系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作.
Flink第三章:基本操作(二)
Flink第四章:水位线和窗口
Flink第五章:处理函数
Flink第六章:多流操作
Flink第七章:状态编程
文章目录
- 系列文章目录
- 前言
- 一、Keyed State(按键分区)
- 1.KeyedStateTest.scala
- 2.PeriodicPVExample.scala
- 3.TwoStreamJoinExample.scala
- 4.FakeWindowExample.scala
- 5.AverageTimestampExample.scala
- 二、Operator State(算子状态)
- 1.BufferingSinkExample.scala
- 三、Broadcast State(广播状态)
- 1.BroadcastStateExample.scala
- 总结
前言
这次我们来学习Flink中的状态学习部分,创建以下scala文件
一、Keyed State(按键分区)
1.KeyedStateTest.scala
这个文件里有几个常用的状态创建
package com.atguigu.chapter06
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.api.common.functions.{AggregateFunction, ReduceFunction, RichFlatMapFunction}
import org.apache.flink.api.common.state._
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object KeyedStateTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.addSource(new ClickSource)
.assignAscendingTimestamps(_.timestamp)
.keyBy(_.user)
.flatMap(new MyFlatMap)
env.execute()
}
class MyFlatMap extends RichFlatMapFunction[Event, String] {
// 定义状态
var valueState: ValueState[Event] = _
var listState: ListState[Event] = _
var mapState: MapState[String, Long] = _
var reduceState:ReducingState[Event]= _
var aggState:AggregatingState[Event,String]= _
override def open(parameters: Configuration): Unit = {
valueState = getRuntimeContext.getState(new ValueStateDescriptor[Event]("my-value", classOf[Event]))
listState = getRuntimeContext.getListState(new ListStateDescriptor[Event]("my-list", classOf[Event]))
mapState = getRuntimeContext.getMapState(new MapStateDescriptor[String, Long]("my-map", classOf[String], classOf[Long]))
reduceState=getRuntimeContext.getReducingState(new ReducingStateDescriptor[Event]("my-reduce",
new ReduceFunction[Event] {
override def reduce(t: Event, t1: Event): Event = Event(t.user,t.url,t1.timestamp)
},classOf[Event]
))
aggState=getRuntimeContext.getAggregatingState(new AggregatingStateDescriptor[Event,Long,String]("my-agg",
new AggregateFunction[Event,Long,String] {
override def createAccumulator(): Long = 0L
override def add(in: Event, acc: Long): Long = acc+1
override def getResult(acc: Long): String = "当前聚合状态为:"+acc.toString
override def merge(acc: Long, acc1: Long): Long = ???
},classOf[Long]
))
}
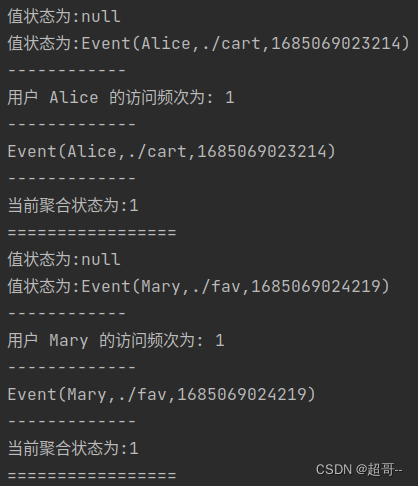
override def flatMap(in: Event, collector: Collector[String]): Unit = {
// 对状态进行操作
println("值状态为:" + valueState.value())
valueState.update(in)
println("值状态为:" + valueState.value())
listState.add(in)
println("------------")
val count: Long =if (mapState.contains(in.user)) mapState.get(in.user) else 0
mapState.put(in.user,count+1)
println(s"用户 ${in.user} 的访问频次为: ${mapState.get(in.user)}")
println("-------------")
reduceState.add(in)
println(reduceState.get())
println("-------------")
aggState.add(in)
println(aggState.get())
