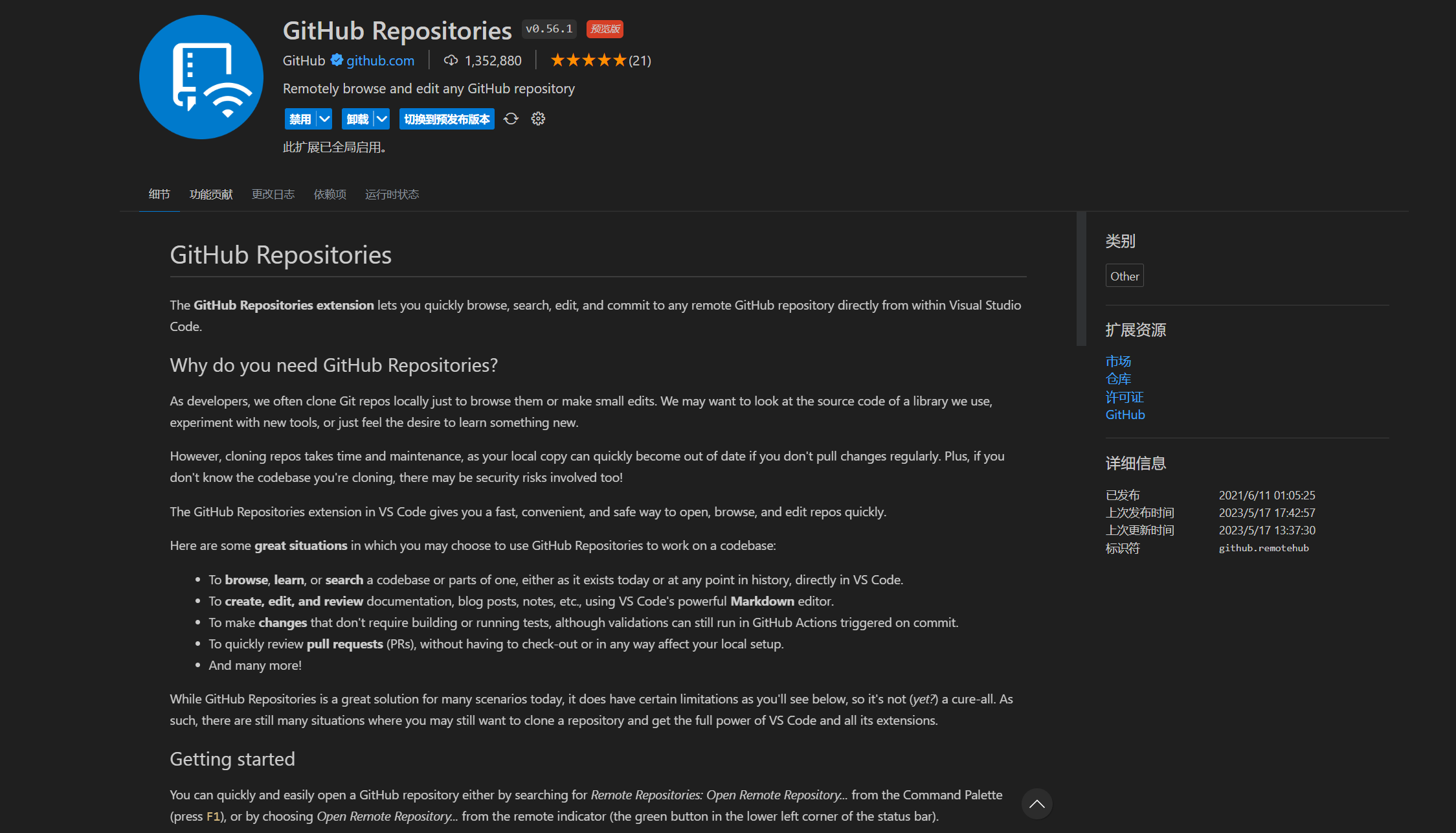
那么好了好了,宝子们,今天给大家介绍一下 “数据在内存中储存” 的来龙去脉,来吧,开始整活!⛳️
一、数据类型的介绍
(1)整型和浮点型:
 (2)其他类型:
(2)其他类型:



二、数据在内存中的储存顺序(大端 小端)
(1)引入字节序:
字节序 是以 字节 为单位讨论内存的储存顺序的
什么大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位
,
,保存在内存的高地址中。
注意:这里的 低位 和 高位 是指:个十百千万 的低位和高位
(2)如何判断:
那么接下来以我的编译器vs2022,给大家来示范判断一下如何判断是大端储存模式还是小端储存模式?
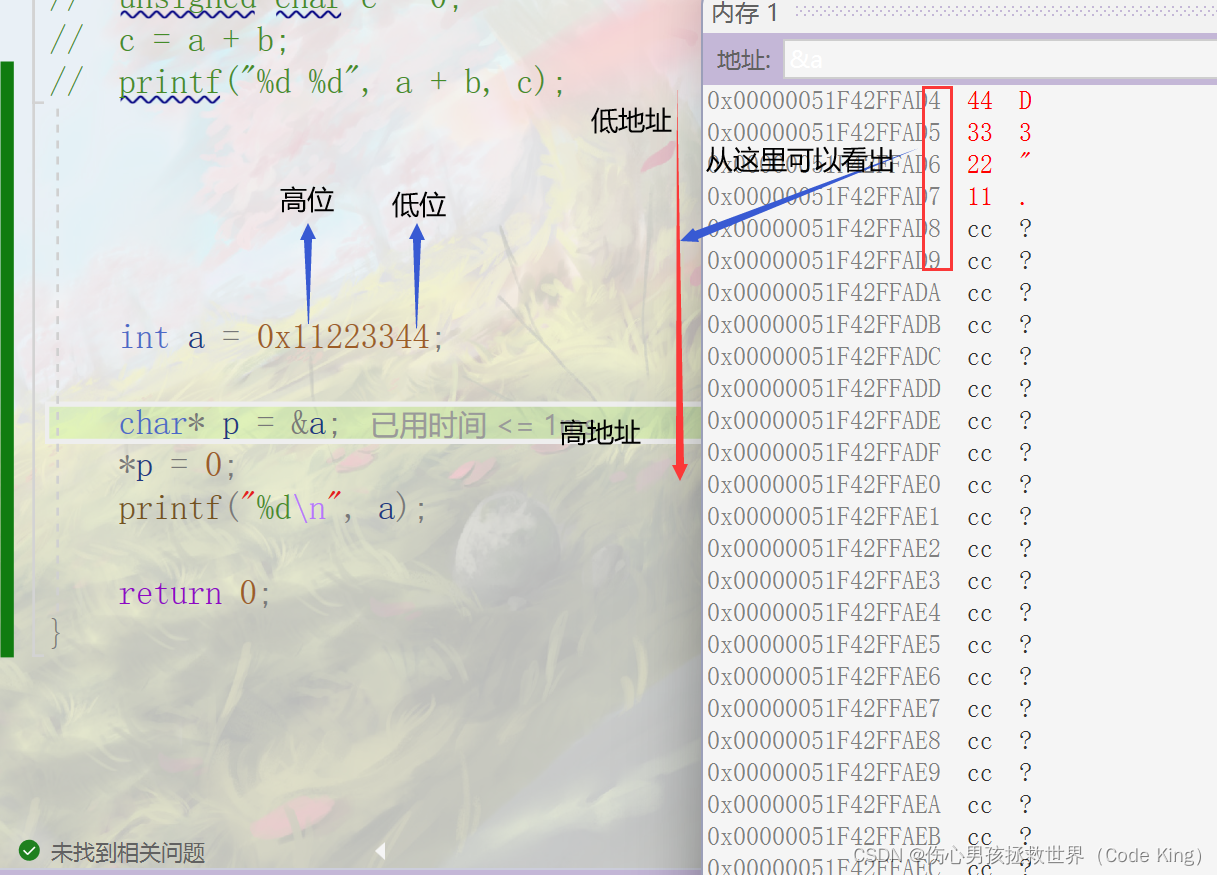
由此可以看出我们的低位存放的是低地址,高位存放的是高地址,所以说在此种情况下,这种储存模式是小端储存
三、通过例题来介绍:数据在内存中是如何存储的
1.(解析在代码中)
#include <stdio.h>
int main()
{
char a = -1;
//10000000000000000000000000000001(原码来写出来),因为你输入的是-1,是整数,所以说是4个字节,要写32个比特位。
//11111111111111111111111111111110(反码)
//11111111111111111111111111111111(这是补码),又因为这里a变量的数据类型是char只能存放1个字节,8个比特位,所以说这里需要从低位向高位进行截断,
//11111111 (a)截断后
//11111111111111111111111111111111(因为最终的结果是以十进制的形式打印有符号的整数,所以说这里需要进行整形提升)依然按照整形提升的规则来。(补码)
//11111111111111111111111111111110(反码)-1啦
//10000000000000000000000000000001 (原码)所以最终的结果:-1,是这样来的
