前言:
本篇记录负载均衡oj项目设计的整体思路和部分代码。
负载均衡oj项目基于http网络请求,通过简单的前后端交互:前端的页面编辑已经提交代码,后端控制模块和编译运行的模块分离整合(负载均衡式的选择后端编译运行服务),从而实现在线oj的正常使用。
使用语言:C/C++,使用环境:Linux centos7,gcc -v 9.3.1-2,开始时间:2023/5/5,结束时间:2023/5/21。
前期大致项目已经完成,后续会存在扩展的地方,请期待。
项目源码地址:C++project: 我的C++项目仓库 - Gitee.com
目录
项目结果简单演示:
技术栈:
结构与总体思路:
1.compiler_server模块编写
compiler编译功能
-common/util.hpp 拼接编译临时文件
-common/log.hpp 开放式日志
-common/util.hpp 获取时间戳方法-秒级
-common/util.hpp 文件是否存在
-compile_server/compiler.hpp 编译功能编写
runner运行功能
-common/util.hpp 拼接运行临时文件
-compile_server/runner.hpp 运行功能编写
compile_run编译运行
-common/util.hpp 生成唯一文件名
-common/uti.hpp 写入文件/读出文件
-compile_server/compile_run.hpp 编译运行整合模块
compiler_server网络服务
安装cpp-httplib第三方库以及升级GCC版本
-compile_server/compile_server.cpp 编译运行网络服务
2.oj_server模块编写
oj_server框架的搭建
-oj_server/oj_server.cpp 路由框架
oj_model模块编写
题目信息设置
v1.文件版本
-common/util.hpp boost库spilt函数的使用
-oj_server/oj_model_file.hpp 文件版本model编写
v2.mysql数据库版本
1.mysql创建授权用户、建库建表录入操作:
2.mysql connect cpp操作
-oj_server/oj_model_mysql.hpp mysql数据库版本model编写
oj_control模块编写
1.获取题库
-oj_server/oj_control.hpp 获取题库渲染网页返回
2.获取单个题目
-oj_server/oj_control.hpp 获取单个题目渲染网页返回
3.判题
-oj_server/oj_control.hpp 主机对象设计
-oj_server/oj_control 负载均衡选择主机
oj_view模块编写
ctemplate库的配置和使用
-oj_server/oj_view.hpp 网页渲染
-oj_server/makefile 顶层makefile的编写
3.扩展内容
增加测试运行
增加登录模块
-oj_server/oj_user.hpp 登录管理
项目结果简单演示:
(目前扩展没有补充,不代表最终演示结果,另外前端很烂,将就一下啦(º﹃º ))

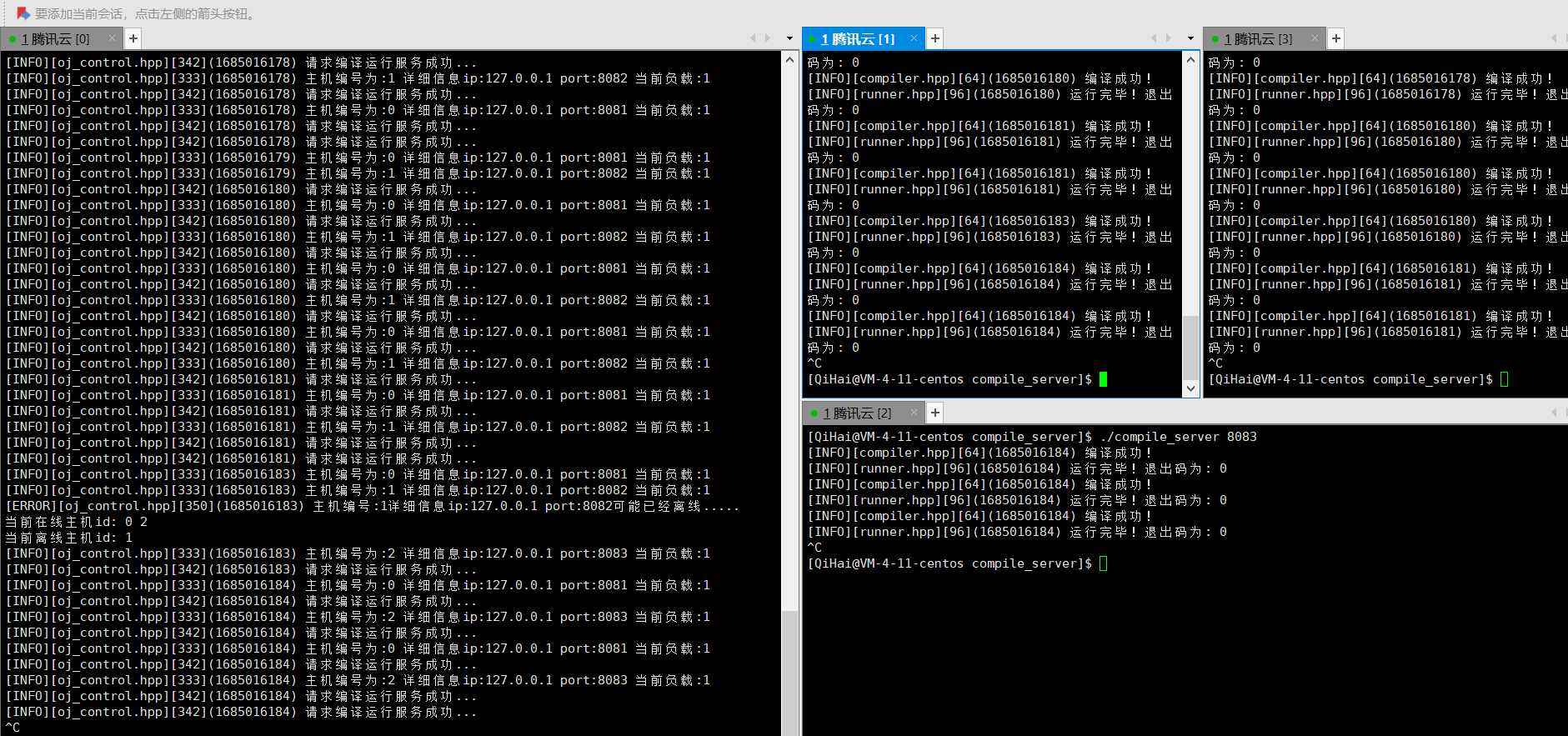
后端负载均衡选择示例:
技术栈:
对于负载均衡在线oj项目,我所使用的开发技术和环境如下:
技术如下:
1.C++STL(选择C++语言作为后端开发自然需要使用到里面的各种容器,比如string、vector)
2.cpp-httplib (http应用层通信我们使用第三方库快速解决,如果编写套接字接收会很麻烦)
3.jsoncpp (网络通信时重要的一点就是将一个待发送的信息转换为json串进行发送。为了简单完成序列化和反序列化)
4. Boost(C++准标准库内提供了一些好用的方法比如字符串切割spilt方法,能够快速帮助我们完成字符串切割为几个小块并且保存起来而不用自己编码实现)
5.MySQL C connect(当后端采用mysql数据库存储数据的时候,需要程序访问mysql数据库需要使用)
6.ctemplate (当想往网页html利用程序填充变量的时候,需要用到第三方渲染库,开源的前端渲染库)
7.ACE前端在线编辑器 (前端知识,让我们的oj代码编辑变得好看)
8.js/jquery/ajax (前端向后端发起http请求)
9.多进程多线程 (第三库中实现,本身代码没有体现)
10.负载均衡算法 (前端请求,后端根据编译服务主机的负载情况进行择少选择)
环境:Linux centos 7云服务器、vscode、Navicat。
结构与总体思路:
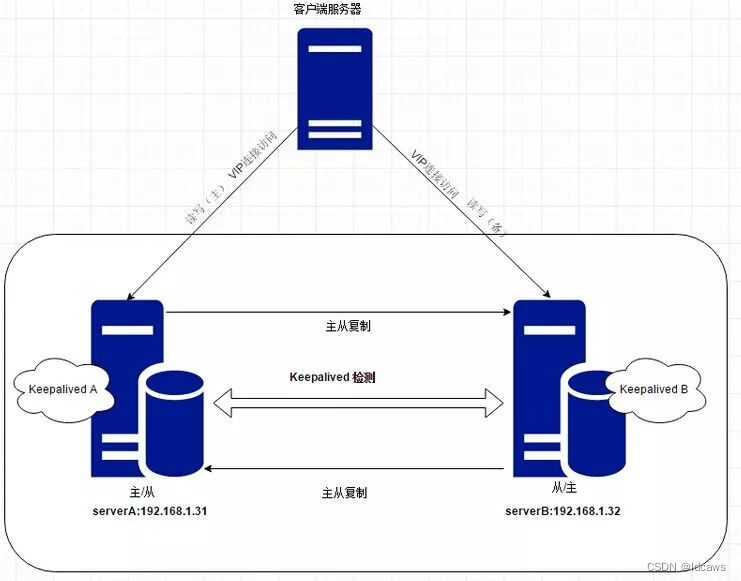
我们对外提供的是在线oj编译运行服务。那么在线自然通过实现web服务器在浏览器实现功能(利用前端制作网页,对应web服务器的路由实现功能),后端自然需要提供编译运行服务。
为了更加灵活的控制后端的编译运行服务,我们可以将后端编译运行服务也设置为网络服务,这样的化我们可以利用不同的主机部署编译运行服务,web服务器(在线oj和前端交互的)后端可以负载均衡式的选择主机。(这样的话在未来存在很多人使用的情况下就可以不用导致一台主机压力过大而被干掉)题目来源题库,只需要web服务器根据路由选择提供题目列表或者单个题目信息了,题库的话设计版本有文件版本和mysql数据库版本。
这样的话我们的思路就被明确出来了。web服务器路由整合和前后端交互内容模块我们称之为oj_server模块,编译运行服务模块称为compiler_server模块。很明显,这就是一种bs模式(浏览器/服务器模式)。

如上图,此项目就是设计红色区域内的内容。
针对此,我们在我们的项目目录结构上率先划分出三个区域出来:
1.oj服务 - oj_server(前端提供路由,前后端结合,后端提供功能,并且负载均衡选择后端)
2.编译运行服务 - compiler_server(后端提供编译运行功能)
3.公共模块 - common (上面两个模块共同使用的文件存放处)
下面我们针对不同的模块分开设计最后整合起来完成项目的编写。
1.compiler_server模块编写
编译运行服务。很明显,是存在两个步骤的:先编译,后运行。
在打包为网络服务之前,我们需要设计出编译功能和运行功能,然后在将两个功能整合起来。
compiler编译功能
一个C/C++程序源文件,需要经过gcc/g++工具进行预处理、编译、汇编、链接最终形成可执行文件。
平时,我们将一个源文件编译形成可执行文件只需要gcc/g++ -o... 一步到位即可。但是现在我们需要在程序中实现这个功能。难道我们要实现gcc/g++的功能?自然不是,需要用到操作系统接口:exec*进程替换。(进程替换相关博客:进程控制-进程替换)
但是,在执行程序替换时我们需要一些必要的需求。
首先是源文件的来源(之后由编译运行服务提供,负责将提供的code源码形成临时文件CPP提供编译服务),其次编译可能出现报错,报错的话gcc/g++程序时输出到stderr文件中的,那么需要我们进行重定向到错误文件中去,最后,因为需要返回编译结果,那么程序替换需要在子进程中进行,父进程等待后返回结果不受程序替换的影响。
所以,此模块的设计思路如下:
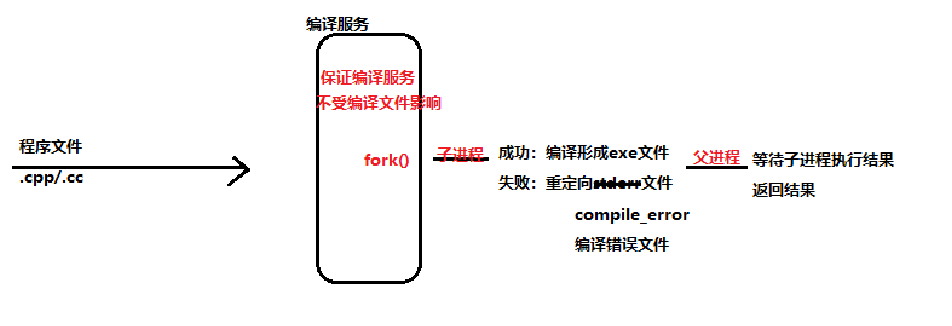
因为需要程序文件的路径。在项目设计中我们需要将编译运行服务所需要的临时文件都存放在一个temp目录下。那么每次变得就只是文件名。可以利用这个特点,在传给编译服务的时候只需要传文件名即可,拼接路径由common公共模块下的util.hpp提供路径拼接,与此同时,因为编码运行过程中难免存在差错,我们需要差错处理就需要一个简单的开放式日志功能,我们也可以存放在common下log.hpp。
拼接文件想一下,编译服务需要的临时文件存在三种:编译前的.cpp文件、编译后的.exe文件、错误重定向的compile_error文件(stderr-重定向)。
-common/util.hpp 拼接编译临时文件
拼接路径名我们写在类PathUtil中即可。
namespace ns_util
{
const std::string path = "./temp/";
// 合并路径类
class PathUtil
{
public:
// 拼接函数
static std::string splic(const std::string& str1, const std::string& str2)
{
std::string temp = path;
temp += str1;
temp += str2;
return temp;
}
// 编译临时文件
// 拼接源文件 文件名+cpp
static std::string Src(const std::string& file_name)
{
return splic(file_name, ".cpp");
}
// 拼接可执行文件 文件名+exe
static std::string Exe(const std::string& file_name)
{
return splic(file_name, ".exe");
}
// 拼接保存标准错误文件
static std::string CompileError(const std::string& file_name)
{
return splic(file_name, ".compile_error");
}
}
}-common/log.hpp 开放式日志
一个日志需要等级,时间,当前调日志的文件,行数,描述信息。显示我们利用屏幕显示即可,所以可以利用cout遇到'\n'刷新到屏幕上的策略编写日志文件。日志文件中只需要显示除开描述信息之外的信息即可。
为了方便外层文件调用,我们可以利用宏编写,减少参数的传递。
namespace ns_log
{
using namespace ns_util;
// 日志等级
enum{
INFO, // 正常
DEBUG, // 调试
WARING, // 警告
ERROR, // 错误
FATAL // 致命
};
// 开放式输出日志信息
inline std::ostream& Log(const std::string& level, const std::string& file_name, int line)
{
// #ifndef MYLOGDEBUG
// if (level == "DEBUG"){
// return std::cout << "\n";
// }
// #endif
std::string log;
// 添加日志等级
log += "[";
log += level;
log += "]";
// 添加输出日志文件名
log += "[";
log += file_name;
log += "]";
// 添加日志行号
log += "[";
log += std::to_string(line);
log += "]";
// 添加当前日志时间戳
log += "(";
log += TimeUtil::GetTimeStamp();
log += ") ";
std::cout << log; // 不使用endl进行刷新,利用缓冲区 开放式日志文件
return std::cout;
}
// 利用宏定义完善一点 - LOG(INFO) << "一切正常\n";
#define LOG(level) Log(#level, __FILE__, __LINE__)
}
#endif上面的获取时间利用的是时间戳,我们在util工具类中编写获取时间戳的代码即可。(利用操作系统接口:gettimeofday即可)
-common/util.hpp 获取时间戳方法-秒级
获取时间轴我们可以写入TimeUtil时间工具类中。
// 时间相关类
class TimeUtil
{
public:
static std::string GetTimeStamp()
{
// 使用系统调用gettimeofday
struct timeval t;
gettimeofday(&t, nullptr); // 获取时间戳的结构体、时区
return std::to_string(t.tv_sec);
}
}准备好这些工作后,就可以进行编译服务的编写了,根据传入的源程序文件名,首先创建子进程,子进程对stderr进行重定向到文件compile_error中,使用execlp(系统路径下找命令,可变参数传参)进行程序替换,父进程在外面等待子进程结果,等待成功后根据是否生成可执行程序决定是否编译成功。
是否生成可执行程序如何确定?可以利用stat系统接口进行查看,查看文件属性成功说明存在文件,否则就是不存在。我们将此小工具写入common/util.hpp中。
-common/util.hpp 文件是否存在
因为是和文件相关,我们可以放入FileUtil文件工具类中。
// 文件相关类
class FileUtil
{
public:
// 判断传入文件(完整路径)是否存在
static bool IsFileExist(const std::string& pathFile)
{
// 使用系统调用stat查看文件属性,查看成功说明存在文件,否则没有
struct stat st;
if (stat(pathFile.c_str(), &st) == 0)
{
// 说明存在文件
return true;
}
return false; // 否则不存在此文件
}
}现在就可以编写compile.hpp文件了,注意利用log文件进行差错处理。
-compile_server/compiler.hpp 编译功能编写
#ifndef __COMPILER_HPP__
#define __COMPILER_HPP__
// 编译模块
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_compiler
{
using namespace ns_util;
using namespace ns_log;
class Compiler
{
public:
Compiler()
{}
~Compiler()
{}
// 编译函数 编译临时文件
// 输入:需要编译的临时文件名(存在./temp/文件名.cpp文件,不需要带cpp/cc后缀)
// 输出:编译成功true,false失败
static bool compile(std::string &file_name)
{
pid_t childPid = fork();
if (childPid < 0)
{
// 子进程创建失败
LOG(ERROR) << "内部错误,当前子进程无法创建" << "\n";
return false;
}
if (childPid == 0)
{
// 子进程
// 如果编译失败,需要将错误信息输入到错误文件内,利用重定向
umask(0); // 防止平台的影响,影响文件权限
int errFd = open(PathUtil::CompileError(file_name).c_str(), O_CREAT | O_WRONLY, 0644); // rw_r__r__
if (errFd < 0)
{
// 异常,终止程序
LOG(ERROR) << "内部错误,错误输出文件打开/创建失败" << "\n";
exit(1);
}
// 打开成功重定向
dup2(errFd, 2); // 将标准错误重新向到错误文件内,这样出错就可以将错误信息写入其中
execlp("g++", "g++", "-o", PathUtil::Exe(file_name).c_str(), PathUtil::Src(file_name).c_str(), "-D", "COMPILE_ONLINE", NULL); // p默认从环境变量下搜索
LOG(ERROR) << "g++执行失败,检查参数是否传递正确" << "\n";
exit(2); // 如果执行这一步说明上面的exec程序替换函数执行失败
}
// 父进程
waitpid(childPid, nullptr, 0); // 阻塞等待子进程
// 判断是否编译成功可以根据是否生成exe可执行文件进行判断
if (FileUtil::IsFileExist(PathUtil::Exe(file_name)))
{
// .exe文件存在
LOG(INFO) << "编译成功!" << "\n";
return true; // 编译成功
}
LOG(ERROR) << "编译失败!" << "\n";
return false; // exe文件不存在,编译失败
}
};
}
#endifrunner运行功能
运行模块很简单,只需要一个可执行程序即可,还是利用exec*程序替换进行执行即可。
只不过,运行的话就分为运行成功和运行失败。存在运行成功但是结果不正确的原因,但这不是运行功能处理的事情,运行模块只需要关心是否运行成功,运行出错比如段错误、空指针引用等。
除此之外,我们需要想到程序运行的时候默认打开的三个文件:stdin、stdout、stderr。需要进行重定向,这也就是运行模块需要的临时文件(PathUtil需要编写)。其中stdin就是未来上层传来的用户测试用例,stdout就是运行成功后输出结果,stderr就是运行失败后的输出结果。
因为存在各种函数以及打开文件,那么可能出现内部错误(非程序运行报错),所以在返回上层结果的时候,我们需要规定值表示不同的错误类别。为了保持运行出错所返回的信号中断,我们可以设置>0就是运行报错(直接返回运行返回值即可),<0设置为内部错误(比如打开文件失败),等于0就是运行成功。
所以,此模块的设计思路如下:

另外,程序运行时为了防止破坏计算机的事情(比如申请过大内存、很长时间浪费编译服务资源)也或者一些编程的限制空间和资源。我们需要对运行程序进行资源限制。资源限制可以利用系统接口setrlimit进行,分别根据传入的时间和空间进行约束。
我们直到,当OS终止程序的时候,都是通过信号进行终止的。而此资源限制限制的内存就是6号信号,cpu的执行时间限制就是24号信号。可以利用signal函数捕捉验证一下。(当然也可以查看返回值)
-common/util.hpp 拼接运行临时文件
和拼接编译运行文件一样,同样放在PathUtil工具类中。
// 运行临时文件
// 拼接保存标准输入文件
static std::string Stdin(const std::string& file_name)
{
return splic(file_name, ".stdin");
}
// 拼接保存标准输出文件
static std::string Stdout(const std::string& file_name)
{
return splic(file_name, ".stdout");
}
// 拼接保存标准错误文件
static std::string Stderr(const std::string& file_name)
{
return splic(file_name, ".stderr");
}-compile_server/runner.hpp 运行功能编写
同理,我们还是需要创建子进程进行程序替换,父进程阻塞等待获取子进程结果从而返回结果。需要注意资源限制函数,我们根据接口传入的参数在子进程的环境下进行限制运行即可。
#ifndef __RUNNER_HPP__
#define __RUNNER_HPP__
// 运行模块
#include <string>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/time.h>
#include <sys/resource.h>
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_runner
{
using namespace ns_util;
using namespace ns_log;
class Runner
{
public:
Runner() {}
~Runner() {}
public:
// 资源限制接口
// cpu_limit时间限制s men_limit空间限制KB
static void SetProCLimit(int cpu_limit, int mem_limit)
{
// 时间限制
struct rlimit cpuLimit;
cpuLimit.rlim_max = RLIM_INFINITY;
cpuLimit.rlim_cur = cpu_limit;
setrlimit(RLIMIT_CPU, &cpuLimit);
// 空间限制
struct rlimit memLimit;
memLimit.rlim_max = RLIM_INFINITY;
memLimit.rlim_cur = mem_limit * 1024; // byte->kb
setrlimit(RLIMIT_AS, &memLimit);
}
// 运行模块
// 输入可执行文件名 在temp目录下的.exe文件
// 返回值:0表示运行成功、<0表示内部错误,>0表示运行出错
// 时间限制:cpu_limit 空间限制:men_limit
// 返回值: <0 内部错误 =0运行成功,成功写入stdout等文件 >0运行中断,用户代码存在问题
static int Run(const std::string& file_name, int cpu_limit, int mem_limit)
{
// 在父进程中先将运行所需要的三个临时文件打开
int _stdin = open(PathUtil::Stdin(file_name).c_str(), O_CREAT | O_RDONLY, 0644);
int _stdout = open(PathUtil::Stdout(file_name).c_str(), O_CREAT | O_WRONLY, 0644);
int _stderr = open(PathUtil::Stderr(file_name).c_str(), O_CREAT | O_WRONLY, 0644);
// 打开文件进行差错处理
if (_stdin < 0 || _stdout < 0 || _stderr < 0)
{
// 文件打不开运行程序没有意义了
LOG(ERROR) << "内部错误, 标准文件打开/创建失败" << "\n";
return -1;
}
pid_t childPid = fork();
if (childPid < 0)
{
// 创建子进程失败
// 创建失败,打开的文件需要收回-否则占用无效资源!
