目录
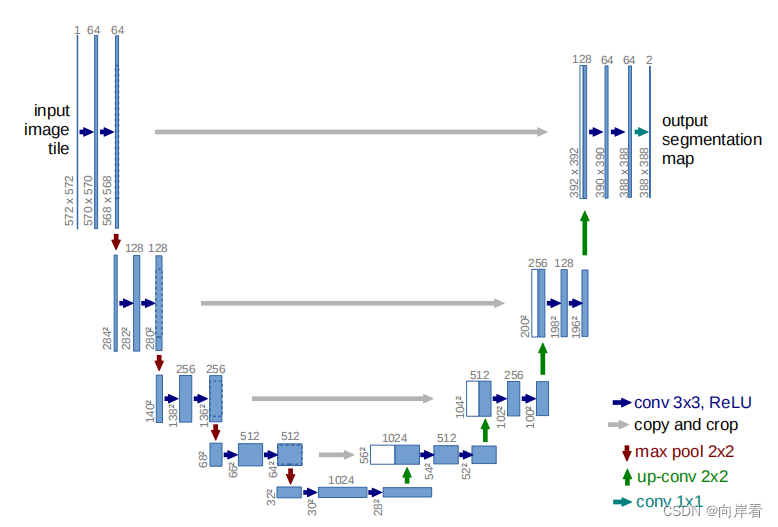
(1)se-unet01(在卷积后,下采样前,添加SE模块)
(2)se-unet02(在卷积后,上采样前,添加SE模块)
(3)se-unet03(在每两个卷积之后,加上SE模块)
(4)se-unet04(只在最后的输出卷积后,添加SE模块)
数据集:refuge视盘数据集
训练轮次:200
评价指标:dice coefficient、mean IOU。
|
Architecture
| dice coefficient | mean IOU |
| unet | 0.799 | 83.0 |
| se-unet01 | 0.989 | 63.3 |
(1)在卷积后,下采样前,添加SE模块
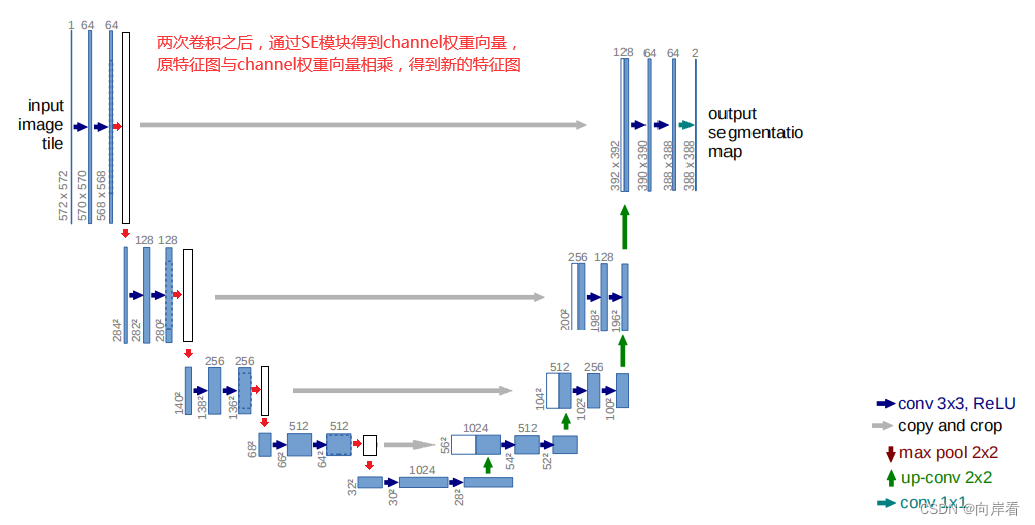
模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):
# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 下采样
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
# 1.最大池化的窗口大小为2, 步长为2
nn.MaxPool2d(2, stride=2),
# 2.两个卷积
DoubleConv(in_channels, out_channels)
)
# 上采样
class Up(nn.Module):
# bilinear是否采用双线性插值
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
# 使用双线性插值上采样
# 上采样率为2,双线性插值模式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 使用转置卷积上采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
# 上采样之后的特征图与要拼接的特征图,高度方向的差值
diff_y = x2.size()[2] - x1.size()[2]
# 上采样之后的特征图与要拼接的特征图,宽度方向的差值
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
# 1.填充差值
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
# 2.拼接
x = torch.cat([x2, x1], dim=1)
# 3.卷积,两次卷积
x = self.conv(x)
return x
# 最后的1*1输出卷积
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
# SE模块
self.SE1 = SE_Block(base_c)
self.SE2 = SE_Block(base_c * 2)
self.SE3 = SE_Block(base_c * 4)
self.SE4 = SE_Block(base_c * 8)
# 下采样,参数:输入通道,输出通道
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1
factor = 2 if bilinear else 1
# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.SE5 = SE_Block(base_c * 16 // factor)
# 上采样,参数:输入通道,输出通道
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
# 最后的1*1输出卷积
self.out_conv = OutConv(base_c, num_classes)
# 正向传播过程
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
# 1. 定义最开始的两个卷积层
x1 = self.in_conv(x)
x1 = self.SE1(x1)
# 2. contracting path(收缩路径)
x2 = self.down1(x1)
