大家好,我是千寻哥,现在自动驾驶很火热,其实自动驾驶是一个很大的概念,主要涉及的领域包括强化学习以及计算机视觉。
今天给各位讲讲强化学习的入门知识,并且手把手和大家一起做一个强化学习的Demo。
一、 浅谈强化学习入门
说到强化学习,你可能会有一些陌生,但是说到Alpha Go的围棋对决,你可能一下子就明白了。是的,这就是强化学习的能力。
为了让大家更加直观的了解强化学习的能力以及效果,千寻自己开发了一个强化学习玩贪吃蛇的游戏!

怎么样是不是十分的神奇!千寻今天和大家介绍一下,如何利用强化学习算法和ChatGPT让AI快速学会玩贪食蛇游戏。
我们将从理论基础出发,解释强化学习和深度强化学习的概念,并详细介绍使用本项目中所使用的DQN算法来训练AI玩贪食蛇的过程。
同时,我们将展示如何将ChatGPT与强化学习结合,以提供对游戏环境的实时解释和指导。
二、强化学习原理简介
强化学习是一种通过与环境交互学习最优行为策略的机器学习方法。在强化学习中,智能体通过观察环境的状态,并根据选择的动作获得奖励或惩罚来学习如何最大化累积奖励。
深度强化学习是将深度学习和强化学习相结合的方法,使用神经网络来近似值函数或策略函数,以解决高维状态空间和动作空间的问题。
在训练贪吃蛇的过程中使用的是PPO强化学习模型,以下是关于PPO算法的原理简介。
三、PPO算法训练智能体原理
定义状态表示
首先,需要定义贪吃蛇游戏的状态表示。状态可以包括蛇头位置、蛇身位置、食物位置等信息。这些信息将作为输入提供给PPO算法。
初始化PPO网络
使用神经网络作为策略函数,在PPO算法中,通常使用多层感知机(MLP)作为策略网络。策略网络的输入是状态表示,输出是在给定状态下选择每个可能动作的概率。
与环境交互
智能体与贪吃蛇环境进行交互。在每个时间步骤中,智能体观察当前状态,并根据策略网络选择一个动作。
收集经验
在与环境交互的过程中,记录智能体的状态、动作、奖励等信息,构成经验轨迹。一般通过多次游戏回合进行经验收集。
计算优势函数
根据收集到的经验,计算优势函数。优势函数用于估计每个动作相对于平均水平的优势程度,即衡量每个动作相对于当前策略的好坏程度。
更新策略网络
使用PPO算法的核心思想,对策略网络进行更新。更新的目标是最大化优势函数,同时限制更新幅度以保证策略的稳定性。
计算策略损失函数
根据收集到的经验和优势函数,计算策略损失函数。一般使用似然比优势函数作为损失函数,它包括策略网络输出动作的对数概率和优势函数的乘积。
计算策略更新
通过最小化策略损失函数来更新策略网络的参数。在PPO算法中,通常使用梯度下降方法,如Adam优化器,来最小化损失函数。
控制策略更新幅度
为了保证策略的稳定性,PPO算法使用了一种重要的技术,即通过限制策略更新幅度来防止太大的策略变化。这可以通过剪切或者概率比例等方式实现。
重复步骤3至步骤6
智能体与环境交互,收集经验,并更新策略网络。这个过程会进行多个迭代,直到达到预定的训练轮次或者策略收敛。
以下为部分训练深度强化学习的训练代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from Agent import AgentDiscretePPO
from core import ReplayBuffer
from draw import Painter
from env4Snake import Snake
import random
import pygame
import numpy as np
import torch
import matplotlib.pyplot as plt
if __name__ == "__main__":
#初始化超参数
env = Snake()
test_env = Snake()
act_dim = 4
obs_dim = 6
agent = AgentDiscretePPO()
agent.init(512, obs_dim, act_dim, if_use_gae=True)
agent.state = env.reset()
buffer = ReplayBuffer(2**12, obs_dim, act_dim, True)
#设定训练迭代的轮数以及数据的批量大小
MAX_EPISODE = 200
batch_size = 64
rewardList = []
maxReward = -np.inf
episodeList = [] # 存储训练轮数
rewardArray = [] # 存储rewards得分
for episode in range(MAX_EPISODE):
# 进行强化学习模型的训练
with torch.no_grad():
trajectory_list = agent.explore_env(env, 2**12, 1, 0.99)
# 反馈数据存入buffer缓存中
buffer.extend_buffer_from_list(trajectory_list)
# 根据缓存中的反馈数据更新网络结构
agent.update_net(buffer, batch_size, 1, 2**-8)
# 测试模型的代理获得贪吃蛇的得分
ep_reward = testAgent(test_env, agent, episode)
# 打印训练过程的信息
print('Episode:', episode, 'Reward:%f' % ep_reward)
rewardList.append(ep_reward)
episodeList.append(episode)
rewardArray.append(ep_reward)
if episode > MAX_EPISODE / 3 and ep_reward > maxReward:
maxReward = ep_reward
print('保存模型!')
