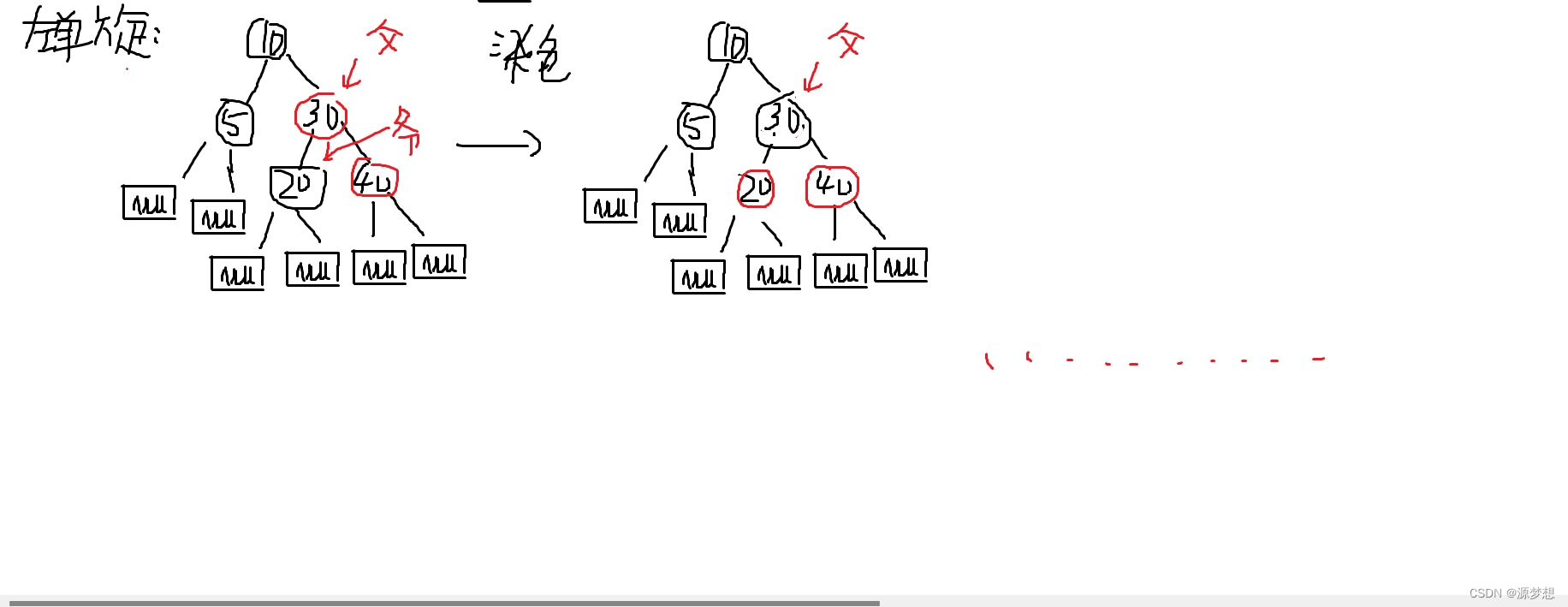
引言:
北京时间:2023/5/20/7:30,周六,可惜有课,而且还是早八,说明我们现在没有多少的学习时间啦!得抓紧把该博客的引言给写完,我们距离期末考越来越近啦!再过一个星期就要开始停课,然后进行什么实训,目前推测,这个实训估计就是在摆烂中摆烂,不过没有关系,只要课不是那么多就行,这样我们就有很多的时间来写博客啦!并且随着期末考将要来临,在将要考试的那段时间,我们肯定是更新不了博客,因为真的什么都不会,哈哈哈,不想挂科,只能是临阵磨枪,更加烦恼的是,还有无数的课需要去刷,很多的作业需要去交,心累呀!不过无太大所谓,什么都不能阻止我们更新博客,所以该篇博客,我们就来学习一下有关unordered_set和unordered_map的知识,当然学习unordered_set和unordered_map最重要的还是明白它的底层封装,也就是该文的重点,有关哈希表的相关知识,让我们一起看看哈希表示如何通过哈希结构实现那一骑绝尘的查找效率吧!