x2 = self.SE2(x2)
x3 = self.down2(x2)
x3 = self.SE3(x3)
x4 = self.down3(x3)
x4 = self.SE4(x4)
x5 = self.down4(x4)
x5 = self.SE5(x5)
# 3. expanding path(扩展路径)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
# 4. 最后1*1输出卷积
logits = self.out_conv(x)
return {"out": logits}
训练结果:
[epoch: 199]
train_loss: 0.0265
lr: 0.000000
dice coefficient: 0.989
global correct: 97.8
average row correct: ['36.4', '99.3']
IoU: ['28.8', '97.8']
mean IoU: 63.3
(2)在卷积后,上采样前,添加SE模块
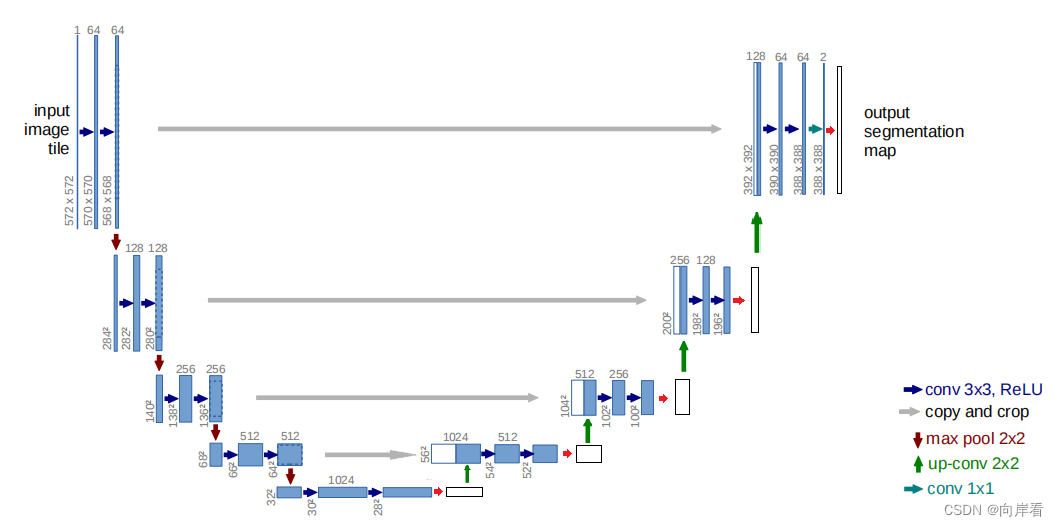
模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):
# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 下采样
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
# 1.最大池化的窗口大小为2, 步长为2
nn.MaxPool2d(2, stride=2),
# 2.两个卷积
DoubleConv(in_channels, out_channels)
)
# 上采样
class Up(nn.Module):
# bilinear是否采用双线性插值
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
# 使用双线性插值上采样
# 上采样率为2,双线性插值模式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 使用转置卷积上采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
# 上采样之后的特征图与要拼接的特征图,高度方向的差值
diff_y = x2.size()[2] - x1.size()[2]
# 上采样之后的特征图与要拼接的特征图,宽度方向的差值
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
# 1.填充差值
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
# 2.拼接
x = torch.cat([x2, x1], dim=1)
# 3.卷积,两次卷积
x = self.conv(x)
return x
# 最后的1*1输出卷积
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
# 下采样,参数:输入通道,输出通道
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1
factor = 2 if bilinear else 1
# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024
self.down4 = Down(base_c * 8, base_c * 16 // factor)
# 上采样,参数:输入通道,输出通道
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
# 最后的1*1输出卷积
self.out_conv = OutConv(base_c, num_classes)
# SE模块
self.SE1 = SE_Block(base_c * 16 // factor)
self.SE2 = SE_Block(base_c * 8 // factor)
self.SE3 = SE_Block(base_c * 4 // factor)