signed char b = -1;
//11111111111111111111111111111111
//11111111 -b
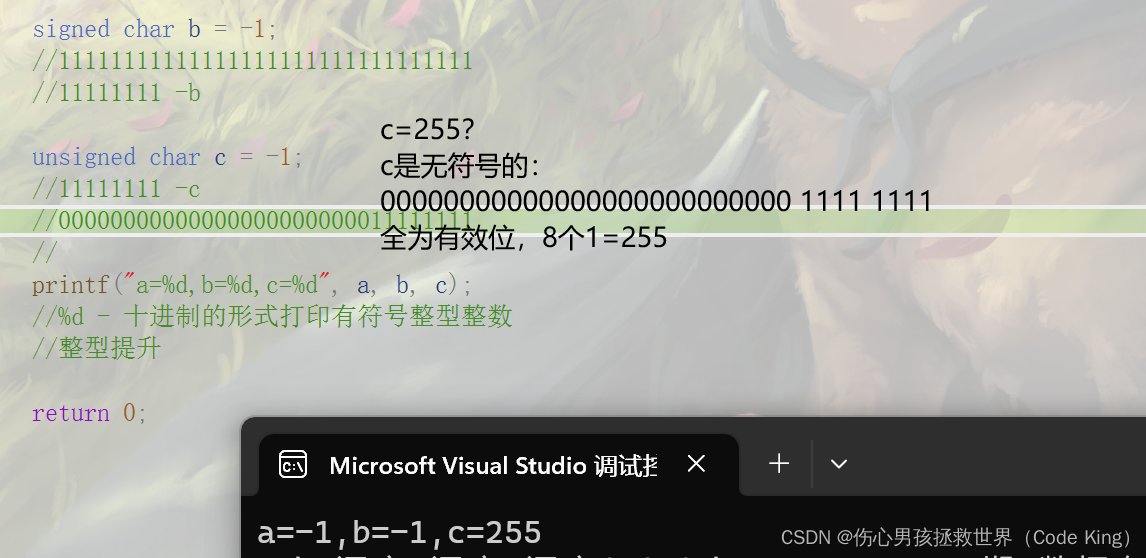
unsigned char c = -1;
//11111111 -c
//00000000000000000000000011111111
//
printf("a=%d,b=%d,c=%d", a, b, c);
//%d - 十进制的形式打印有符号整型整数
//整型提升
return 0;
}
c=255的解释:
2.
#include <stdio.h>
int main()
{
char a = -128;
//-128
//10000000000000000000000010000000(原码)
//11111111111111111111111101111111(反码)
//11111111111111111111111110000000(补码)
//-128的补码
//10000000(截断后)
//11111111111111111111111110000000(整形提升后)--最终结果
//
printf("%u\n", a);
return 0;
}3.