简简单单,摆摆烂烂,北京时间:2023/5/23/19:34,开开心心,麻麻赖赖,哟哟哈哈,可以看出我已逐渐疯狂,本以为这篇博客在周天就能如期而至,没想到啊没想到,周末摆了一整天,呜呜呜呜,主要原因值得沉思,原因很多,但,导火索应该是周天进行的消毒活动,导致无聊看了一下满江红,在我看来,大导的作品还是具有一定保障,虽然影片场景没有想象中的那么宏伟壮观,但是故事情节是紧凑的,题材和套路也很符合中国人的要求,所以口碑肯定不会差,有保障,这种电影估计还没播出之前,人家都知道肯定有人看,哈哈哈!但是说过来,确实,耐人寻味,好了,就这样吧!进入正题,这种东西,个人观点不同,不适合多做评价
什么是哈希表
这个问题,我一开始也很好奇,什么是哈希表,现有名言:我不知道什么是哈希表,但是我知道什么是哈哈哈哈哈!哈哈哈,该,精神开始错乱了,不好意思,不好意思,进入正题,进入正题,首先我认为,想要在最短的时间内,知道哈希表是什么,那么就两个办法,一个是画图,因为图就不再是抽象,而是具象,另一个是类比,把哈希表类比一个我们以前学习过的知识,通过以前学习过的知识来模仿它,寻找相同点和不同点,最终把不同点搞定,那我们就大致学会啦! 所以go,go,go,让我们一起来模仿吧!模仿谁不会吗?抄作业都抄不明白,干脆直接摆烂,好吧!
首先明白几个概念:
很多东西学不扎实,本质上在于概念不清,只要把概念搞清楚了,一切都是水到渠成,就会给人一种感觉,一泻千里的感觉,哈哈哈,真香定理,当然这也就是为什么要注重上课前预习的思想,所以在哈希有关知识中相关概念如下:哈希结构、哈希下标、哈希地址、哈希值、哈希函数 搞定了这些,哈希有关的字面基础知识,直接搞定
上高中的时候,相信大家,都知道生物的探究性实验基本步骤 ,1.提出问题 2.做出假设 3.进行实验 4.得出结论
哈哈哈,高中上学的时候,老师提问,站起来什么都不会,没想到啊,没想到,现在写的这么麻溜,糟糕,这个现象可不是什么好东西,此时我们也不管那么多,类比,上述提出概念之后,此时进入分析概念,最终得出结论就OK!如下:
哈希表基础概念
这几个概念之间具有强相关,所以不好按照顺序进行讲解,所以我就直接怎么舒服怎么来,如下:
什么是哈希下标
谈到哈希下标,按照我们上述的类比方法,此时简简单单,第一时间想到的就是数组下标,它们之间到底是什么关系呢?或者说是有什么区别呢?接下来,就让我一一道来,相信大家对数组下标肯定不陌生,但,如果谈到数组下标,此时就又会涉及到一个比较庞大的知识点,就是索引,当然不仅是数组下标,我们目前学习的哈希表进行数据映射的时候,通常使用的也是索引,所以在哈希表中,哈希下标就是对应数据在哈希表中的索引 ,明白了这个点,哈希下标的知识我们就有了一定的了解,甚至可以说很是明白,但,我们明白的只是哈希下标这个比较浅显的概念,并没有真正深入,所以想要真正深入,此时就需要把 索引 这个老油条给搞定,当然这波买卖肯定是稳赚不亏的,因为索引这个概念会出现在计算机中的各个领域,当然上述谈到的 映射 概念,就更加的老油条,基本可以说,操作系统到处都是映射,特别是与数据存储相关的,如文件系统那一块知识,所以接下来就让我们一起来看看什么是索引和什么是映射吧!
索引和映射
还是那句话,不怕啰啰嗦嗦,就怕概念玩的不清不楚,当然声明,这些概念不是因为我学过,我以前只是了解过,并且在了解的过程中被困扰过,所以对它们有一定的敌视心理,想要搞懂,我也需要进行查询,所以这也是写博客的好处,查询完,我可以自己进行梳理,然后总结,最终可以较为容易熟悉或者说是搞懂,如下:
索引:通常是指数据结构中用于标示某个位置或者某个元素的值或者指针 ,同理,类比数组下标,就是用于标示某个位置的值,类比链表结点中的指针,可以通过结点指针进行对应下一个结点的访问
映射:映射一般指将某个数据结构或数据类型中的数据,使用一定的算法和规则进行转换,得到另一个数据结构或数据类型中的数据 ,概念可以说是非常的清晰易懂,本质就是将某种数据以另一种形式进行表示,同理,类比页表映射,但,由于对于页表相关知识还不是很清楚,所以对于虚拟内存和物理内存的映射关系,我存在盲区,具体是什么数据类型到什么数据类型,我也存在疑问,这里对其不多做分析,我们类比较为简单的映射关系,如:ASCII码值和其对应的字符,此时就很好理解,就是把许多字符类型的数据映射成整形类型,索引和映射的概念都在上面,千万不敢困惑哦!
索引作用:快速定位对应数据,提高查找数据和操作数据的效率
映射作用:数据之间进行进行类型转换的方法
什么是哈希值
首先声明一个误区,哈希表是一个用来存储任意类型数据的数据结构,虽然大部分数据是以整形和字符串类型为主,但是,只要符合对应的存储规则和期望,任意的自定义类型都是可以存储的,所以此时的这个误区就是,不能把哈希值和我们存储的数据一样,都认为是整形类型的数据,举例:如果此时你需要在哈希表中存储的数据是整形,那么理所当然,此时的哈希值就是对应你要存储的数据,但,如果你需要存储的数据不是整形,而是一个字符串类型或者是一个自定义类型,那么此时哈希值是什么,就不是我需要存储的数据说了算的了,而是我需要存储数据对应映射关系的数据类型,并且通常这个映射数据类型需要自己根据预期和规则进行编写(从避免冲突的角度),通常最终获得的是一个整数,所以导致哈希值通常也是整数,最后明白,哈希值不是单单由数据类型决定的,而是需要通过一系列的哈希函数,通过各种运算得到
什么是哈希函数
上述两个概念,哈希下标和哈希值,可以说是哈希表中比较容易混淆的概念了,搞定了上述两个,接下来的概念,还是那句话,一通百通,并且上述我们也提到了,哈希值就是通过相应的哈希函数对数据进行的映射,明白,哈希函数只是一个抽象的概念,具体如何实现,需要根据自己的需求和数据冲突方面来规定,并且明白,哈希函数不单单可以用在哈希值的映射,在我看来更重要的是对哈希地址的运算,主要还是因为,映射那块的知识比较抽象,难度较大,使用哈希函数进行哈希运算得到哈希地址的过程比较简单,具体方法有:直接定址法(适用于当数据范围比较集中时)、除留余数法(用于数据范围不集中时)、平方取中法、随机数法…等方法
什么是哈希地址
同理,并且上述我们也提到了相关使用哈希函数计算哈希地址和哈希表中哈希地址的使用,此时我们就可以很容易的得出结论,哈希地址就是先让数据通过哈希函数映射获取到对应的哈希值,再让该哈希值根据对应哈希函数的哈希运算得到,最后在根据算出的哈希地址,将对应的数据存储到哈希表中,生成该数据特定的哈希下标,简简单单,多的没有,如下,就是一个除留余数法的哈希函数 hash(key) = key % tablesize;
什么是哈希结构
想要明白什么是哈希结构这个点,只要搞定下面这个问题就行啦!简简单单,麻麻辣辣嘛!
为什么要有哈希结构
想要搞定这个问题,首先就要明白,当每一个不同的数据通过同一哈希函数进行计算得到哈希地址时,此时会存在计算结果相同的问题,也就是哈希地址相同,那么此时因为哈希地址相同,就会导致哈希地址冲突,也叫哈希冲突,简简单单,人家直接就傲娇的跟你说,你处不处理,不处理,我就覆盖数据,莫得商量,八头牛都拦不住的那种哦!哈哈哈,So,当遇到这种情况,此时我们是一定需要进行处理,具体如何处理,如下,涉及到哈希结构相关的知识
正式了解哈希结构
搞定了上述知识,此时我们对哈希表的结构就有了一定的认知,此时想要深入,懂的都懂,哈希结构就是我们的跳板,并且哈希结构也是我们接下来要讲的重点内容,因为其还涉及到了如何解决哈希冲突的问题,并且哈希冲突可以说是哈希表的一个疑难杂症,想要根除根本不可能,解决起来只能是两个字,“争取”,争取将哈希冲突的可能性控制在最低,并且因为这块知识和我们如何设计哈希表关联性很大,所以这块知识先粗略通过概念分析一下,然后再以代码的形式展开来讲解,最经典的哈希结构有两种,闭散列和开散列 这两种方法都可以对哈希冲突问题进行处理,将可能性降低,具体如下:
闭散列:也叫开放地址法,当发生哈希冲突时,开放地址法通过一系列的搜索算法,如:线性探测、二次探测,来寻找下一个空闲地址,并将冲突元素存储在该地址处,如下图:

开散列:也叫开链法,是一种使用链表来解决哈希冲突问题的哈希结构,每个哈希地址(桶)都包含一个链表,相同哈希值的元素将被插入到链表中,从而避免冲突 ,如下图:
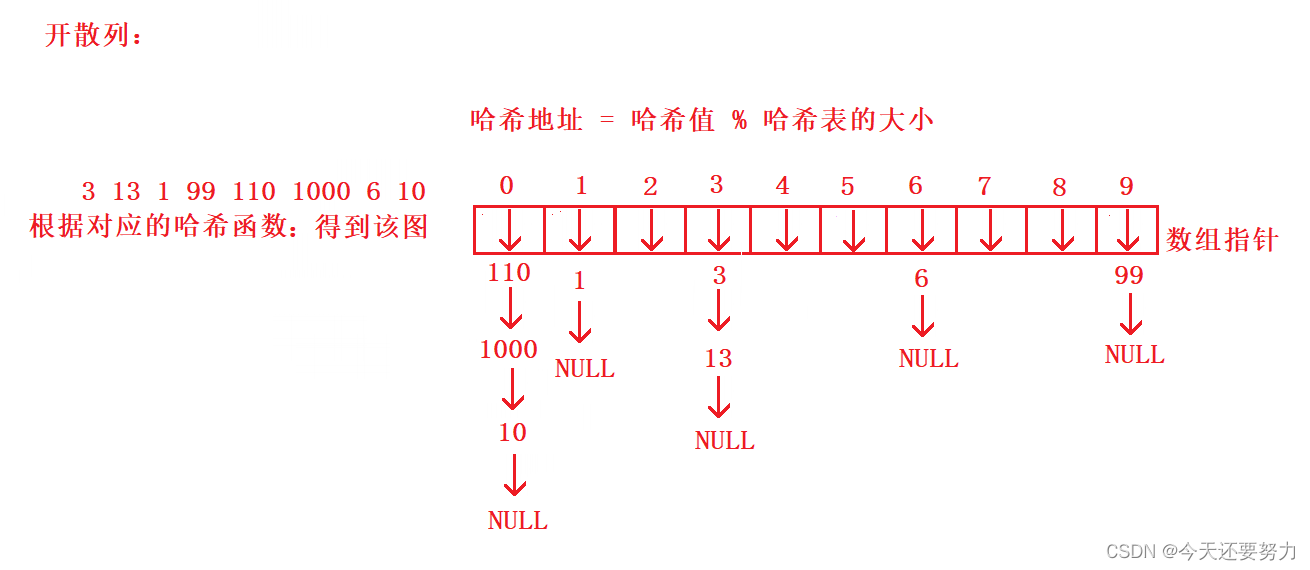
了解了上述两种不同的哈希结构,此时我们进行一定的分析,因为在STL源码中unordered_set和unordered_map肯定是只使用了其中一种来实现具体的哈希表,这说明,上述两种结构肯定存在一定的对比性优势或者劣势,可以看出如果是使用闭散列的形式,遇到哈希冲突就去该哈希地址的后方寻找空位置,那么就一定会导致该元素占据了别的元素的存储位置,如果往极端情形下走,连续性的哈希冲突,导致对应的数据存储在了哈希表的末端,那么此时在查找的时候,就会导致需要遍历哈希表才能查找到该数据,直接导致效率明显降低,而如果是开散列的话,可以看出根本不存在占用其它元素存储位置的情况,所以相对于这点,开散列肯定是具有优势的,但如果链表长度太长,同样会导致效率问题,但这个现象可以通过一定的手段进行控制,所以在STL中,哈希表的实现,使用的就是开散列的结构,如下:让我们通过对不同哈希结构的代码实现来具体看一看它们到底是骡子还是马!
哈希表不同哈希结构代码实现
1.闭散列
首先,在正式实现代码之前,我觉得有必要进行一定的思路汇总,本质也就是根据上述那么多有关哈希表的概念,进行编码,应该要如何如何,所以根据概念来讲,那么我们一定要得到对应的数据才可以根据哈希结构设计出真正可以存储数据的哈希表,例如: 我们需要选择哈希函数,然后根据选择的哈希函数和需要存储的元素,算出对应的哈希地址,得到对应哈希表中的哈希下标,并且值得注意的是:我们要在堆上开辟空间,并且解决相应的扩容问题,最后实现插入、查找和删除这几个数据结构基础接口,并且更新哈希表中对应哈希下标的状态
如上所说,此时涉及到两个方面的问题还没有介绍,一个是扩容,一个是状态,扩容这个问题在哈希表中属于重点中的重点,需要根据代码进行分析,所以这里不详细展开,我们就正式的讲一讲什么是哈希状态吧!还是一样,从问题出发,为什么要区分哈希状态?
从场景来分析,按照以前有关删除接口的写法,删除一个数据我们使用的都是直接删除的方式,并且大多数是两种编码方式,一种是像顺序表这样的,覆盖删除,另一种是与链表类似的,置空删除,但是此时在哈希表中,这两种方式都不适用,因为置空删除的本质是使用0来标示这个位置为空,但是在哈希表看来,0代表的也是具体的数据,并且当哈希表使用的是闭散列方法实现的时候,此时向后探测数据,那么这个数据一定是连续存放,因为插入原理是向后找空,但如果你使用删除接口将某一个位置删除,然后将该位置置为空时,那么在查找的时候,就可能会因为提前遇到空而导致查找提前结束,导致本来存在哈希表中的数据查找不到,所以千万不可以将删除之后的数据直接置空,这样会影响到查找,具体就是因为,插入数据时,是通过判空为条件,所以在查找过程不允许存在空,只允许在最后真正没有对应数据存在空,否则该哈希表就存在问题,所以此时最好的解决方法就是,将哈希表中每一个哈希地址给定一个状态,如:删除状态,空状态,存在状态,这也就是另一种删除方法,标记删除法,具体代码表示同理红黑树,使用的是枚举类型来控制,如下:

闭散列结点构建
并且无论是闭散列还是开散列,首先我们都需要构建一个哈希结点,如下图所示:以Key/Value结构构建

正式进入闭散列基础接口实现
注意:如下图,在哈希表中,我们可以自己实现tables结构,也可以直接复用vector类来充当tables结构,而我们选择的肯定是直接调用vector类,因为这样更加的方便和实用(聪明的偷懒)

插入接口
此时插入接口由于涉及到扩容,所以不适合一次性搞定,所以我们一块一块知识搞定它,因为哈希表的重点就在于扩容方面的问题,像是往哈希表中插入数据本质上和向vector中插入数据是没有什么区别的,只是由于此时我们使用的是闭散列结构,涉及到了线性探测的问题(向后找空)而已
不考虑扩容情况插入接口实现,代码如下图:

考虑扩容情况插入接口实现:
上述搞定了如何向哈希表中插入数据,此时我们就需要考虑当数据插入之后的操作了,像vector类中,当你插入的数据个数大于你在堆区上开辟的空间时,此时你就需要进行扩容操作,注意:此时哈希表和我们之前学习的vector有一些些不同,因为vector的目的仅仅只是用来存储数据而已,而哈希表要考虑查找方面功能的效率,并且明白,当你在一段哈希表空间中,插入的数据越多,那么发生哈希冲突的可能性就越大(闭散列情况下),所以哈希表为了提高效率,此时就不允许当插入的数据大于哈希表时,才进行扩容,而是需要提供一个新的概念:负载因子,当哈希表中的数据容量大于负载因子时,就需要进行扩容,注意:负载因为一般是自己控制的,但是实验表明当负载因子处于0.7~0.8最合适,如下代码所示:

但,如果此时你按照上述的写法进行扩容,那么就会出问题,因为此时是哈希表不是vector,按照上述的写法进行编码,那么就会导致,_tables.size()变为原来的两倍,最终因为_tables.size()的改变,使哈希地址发生改变,从而导致在使用查找接口的时候,查找不到已经在哈希表中的数据,如下图举例:

解决方法:遍历旧表,重新将数据映射到新表对应的哈希下标中
这样的解决方法不仅可以解决上述问题,而且可以很好的减少哈希冲突,可谓是一举两得,所以我们只要在扩容过程中,将原哈希表中的数据重新根据哈希函数获取到新表中的哈希地址就行了,这样就可以很好的解决由于哈希冲突和哈希函数改变导致的查找问题,具体代码如下:

但此时值得注意的是最后一步,调用vector类中的swap接口,具体如下图所示:

插入接口完整代码

查找接口
同理,在明白了插入接口的前提下,此时想要搞懂查找接口就跟喝水一般,简简单单就能搞定,如下代码所示,但,值得注意的是有许多和标记删除法有关的细节方面处理,所以实现的时候要格外注意,不然容易导致出现一些极端场景下的问题

删除接口
同理,删除接口本身并没有什么难度,插入接口之所以需要我们花费那么多的时间去讲解,是因为它需要进行扩容,而扩容就是哈希表重点中的重点,所以插入接口可以说是哈希表中基础接口中最重要的,删除接口,没有比较特别的地方,代码如下图所示:

2.开散列
上述方法是哈希结构中的一种,在该篇博客的开头,我们也详细讲述过了,在STL源码底层的封装中,大部分使用的都不是上述闭散列的方法,因为无论闭散列如何优化,最终都是去占用别人的位置,一定会导致效率方面下降明显,而如果使用开散列的方式,效率方面的就明显更高,所以在STL源码中使用的都是开散列的方式去封装哈希表,并且明白,哈希结构的一大特点就是,根据哈希结构,数据怎么插入,那么查找和删除接口就需要根据插入接口的具体实现来实现 ,明白了这点之后,此时我们就正式进入开散列的实现,本质如上述图示一般
开散列结点构建
同理,由于开散列使用的是链表结构,所以结点结构如下图所示:虽然可以直接调用list和vector,但是由于扩容方面问题,我们选择自己实现原生结构