self.SE4 = SE_Block(base_c * 2 // factor)
self.SE5 = SE_Block(num_classes)
# 正向传播过程
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
# 1. 定义最开始的两个卷积层
x1 = self.in_conv(x)
# 2. contracting path(收缩路径)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x5 = self.SE1(x5)
# 3. expanding path(扩展路径)
x = self.up1(x5, x4)
x = self.SE2(x)
x = self.up2(x, x3)
x = self.SE3(x)
x = self.up3(x, x2)
x = self.SE4(x)
x = self.up4(x, x1)
# 4. 最后1*1输出卷积
logits = self.out_conv(x)
logits = self.SE5(logits)
return {"out": logits}
(3)在每两个卷积之后,加上SE模块
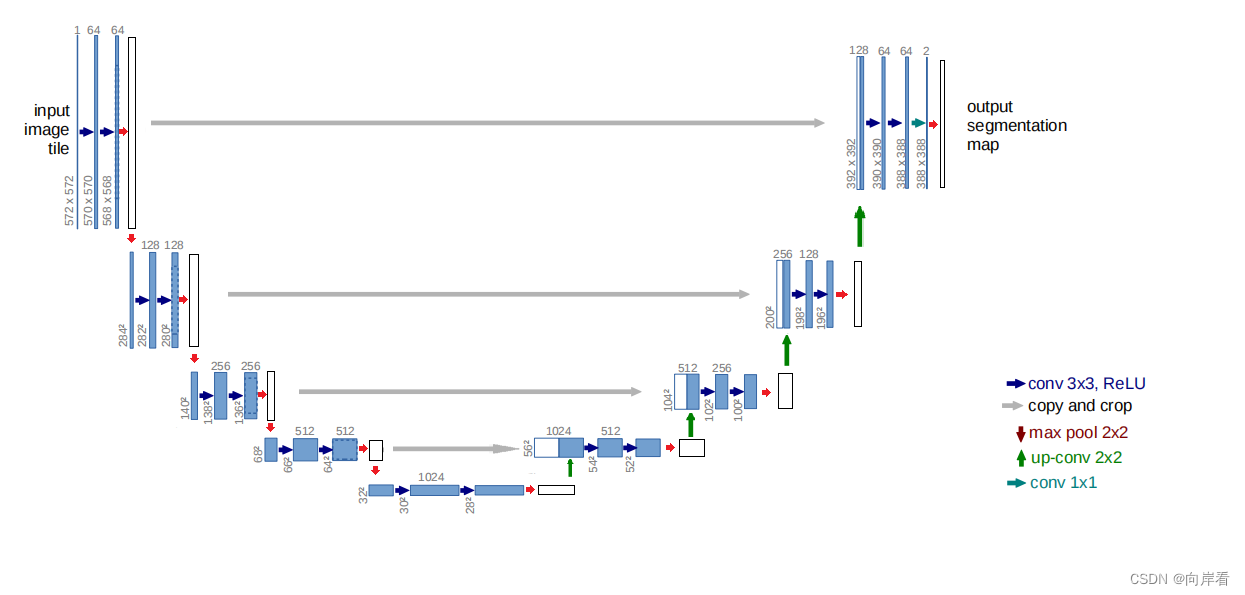
模型改动代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
# se-unet03
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):
# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 下采样
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
# 1.最大池化的窗口大小为2, 步长为2
nn.MaxPool2d(2, stride=2),
# 2.两个卷积
DoubleConv(in_channels, out_channels)
)
# 上采样
class Up(nn.Module):
# bilinear是否采用双线性插值
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
# 使用双线性插值上采样
# 上采样率为2,双线性插值模式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 使用转置卷积上采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
# 上采样之后的特征图与要拼接的特征图,高度方向的差值
diff_y = x2.size()[2] - x1.size()[2]
# 上采样之后的特征图与要拼接的特征图,宽度方向的差值
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
# 1.填充差值
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
# 2.拼接
x = torch.cat([x2, x1], dim=1)
# 3.卷积,两次卷积
x = self.conv(x)
return x
# 最后的1*1输出卷积
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
# 下采样,参数:输入通道,输出通道
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1
factor = 2 if bilinear else 1
# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024
self.down4 = Down(base_c * 8, base_c * 16 // factor)
# 上采样,参数:输入通道,输出通道
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
# 最后的1*1输出卷积
self.out_conv = OutConv(base_c, num_classes)
