Python 文件拆分技巧详解
随着数据量的不断增大,我们经常需要处理非常大的数据文件,这时候就需要用到文件拆分技巧。在Python中,文件拆分可以帮助我们提高数据处理的效率,这是一个非常实用的技巧。在本篇文章中,我们将详细介绍Python文件拆分的方法,并提供一些实用的技巧,让您在处理大数据时更加得心应手。
何时使用文件拆分
在处理大数据文件时,我们通常面临两个问题:存储和处理速度。如果整个文件都被读取到内存中,将会占用大量内存,对于一些内存受限的设备来说,这显然是不可行的。同时,对于很多情况下,需要对数据进行分析,而这些数据往往需要进行预处理,包括筛选、排序、聚合等操作。在面对庞大的数据集时,这些操作需要很长时间才能完成,很容易导致程序崩溃或影响其他程序的运行。因此,使用文件拆分技术可以帮助我们解决这些问题。
Python文件拆分的方法
在Python中,我们可以使用内置的open函数和readlines方法来实现文件拆分。下面是示例代码:
# 打开文件
with open("data.txt", "r") as f:
# 读取文件内容
lines = f.readlines()
# 每10000行数据分为一份,写入新文件
for i in range(0, len(lines), 10000):
with open("data_" + str(i//10000) + ".txt", "w") as wf:
wf.writelines(lines[i:i+10000])
这段代码将原始文件按每10000行数据分为一份,写入新文件中。其中with语句会自动关闭文件,避免因忘记关闭文件而导致的问题。readlines会将整个文件读取为一个字符串列表,方便我们进行分割处理。range函数可以轻松地对数据进行分块,并通过整除法将文件名编号为1、2、3…的格式。最后,我们使用writelines方法写入分割后的文件。
实用技巧
在实际使用中,我们还可以根据需求对文件进行更灵活的拆分和处理。下面是一些实用技巧:
按文件大小拆分
我们也可以通过文件大小来进行文件拆分。下面是示例代码:
# 导入文件操作库
import os
# 定义文件大小
FILE_SIZE_LIMIT = 100 * 1024 * 1024 # 100MB
# 分块函数,按文件大小拆分
def split_by_size(file_path, size_limit):
# 分离文件名和扩展名
base_name, ext = os.path.splitext(file_path)
suffix_format = "{}.{}" + ext
with open(file_path, "rb") as fp:
chunk_id = 0
while True:
# 读取数据块
chunk = fp.read(size_limit)
if not chunk:
return
# 分块重命名
chunk_file = suffix_format.format(base_name, chunk_id)
with open(chunk_file, "wb") as cp:
cp.write(chunk)
chunk_id += 1
这段代码会将原始文件按照100 MB一块进行文件拆分。splitext函数会将文件名拆分成名称和扩展名两部分,suffix_format会控制分块后的文件名,每个文件都包含之前文件名+编号,保证文件名唯一。使用open函数和read方法循环读取数据块,并写入新文件中。在处理大文件时,这种方法是非常常见的文件拆分方法。
按正则表达式匹配拆分
如果我们需要按照特定的规则对数据进行预处理,这时候就可以考虑使用正则表达式来进行文件拆分。下面是示例代码:
# 导入正则表达式库
import re
# 定义正则表达式
REGEX_PATTERN = "^\d{4}-\d{2}-\d{2}.txt$"
# 分块函数,按正则表达式匹配拆分
def split_by_regex(file_path, regex):
# 分离文件名和扩展名
base_name, ext = os.path.splitext(file_path)
suffix_format = "{}_{:03d}" + ext
with open(file_path, "r") as fp:
# 读取并分离数据
raw_data = fp.read().split("\n")
groups = {}
# 将数据按规则存储到字典中
for line in raw_data:
match = re.search(regex, line)
if match is not None:
if match.group(0) not in groups:
groups[match.group(0)] = []
groups[match.group(0)].append(line)
# 根据字典中的数据写入新文件中
for i, key in enumerate(groups):
group_file = suffix_format.format(key, i)
with open(group_file, "w") as cp:
cp.write("\n".join(groups[key]))
这段代码将原始文件按照正则表达式进行拆分,并将符合同一规则的数据放在同一个文件中。我们可以通过search函数对数据进行正则表达式匹配,将符合规则的数据放在一个列表中,并以规则字符串为文件名写入新文件中。如果您已经了解正则表达式,那么这种方法是非常方便的文件拆分方法。
结论
在本篇文章中,我们介绍了Python文件拆分的方法和实用技巧。通过文件拆分,我们可以提高数据处理效率,避免程序因内存占用过高而崩溃。我们还介绍了按文件大小和正则表达式进行文件拆分的方法,这些技巧可以根据需求进行灵活使用。希望通过本文,您已经了解了Python文件拆分技巧,能够在实际工作中得心应手。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
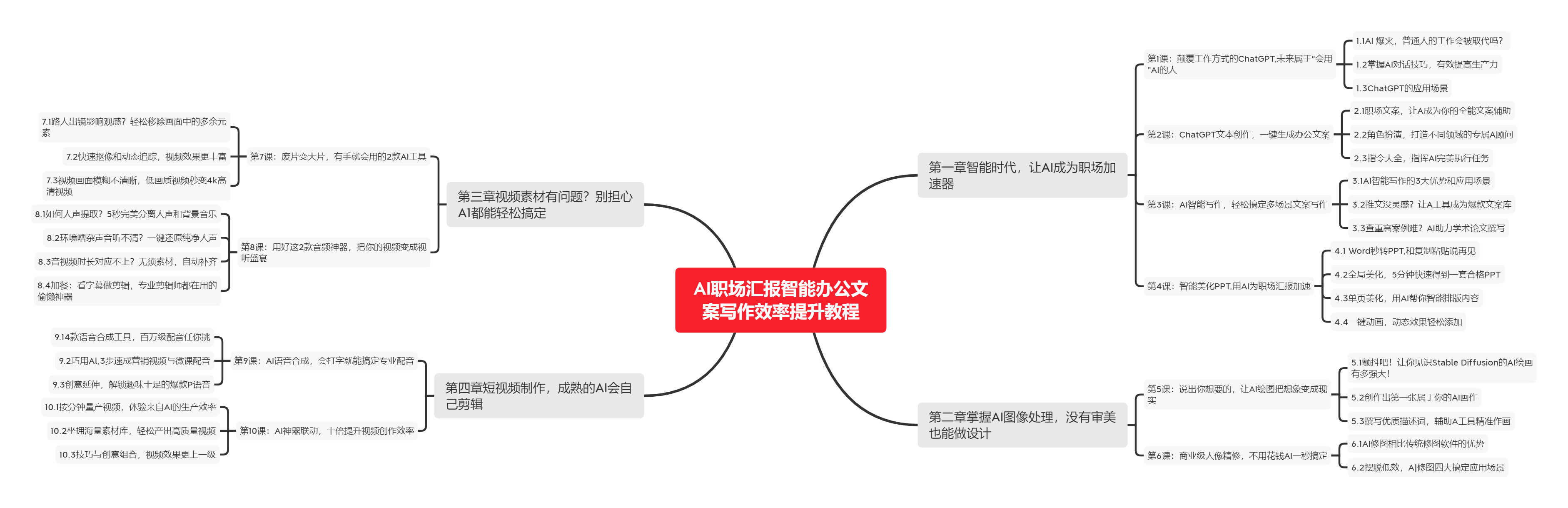
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |