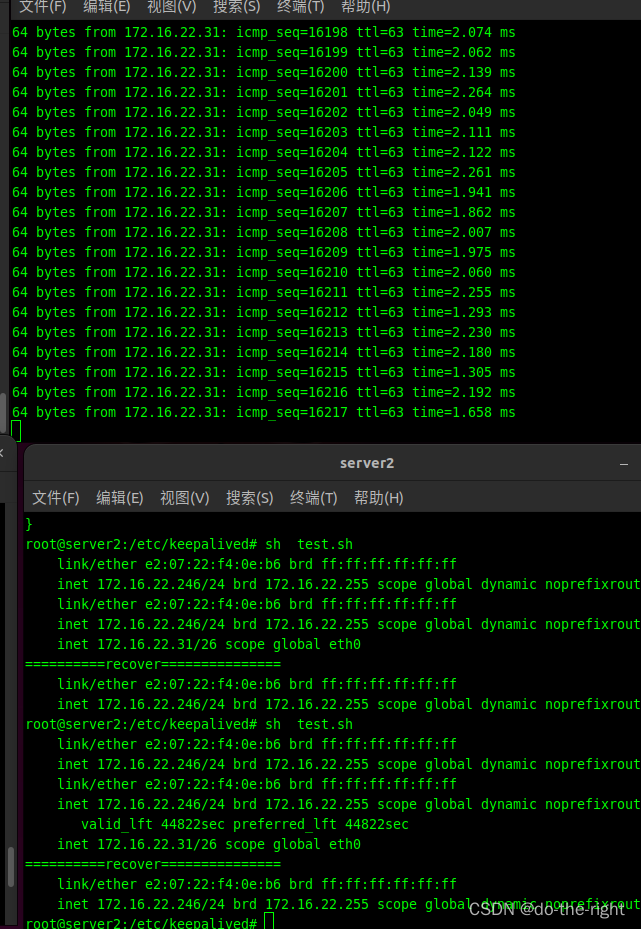
网络条件差的情况下,还是大概率会中断两秒
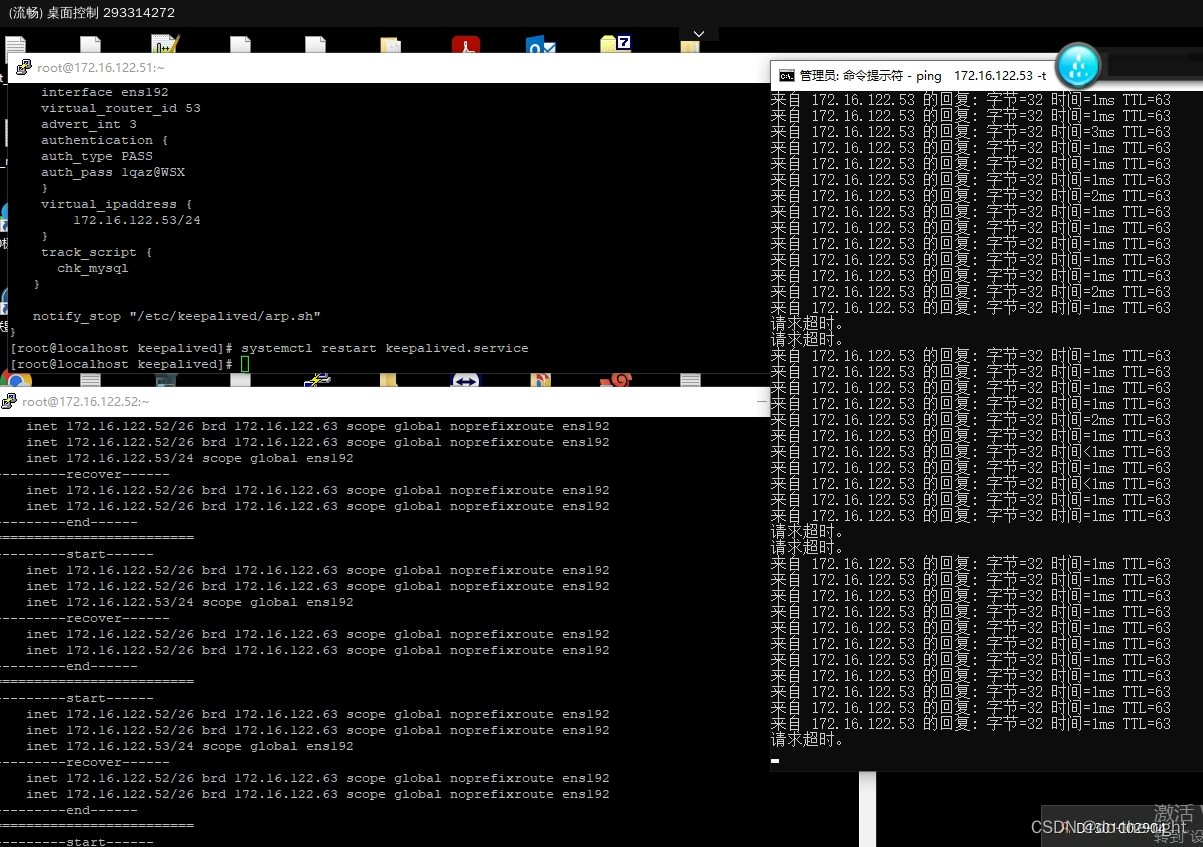
系统方案
方案实现
在进阶方案基础上,修改路由器或者交换机上的设置ARP表项固化,确认后才更新ARP表项:
对于华为系列的路由器或者交换机是:
arp anti-attack entry-check send-ack enable
un arp anti-attack entry-check enable
对于H3C 系列的交换机和路由器是:
arp active-ack enable
其他系列的交换和路由器待补充。
方案说明
路由器或者交换机中有防止ARP表项被攻击者修改的功能,keepalived脑裂的情况和攻击类似,可以使能表项确认的开关,确认原节点不可访问后再更新表项,这样就可以防止脑裂时候ARP表项被刷新。
方案的优点
可以防止脑裂的时候出现不可访问的中断。
方案的劣势
- 如果开始的ARP表是错误的,刷新就要等到老化时间到了。
- 需要交换机或者路由器支持,不同厂商的配置不同,而且不一定都实现了此功能。
方案效果
最终效果和进阶方案不中断的情况一致。
附属说明
- 脑裂引起的问题首先要排除脑裂发生的原因,除了网络异常抖动,之外的其他常见原因,同事已经排除,所以这里并未赘述。
- 脑裂的网络原因目前只是猜测,没有实锤,根据真实的网络拓扑如下,
这个概率很低一年才出现一次,根据网络拓扑,如果出现宿主机上的虚拟机不走同一个交互机,经过其他网络设置,tll值就会小于255.
按照RFC 2338的规定,系统对收到的VRRP报文的TTL值进行检测,如果TTL值不等于255,则丢弃这个报文,并打印出VRRP报文错误的日志信息。
华为系列可以配置不丢弃 vrrp check ttl disable 参考手册来自:https://support.huawei.com/enterprise/zh/doc/EDOC1000017951/217b12b7






![[答疑]UMLChina的Logo是不是不对劲](https://img-blog.csdnimg.cn/img_convert/9c6838b348c1d86190592a0412cb8b59.png)