# SE模块
self.SE1 = SE_Block(base_c)
self.SE2 = SE_Block(base_c * 2)
self.SE3 = SE_Block(base_c * 4)
self.SE4 = SE_Block(base_c * 8)
self.SE5 = SE_Block(base_c * 16 // factor)
self.SE6 = SE_Block(base_c * 8 // factor)
self.SE7 = SE_Block(base_c * 4 // factor)
self.SE8 = SE_Block(base_c * 2 // factor)
self.SE9 = SE_Block(num_classes)
# 正向传播过程
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
# 1. 定义最开始的两个卷积层
x1 = self.in_conv(x)
x1 = self.SE1(x1)
# 2. contracting path(收缩路径)
x2 = self.down1(x1)
x2 = self.SE2(x2)
x3 = self.down2(x2)
x3 = self.SE3(x3)
x4 = self.down3(x3)
x4 = self.SE4(x4)
x5 = self.down4(x4)
x5 = self.SE5(x5)
# 3. expanding path(扩展路径)
x = self.up1(x5, x4)
x = self.SE6(x)
x = self.up2(x, x3)
x = self.SE7(x)
x = self.up3(x, x2)
x = self.SE8(x)
x = self.up4(x, x1)
# 4. 最后1*1输出卷积
logits = self.out_conv(x)
logits = self.SE9(logits)
return {"out": logits}
(4)只在最后的输出卷积后,添加SE模块
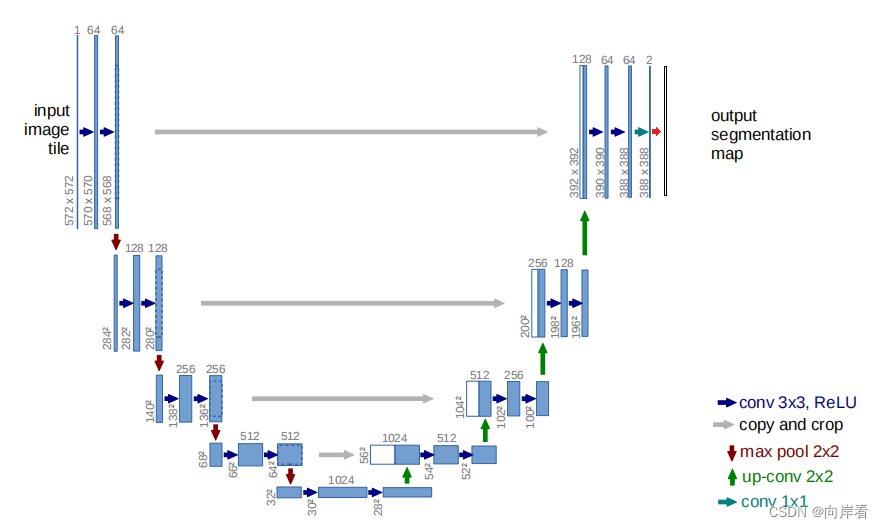
模型修改代码:
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
# se-unet04
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):
def __init__(self, inchannel, ratio=16):
super(SE_Block, self).__init__()
# 全局平均池化(Fsq操作)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
# 两个全连接层(Fex操作)
self.fc = nn.Sequential(
nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
nn.ReLU(),
nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
nn.Sigmoid()
)
def forward(self, x):
# 读取批数据图片数量及通道数
b, c, h, w = x.size()
# Fsq操作:经池化后输出b*c的矩阵
y = self.gap(x).view(b, c)
# Fex操作:经全连接层输出(b,c,1,1)矩阵
y = self.fc(y).view(b, c, 1, 1)
# Fscale操作:将得到的权重乘以原来的特征图x
return x * y.expand_as(x)
# 卷积,在uent中卷积一般成对使用
class DoubleConv(nn.Sequential):
# 输入通道数, 输出通道数, mid_channels为成对卷积中第一个卷积层的输出通道数
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None:
mid_channels = out_channels
super(DoubleConv, self).__init__(
# 3*3卷积,填充为1,卷积之后输入输出的特征图大小一致
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 下采样
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__(
# 1.最大池化的窗口大小为2, 步长为2
nn.MaxPool2d(2, stride=2),
# 2.两个卷积
DoubleConv(in_channels, out_channels)
)
# 上采样
class Up(nn.Module):
# bilinear是否采用双线性插值
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
# 使用双线性插值上采样
# 上采样率为2,双线性插值模式
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 使用转置卷积上采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
# 上采样之后的特征图与要拼接的特征图,高度方向的差值
diff_y = x2.size()[2] - x1.size()[2]
# 上采样之后的特征图与要拼接的特征图,宽度方向的差值
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
# 1.填充差值
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
# 2.拼接
x = torch.cat([x2, x1], dim=1)
# 3.卷积,两次卷积
x = self.conv(x)
return x
# 最后的1*1输出卷积
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
# 参数: 输入通道数, 分割任务个数, 是否使用双线插值, 网络中第一个卷积通道个数
def __init__(self,
in_channels: int = 1,
num_classes: int = 2,
bilinear: bool = True,
base_c: int = 64):
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
# 下采样,参数:输入通道,输出通道
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
# 如果采用双线插值上采样为 2,采用转置矩阵上采样为 1
factor = 2 if bilinear else 1
# 最后一个下采样,如果是双线插值则输出通道为512,否则为1024
self.down4 = Down(base_c * 8, base_c * 16 // factor)
# 上采样,参数:输入通道,输出通道
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
# 最后的1*1输出卷积
self.out_conv = OutConv(base_c, num_classes)
# SE模块
self.SE5 = SE_Block(num_classes)
# 正向传播过程
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
# 1. 定义最开始的两个卷积层
x1 = self.in_conv(x)
# 2. contracting path(收缩路径)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# 3. expanding path(扩展路径)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
# 4. 最后1*1输出卷积
logits = self.out_conv(x)
logits = self.SE5(logits)
return {"out": logits}



![[创业之路-70] :聊天的最高境界因场景不同而不同](https://img-blog.csdnimg.cn/img_convert/b8848b679aa94bd02b97687668150a96.jpeg)