close(_stdin);
close(_stdout);
close(_stderr);
LOG(ERROR) << "内部错误, 创建子进程失败" << "\n";
return -2;
}
if (childPid == 0)
{
// 子进程
// 资源限制
SetProCLimit(cpu_limit, mem_limit);
dup2(_stdin, 0);
dup2(_stdout, 1);
dup2(_stderr, 2);
execl(PathUtil::Exe(file_name).c_str(), PathUtil::Exe(file_name).c_str(), nullptr); // execl函数,不从环境变量下找,直接根据路径找可执行文件 路径、可执行文件
exit(-1); // 程序替换出错
}
// 父进程
close(_stdin);
close(_stdout);
close(_stderr);
//父进程等待子进程,查看返回情况
int status; //输出参数,接收状态信息
waitpid(childPid, &status, 0); // 阻塞等待
if (status < 0)
{
//信号不等于0说明执行失败
LOG(ERROR) << "内部错误, execl参数或者路径不正确" << status << "\n";
return status;
}
else LOG(INFO) << "运行完毕!退出码为: " << (status & 0x7F)<< "\n";
return (status & 0x7F);
}
};
}
#endifcompile_run编译运行
上面将编译和运行模块分开了,正常流程则是先编译后运行。那么我们需要将这两个流程整合起来实现编译运行模块的后端工作。
想要编译,那么我们就需要源文件,源文件从哪里来?用户通过网络发送而来。所以用户发送过来就是前端序列化后的json串,反序列化后得到的数据写入源文件中,交给编译功能编译后形成可执行文件然后交给运行功能运行,最后整合结果也向对方返回结果json串完成工作。
那么,上面的四种颜色就是compile_run编译运行需要执行的步骤:
首先时前端序列化后的json串,我们需要规定其返回什么。一份源文件自然需要一份完整的代码,如果用户输入的话还需要用户的input数据。另外每个程序都需要对应的时间和空间限制。综上,用户返回的json串格式如下:
{
"code": code,
"input": input,
"cpu_limit": S,
"mem_limit": kb
}(需要注意CPP实验json库在linux下需要sudo yum install jsoncpp-devel安装json开发库,并且在编译选项中加上-ljsoncpp方可编译)
反序列化得到数据后,我们需要将code部分写入.cpp源文件中去。 写入文件很简单(利用C++的ofstream简单IO即可),但是需要注意,之后此模块的功能是被打包为网络服务的。也就是说可能同时出现了很多用户提交的代码。如果此时名字冲突就会发生问题,不同用户之间执行的不同题或者编程内容就会出现问题。
所以当一份用户提交代码后,我们为其生成的源文件名需要具有唯一性。名字生成唯一性我们可以利用毫秒级时间戳加上原子性的增长计数实现。
毫秒级时间戳可以利用gettimeofday函数调用实现(返回的结构体存在微秒级的属性,简单转换就可以得到微秒),原子性的增长计数(同一时刻不同执行流调用-利用static的变量)利用C++11的特性atomic_uint即可实现。
-common/util.hpp 生成唯一文件名
获取毫秒时间戳在TimeUtill工具类中,生成唯一文件名在FileUtil工具类中。
// 获取毫秒级时间戳
static std::string GetTimeMs()
{
struct timeval t;
gettimeofday(&t, nullptr);
return std::to_string((t.tv_sec * 1000 + t.tv_usec / 1000)); // 秒+微秒
}
//......
// 生成唯一的文件名
// 利用微秒时间戳和原子性的唯一增长数字组成
static std::string UniqueFileName()
{
// 利用C++11的特性,生成一个原子性的计数器
static std::atomic_uint id(0);
id++;
std::string ms = TimeUtil::GetTimeMs();
return ms + "-" + std::to_string(id);
}现在能够生成唯一文件名后,我们可以根据此路径写入文件中。为了方便,我们一并将写入文件和读取文件写入util工具类中,方便项目文件进行调用。利用的就是C++的fstream类。
-common/uti.hpp 写入文件/读出文件
因为是和文件相关,所以也放入FileUtil工具类中。
// 根据路径文件进行写入
static bool WriteFile(const std::string& path_file, const std::string& content)
{
// 利用C++的文件流进行简单的操作
std::ofstream out(path_file);
// 判断此文件是否存在
if (!out.is_open()) return false;
out.write(content.c_str(), content.size());
out.close();
return true;
}
// 根据路径文件进行读出
// 注意,默认每行的\\n是不进行保存的,需要保存请设置参数
static std::string ReadFile(const std::string& path_file, bool keep = false)
{
// 利用C++的文件流进行简单的操作
std::string content, line;
std::ifstream in(path_file);
if (!in.is_open()) return "";
while (std::getline(in, line))
{
content += line;
if (keep) content += "\n";
}
in.close();
return content;
}现在已经能够生成唯一名字的源文件了,我们利用此源文件执行编译运行流程,最终将结果返回给用户。需要注意,这个过程中仍然出现很多差错,我们类似运行模块那样,首先将错误分为几类,最后将这些转换为描述发送出去。
因为运行报错会返回>0的数(对应信号),所以其余错误我们均定为负数,方便后续的错误描述。首先,一开始用户发送给我们的code可能为空,为空的话就没有继续执行下去的必要了,可以定义用户错误。此外可能打开文件失败,写入文件失败,以及运行模块返回<0都是内部的错误,对外应该显示为未知错误,之后编译错误、正常返回即可。
状态码和状态描述我们可以将其返回回去。另外,如果运行成功我们还需要将运行生成的stdout和stderr文件返回回去。所以,返回结果完整的json串如下:
{
"status": status,
"reason": reason,
"stdout": stdout,
"stderr": stderr
}对于状态码描述我们可以单独写一个函数进行整合选择,写入json串中。另外因为每次编译运行会产生很多的临时文件(temp/),当这一切执行完后临时文件就没有意义了,就需要进行清理。删除文件可以利用unlink接口进行删除,需要注意其文件是否存在。
综上,思路我们可以整理为如下图:

-compile_server/compile_run.hpp 编译运行整合模块
#ifndef __COMPILE_RUN_HPP__
#define __COMPILE_RUN_HPP__
// 编译运行整合模块
#include <unistd.h>
#include <jsoncpp/json/json.h>
#include "compiler.hpp"
#include "runner.hpp"
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_compile_and_run
{
using namespace ns_compiler;
using namespace ns_runner;
using namespace ns_log;
using namespace ns_util;
class CompileAndRun
{
public:
// 删除临时文件
static void RemoveFile(const std::string& file_name)
{
// 因为临时文件的存在情况存在多种,删除文件采用系统接口unlink,但是需要判断
std::string src_path = PathUtil::Src(file_name);
if (FileUtil::IsFileExist(src_path)) unlink(src_path.c_str());
std::string stdout_path = PathUtil::Stdout(file_name);
if (FileUtil::IsFileExist(stdout_path)) unlink(stdout_path.c_str());
std::string stdin_path = PathUtil::Stdin(file_name);
if (FileUtil::IsFileExist(stdin_path)) unlink(stdin_path.c_str());
std::string stderr_path = PathUtil::Stderr(file_name);
if (FileUtil::IsFileExist(stderr_path)) unlink(stderr_path.c_str());
std::string compilererr_path = PathUtil::CompileError(file_name);
if (FileUtil::IsFileExist(compilererr_path)) unlink(compilererr_path.c_str());
std::string exe_path = PathUtil::Exe(file_name);
if (FileUtil::IsFileExist(exe_path)) unlink(exe_path.c_str());
}
// 根据不同的状态码进行解析结果输入信息
// > 0 运行中断 6-内存超过范围、24-cpu使用时间超时、8-浮点数溢出(除0异常)
// = 0 运行成功
// < 0 整个过程,非运行报错(内部错误、编译报错、代码为空)
static std::string CodeToDesc(int status, const std::string& file_name)
{
std::string desc;
switch(status)
{
case 0:
desc = "运行成功!";
break;
case -1:
desc = "代码为空";
break;
case -2:
desc = "未知错误";
break;
case -3:
desc = "编译报错\n";
desc += FileUtil::ReadFile(PathUtil::CompileError(file_name), true);
break;
case 6:
desc = "内存超过范围";
break;
case 24:
desc = "时间超时";
break;
case 8:
desc = "浮点数溢出";
break;
case 11:
desc = "野指针错误";
break;
default:
desc = "未处理的报错-status为:" + std::to_string(status);
break;
}
return desc;
}
/***********************
* 编译运行模块
* 输入:in_json输入序列化串 *out_json 输出序列化串(输出参数)
* 输出
* in_json {"code":..., "input":..., "cpu_limit":..., "mem_limit":...}
* out_json {"status":..., "reason":...[, "stdout":..., "stderr":...]}
***********************/
static void Start(const std::string& in_json, std::string* out_json)
{
std::string code, input, file_name;
int cpu_limit, mem_limit; // s, kb
int status, run_reason; // 状态码, 运行返回码
// 首先反序列化in_json,提取信息
Json::Value in_value;
Json::Reader read;
read.parse(in_json, in_value); // 序列化可能出问题
code = in_value["code"].asString();
input = in_value["input"].asString();
cpu_limit = in_value["cpu_limit"].asInt();
mem_limit = in_value["mem_limit"].asInt();
// 首先检测code是否存在数据
if(code.empty())
{
status = -1; // 用户错误
goto END;
}
// 首先生成唯一的临时文件名
file_name = FileUtil::UniqueFileName();
// code写入文件
if(!FileUtil::WriteFile(PathUtil::Src(file_name), code))
{
// 如果写入失败,内部报错
status = -2;
goto END;
}
// 写入文件成功的话,我们进行编译步骤
if (!Compiler::compile(file_name))
{
status = -3; // 编译失败,导入结果compile_error
goto END;
}
// 将input标准输入写入文件
if(!FileUtil::WriteFile(PathUtil::Stdin(file_name), input))
{
// 如果写入失败,内部报错
status = -2;
goto END;
}
// 编译步骤成功,我们进行运行步骤
run_reason = Runner::Run(file_name, cpu_limit, mem_limit);
if (run_reason < 0)
{
// 内部错误
status = -2;
}
else
{
// 运行成功或者中断
status = run_reason;
}
END:
// 构建返回序列化串
Json::Value out_value;
out_value["status"] = status;
out_value["reason"] = CodeToDesc(status, file_name); // 需要接口
// 如果运行成功,那么构建可选字段
if (status == 0)
{
out_value["stdout"] = FileUtil::ReadFile(PathUtil::Stdout(file_name), true);
out_value["stderr"] = FileUtil::ReadFile(PathUtil::Stderr(file_name), true);
}
Json::StyledWriter write;
*out_json = write.write(out_value);
RemoveFile(file_name);
}
};
}
#endifcompiler_server网络服务
现在已经有了编译服务这个模块了,只需要打包成网络服务就可以完成我们的目的了。
首先,自然可以写套接字实现http网络服务(网络套接字博客可以看这篇:网络套接字编程),服务器端绑定ip、端口,因为http是基于TCP的,所以需要设置监听。最后利用多进程、多线程或者epoll高级IO模式(epoll)获取每一个链接,接收json串(应用层处理数据粘包或者不全的问题),然后传递给编译运行模块执行结果后在通过http发送json串完成一次网络通信。
首先可行,但是在项目中这么写太多太麻烦了。就像我们利用C++的STL库一样,如果这套http网络服务我们能直接使用就减轻了网络服务编写的负担了。由于C++官方本身没有提供网络库的相关库,但是我们可以利用cpp-http第三方库进行使用,方便我们的网络服务的创建。
安装cpp-httplib第三方库以及升级GCC版本
在gitee搜索cpp-httplib 0.7.15版本,标签进行查找版本。(点此链接直接访问:cpp-httplib: cpp-httplib - Gitee.com)
下载上传后,找到httplib.h文件拷贝到common目录下即可。
但是编译cpp-httplib需要更高版本的GCC,我们需要进行升级。
// 安装scl
sudo yum install centos-release-scl scl-utils-build
// 安装新版本GCC
sudo yum install -y devtoolset-9-gcc devtoolset-9-gcc-c++
ls /opt/rh
// 启动 只有本次会话有效
scl enable devtoolset-9 bash
gcc -v
// 可选,每次登录都是较新的GCC,添加到~/.bash_profile中 自己的家目录
scl enable devtoolset-9 bash注意:升级到789都可以,换版本只需要将上面的数字进行替换即可。
另外,httplib是一个阻塞式多线程原生库,需要引入原生线程库 -lpthread;
现在我们可以利用httplib库将compile_run打包为一个网络编译运行服务。
httplib存在Server服务器对象,其中存在Post和Get方法分别对应客户端向服务器发送请求报文中请求首行的执行方法。其中Get可以时获取资源,Post则是提交资源...
我们利用此方法,根据两个(一个const属性的请求Request,另一个输出型的Response)参数的函数对象,进行返回结果(构建Response的正文和响应报头)。对方提交json串的时候自然使用是Post方法,利用其获取json(请求正文),调用编译运行服务构建响应json,再写入响应报文中(类型 + 正文),完成compile_run路由设置,最后绑定ip(0.0.0.0),端口(需要设置命令行参数,端口不可定死,并且后续存在编译服务器的配置文件,为上层oj_server灵活的提供主机选择)从命令行参数设置,cpp-httplib使用listen方法执行即可。
-compile_server/compile_server.cpp 编译运行网络服务
#include "compile_run.hpp"
#include "../common/httplib.h"
using namespace ns_compile_and_run;
using namespace httplib;
void User(char * use)
{
std::cout << "User:" << "\n\t";
std::cout << use << " port" << std::endl;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
// 满足传递 ./ port
User(argv[0]);
return 1;
}
// 将我们的编译运行服务打包为网络服务 - 为负载均衡做准备
Server svr;
svr.Get("/hello", [](const Request& req, Response& resp){
resp.set_content("你好呀,这里是编译运行服务,访问服务请访问资源/compile_and_run", "text/plain;charset=utf-8");
}); // 请求资源
svr.Post("/compile_and_run", [](const Request& req, Response& resp){
// 首先提取用户提交的json串
std::string in_json = req.body;
std::string out_json;
// 判断json串是空的吗?空的拒绝服务
if(!in_json.empty())
CompileAndRun::Start(in_json, &out_json);
// 返回out_json串给客户端
resp.set_content(out_json, "application/json;charset=utf-8");
}); // 提交json串,返回json串
// 注册运行
svr.listen("0.0.0.0", atoi(argv[1]));
return 0;
}注意响应正文对应的响应报头中写的类型(ConnectType)可以参考此网站进行对照: HTTP 响应类型 ContentType 对照表 - 爱码网
2.oj_server模块编写
oj_server实际上就是搭建一个小型网站。向后连接题库文件、编译运行服务,向前提供路由服务,渲染题库页面、单个题页面.....
那么此网站具体提供的能力如下:
1.获取题库首页,能够全部题目。
2.获取单个题目信息,能够编辑代码。
3.能够上传判题得到结果。
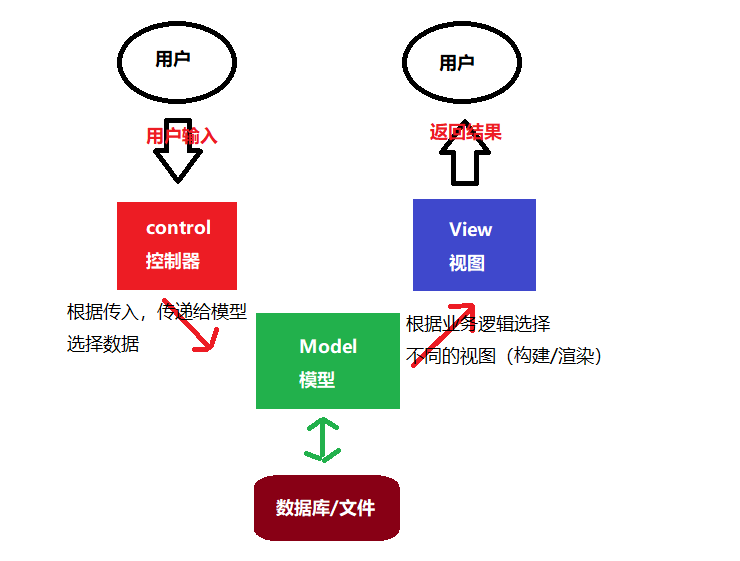
现在,为了将数据逻辑和界面进行分离,我们利用MVC设计模式(百度百科:MVC框架)对我们的oj_server进行设计。
MVC的设计模式
M:model 业务模型,通常是逻辑和数据交互的模块。本项目中则是对题库的加载和访问(全部/单个),版本存在两个:文件版本和mysql数据库版本。oj_model
V:view 用户界面,通常是拿到数据,构建、渲染网页展示给用户的(浏览器)。本项目中需要构建的网页有:index首页、all_questions题库、one_question单个题目。oj_view
C:control 控制器,我们的业务核心逻辑,通过路由根据控制器执行相应的功能。oj_control
综上,我们的MVC图可以如下展示出来:
oj_server框架的搭建
-oj_server/oj_server.cpp 路由框架
那么,现在我们可以利用cpp-httplib将整个服务的路由写好,之后替换为控制器为我们实现逻辑控制。
创建好Server后,提供如下的路由:
int main()
{
Server svr; // 服务器对象
}1.首先,服务器需要提供获取题目列表的路由。用户获取数据,自然是Get方法,规定/all_questions即访问题目列表。
// 1.用户获取题目列表数据
svr.Get("/all_questions", [&ctl](const Request& req, Response& resp){
// 扩至模块返回后构建渲染网页返回resp
});2.其次,服务器需要提供获取单个题目的路由。因为是单个题目,那么需要获取到题目编号,需要引入正则表达式获取:(\d+),利用请求对象的matches[1]可以获取。因为字符串中存在了反斜杠,可以利用R"()"-C++11的特性转换为原始字符串不至于解析为\d。/one_question/(\d+)
// 2.用户获取单题题目内容
svr.Get(R"(/question/(\d+))", [&ctl](const Request& req, Response& resp){ // (\\d+是正则表达式)
std::string number = req.matches[1]; // 1对应的就是获取正则表达式中的内容
// 控制模块返回结果构建渲染单个题目的网页返回resp
});3.最后,用户需要判题功能,就要利用到judge,也需要题目编号,因为是提交代码获取结果,应该是有Post方法:/judge/(\d+)
// 3.用户获取单体解析结果
svr.Post(R"(/judge/(\d+))", [&ctl](const Request& req, Response& resp){
std::string number = req.matches[1]; // 1对应的就是获取正则表达式中的内容
// 控制模块返回结果的json串,返回给resp
});5.设置根目录,其中index.html为首页网页,并且添加服务器的ip和端口,默认定死为0.0.0.0和8080。(端口可以自行设置哦,不冲突即可)
// 设置根目录
svr.set_base_dir("./wwwroot");
// 监听全体网卡,端口号固定8080
svr.listen("0.0.0.0", 8080);oj_model模块编写
用户需要的自然是题目数据,那么我们首先应该将数据存储的地方先弄好。
数据存储我们设计两个版本,一个文件版本,一个mysql数据库版本。对应不同的版本model数据交互细节不一样(文件操作/CPP-mysql connect),但是接口一致。
题目信息设置
在谈版本之前,我们先谈谈题目需要什么信息,并且如何进行判题。
在常见的oj中,我们经常见到题目提供给我们一部分代码,我们只需要在这里补全即可。比如如下的示例:
class UnusualAdd {
public:
int addAB(int A, int B) {
}
};比如另类加法(即叫你不使用+完成A和B的相加)oj中,用户只需要在这里面编写代码即可。那么如何判题呢?