正式进入开散列基础接口实现
插入接口实现
不考虑扩容插入数据

同理,需要进行扩容操作,但是扩容的原因和闭散列不同,闭散列扩容的原因是没有位置可以插入数据,而开散列由于使用的是链式结构,所以可以无限存储数据,无限头插,但是这样会导致效率下降,直接从哈希结构的O(1)时间复杂度,变成O(N),所以得不偿失,所以依然需要让哈希表进行扩容,从而让每一个哈希地址上的链式结构中的数据保持在一个可控范围内,从而提高查找和访问效率,如下代码所示:
考虑扩容插入数据

查找接口实现
同理,如下述代码所示:还是那句话,哈希表的实现整体就是看插入接口如何实现,插入接口如何实现,删除和查找接口就应该要如何匹配实现,多的没有,反正按照此时开散列来看,就还是使用哈希函数进行哈希运算,算出哈希地址,再根据哈希地址去访问对应哈希下标中存储的数据而已,不为空就访问,并且在查找接口看来,访问操作就是链表中就基础的迭代访问而已,并且上述插入接口,本质同理,只不过使用的是链表中最基础的头插原理而已

删除接口实现
同理,本质对于开散列的删除接口来看,就是一个对于链表的基础删除操作,这里不详解,代码如下:

以上就是开散列的基础接口实现,大体思路和闭散列的实现没什么区别,重点都还是在扩容和插入那一块,查找和删除都是根据插入的实现而实现,但是此时闭散列和开散列还有一定的不同,这个点也是使用开散列必须要完成的,就是释放堆空间的问题,由于闭散列使用的是vector和线性探测的方法,并且vector在自动帮助我们开辟空间的同时,它也会自动帮助我们把开辟的堆空间给释放掉,但是当我们在使用vector实现开散列的时候,此时由于数据存储时是存储在了对应vector上的Node*结点上,也就是对应的链表上,并且我们不仅在vector上开辟了堆空间,此时在对应的链表上,我们也开辟了空间,所以vector只会释放自己开辟的堆空间,不会释放链表上的堆空间,所以此时一定要自己实现一个析构函数,否则就会导致内存泄露问题,如下图所示:

链表正常析构函数,这里不多做讲解,接下来我们具体分析一个哈希表的时间复杂度,和解决一下有关类型方面的问题,该篇博客就搞定啦!
哈希表时间复杂度
为什么哈希表的时间复杂度是O(1)呢?具体就是因为其设计原理是以关键字(Key)的哈希值通过对应的哈希函数,进行对应的哈希运算,得到对应的哈希地址,通过哈希地址将对应的数据存储在对应的哈希表中对应的哈希下标中,也就是将元素存储在内部桶数组中,使得查找、插入和删除的时间复杂度都可以达到常数级别(本质是插入接口的功劳),所以当我们向哈希表中插入一个元素时,哈希函数首先计算出这个元素的哈希值,并将其对桶数组空间大小取模(通常我们会设置桶的数量为质数),得到要插入的桶的下标,这个下标的计算是瞬间完成的,因此它的时间复杂度为 O(1)