println("=================")
}
}
}
2.PeriodicPVExample.scala
按键分区中值状态编程案例
我们这里会使用用户 id 来进行分流,然后分别统计每个用户的 pv 数据,由于我们并不想每次 pv 加一,就将统计结果发送到下游去,所以这里我们注册了一个定时器,用来隔一段时间发送 pv 的统计结果,这样对下游算子的压力不至于太大。具体实现方式是定义一个用来保存定时器时间戳的值状态变量。当定时器触发并向下游发送数据以后,便清空储存定时器时间戳的状态变量,这样当新的数据到来时,发现并没有定时器存在,就可以注册新的定时器了,注册完定时器之后将定时器的时间戳继续保存在状态变量中。
package com.atguigu.chapter06
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object PeriodicPVExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.addSource(new ClickSource)
.assignAscendingTimestamps(_.timestamp)
.keyBy(_.user)
.process(new PeriodicPv)
.print()
env.execute()
}
class PeriodicPv extends KeyedProcessFunction[String, Event, String] {
// 定义值状态,保存当前用户的pv数据
lazy val countState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("count", classOf[Long]))
//定义值状态,保存定时器的时间戳
lazy val timerTsState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("time-Ts", classOf[Long]))
override def processElement(value: Event, ctx: KeyedProcessFunction[String, Event, String]#Context, out: Collector[String]): Unit = {
// 每来一个数据,就将状态中的count+1
val count: Long = countState.value()
countState.update(count + 1)
// 注册定时器,每隔10秒输出一次统计结果
if (timerTsState.value() == 0L) {
ctx.timerService().registerEventTimeTimer(value.timestamp + 10 * 1000L)
//更新状态
timerTsState.update(value.timestamp + 10 * 1000L)
}
}
// 定时器触发
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, Event, String]#OnTimerContext, out: Collector[String]): Unit = {
out.collect(s"用户 ${ctx.getCurrentKey}的pv值为:${countState.value()}")
// 清理状态
timerTsState.clear()
}
}
}
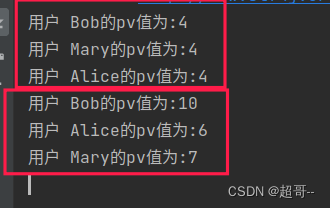
10s统计一次,并且不断累加,有点像全局窗口.
3.TwoStreamJoinExample.scala
列表状态编程
SELECT * FROM A INNER JOIN B WHERE A.id = B.id;
这样一条 SQL 语句要慎用,因为 Flink 会将 A 流和 B 流的所有数据都保存下来,然后进行 join。不过在这里我们可以用列表状态变量来实现一下这个 SQL 语句的功能。
package com.atguigu.chapter06
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.streaming.api.functions.co.CoProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object TwoStreamJoinExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[(String, String, Long)] = env.fromElements(
("a","stream-1",1000L),
("b","stream-1",2000L),
).assignAscendingTimestamps(_._3)
val stream2: DataStream[(String, String, Long)] = env.fromElements(
("a","stream-2",3000L),
("b","stream-2",4000L),
).assignAscendingTimestamps(_._3)
// 连接两条流进行Join操作
stream1.keyBy(_._1)
.connect(stream2.keyBy(_._1))
.process(new TwoStreamJoin)
.print()
env.execute()
}
class TwoStreamJoin extends CoProcessFunction[(String, String, Long),(String, String, Long),String] {
// 定义列表状态,保存流中已经到达的数据
lazy val stream1ListState: ListState[(String, String, Long)] = getRuntimeContext.getListState(new ListStateDescriptor[(String, String, Long)]("stream1-list", classOf[(String, String, Long)]))