torch.save(agent.act.state_dict(), 'model_weights/act_weight.pkl')
pygame.quit()
代码的每一部分的功能,我已经在代码文件中进行了详细的注释。终端输出训练信息如下:
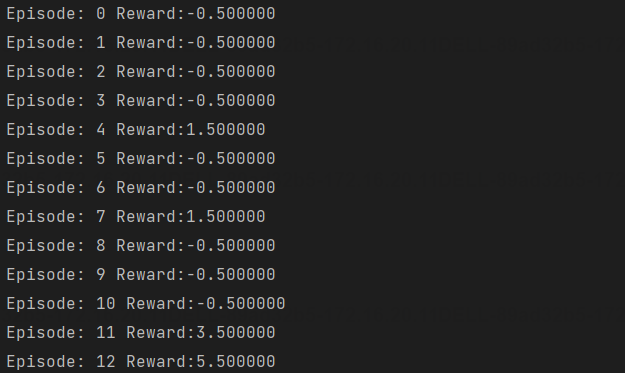
为了进一步的对强化学习的模型训练过程,我们对训练过程的信息进行可视化。
添加如下代码:
# 绘制训练轮数与rewards得分曲线
plt.plot(episodeList, rewardArray, label='Actual Rewards')
plt.plot(episodeList, fitted_rewards, label='Fitted Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.legend()
我们希望观察迭代训练的次数episode与最终强化学习的模型得分reward之间的关系,如下图所示:
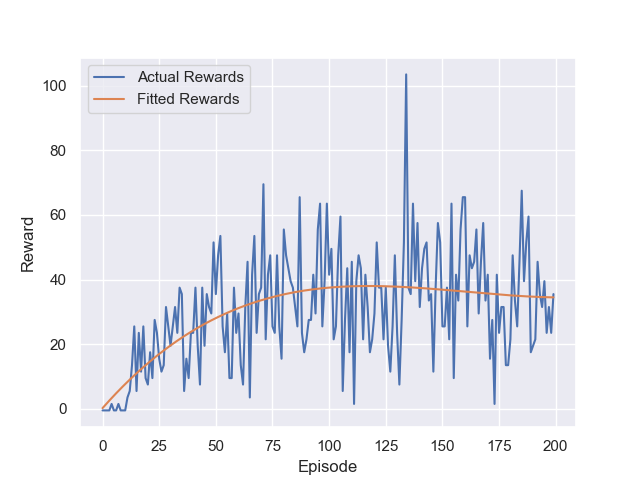
在曲线图像中的Actual Rewards标签为当前迭代轮数下的“实际得分数值”,Fittered Rewards标签为“拟合得分数值”。
通过以上的曲线,我们可以看出在约100轮左右,模型已经进入收敛状态,表示模型性能已经训练完成
四、ChatGPT与强化学习训练的结合
为了进一步优化强化学习的模型性能,将模型训练融入ChatGPT,ChatGPT是一种基于GPT-3.5架构的大型语言模型,具有强大的自然语言处理和生成能力。
那么ChatGPT语言生成模型与强化学习结合可以做什么呢?
必然是引入AI算法从而提供实时的游戏环境解释和指导。包括以下几点:
(1)游戏环境交互:通过ChatGPT与玩贪食蛇游戏的AI进行实时对话,AI可以向ChatGPT提问关于当前状态和最佳行动的问题。
(2)状态解释:AI可以将当前状态描述发送给ChatGPT,并从ChatGPT获得对状态的解释和建议。ChatGPT可以帮助AI理解游戏中的复杂状态和策略。
(3)行动建议:AI可以向ChatGPT询问最佳行动,并根据ChatGPT的建议选择下一步动作。ChatGPT可以基于其语言模型和先前的训练经验提供合理的建议。
(4)策略优化:AI可以根据ChatGPT提供的建议进行策略优化。AI在每个时间步骤中选择动作后,可以将结果反馈给ChatGPT,以便进行进一步的讨论和改进。
五、训练模型代理的验证
经过了ChatGPT的生成模型与PPO算法强化学习模型训练的AI玩贪吃蛇游戏,我们可以编写一个AI自动玩贪吃蛇游戏的推理代码:
定义Snake类的属性
class Snake:
def __init__(self):
self.snake_speed = 100 # 贪吃蛇的速度
self.windows_width = 600
self.windows_height = 600 # 游戏窗口的大小
self.cell_size = 50 # 贪吃蛇身体方块大小,注意身体大小必须能被窗口长宽整除
self.map_width = int(self.windows_width / self.cell_size)
self.map_height = int(self.windows_height / self.cell_size)
self.white = (255, 255, 255)
self.black = (0, 0, 0)
self.gray = (230, 230, 230)
self.dark_gray = (40, 40, 40)
self.DARKGreen = (0, 155, 0)
self.Green = (0, 255, 0)
self.Red = (255, 0, 0)
self.blue = (0, 0, 255)
self.dark_blue = (0, 0, 139)
self.BG_COLOR = self.white # 游戏背景颜色
# 定义方向
self.UP = 0
self.DOWN = 1
self.LEFT = 2
self.RIGHT = 3
self.HEAD = 0 # 贪吃蛇头部下标
pygame.init() # 模块初始化
self.snake_speed_clock = pygame.time.Clock() # 创建Pygame时钟对象
[self.snake_coords,self.direction,self.food,self.state] = [None,None,None,None]
设置奖励条件与游戏终止条件
# 判断蛇死了没
def snake_is_alive(self,snake_coords):
tag = True
if snake_coords[self.HEAD]['x'] == -1 or snake_coords[self.HEAD]['x'] == self.map_width or snake_coords[self.HEAD]['y'] == -1 or \
snake_coords[self.HEAD]['y'] == self.map_height:
tag = False # 蛇碰壁啦
for snake_body in snake_coords[1:]:
if snake_body['x'] == snake_coords[self.HEAD]['x'] and snake_body['y'] == snake_coords[self.HEAD]['y']:
tag = False # 蛇碰到自己身体啦
return tag
# 判断贪吃蛇是否吃到食物
def snake_is_eat_food(self,snake_coords, food): # 如果是列表或字典,那么函数内修改参数内容,就会影响到函数体外的对象。
flag = False
if snake_coords[self.HEAD]['x'] == food['x'] and snake_coords[self.HEAD]['y'] == food['y']:
while True:
food['x'] = random.randint(0, self.map_width - 1)
food['y'] = random.randint(0, self.map_height - 1) # 实物位置重新设置
tag = 0
for coord in snake_coords:
if [coord['x'],coord['y']] == [food['x'],food['y']]:
tag = 1
break
if tag == 1: continue
break
flag = True
else:
del snake_coords[-1] # 如果没有吃到实物, 就向前移动, 那么尾部一格删掉
return flag
自动玩贪吃蛇游戏部署,设置贪吃蛇的复活命数为10次
if __name__ == "__main__":
random.seed(100)
env = Snake()
env.snake_speed = 10
agent = AgentDiscretePPO()
agent.init(512,6,4)
# 加载强化学习的训练模型
agent.act.load_state_dict(torch.load('model_weights/act_weight.pkl'))
# 设置贪吃蛇复活次数
lifes = 10
for _ in range(lifes):
o = env.reset()
while 1:
env.render()
for event in pygame.event.get():
pass
a,_ = agent.select_action(o)
o2,r,d,_ = env.step(a)
o = o2
if d: break
最终在PyCharm环境中贪吃蛇的运行效果如图:
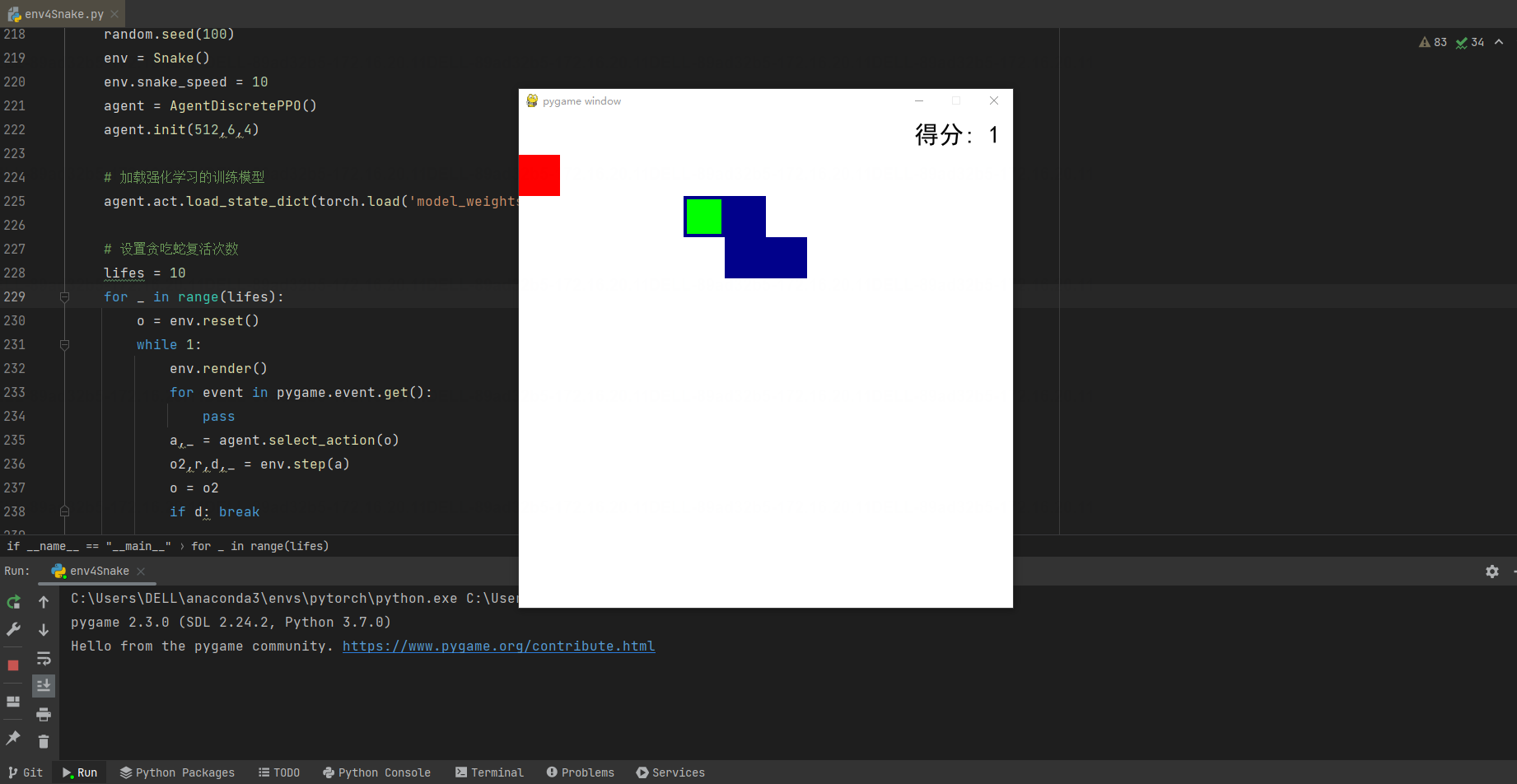
实际的动图检验效果:

通过ChatGPT指导的AI自动玩贪吃蛇,怎么样,效果不错吧,是不是很想尝试一下,没事,马上安排上!以下github地址链接,本地拷贝一下,就可以玩耍了!
Github:https://github.com/qianyuqianxun-DeepLearning/SnakeGameAI.git
我是千与千寻,一个只讲干货的码农,我们下期见~
本文由 mdnice 多平台发布