如上哈希表存在的问题(类型)
在上述讲解有关哈希值概念的时候,我们已经提到过了,哈希表是允许任意类型的数据存储,而不单单只是整形,或者字符串类型,所以无论是上述的闭散列还是开散列,此时实现的方法都是以整形为目的去实现的,也就是在使用哈希函数进行哈希运算计算哈希地址的时候,并没有考虑到别的类型,而单单只是整形的取模运算,此时如果Key值的类型发生改变,不再是整形,而是字符串类型或者是别的自定义类型,那么此时就会导致取模运算出现问题,或者是根本就不允许使用取模运算,所以上述代码存在最大的问题就是没有考虑到各种类型的存储,所以在该篇博客的最后,我们就来探讨一下有关类型存储计算的问题,如下:
解决方法: 简简单单,碰到这种问题,第一时间考虑的就是使用泛型编程(烦心编程),使用模板参数来控制,通过传具体的自定义类型参数,来控制不同类型的不同计算方式,也如上有关哈希值概念中所说,此时该类型想要转换成哈希值,就需要让该类型先通过对应的哈希函数进行映射,举例:如果此时是一个字符串类型,那么就需要让字符串类型根据一定的规则,将每一个字符根据其映射的ASCII码值进行相加,然后获取到整个字符串的整形映射值,最终在哈希表中根据该映射值,也就是哈希值去获取到对应的哈希地址,进而存储到哈希表中,具体编码时的操作:自己封装一个自定义类型,在这个类中进行对应符合自己期望的操作,本质也就是将对应不支持哈希运算或者是数学运算的类型,映射成一个支持哈希运算或者数学运算的哈希值,一般是整数,所以我们在该类中进行的编码,主要目的就是把一个自定义类型或者字符串类型,转化成一个允许运算的整形,具体如下图所示:
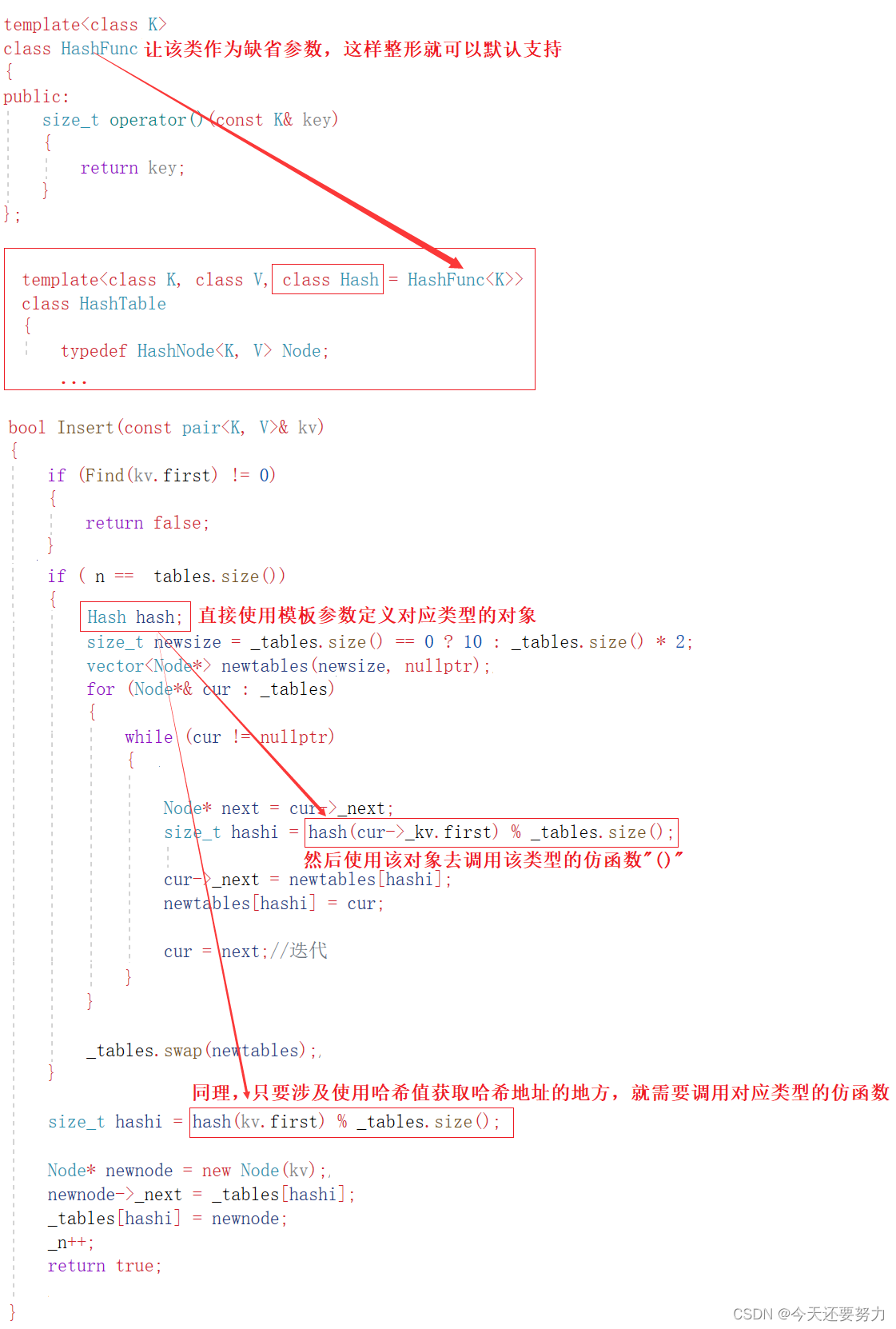
具体如何使用模板参数来控制哈希运算中的哈希值,就是如上图所示,重点就在于我们添加了一个 Hash的模板参数,以后在使用不同类型调用哈希表时,这个参数表示的就是对应类型映射成整数的类名,此时我们就可以在哈希表中使用这个模板参数(也就是对应的类名),然后用这个类名去定义对应类型的对象,再通过这个对象去调用对应的仿函数("()"),获取到对应整数哈希值,最终计算哈希地址成功,具体如下图所示:

如上图,注意:具体这个对应类型的映射方法如何实现,需要根据不同类型不同的数学函数来决定,具体水平有限,我也解释不了,反正是有一定规则规定好了的,所以我们直接利用就行,不需要太深入学习,我们重点只要知道为什么需要那么复杂的去实现这个映射值,也就是哈希值就完了,本质还是为了提高哈希表的效率,减少哈希冲突,总:映射值同样决定了哈希冲突的概率,所以在实现对应类型的映射时,同样需要考虑到哈希冲突问题,减少相同哈希值出现的可能性,从而提高哈希表整体的效率

总结:简简单单,嘻嘻哈哈,我们就把哈希表的实现给学习完啦!不过如此(刚开始学习的时候,卧槽卧槽的喊,哈哈哈),可以发现,任何东西,只要学完了,都会感觉它并不难,人天性如此,如同记忆一般,哈哈哈!但,可以是由于大框架的问题,刚开始学接触不同哈希的全部面貌,所以认为其很难,但是当你全部学完之后,看清了整座庐山,此时就不觉得难了,因素很多,这里不多说,撤退啦!哈哈哈,哈哈哈!
完整学习代码,如下:
#include<iostream>
#include<vector>
using namespace std;
namespace openAddress
{
enum State//注意:当我们定义了一个枚举结构的时候,此时该枚举结构的名称就是一个类型(枚举类型),可以用来定义变量
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>//此时还没有涉及到封装unordered_set和unordered_map,所以先不只使用一个模板
class HashData
{
public:
State _state = EMPTY;
pair<K, V> _kv;
//int _loadfactor;//负载因子需要根据插入数据的个数进行计算,所以不需要这样写,但也不是不行
};
template<class K>
class HashFunc
{
public:
size_t operator()(const K& key)
{
return key;
}
};
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
typedef HashData<K, V> data;
public:
bool Insert(const pair<K, V>& kv)
{
Hash hash;
if (Find(kv.first) != 0)//此时不等于0也就是表示找到了对应的值(防止冗余重复而已)
{
return false;
}
//插入数据,一来第一个问题就是考虑是否需要扩容问题,而不是计算哈希地址(判断是否可以存储)
/*if (_n / _tables.size() >= 0.7)*/
/*if ((double)_n / (double)_tables.size() >= 0.7)*/
//注意:_n 此时是整形,size也是整形,所以不可以直接除,要么强转(转其中一个就行),要么改进
if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7)//两边同时扩大10倍,去除小数烦恼(并且防止除0错误)
{
//_tables.reserve(_tables.capacity() * 2);//使用vector模板类的好处,直接用就行了(但注意:此时有两个问题 1.当capacity为0 2.没有更新size的大小,因为是size变大导致扩容,所以扩容的时候,一定需要更新size,例:size从10变成11,导致扩容,如果不更新size,那么size就是还是10)
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
//但是如果像上述这个写法,依然存在一定的问题,如下:
//问题情况:就是当哈希地址3处存储的是3,而13不能存储在3处,只能存储在4处,此时如果进行了扩容,那么导致
//_tables.size()的大小发生改变,也就是13不会再存储在4处了,而是存储在哈希地址为13处,就会导致在查找的时候,不能找到
//所以此时的解决方法就是:遍历旧表,重新映射新表
//方法一:
vector<HashData<K, V>> newtables(newsize);
for (auto& data : _tables)//避免在每次迭代过程中复制一份新的元素对象(范围for中使用引用的目的)
{
if (data._state == EXIST)
{
size_t hashi = hash(data._kv.first) % _tables.size();
size_t i = 1;
size_t index = hashi;
while (newtables[index]._state == EXIST)
{
index = hashi + i;
index %= newtables.size();
++i;
}
newtables[index]._kv = data._kv;
newtables[index]._state = EXIST;
}
}
_tables.swap(newtables);//这步较好要去复习一下
//方法二:
//HashTable<K, V> newht;//上述还是同理使用vector对象,这里使用的就是哈希表对象了
//newht._tables.resize(newsize);//此时这步让tables的大小变大,导致在下标调用insert的时候,就不会再进行这个判断条件
//for (auto& data : _tables)
//{
// if (data._state == EXIST)
// {
// newht.Insert(data._kv);//本质不进入这个条件,就只是在调用下面那一串代码而已(同理)
// }
//}
//_tables.swap(newht._tables);
}
size_t hashi = hash(kv.first) % _tables.size();//使用对应的哈希函数计算出散列地址(也就是vector中的下标)
size_t i = 1;
size_t index = hashi;
//循环判断找空位置存储数据(循环就是多次if,并且是会迭代的if)
while (_tables[index]._state == EXIST)//此时由于我们可能存储的数据就是0和需要以空来查找数据,所以此时就需要使用到枚举中的状态
{
index = hashi + i;
index %= _tables.size();//目的:防止hashi越界,导致数据插入在非法位置
++i;//不直接使用+=的原因,方便改成二次探测
}
//代码来到这里,出循环,表示的自然就是这个位置是一个空位置,直接插入数据就ok了
_tables[index]._kv = kv;
_tables[index]._state = EXIST;
_n++;//这个位置的代码就是直接使用vector模板类的好处,不需要我们自己去更新size和capacity
return true;
}
HashData<K, V>* Find(const K& key)
{
Hash hash;
if (_tables.size() == 0)
{
return nullptr;
}
size_t hashi = hash(key) % _tables.size();
size_t i = 1;
size_t index = hashi;
while (_tables[index]._state != EMPTY)
{
if (_tables[index]._state == EXIST && _tables[index]._kv.first == key)
{
return &_tables[index];//找到了就返回对应下标的地址
}
index = hashi + i;
index %= _tables.size();
++i;
if (index == hashi)//表示找了一圈(表示此时所有位置都是存在或者删除,没有空位置),目的:防止上述循环死循环
{
break;
}
}
//代码来到这里,自然表示的就是遍历到了空位置,还没有找到相应的值
return nullptr;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret != nullptr)
{
ret->_state = DELETE;//标记删除法(但此时会导致查找接口出现问题),需要改进
_n--;
return true;
}
else
{
return false;
}
}
private:
//HashData* _tables;
//size_t _size;
//size_t _capacity;
//可以像之前学习vector一样,来构建这个hashtable,但是也可以直接去调用vector,如下:
vector<HashData<K, V>> _tables;//使用vector来作为哈希结构的存储空间
size_t _n = 0;//表示存储数据的个数
};
void testopenAddress()
{
HashTable<int,int> hash;
hash.Insert(make_pair(1, 1));
hash.Insert(make_pair(2, 2));
hash.Insert(make_pair(3, 3));
hash.Insert(make_pair(4, 4));
hash.Insert(make_pair(5, 5));
}
}
//搞定了上述闭散列的知识,此时下述这个就是真正底层实现哈希表的代码,开散列
namespace HashBucket
{
template<class K,class V>//注意:模板的范围和访问限定符同理
class HashNode
{
public:
HashNode<K, V>* _next;
pair<K, V> _kv;
HashNode(const pair<K,V>& kv)
:_next(nullptr),_kv(kv)
{}
};
//解决不同类型的比较问题(注意:key大多数情况下不是整形就是字符串类型,自定义类型可以忽略),玩你妹的日期类(同理字符串就行)
template<class K>
class HashFunc//这个类用来作为整形传参的仿函数(注意:任何数据类型都可以作为模板参数,无论是内置类型还是自定义类型)
{
public:
size_t operator()(const K& key)
{
return key;
}
};
//特化的经典场景
template<>
class HashFunc<string>
{
public:
size_t operator()(const string& str)
{
size_t hash = 0;
for (auto ch : str)
{
hash += ch;
hash *= 31;
}
return hash;
}
};
//但是这种设计方式非常的挫,所以在STL中是如上述方法写的(特化)
class HashString//注意:此时该类产生不仅是为了解决在哈希表中类型的存储,还是为了解决对应字符串的冲突问题,因为一个字符串不同,但是它的ASCII码值可能相同
{
public:
size_t operator()(const string& str)//1.解决存储类型问题(需要取余数) 2.减少ASCII码值冲突(使用哈希函数时*31/131...)
{
size_t hash = 0;
for (auto ch : str)//遍历,将每一个字母的ASCII码值加起来(但任然存在一定的问题),如:abcd/bcad/aadd ... 解决方法如下:
{
hash += ch; //先使用整形进行比较,比较成功之后,再使用对应字符串进行遍历比较,找到对应完全相同的字符串
hash *= 31; //这个位置需要结合+=理解,不然搞不定不同顺序的字符串,画个图就好了
}
return hash;
}
};
template<class K, class V, class Hash = HashFunc<K>>//此时这个位置的第三个模板参数就是为了解决不同类型除模余数法的问题
class HashTable //注意:此时HashFunc是作为Hash模板参数的缺省值,并且这个缺省值是通过对应的模板进行初始化,是一个模板中模板的使用,具体需要画图
{ //此时这个类模板参数值得详解(注意:此时这个缺省参数本质还要取决于我传没传)
typedef HashNode<K, V> Node;
public:
//注意:上述如果直接使用vector,vector库中有对应的析构函数,但是此时由于vector中存储的都是Node*指针,它们都指向了不同的链表结构,所以此时这个链表结构图就需要我们自己去释放
~HashTable()
{
for (auto& cur : _tables)
{
while (cur != nullptr)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
cur = nullptr;//因为此时我们使用了引用,所以直接置空就行了
}
}
//经典问题:如果我们就这样开了空间,然后又释放空间,此时就非常的浪费,最好的方式:就是扩容的时候,使用移动的方式,直接将原空间链表上的数据移动到新空间上
bool Insert(const pair<K, V>& kv)
{
if (Find(kv.first) != 0)//只有当这个数据找不到,我们才插入的意思而已
{
return false;
}
Hash hash;
//同理,第一步都不是插入数据,而是判断是否需要扩容(根据:当负载因子== 1的时候进行扩容),因为当负载因子等于1的时候,就是期望每个链表上都有一个数据的时候,此时就扩容(本质就是为了控制链表上的数据个数)
if (_n == _tables.size())
{//满足该条件,就扩容
//size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
//HashTable<K, V> newht;
//newht.resize(newsize);
//for (auto cur : _tables)//此时这个迭代器的本质就是返回_tables中的一个一个指针(以指针地址的形式),然后拷贝给cur
//{
// while (cur != nullptr)
// {
// newht.Insert(cur->_kv);
// cur = cur->next;
// }
//}
//_tables.swap(newht._tables);//这个swap可以去复习一下vector好像(还有相关的扩容知识)
//改进方法:将原空间链表上的数据移动到新空间上(如下)(本质也就是不去调用insert了,也就是不需要开结点了)
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
vector<Node*> newtables(newsize, nullptr);//这个初始化可以去复习一下vector的构造函数
for (Node*& cur : _tables)//不使用auto写法,同理:for(size_t i = 0; i < _tables.size(); ++i) Node*& cur = _table[i];
{
while (cur != nullptr)//不需要重新开结点,而是直接进行指针替换
{
//头插到新表(先保存,后迭代头插)
Node* next = cur->_next;
size_t hashi = hash(cur->_kv.first) % _tables.size();
cur->_next = newtables[hashi];//还是头插
newtables[hashi] = cur;
cur = next;//迭代
}
}
_tables.swap(newtables);//窃取劳动果实写法(类似迭代)
}
size_t hashi = hash(kv.first) % _tables.size();
//获取到对应的地址,开始插入(头插)
Node* newnode = new Node(kv);//在堆区上开辟结点(注意:上述使用闭散列方法也有在堆区上开辟空间,只是本质上是在扩容的时候开辟的而已)
newnode->_next = _tables[hashi];//链接当前位置的数据
_tables[hashi] = newnode;//然后自己做头(头插),反正本质就是newnode的next是hashi,所以newnode可以直接做头
_n++;
return true;
//但,此时不能无限头插,需要进行扩容,同理涉及负载因子问题(如上)
}
Node* Find(const K& key)
{
Hash hash;//目的:让对应的key值变成一个可以取模的值
if (_tables.size() == 0)//这步判断,可以控制,主要看怎么编码,可以先开辟空间
{
return nullptr;
}
size_t hashi = hash(key) % _tables.size();//获取到数据储存的地址(也就是下标),然后再去遍历链表
Node* cur = _tables[hashi];
while (cur != nullptr)//遍历链表而已(可以对比一下上述闭散列的写法)
{
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key)
{
Hash hash;
//首先明白,此时就不能直接是Find之后删除,因为是链表,所以需要考虑
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur != nullptr)
{
if (cur->_kv.first == key)
{
//先保存,后删除
if (prev == nullptr)//表示下述迭代没有进行,也就是表示第一个数据就是我要删除的数据(头删)
{
_tables[hashi] = cur->_next;
}
else//要删除的是中间数据
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;//迭代
cur = cur->_next;
}
}
return false;
}
private:
vector<Node*> _tables;//注意:此时该vector数组就是一个指针数组
size_t _n = 0;
};
void test()
{
HashTable<string, string, HashString> ht;//按照上述的编码方式,此时这个位置就只能给整形,如果给string类型,那么此时就会在使用除模余数法的时候,无法获取到对应的哈希地址(下标)
ht.Insert(make_pair("sort", "排序"));
ht.Insert(make_pair("string", "字符串"));
//所以此时需要改进,不然就会导致我们的程序只能满足整形的存储(肯定是不合适的),解决方法如上(再使用一个模板参数)
HashString hashstr;//注意:此时该类产生不仅是为了解决在哈希表中类型的存储,还是为了解决对应字符串的冲突问题,因为一个字符串不同,但是它的ASCII码值可能相同
cout << hashstr("abcd") << endl;//此时本质就是在使用hashstr中的仿函数而已(注意:"()"就是仿函数的特征)
cout << hashstr("badc") << endl;
cout << hashstr("aadd") << endl;//所以此时需要二次改进,本质就是让这些相同ASCII码值的字符串最终映射的地址不同(下标)
cout << hashstr("eat") << endl;
cout << hashstr("ate") << endl;
}
}
int main()
{
openAddress::testopenAddress();
HashBucket::test();
return 0;
}