lazy val stream2ListState: ListState[(String, String, Long)] = getRuntimeContext.getListState(new ListStateDescriptor[(String, String, Long)]("stream2-list", classOf[(String, String, Long)]))
override def processElement1(value1: (String, String, Long), ctx: CoProcessFunction[(String, String, Long), (String, String, Long), String]#Context, out: Collector[String]): Unit = {
// 直接添加到列表状态中
stream1ListState.add(value1)
//遍历另一条流中已经到达的数据,输出配对信心
import scala.collection.convert.ImplicitConversions._
for (value2<-stream2ListState.get()){
out.collect(value1+"=>"+value2)
}
}
override def processElement2(value2: (String, String, Long), ctx: CoProcessFunction[(String, String, Long), (String, String, Long), String]#Context, out: Collector[String]): Unit = {
// 直接添加到列表状态中
stream2ListState.add(value2)
//遍历另一条流中已经到达的数据,输出配对信心
import scala.collection.convert.ImplicitConversions._
for (value1<-stream1ListState.get()){
out.collect(value1+"=>"+value2)
}
}
}
}

4.FakeWindowExample.scala
映射状态编程
映射状态的用法和 Java 中的 HashMap 很相似。在这里我们可以通过 MapState 的使用来探
索一下窗口的底层实现,也就是我们要用映射状态来完整模拟窗口的功能。这里我们模拟一个
滚动窗口。我们要计算的是每一个 url 在每一个窗口中的 pv 数据。我们之前使用增量聚合和
全窗口聚合结合的方式实现过这个需求。这里我们用 MapState 再来实现一下。
package com.atguigu.chapter06
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object FakeWindowExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.addSource(new ClickSource)
.assignAscendingTimestamps(_.timestamp)
.keyBy(_.url)
.process(new FakeWindow(10000L)) //10秒的滚动窗口
.print()
env.execute()
}
class FakeWindow(size:Long) extends KeyedProcessFunction[String,Event,String]{
//定义一个映射状态,用来保存一个窗口的pv值
lazy val windowMapSate: MapState[Long, Long] = getRuntimeContext.getMapState(new MapStateDescriptor[Long, Long]("window-pv", classOf[Long], classOf[Long]))
override def processElement(value: Event, ctx: KeyedProcessFunction[String, Event, String]#Context, out: Collector[String]): Unit = {
//集散当前数据落入窗口的启示时间戳
val start: Long = value.timestamp / size * size
val end: Long = start + size
// 注册一个定时器,用力触发窗口计算
ctx.timerService().registerEventTimeTimer(end-1)
// 更新状态 count+1
if (windowMapSate.contains(start)){
val pv: Long = windowMapSate.get(start)
windowMapSate.put(start,pv+1)
} else {
windowMapSate.put(start,1L)
}
}
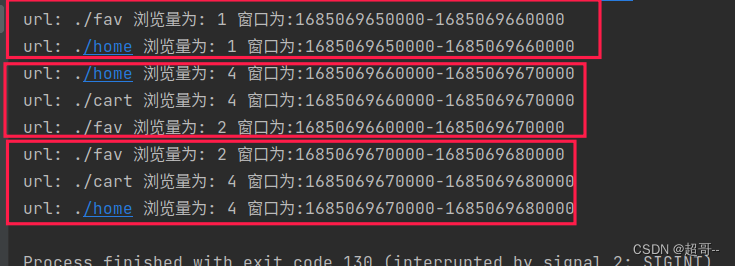
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, Event, String]#OnTimerContext, out: Collector[String]): Unit = {
// 定时器触发,窗口输出结果
val start: Long = timestamp + 1 - size
val pv: Long = windowMapSate.get(start)
// 窗口输出结果
out.collect(s"url: ${ctx.getCurrentKey} 浏览量为: ${pv} 窗口为:${start}-${start+size}")
//窗口销毁
windowMapSate.remove(start)
}
}
}
5.AverageTimestampExample.scala
聚合状态编程
我们举一个简单的例子,对用户点击事件流每 5 个数据统计一次平均时间戳。这是一个类似计数窗口(CountWindow)求平均值的计算,这里我们可以使用一个有聚合状态的
RichFlatMapFunction 来实现。
package com.atguigu.chapter06
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.api.common.functions.{AggregateFunction, RichFlatMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object AverageTimestampExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.addSource(new ClickSource)