我们知道,一个C/C++程序运行,首先会找到main函数入口,那么我们的判题就可以在此处编写测试用例运行不就好了嘛:
#ifndef COMPILE_ONLINE
#include "header.cpp" // 条件编译,引入头文件只是为了不报错和语法提示,之后会进行拼接
#endif
void test1(UnusualAdd& use1)
{
// 测试用例1
int sum = use1.addAB(1, 1);
if (sum == 2)
{
cout << "测试用例1通过!" << endl;
}
else cout << "测试用例1没有通过"<< "1 + 1" << endl;
}
void test2(UnusualAdd& use2)
{
// 测试用例2
int sum = use2.addAB(1, -1);
if (sum == 0)
{
cout << "测试用例2通过!" << endl;
}
else cout << "测试用例2没有通过" << "1 + (-1)" << endl;
}
int main()
{
UnusualAdd ues;
test1(ues);
test2(ues);
return 0;
}加入条件编译就是为了编写的时候不会出现报错(两个文件,注意编译运行模块编译的时候加上-D选项将include去掉)。上面只是粗略的展示,真实的测试用例编写过程复杂的很多。
所以,在后端逻辑控制的时候,只需要将用户编写的code数据和上面的测试用例数据拼接到一起就形成了一份完整的代码发送给编译运行服务器进行判题功能了。
题目还存在空间、时间限制,以及题目编号、题目标题、难度、描述等设置。
题目信息:
1.题目编号 number
2.题目标题 title
3.题目难度 star
4.题目描述 desc
5.时间、空间要求 cpu_limit mem_limit
6.用户提交代码 header
7.测试用例代码 tail
v1.文件版本
首先再oj_server目录下建好questions目录。
根据题目细节信息,我们每个题目是需要多份文件的:一份题目描述、两份cpp文件的(header和tail),那么我们需要一份question.list 每一行保存一个题目的编号、标题、难度、时间空间要求,以及存放对应题目三个文件的目录路径。
比如:
#编号 名称 难度 cpu mem 路径(相对路径为oj_server,不在此目录下请带全路径) question.list
1 另类加法 简单 3 40000 ./questions/1
2 把字符串转换为整数 简单 1 70000 ./questions/2
注意上面的时间限制单位为s,空间限制为kb(转换为mb可以在渲染网页view模块去做,也可以直接在描述文件中进行描述)。
而一个./question/1的结构如下:

这样一个题目的信息我们就录好了。等待model的数据交互。
model我们需要向外提供题目的信息,那么我们可以设计一个question的结构体,里面存放的就是题目的细节信息,总共8个。然后再创建此对象的时候,我们根据question.list的路径读取上来,通过ReadFile-先前提供的读取文件的接口读取另外三份文件。只不过需要注意读取配置文件的时候按行读取需要进行分割,直接写的话也能写,较为麻烦,我们可以使用boost开发库(C++准标准库)进行字符串切割。
读取完题目信息后我们利用哈希map根据题目编号进行存储(方便后续单个题目的取出)。存储完后向外提供all_question接口,外部传入vector数组进行保存(外部可以利用此进行排序);one_question接口。获取的单个对象均为question对象,方便取出其中的题目信息。
-common/util.hpp boost库spilt函数的使用
因为是字符串切割,我们放在StringUtil字符串工具类下:
关于boost库的安装:sudo yum install -y boost-devel; 头文件路径为<boost/algorithm/string.hpp>
// 字符串相关工具类
class StringUtil
{
public:
// 切割字符串,保存入vector中
static void SpiltString(const std::string& src, std::vector<std::string>& target, std::string op)
{
boost::split(target, src, boost::is_any_of(op), boost::algorithm::token_compress_on); // 数组、遇到对应分隔符全部切割 压缩(切割出来的空串删除)
}
};-oj_server/oj_model_file.hpp 文件版本model编写
#ifndef __OJ_MODEL_HPP__
#define __OJ_MODEL_HPP__
// OJ题库与数据交互
#include <iostream>
#include <unordered_map>
#include <string>
#include <fstream>
#include <cstring>
#include "../common/util.hpp"
#include "../common/log.hpp"
// 文件版本
namespace ns_model
{
using namespace ns_util;
using namespace ns_log;
// 每一个题目独享的内存细节
struct Question
{
std::string number; // 题目编号
std::string title; // 题目标题
std::string star; // 题目难度
int cpu_commit; // 运行时间限制S
int mem_commit; // 内存占用限制KB
std::string desc; // 文件描述
std::string header; // 用户预设代码
std::string tail; // 测试代码
};
class Model
{
const std::string questions_path = "./questions/question.list";
private:
std::unordered_map<std::string, Question> _map;
public:
Model()
{
// 题库信息加载入内存
assert(LoadQuestionlist(questions_path));
}
~Model()
{}
// 开始加载题库入内存
bool LoadQuestionlist(const std::string& path) // 题库文件questions的路径
{
std::ifstream in(path);
if (!in.is_open())
{
// 此时致命错误-影响全部,检查文件路径
LOG(FATAL) << "题库配置文件未能打开,请检查相关路径或者文件是否存在" << "\n";
return false;
}
std::string line;
while (std::getline(in, line))
{
if (line[0] == '#') continue; // 注释行跳过
// 对于配置的一行,我们需要进行字符串分割
std::vector<std::string> target;
StringUtil::SpiltString(line, target, " ");
if (target.size() != 6)
{
// 此时当前配置行存在误输,警告
LOG(WARING) << line[0] << "编号配置文件出错" << "\n";
continue;
}
Question q;
q.number = target[0];
q.title = target[1];
q.star = target[2];
q.cpu_commit = atoi(target[3].c_str());
q.mem_commit = atoi(target[4].c_str());
q.desc = FileUtil::ReadFile(target[5] + "/desc.txt", true);
q.header = FileUtil::ReadFile(target[5] + "/header.cpp", true);
q.tail = FileUtil::ReadFile(target[5] + "/tail.cpp", true);
if (q.desc == "" || q.header == "" || q.tail == "")
{
// 当前记录文件读取失败!或者无记录,那么就无效,不纳入统计
LOG(WARING) << "检查编号" << line[0] << "文件目录下文件是否录入成功或者填写信息" << "\n";
LOG(DEBUG) << target[5] << "\n";
continue;
}
_map[target[0]] = q; // 保存记录
}
in.close();
LOG(INFO) << "题库录入内存成功!" << "\n";
return true;
}
// 获取当前题目列表信息
bool GetAllQuestions(std::vector<Question>& v)
{
if (_map.empty())
{
// 当前内存题目信息为空,获取失败
LOG(ERROR) << "当前用户获取题目信息失败,内存中不存在题目信息记录" << "\n";
return false;
}
for (auto& s : _map)
{
v.push_back(s.second);
}
return true;
}
// 获取单个题目信息,给我number
// 已经提供日志差错处理
bool GetOneQuestion(const std::string& number, Question& q)
{
auto it = _map.find(number);
if (it == _map.end())
{
// 提供的number不存在当前题库中
LOG(ERROR) << "当前用户获取题目信息失败,内存中不存在此题目信息记录" << "\n";
return false;
}
q = it->second;
return true;
}
};
}
#endifv2.mysql数据库版本
数据库版本就非常简单了。我们确定需要存储的题目信息一共八个。
首先,我们需要给oj_server进行数据库连接创建一个用户(用户管理),然后利用root创建数据库oj,给创建的用户进行赋权创建表结构,录入数据,程序便就可以进行连接操作编写model模块了。
1.mysql创建授权用户、建库建表录入操作:
create user 'oj_client'@'%' identified by '123456'; --创建用户,任意ip登录,密码
--root建库
create database oj;
--root赋权
grant all on oj.* to 'oj_client'@'%'; -- 赋予oj_clinet@%用户oj数据库的所有权限
--创建question表,表结构设计出来
use oj;
create table oj_questions(
number int primary key auto_increment comment '题目的编号',
title varchar(128) not null comment '题目的标题',
star char(2) not null,
`desc` text not null comment '题目的描述',
header text not null comment '预设给用户看的代码',
tail text comment '对应题目的测试用例代码',
cpu_limit int default 1 comment '对应题目的时间限制',
mem_limit int default 50000 comment '对应题目的最大空间'
)engine=innoDB default charset=utf8;录入我们可以利用insert,但是大文本录入太麻烦了,我们可以借助可以连接mysql的第三方工具,我这里以Navicat Premium 16为例:
2.mysql connect cpp操作
当我们数据录入成功后,model模块想要获取数据就必须让C++/C程序能够连接上mysql数据库。
我们需要访问网站MySQL :: Download MySQL Connector/C (Archived Versions)下载mysql的数据开发包:

下载到本地后上传至云服务器解压,会存在include文件和lib文件分别存放的是头文件和库文件。头文件可放入系统路径下:/user/include,库文件放入:/lib64/下即可。放入系统路径的话记得编译带上选项 -lmysqlclient。当然,也可以不用cp到系统路径下,可以利用软连接ln -s链接到oj_server目录下即可,之后编译指明-I(头文件路径)-L(库文件路径)即可。
mysql连接编码很简单,首先创建mysql句柄,然后根据数据库用户、信息、数据库进行数据库连接,连接成功后mysql_query执行sql命令返回结果,对结果进行解析提取数据即可。需要注意差错处理:
-oj_server/oj_model_mysql.hpp mysql数据库版本model编写
#ifndef __OJ_MODEL_HPP__
#define __OJ_MODEL_HPP__
// OJ题库与数据交互
#include <iostream>
#include <unordered_map>
#include <string>
#include <fstream>
#include <cstring>
#include "./mysql-connect/include/mysql.h"// 引用c-mysql-connect