#include <windows.h>
int main()
{
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n", i);
Sleep(1000);//单位是毫秒
}
return 0;
}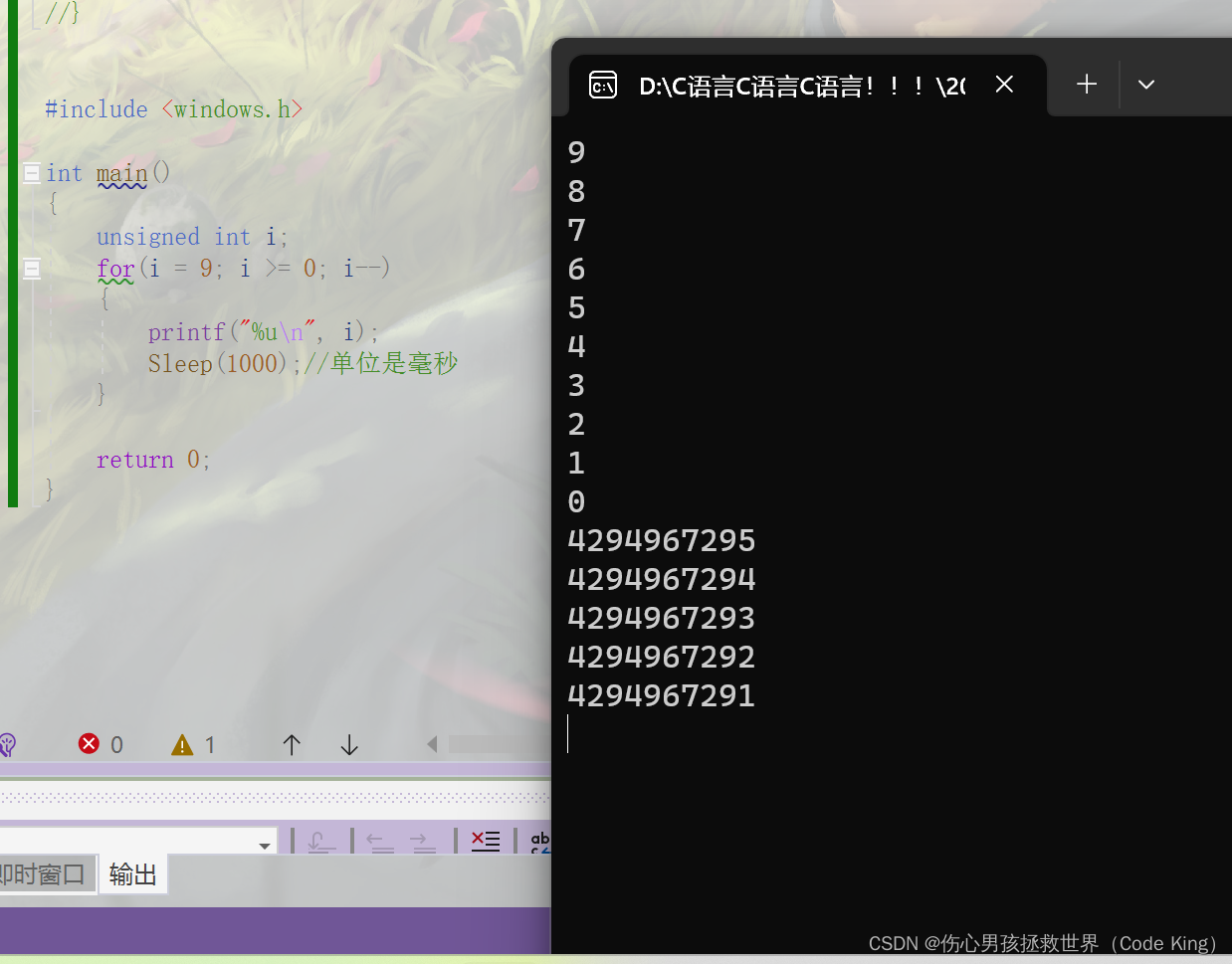
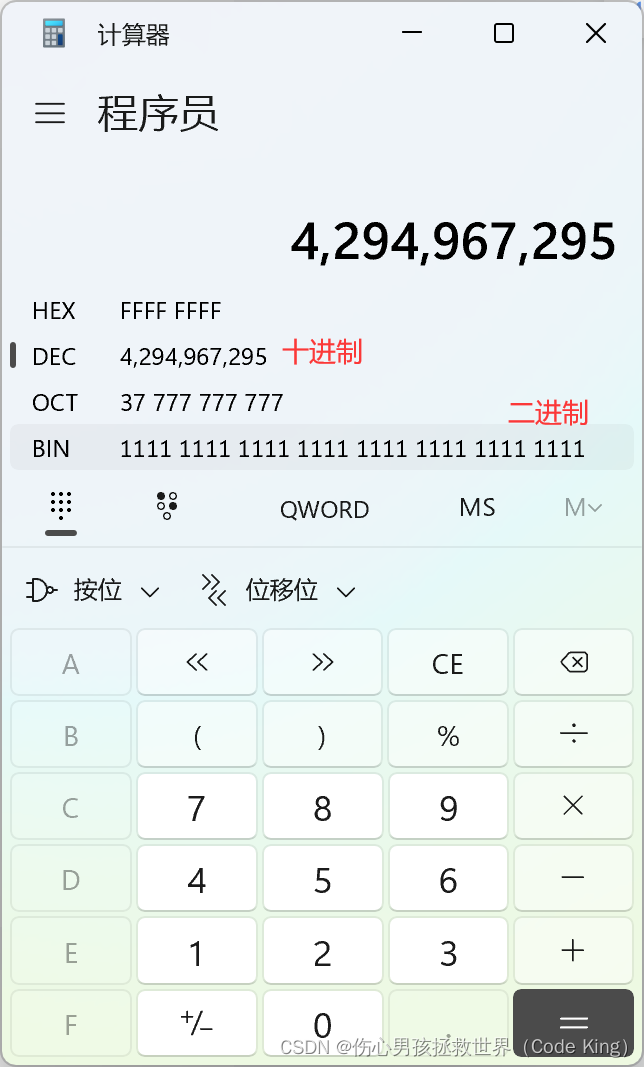
结果到零的时候,为什么是又变成了一个很大的数字呢?
这答案就在下面的这张图里面,(注意:这个图里面的数据类型是char,但是解释原理是一样的)
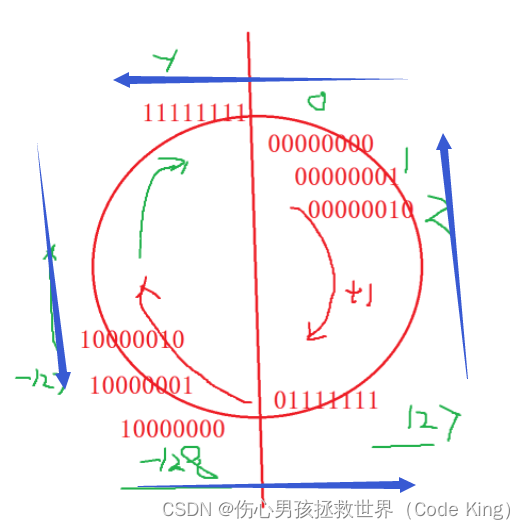
当 i 减到零的时候,有32个0,再减的时候,就变成了全1:
4.(很奇妙的例题):
#include <string.h>
#include <stdio.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
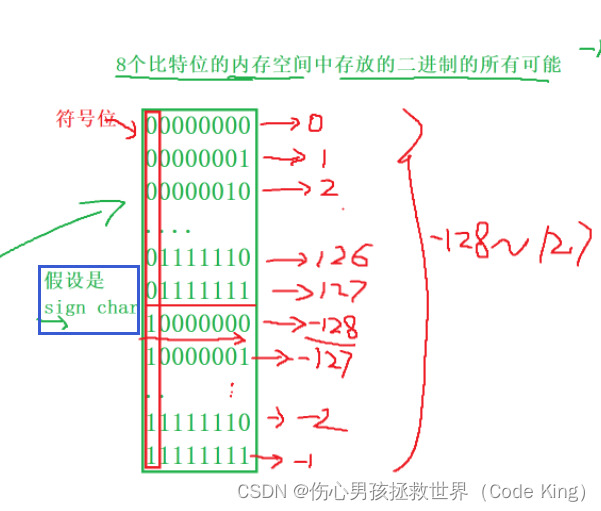
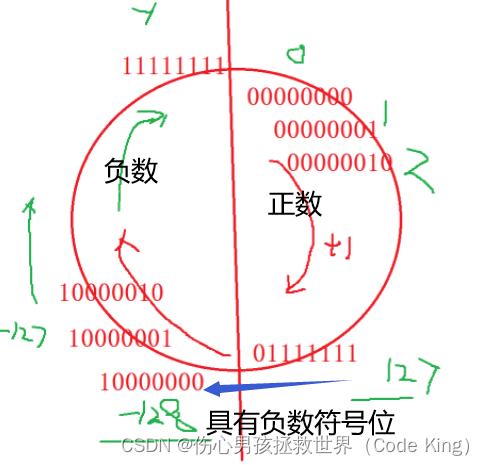
结果为什么是这个呢?那么接下来看4张图片,你就会明白了
还有一点需要注意:他先打印的是-1,-2,-3,-4........-128,127,126......1,0(这一组数不断的循环打印!但是0='\0',strlen函数只计算‘\0’之前的内容,所以最终答案是255。)


所以,综上所述:
char = signed char的范围是:(-128~127)
unsigned char的范围是:(0~255)
在最后我总结了一份关于这种类型题的解题思路:(大家可以参考一下,还望多多指教)

好了,今天的分享就到这里了
如果对你有帮助,记得点赞👍+关注哦!
我的主页还有其他文章,欢迎学习指点。关注我,让我们一起学习,一起成长吧!