.assignAscendingTimestamps(_.timestamp)
stream
.keyBy(_.url)
.flatMap(new AvgTimestamp)
.print("input")
stream.print("input")
env.execute()
}
class AvgTimestamp extends RichFlatMapFunction[Event, String] {
// 定义一个聚合状态
lazy val avgTsAggState: AggregatingState[Event, Long] = getRuntimeContext.getAggregatingState(new AggregatingStateDescriptor[Event, (Long, Long), Long](
"avg-ts",
new AggregateFunction[Event, (Long, Long), Long] {
override def createAccumulator(): (Long, Long) = (0L, 0L)
override def add(in: Event, acc: (Long, Long)): (Long, Long) = (acc._1 + in.timestamp, acc._2 + 1)
override def getResult(acc: (Long, Long)): Long = acc._1 / acc._2
override def merge(acc: (Long, Long), acc1: (Long, Long)): (Long, Long) = ???
},
classOf[(Long,Long)]
))
// 定义一个值状态,保存当前到达的数据个数
lazy val countState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("count", classOf[Long]))
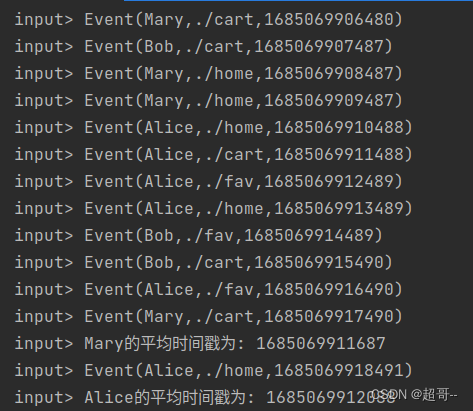
override def flatMap(in: Event, collector: Collector[String]): Unit = {
avgTsAggState.add(in)
// 更新count值
val count: Long = countState.value()
countState.update(count+1)
if (countState.value()==5){
collector.collect(s"${in.user}的平均时间戳为: ${avgTsAggState.get()}")
countState.clear()
}
}
}
}
二、Operator State(算子状态)
1.BufferingSinkExample.scala
在下面的例子中,自定义的 SinkFunction 会在CheckpointedFunction 中进行数据缓存,然后统一发送到下游。这个例子演示了列表状态的平均分割重组(event-split redistribution)。
package com.atguigu.chapter06
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala._
import scala.collection.mutable.ListBuffer
object BufferingSinkExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.addSource(new ClickSource)
.assignAscendingTimestamps(_.timestamp)
.addSink(new BufferingSink(10))
env.execute()
}
// 实现自定义SinkFunction
class BufferingSink(threshold: Int) extends SinkFunction[Event] with CheckpointedFunction {
// 定义列表状态,保存要缓冲的数据
var bufferedState: ListState[Event] = _
// 定义本地变量列表
val bufferedList: ListBuffer[Event] = ListBuffer[Event]()
override def invoke(value: Event, context: SinkFunction.Context): Unit = {
// 缓冲数据
bufferedList+=value
// 判断是否达到阈值
if (bufferedList.size==threshold){
// 输出到外部系统,打印
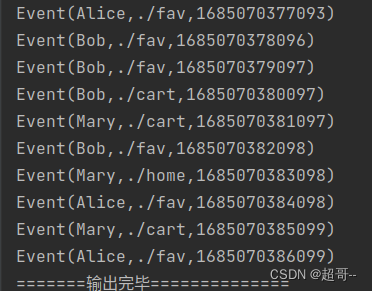
bufferedList.foreach(data=>println(data))
println("=======输出完毕==============")
// 清空缓冲
bufferedList.clear()
}
}
override def snapshotState(context: FunctionSnapshotContext): Unit = {
// 清空状态
bufferedState.clear()
for (data <- bufferedList){
bufferedState.add(data)
}
}
override def initializeState(context: FunctionInitializationContext): Unit = {
bufferedState = context.getOperatorStateStore.getListState(new ListStateDescriptor[Event]("buffered-list", classOf[Event]))
// 判断如果是从故障中恢复,那么就将状态中的数据添加到局部变量中
if (context.isRestored) {
import scala.collection.convert.ImplicitConversions._