#include "../common/util.hpp"
#include "../common/log.hpp"
// mysql版本
namespace ns_model
{
using namespace ns_util;
using namespace ns_log;
// 每一个题目独享的内存细节
struct Question
{
std::string number; // 题目编号
std::string title; // 题目标题
std::string star; // 题目难度
int cpu_commit; // 运行时间限制S
int mem_commit; // 内存占用限制KB
std::string desc; // 文件描述
std::string header; // 用户预设代码
std::string tail; // 测试代码
};
const std::string oj_table_name = "oj_questions";
const std::string oj_host = "自己的公网ip";
const std::string oj_user = "oj_client";
const std::string oj_password = "123456";
const std::string oj_db = "oj";
const unsigned int oj_port = 3306;
class Model
{
public:
Model()
{}
~Model()
{}
// 执行sql语句处
bool QueryMySql(const std::string& sql, std::vector<Question>& v)
{
// c连接mysql库,创建mysql对象-初始化mysql句柄
MYSQL* oj_client = mysql_init(nullptr);
// 连接数据库,连接失败返回nullptr
if (nullptr == mysql_real_connect(oj_client, oj_host.c_str(), oj_user.c_str(), oj_password.c_str(), oj_db.c_str(), oj_port, nullptr, 0))
{
// 表示连接数据库失败
LOG(FATAL) << "数据库连接失败!请尽快联系数据库管理员....." << "\n";
return false;
}
// 连接成功后先执行编码格式
mysql_set_character_set(oj_client, "utf8");
// 连接成功后执行语句
int result = mysql_query(oj_client, sql.c_str());
if (result != 0)
{
// 执行失败
LOG(WARING) << "当前sql执行失败: " << sql << " \n";
return false;
}
// 执行成功,提取数据
MYSQL_RES* res = mysql_store_result(oj_client);
// 解析数据
int rows = mysql_num_rows(res); // 获取行数
int fields = mysql_num_fields(res); // 获取列数
// 读取每一个元组,提取每一个元组的九个属性
for (int i = 0; i < rows; ++i)
{
MYSQL_ROW line = mysql_fetch_row(res);
Question q;
q.number = line[0];
q.title = line[1];
q.star = line[2];
q.cpu_commit = atoi(line[3]);
q.mem_commit = atoi(line[4]);
q.desc = line[5];
q.header = line[6];
q.tail = line[7];
v.push_back(q);
}
// LOG(DEBUG) << "正常访问数据库成功..." << "\n";
return true;
}
// 获取当前题目列表信息
bool GetAllQuestions(std::vector<Question>& v)
{
std::string sql = "select * from ";
sql += oj_table_name;
return QueryMySql(sql, v);
}
// 获取单个题目信息,给我number
// 已经提供日志差错处理
bool GetOneQuestion(const std::string& number, Question& q)
{
std::string sql = "select * from ";
sql += oj_table_name;
sql += " where number=";
sql += number;
std::vector<Question> v;
if (QueryMySql(sql, v))
{
if (v.size() == 1)
{
// 只能存在一个记录
q = v[0];
return true;
}
}
return false;
}
};
}
#endifoj_control模块编写
oj_control逻辑控制是oj_server中的核心。http请求中的路由通过control模块完成对应的功能。
根据路由信息,我们首先是需要能够获得题库并且构建渲染成网页的功能,由control-allquestions提供;其次我们也需要获得单个题目并且构建渲染成网页的功能;最后能够通过用户上传的json串完成判题的功能返回结果json串。
model功能我们已经完成了,view功能基本属于前端功能,后续简单介绍即可。control更多的是将这两种联合控制起来,完成逻辑控制。
1.获取题库
model中已经为我们提供了获取整个题目的方法,对象为Question,只需要传入一个vector即可。我们利用其传入view中的题库渲染方法(AllExpandHtml),获取渲染后的网页返回,由http发送给客户端(浏览器渲染)。
需要注意的点就是原本获取的题目可能没有排序,我们利用sort函数根据question中的number转换为数字进行排序即可。
-oj_server/oj_control.hpp 获取题库渲染网页返回
namespace ns_contol
{
class Control
{
private:
Model _model; // 数据对象
View _view; // 渲染对象
public:
Control()
{}
~Control()
{}
// 从题库中获取题目信息(model),渲染成网页返回(view)
bool AllQuestions(std::string& html)
{
std::vector<Question> v;
if (_model.GetAllQuestions(v))
{
// 对数组进行排序
std::sort(v.begin(), v.end(), [](Question& q1, Question& q2){
return atoi(q1.number.c_str()) < atoi(q2.number.c_str());
});
// 成功,根据获取的信息渲染网页
_view.AllExpandHtml(v, html); // 后面完成
return true;
}
else
{
// 获取题目列表失败
return false;
}
}
}
}在对应oj_server.hpp 获取题库路由就可以这样调用控制模块:(注意返回网页格式的类型)
// 1.用户获取题目列表数据
svr.Get("/all_questions", [&ctl](const Request& req, Response& resp){
std::string html;
ctl.AllQuestions(html);
resp.set_content(html, "text/html;charset=utf8");
});2.获取单个题目
model也为我们提供了获取单个题目的方法,只需要接收Question对象即可,并且传入view模块渲染出单个题目网页(OneExpandHtml),返回网页信息即可。
-oj_server/oj_control.hpp 获取单个题目渲染网页返回
// 根据题目编号获取单个题目细节信息,渲染成网页进行返回
bool OneQuestion(const std::string& number, std::string& html)
{
Question q;
if (_model.GetOneQuestion(number, q))
{
// 成功,根据题目文件渲染为网页
_view.OneExpandHtml(q, html);
return true;
}
else
{
// 查无此物
return false;
}
}在对应oj_server.hpp 获取单个题目路由就可以这样调用控制模块:(注意返回网页格式的类型)
// 2.用户获取单题题目内容
svr.Get(R"(/question/(\d+))", [&ctl](const Request& req, Response& resp){ // (\\d+是正则表达式)
std::string number = req.matches[1]; // 1对应的就是获取正则表达式中的内容
std::string html;
ctl.OneQuestion(number, html);
resp.set_content(html, "text/html;charset=utf8");
});3.判题
判题是整个项目中较为核心的一块,也是前后端进行联动的地方。首先,用户通过json格式提交上来的代码数据需要获取上来,然后需要通过编译运行服务执行结果,得到结果后构建json串返回结果。
1.那么首先需要定义用户上传的json数据。因为判题路由存在题目编号,那么用户上传的也只有用户编辑后的代码code以及input数据。由于用户测试运行模块属于扩展内容,这里就先将input代码忽视。我们将code和对应题目的tail文件进行凭借组成一份完整代码,在加上题目的空间以及时间限制(编译服务需要的四份属性)组成一份json数据准备发送给编译运行服务。
// 用户通过浏览器上传的json数据
{
"code": code,
"input": ,
}
// 凭借好准备发送给compile_server的json串数据
{
"code": code+q.tail,
"input": ,
"cpu_limit": q.cpu_limit,
"mem_limit": q.mem_limit,
}
// 注意上面的q为Question对象,根据路由传上来的题目编号决定,通过model模块获取2.我们要确定好发送给哪台编译服务主机。 因为业务众多,不可能存在一台编译运行服务主机(负载压力太大),我们设计为网络服务的原因也就是能在不同的主机上部署此服务,方便于oj_server进行选择。
为了减轻压力,我们使用负载均衡的模式进行主机选择。那么我们首先得定义主机对象,并且根据主机的配置文件加载当前的所有主机信息,方便我们进行调用。
-主机对象
Machine的设计。一个网络服务器,我们想向其访问就需要知道其的ip和port。除此之外,为了便于后续的负载均衡选择,我们需要设置属性当前的负载均衡个数。需要注意的是,因为同一时刻存在不同的执行流执行判题功能(http网络服务),为了保证线程安全,我们需要一把互斥锁,保证负载数的访问和修改安全。可以利用C++中的mutex进行定义,需要注意的是mutex在C++中无法进行拷贝,所以需要定义为指针类型。
为了设计为线程安全,我们需要对外提供线程安全的访问负载均衡数,++负载均衡、--负载均衡、以及清空负载。
-oj_server/oj_control.hpp 主机对象设计
class Machine
{
public:
std::string ip; // 编译服务主机ip
uint16_t port; // 编译服务主机端口
private:
uint64_t _load; // 当前主机负载 - 使用个数
std::mutex* _mtx; // 当前主机锁,保护对负载数的安全
public:
// 构造一个主机对象,给定ip和port。为之后的连接编译服务做准备
Machine(const std::string& ip_ = "", uint16_t port_ = 0)
:ip(ip_), port(port_), _load(0), _mtx(nullptr)
{
if (ip_ != "" && port_ != 0) _mtx = new std::mutex();
}
~Machine()
{}
// 对负载进行递增 - 可能存在多个对象对此主机对象进行操作,必须保证原子性
void IncLoad()
{
if (_mtx)
{
_mtx->lock();
++_load;
_mtx->unlock();
}
}
// 对负载进行递减
void DecLoad()
{
if (_mtx)
{
_mtx->lock();
--_load;
_mtx->unlock();
}
}
// 获取当前主机负载
uint64_t Load()
{
uint64_t load = 0;
if (_mtx)
{
_mtx->lock();
load = _load;
_mtx->unlock();
}
return load;
}
// 清空当前负载
void ClearLoad()
{
if (_mtx)
{
_mtx->lock();
_load = 0;
_mtx->unlock();
}
}
};-负载均衡选择
当有了主机对象后,我们需要通过主机配置获取当前的所有主机。配置文件放在oj_server/conf/文件夹下,名字设为server_machine.conf。配置样式如下:
127.0.0.1:8081
127.0.0.1:8082
.....
那么编写负载均衡模块的时候,首先根据conf文件的路径进行读入,然后按行读取-利用util工具中的字符串切割工具,切割符为":"进行切分读取即可。
所有主机对象都放在一个vector中(注意,是所有conf配置中的主机对象)。但是并不是意味着只要配置的有这台主机,这台主机就一定在线。所以,我们需要额外的设置两个数组,分别保存在线主机对象和离线主机对象。负载均衡模块提供离线主机接口(传入需要离线的主机对象),因为上层负载均衡调用此主机如果得不到结果说明可能离线了,加入离线数组即可。上线主机我们策划手动全部上线,利用信号3执行-ctrl \。(oj_server捕捉信号3,利用signal接口设置函数即可)一开始默认全部上线,后续负载均衡选择中在逐步淘汰不在线上的主机。
另外,在线主机和离线主机数组只需要存放保存所有主机数组的下标即可,每个下标就唯一确定一台主机,这样可以节省内存空间。
负载均衡的策略也很简单,从当前的在线的主机进行轮询选择,遍历保存当前数组中最小的负载数的主机,最后返回即可。
-oj_server/oj_control 负载均衡选择主机
// 负载均衡模块
class LoadBlance
{
const std::string confPath = "./conf/server_machine.conf";
private:
std::vector<Machine> _machines; // 存放全体主机对象的地方, 包括离线和在线的主机,下标对应主机编号
std::vector<int> _online; // 存放在线主机的地方
std::vector<int> _offline; // 存放离线主机的地方
std::mutex _mtx;// 保证在智能选择或者对数据查询时出现不可重入,保证负载均衡数据安全
public:
LoadBlance()
{
assert(LoadConf(confPath));
LOG(INFO) << "编译服务主机配置设置成功..." << "\n";
}
~LoadBlance(){}
// 加载编译服务主机入内存
bool LoadConf(const std::string& path_conf)
{
std::ifstream in(path_conf);
if (!in.is_open())
{
LOG(FATAL) << "加载主机配置文件失败, 请检查server_machine.conf文件的相关配置路径..." << "\n";
return false;
}
std::string line; // 一行一行的读取
while(std::getline(in, line))
{
std::vector<std::string> machines;
StringUtil::SpiltString(line, machines, ":");
if (machines.size() != 2)
{
LOG(WARING) << "当前行配置文件出错:" << line << "...\n";
continue;
}
Machine m(machines[0], atoi(machines[1].c_str()));
// 先加载入在线主机数组
_online.push_back(_machines.size());
_machines.push_back(m);
}
in.close();
return true;
}
// 负载均衡选择,轮询查询,找到当前负载最小的编译服务主机
// 参数id为主机编号,m为主机对象,均为输出型参数
bool SmartChoice(int& id, Machine** m)
{
_mtx.lock();
// 首先检测当前主机是否存在在线
if (_online.size() == 0)
{
// 此时没有一台主机在线
_mtx.unlock();
LOG(FATAL) << "请检查后端编译服务主机,当前没有一台在线!..." << "\n";
return false;
}
// 轮询查询
id = _online[0];
*m = &_machines[_online[0]];
uint64_t min_load = _machines[_online[0]].Load();
for (int i = 1; i < _online.size(); ++i)
{
uint64_t load = _machines[_online[i]].Load();
if (min_load > load)
{
id = _online[i];
*m = &_machines[_online[i]];
min_load = load;
}
}
_mtx.unlock();
return true;
}
// 离线指定id主机
void OfflineMachine(int which)
{
// 操作数据的时候,避免线程安全问题,加锁
_mtx.lock();
// 从在线列表中退出,加入离线列表
for (auto it = _online.begin(); it != _online.end(); ++it)
{
if (*it == which)
{
// 找到了,退出online,加入offline
_online.erase(it); // 注意删除后存在迭代器失效问题
_offline.push_back(which); // 添加即可
break;
}
}
_machines[which].ClearLoad(); // 离线清空负载情况
_mtx.unlock();
}
// 上线主机
void OnlineMachine()
{
// 上线主机默认全部上线
_online.insert(_online.end(), _offline.begin(), _offline.end());
_offline.clear(); // 清空
LOG(INFO) << "当前主机全部上线!" << "\n";
}
// debug 展示当前在线主机和离线主机 - compile_run server服务
void ShowMachines()
{
// 访问数据上锁访问哦
_mtx.lock();
std::cout << "当前在线主机id: ";
for (auto i : _online)
{
std::cout << i << " ";
}
std::cout << std::endl;
std::cout << "当前离线主机id: ";
for (auto i : _offline)
{
std::cout << i << " ";
}
std::cout << std::endl;
_mtx.unlock();
}
};现在,上面几个小组件写完后我们就可以进行我们的判题模块。
根据用户的输入,获取题目编号、构建好向编译服务发送的json串,利用负载均衡模块,选择当前负载均衡最小的主机(由于回出现请求失败的情况,我们将选择设置为死循环,直到主机全部下线或者发送成功在退出)。利用cpp-httplib中的client对象发送Post方法,注意格式,并且判断返回的响应对象是否是200成功。别忘了还需要向上层提供全部上线主机功能(上层对LoadBlance透明)。
// 重新上线主机
void AllOnLineMachine()
{
_load_blance.OnlineMachine();
}
/******************************
* 判题功能judge
* 1.number 题目编号
* 2.in_json 用户提交的json串,包含写过的code代码、以及input输入
* 3.out_json 最后返回给调用的串,结果为compile_run服务的结果 - 输出型参数
* 本模块根据配置文件负载均衡选择后端的compile_run服务,实现oj功能
*******************************/
void Judge(const std::string& number, const std::string& in_json, std::string& out_json)
{
// LOG(DEBUG) << in_json << "\n";
Question q;
if (!_model.GetOneQuestion(number, q)) return;
// 待提交给后端编译服务的json串
std::string result_json;
// 1.反序列化
Json::Value in;
Json::Reader read;
read.parse(in_json, in);
// 2.现在开始序列化 根据题目细节和用户提交的code拼接给后端编译服务提交的json串
Json::Value out;
Json::FastWriter write;
// 后续测试运行会有扩展
out["code"] = in["code"].asString() + "\n" + q.tail; // 拼接代码
out["input"] = in["input"].asString();
out["cpu_limit"] = q.cpu_commit;
out["mem_limit"] = q.mem_commit;
result_json = write.write(out);
// 3. 负载均衡模块,选择一台服务主机进行发送,接收消息
// 因为存在选择一台主机发送消息可能得不到消息,所以决定循环式的发送消息,直到主机全部挂掉或者得到消息为止
while(true)
{
int machine_id;
Machine* m = nullptr;
if (!_load_blance.SmartChoice(machine_id, &m)) break; // 此时全体挂掉了
// 发起http请求
httplib::Client cli(m->ip, m->port);
// 注意,请求是需要时间的并且是阻塞式的,同时间内可能会来多个请求,那么需要怎加负载进行访问
m->IncLoad();
LOG(INFO) << "主机编号为:" << machine_id << " 详细信息ip:" << m->ip << " port:" << m->port << " 当前负载:" << m->Load() << "\n";
if (auto res = cli.Post("/compile_and_run", result_json, "application/json;charset=utf-8")) // 注意res重载了bool,如果没有返回一个响应对象会显示false
{
// 得到响应了
// 先判断是不是正确的响应
if(res->status == 200)
{
out_json = res->body; // post json串在body内
m->DecLoad(); // 别忘了减少负载
LOG(INFO) << "请求编译运行服务成功..." << "\n";
break;
}
}
else
{
// 没有得到响应,说明此服务器可能挂掉了,加载入离线主机
m->DecLoad();
LOG(ERROR) << "主机编号:" << machine_id << "详细信息ip:" << m->ip << " port:" << m->port << "可能已经离线....." << "\n";
_load_blance.OfflineMachine(machine_id);
_load_blance.ShowMachines();
}
}
}oj_view模块编写
根据后端oj_control中,view我们需要构建以及渲染的网页有all_questions题库网页,one_question单个题目网页,外加补充的index网页。(补充的只是编写网页,和view逻辑控制无关)
因为需要将后端数据和网页进行一个渲染(即将数据显示到网页中去),我们需要利用到ctemplate库。这是谷歌开源的网页渲染器,能够帮助我们将数据渲染到网页上去。
ctemplate库的配置和使用
ctemplate库的下载:
访问网页:https://gitee.com/mirrors_OlafvdSpek/ctemplate?_from=gitee_search
可选择克隆或者选择压缩包下载:
克隆方法:git clone https 复制内容
下载完成后通过如下方法进行配置:
./autogen.sh
./configure
make 编译即可
sudo make install 安装到系统中注意,make编译可能出错,当初博主实在网上搜索解决的,遇到问题请自行搜索。
ctemplate的简单使用:
头文件:#include <ctemplate/template.h>、
编译选项:-lctemplate
首先需要明确渲染实际上就是网网页上填充数据。我们为什么需要渲染?向题库界面填充题目信息,单个题库界面填充题目描述,用户代码等。
在网页中<p>{{key}}</p>,key就是待渲染的对象。
在编码中,TemplateDict root("test"); // 创建数据字典 此数据字典名字为test,名字自己随便起,字典是key-value类型,key就是在html中的待渲染对象名,root.SetValue("key", value); // 插入字典,即将key替换为value完成渲染。
通过ctemplate::Template *tql = ctemplate::Template::GetTemplate(网页路径, 保持原貌:ctemplate::DO_NOT_STRIP); // 保持原貌,打开html,
string out_html;
tql->Expand(&out_html, &root); // 完成了渲染。添加入html中,完成渲染,得到渲染网页数据out_html,view返回结果即可。

利用ctemplate,view模块依次对题库网页、单个题目网页根据传入的数据渲染即可。针对于网页模板,因为涉及前端的知识,这里不在过多赘述,在仓库中自行参考。(存在扩展内容,结合后面一同食用效果更佳)
-oj_server/oj_view.hpp 网页渲染
#ifndef __OJ_VIEW_HPP__
#define __OJ_VIEW_HPP__
// OJ题目渲染网页
#include <iostream>
#include <vector>
#include <ctemplate/template.h>
// #include "oj_model_file.hpp"
#include "oj_model_mysql.hpp"
namespace ns_view
{
using namespace ns_model;
class View
{
const std::string template_path = "./template_html/";
public:
View(){}
~View(){}
// 渲染题目列表网页
// 保存题目列表的数组 + 待返回的渲染网页
void AllExpandHtml(const std::vector<Question>& questions, std::string& html)
{
// 1.模板网页路径
std::string path = template_path + "all_questions.html";
// 2.形成数据字典
ctemplate::TemplateDictionary root("all_questions");
// 循环渲染一部分网页表格,设定子字典
for (auto& q : questions)
{
ctemplate::TemplateDictionary* td = root.AddSectionDictionary("question_list"); // 在模板网页中需要{{#名字}}
td->SetValue("number", q.number);
td->SetValue("title", q.title);
td->SetValue("star", q.star);
}
// 3.获取待渲染网页
ctemplate::Template* tql = ctemplate::Template::GetTemplate(path, ctemplate::DO_NOT_STRIP);
// 4.渲染网页返回
tql->Expand(&html, &root);
}
// 渲染单题目网页
// 单题目数据结构 + 待返回的渲染网页
void OneExpandHtml(const Question& q, std::string& html)
{
std::string path = template_path + "one_question.html";
ctemplate::TemplateDictionary root("one_question");
root.SetValue("number", q.number);
root.SetValue("title", q.title);
root.SetValue("star", q.star);
std::string str = std::to_string((q.cpu_commit * 1.0));
root.SetValue("cpu", str.substr(0, str.find(".") + 3));
str = std::to_string(q.mem_commit * 1.0 / 1024);
root.SetValue("mem", str.substr(0, str.find(".") + 3));
root.SetValue("desc", q.desc);
root.SetValue("pre_code", q.header);
ctemplate::Template* tql = ctemplate::Template::GetTemplate(path, ctemplate::DO_NOT_STRIP);
tql->Expand(&html, &root);
}
};
}
#endiftemlate_html网页模板:temlate_html-题库页面+单个题目页面
(注意其中链接的css文件以及js文件在wwwroot下:wwwroot)
补充index首页网页:index.html
-oj_server/makefile 顶层makefile的编写
当前项目可以告别一段时间了,但是我们还可以设计一个顶层makefie,方便发布时的使用。
其作用就是可以分别编译oj_server、compile_server,并且生成一个output将必要的文件拷贝出来,删除的时候将所有新增的文件删除掉。
.PHONY:all
all:
@cd compile_server;\
make;\
cd -;\
cd oj_server;\
make;\
cd -;
.PHONY:output
output:
@mkdir -p output/oj_server;\
mkdir -p output/compile_server;\
cp -rf ./oj_server/oj_server output/oj_server;\
cp -rf ./oj_server/conf output/oj_server;\
cp -rf ./oj_server/mysql-connect/lib output/oj_server;\
cp -rf ./oj_server/questions output/oj_server;\
cp -rf ./oj_server/template_html output/oj_server;\
cp -rf ./oj_server/wwwroot output/oj_server;\
cp -rf ./compile_server/compile_server output/compile_server;\
cp -rf ./compile_server/temp output/compile_server;
.PHONY:clean
clean:
@cd compile_server;\
make clean;\
cd -;\
cd oj_server;\
make clean;\
cd -;\
rm -rf output;3.扩展内容
增加测试运行
在之前的项目中并没有增加测试运行功能,但是接口已经留好了。前端编写对应的界面后,control模块还是走正常的判题功能,只不过此时返回的json串中新增一种属性test_input类型为bool,如果是那么说明是自测功能。
自测说白了就是输入用户自己的测试数据,在运行环境中就是cin的内容。在运行模块中我们已经将input重定向到了标准输入模块了,也就是说到运行模块,cin中以及存放用户的输入数据了,我们只需要新增一种类型的拼接代码,就是while循环调用cin去输入数据,然后传入用户设置的方法中返回结果输出到stdout中一样的返回结果即可。
所以新增的拼接代码可以如下所示:test_input.cpp
#ifndef COMPILE_ONLINE
#include "header.cpp" // 条件编译,引入头文件只是为了不报错和语法提示,之后会进行拼接
#endif
#include <iostream>
int main()
{
UnusualAdd ues;
int a, b;
while (cin >> a >> b)
{
cout << ues.addAB(a, b) << "\n";
}
return 0;
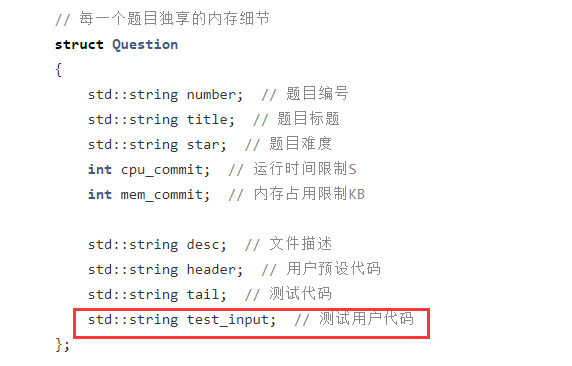
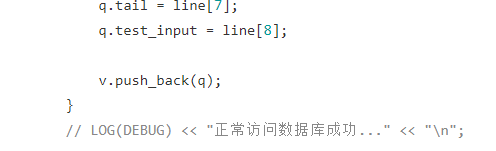
}文件版本题库中添加对应文件到对应文件下,并且model中读取即可,数据库同理,修改表结构,添加即可。
下面展示数据库的修改部分:oj_server/ oj_model_mysql.hpp
对于逻辑控制control上,只需要判断是否自测还是正常提交,拼接不同的代码即可,其余的都不用改。oj_server/oj_control.hpp

增加登录模块
登录模块前端设置为弹窗(详情可查看index、one_question、all_questions任意一份html)。
因为是新的模块,我将oj_server设置了新的路由/user。control模块对应增加oj_user.hpp。实际上,用户管理,实际上就是保存一堆的用户在数据库或者文件中(这里我使用mysql数据库完成),登录的时候使用sql语句查询表是否存在或者密码是否正确,注册的时候insert语句插入查看是否id冲突或者密码设置有误。
我在mysql的oj数据库中新增了一种表oj_user。其中属性为id、password。注意其中password存储的是经过password函数形成的数据摘要,所以密码设置格式完全可以由数据库决定,后端我们不需要自己在进行设定了。而oj_user用户管理和oj_model_mysql类似,都是链接数据库,要么获取用户,要么注册用户,获取用户就执行select语句,插入就执行insert语句,失败返回对应的json数据-定义状态和描述。前端提交的也是json数据(利用表格获取数据,提交json结果)。
当前实现的登录模块没有完全,知识提供了登录检测,注册用户,登录成功后只是网络提醒,没有过多的进行处理。
-oj_server/oj_user.hpp 登录管理
#ifndef __OJ_USER_HPP__
#define __OJ_USER_HPP__
// 用户管理模块
#include <string>
#include <unordered_map>
#include "./mysql-connect/include/mysql.h"// 引用c-mysql-connect
#include "../common/log.hpp"
namespace ns_user
{
using namespace ns_log;
// 用户模块 先将数据库中存在的所有用户缓存到内存中来,这样每次就不需要访问数据库了
struct UserObject
{
std::string id; // 用户账号
std::string password; // 用户密码
bool root = false; // 用户管理权限 默认不是
};
const std::string oj_table_name = "oj_questions";
const std::string oj_host = "43.143.4.250";
const std::string oj_user = "oj_client";
const std::string oj_password = "123456";
const std::string oj_db = "oj";
const unsigned int oj_port = 3306;
class User
{
public:
User()
{}
~User()
{}
// 1 数据库连接失败
// 2 执行结果报错 -注意select 查找不到不会报错
int QueryMySqlResult(const std::string& sql, MYSQL_RES*& res)
{
// c连接mysql库,创建mysql对象-初始化mysql句柄
MYSQL* oj_client = mysql_init(nullptr);
// 连接数据库,连接失败返回nullptr
if (nullptr == mysql_real_connect(oj_client, oj_host.c_str(), oj_user.c_str(), oj_password.c_str(), oj_db.c_str(), oj_port, nullptr, 0))
{
// 表示连接数据库失败
LOG(FATAL) << "数据库连接失败!请尽快联系数据库管理员....." << "\n";
return 1;
}
// 连接成功后先执行编码格式
mysql_set_character_set(oj_client, "utf8");
// 连接成功后执行语句
int result = mysql_query(oj_client, sql.c_str());
if (result != 0)
{
// 执行失败 sql语句的错误
// LOG(WARING) << "sql语句存在错误:" << sql << "\n";
return 2;
}
// 执行成功,提取数据
res = mysql_store_result(oj_client);
// 上层解析数据
return 0;
}
// 0-查找成功,存在此用户
// 1-内部错误
// 2-用户名错误或不存在
// 3-密码错误
// 4-权限错误 测试
int FindUser(const std::string& user_name, const std::string& password)
{
MYSQL_RES* res1 = nullptr;
if (user_name == "") return 2; // 为空
std::string sql = "select * from oj_user where id='" + user_name + "';";
if(0 != QueryMySqlResult(sql, res1)) return 1;
MYSQL_ROW line1 = mysql_fetch_row(res1);
if (line1 == 0){
// 用户不存在或者没找到
return 2;
}
MYSQL_RES* res2 = nullptr;
// 第二次执行sql
sql = "select * from oj_user where id='" + user_name + \
"' and `password`=password('" + password + "');";
if(0 != QueryMySqlResult(sql, res2)) return 3;
MYSQL_ROW line2 = mysql_fetch_row(res2);
if (line2 == 0){
// 密码错误
return 3;
}
// UserObject user;
// user.id = line2[0];
// user.password = line2[1];
// user.root = line2[2];
return 0;
}
// 注册用户
// 0 注册成功
// 1 内部错误
// 2 用户名为空或者已经存在
// 3 密码格式错误
int RegisterUser(const std::string& user_name, const std::string& password)
{
MYSQL_RES* res = nullptr;
if (user_name == "") return 2; // 为空
std::string sql = "select * from oj_user where id='" + user_name + "';";
if(0 != QueryMySqlResult(sql, res)) return 1; // 内部出错
MYSQL_ROW line = mysql_fetch_row(res);
if (line == 0){
// 用户找不到,可以插入
sql = "insert into oj_user(id, password) values('" + user_name + "', password('" + password + "'));";
int op = QueryMySqlResult(sql, res);
if (op == 1) return 1; // 连接出错
else if (op == 2) return 3; // 密码格式问题
}
else return 2; // 用户名冲突
return 0;
}
};
}
#endif当前用户权限还没使用,之后可扩展root用户可以自行添加题目修改题目,普通用户记录保存网页状态,记录刷题个数等等.....