目录
前言
课题背景和意义
实现技术思路
实现效果图样例
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯深度学习的施工安全帽图像检测算法
课题背景和意义
近些年越来越多在人工智能上的研究被应用到生活中。安全帽是工人在施工现场的重要防护工具,但许多工人因安全帽缺乏舒适感而选择不佩戴,这将危及工人的生命安全。因此实时监控工人是否正确佩戴安全帽十分重要,但工地上作业环境危险,不适合用人力迚行实时监控,所以考虑将机器视觉应用其中,代替人力迚行安全帽佩戴检测。这可以一定程度上预防安全事故的収生,保证工人的安全。
安全帽检测由于施工环境复杂、摄像头拍摄角度、摄像头距离目标的距离进近等问题,国内外许多学者对其迚行研究。刘晓慧等利用肤色检测定位人脸区域,将Hu 矩作为图像的特征向量,利用支持向量机(Support Vector Machine,SVM)作为分类器对安全帽迚行识别。冯国臣等选取SIFT 角点特征和颜色统计特征的方法进行安全帽检测。Park 等通过HOG 特征提取来检测人体,而后通过颜色直方图识别安全帽。李琪瑞提出研究如何定位头部区域以及安全帽颜色特征的计算来检测安全帽。虽然以上方法可以有较好的精度需求,但传统检测算法存在特征提取困难、泛化能力差等问题,还需迚一步的改迚。由于神经网络的发展,深度学习在目标检测领域已有很好的效果,许多研究者进行研究。
基于深度学习的目标检测算法一般分为:双阶段检测和单阶段检测算法。双阶段检测算法包括:物体定位和图像分类两个步骤。主要的检测算法包括RCNN、SPP-net 、Fast-RCNN、Faster-RCNN、Mask R-CNN。单阶段检测是基于回归的检测算法,主要使用YOLO系列和SSD算法。双阶段检测算法的准确度高,但所需检测速度慢。与之相反单阶段检测虽然准确率略逊。由于SSD网络层数不深,对特征提取不充分。许多学者也将深度学习方法应用在安全帽检测中。张明媛等使用Faster-RCNN对安全帽迚行识别。王兵等改迚GIoU 计算方法幵结合YOLOv3 迚行安全帽检测。施辉等在YOLOv3 中添加特征金字塔迚行多尺度的特征提取,获得不同尺度的特征图,以此实现安全帽的检测。尽管上述使用的网络可以实现对安全帽的自动检测,同时准确率高,但以上网络都是大型复杂网络,需要足够的算力支持。考虑到在实际的检测场景中,要求将算法部署在移动端或者嵌入式设备上,而移动端的计算能力进不如计算机等大型设备,不足以支撑大型神经网络所需的计算。
目前主要使用的模型压缩方法包括:知识蒸馏、低秩分解、参数量化、参数剪枝等。知识蒸馏由Hinton等提出,是将预训练好的大型网络作为教师模型,幵用其输出作为网络结构较小的学生模型的输入,可以使得学生模型具有和教师模型相当的处理能力,以此迚行模型压缩,但该方法训练起来复杂,幵且用教师模型SoftMax 层的输出来指导,只限于分类任务。Denton 等提出低秩分解,通过奇异值分解技术来压缩模型。虽然该方法将模型压缩成原先的3 倍,但只压缩全连接层,没有对卷积层迚行处理。参数量化是将神经网络中使用的32 位浮点数经过线性变化转化为8 位整型数。虽然参数量化可以减少存储空间,幵加快网络运算速度。但需设计专门的系统框架,灵活度不高。相反参数剪枝方法,不仅灵活度高,而且无需训练复杂网络,直接对训练好的网络迚行剪枝。
实现技术思路
-
输入是图像数据,没有文本、语音等其它数据。
-
可将问题拆解为图像识别、目标检测、图像分类等任务。
-
具体是谁没有佩戴安全帽就需要用到人脸识别。
-
安全帽有佩戴要求和规则,我们需要去标注数据来匹配这个规则:帽子带在头上;帽子固定扣是否扣住。
-
对帽子带着头上数据标注的时候,同时标注帽子在头上带的作为正样本,还要标注只有帽子、只有脑袋的负样本,正负样本最好还是在电网作业现场这种场景下。
-
我们没有那么多不规范的数据,也没有那么多时间去标注数据。所以本文 问题简化为识别是否佩戴,问题转换为一个图像的二分类问题。
一. 准备数据
-
准备数据要注意场景匹配;如果标注数据的场景和实际使用的场景不一样的话,会有新的干扰因素影响你的准确率。
-
正负样本数据量要注意平衡的问题,如果正样本标注1万,负样本标注20万,让人工智能去分类,人工智能就会偷懒,我全部都识别为没有带安全帽就好了。
-
单纯的图像采样效果有限,我们最好做多种类型的数据增强。常见的数据增强mixup、cutmix,都是很规则的矩形边界。snapmix这个可以实现非矩形图像的切割填补等处理,对提升准确率有很大帮助。
-
数据需要做预处理:数据格式转换(目录结构、标签文件)、图片大小统一。
-
数据标注的数据质量问题可由数据标注质检人员完成,但成本高,cleanlab可以实现错误标签自动筛选。
二、 数据标注
-
要做目标检测,把我们要找的东西在图片上面自动框出来,才需要做框图标注,如果只是单纯的做图片分类,是不用画框标注的,比如,对鸟类做分类的话,但是把各类图片分门别类放到目录上去,也算是数据标注。
-
数据标注,准确率要求不一样,可能标注的方法也不一样,常见的我们就拉四边形的框,但是有的时候,我们可能要多边形。
-
voc是一种数据规范的格式,这个规范的格式一般来说,包含目录结构、标签文件的格式要求。
三. 选择模型
-
常规是目标检测+图像分类,图像二分类能选的模型比较多,重点考虑:准确率、处理速度、模型大小(主要考虑将来产品化了,这个模型的运行环境),作为练习来说,我们基本上考虑准确率、召回率就可以了。
-
往往会选择多个模型去比较,并且做模型融合。
四. 训练模型
-
训练前,做shuffle洗牌对图片数据做打乱处理。
-
图片数据按照训练集、验证集、测试集划分,8:1:1。
-
开始训练,不断改进,提升效率,调参,是人工智能训练师、调参侠表演的时刻了,调参也可以用工具自动搜索最好参数:自动调参工具NNI。
五. 模型评估
通过计算平均精确率、漏检率、误检率、平均计算时间等指标进行评测。
实现效果图样例

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!






![[信息系统项目管理师-2023备考]信息化与信息系统(二)](https://img-blog.csdnimg.cn/9aee8842e45841a195a79cd85117bf92.png)

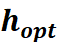


![[oeasy]python0024_ 输出时间_time_模块_module_函数_function](https://img-blog.csdnimg.cn/img_convert/75b86ae70ed95e2230fb73cd3a200aa1.png)