for (data <- bufferedState.get()) {
bufferedList += data
}
}
}
}
}
三、Broadcast State(广播状态)
1.BroadcastStateExample.scala
行为匹配案例
package com.atguigu.chapter06
import org.apache.flink.api.common.state.{BroadcastState, MapStateDescriptor, ReadOnlyBroadcastState, ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.datastream.BroadcastStream
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
// 声明样例类
case class Action(userid: String, action: String)
case class Pattern(action1: String, action2: String)
object BroadcastStateExample {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 定义数据流
val actionStream: DataStream[Action] = env.fromElements(
Action("Alice", "login"),
Action("Alice", "pay"),
Action("Bob", "login"),
Action("Bob", "buy")
)
// 定义模式流,读取指定的行为模式
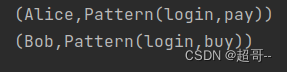
val patternStream: DataStream[Pattern] = env.fromElements(
Pattern("login", "pay"),
Pattern("login", "buy")
)
// 定义广播状态的描述器
val patterns = new MapStateDescriptor[Unit, Pattern]("patterns", classOf[Unit], classOf[Pattern])
val broadcastStream: BroadcastStream[Pattern] = patternStream.broadcast(patterns)
// 连接两条流,进行处理
actionStream.keyBy(_.userid)
.connect(broadcastStream)
.process(new PatternEvaluation)
.print()
env.execute()
}
// 实现自定义的KeyedbroadcastProcessFunction
class PatternEvaluation extends KeyedBroadcastProcessFunction[String,Action,Pattern,(String,Pattern)]{
// 定义值状态,保存上一次用户行为
lazy val prevActionState: ValueState[String] = getRuntimeContext.getState(new ValueStateDescriptor[String]("prev-action", classOf[String]))
override def processElement(value: Action, ctx: KeyedBroadcastProcessFunction[String, Action, Pattern, (String, Pattern)]#ReadOnlyContext, out: Collector[(String, Pattern)]): Unit = {
// 从广播状态中获取行为数据
val pattern= ctx.getBroadcastState(new MapStateDescriptor[Unit, Pattern]("patterns", classOf[Unit], classOf[Pattern]))
.get(Unit)
// 从值状态中获取上次的行为
val prevAction: String = prevActionState.value()
if (pattern != null && prevAction != null){
if (pattern.action1==prevAction && pattern.action2==value.action){
out.collect((ctx.getCurrentKey,pattern))
}
}
// 保存状态
prevActionState.update(value.action)
}
override def processBroadcastElement(value: Pattern, ctx: KeyedBroadcastProcessFunction[String, Action, Pattern, (String, Pattern)]#Context, out: Collector[(String, Pattern)]): Unit = {
val bcState: BroadcastState[Unit, Pattern] = ctx.getBroadcastState(new MapStateDescriptor[Unit, Pattern]("patterns", classOf[Unit], classOf[Pattern]))
bcState.put(Unit,value)
}
}
}
总结
这次记录就到这里.


![[RSA议题分析] eBPF Warfare - Detecting Kernel eBPF Rootkits with Tracee](https://img-blog.csdnimg.cn/4e609603a50b464f897eddc98c68c757.png#pic_center)

![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations](https://img-blog.csdnimg.cn/d3d437eb34974ad9b728734b20453303.png#pic_center)