声明:python不同于其他语言的最厉害之处就在于其他的第三方库可以实现不同的功能,但是在学习其他第三方库之前,我们还需要学习完python语言的基础。基础我们都学过,但是总有一些知识点平时很少使用,再碰到很陌生。这里我重新看一篇python基础的博客,把里面针对个人不怎么友好的记录下来,也可以当作一种复习,接下来我们就开始学习第三方库的知识了。
一.基础与环境
1.编程语言
不同的编程语言有不同的规定:
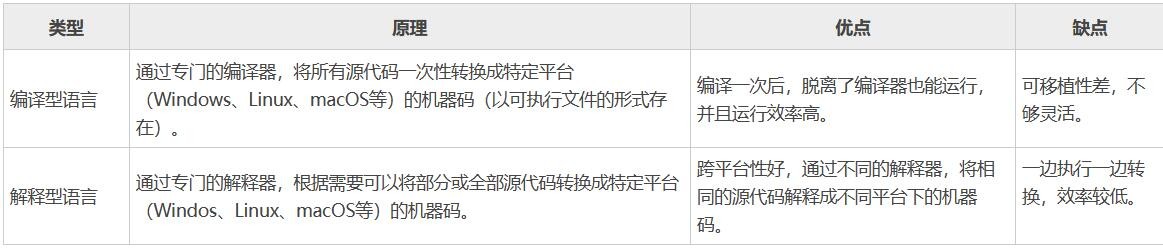
- 有的编程语言要求必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序(比如 Windows 下的 .exe 文件),比如C语言、C++、Golang、汇编语言等,它们都属于编译型语言,使用的转换工具称为编译器。
- 有的编程语言可以一边执行一边转换,需要哪些源代码就转换哪些源代码,不会生成可执行程序,比如 Python、JavaScript、PHP、Shell 等,这类编程语言称为解释型语言,使用的转换工具称为解释器。
2.Anaconda神器
想要在程序中使用第三方库,必须先手动安装它们,可以借助 pip 包管理器,但有些情况下,用 pip 安装库并不是很方便,比如说,一次性安装多个库时,pip 只能一个一个地安装,需要编写各种各样的 pip 命令,费时费力。再比如,使用 pip 安装不同版本的库时(例如不同版本的 Pandas),还要考虑两者的兼容性问题,否则很容易造成混乱甚至错误。
鉴于此,我们可以使用Anaconda,它 提供有 600 多个与科学计算相关的第三方库,安装 Anaconda 的过程中,会顺带安装一些常用的库,比如 Pillow、Numpy、Matplotlib 等。根据需要,你可以对这些库做更新或者卸载等操作。
Anaconda本身也是一个python的IDE,但是他没有图像化界面,只能使用命令行编译python文件。我们可以使用它来管理我们的pycharm的第三方库,只不过我们需要把pycharm的解释器设置为Anaconda,然后通过Anaconda管理第三方库。
3.手机python环境
我们平时的操作都是在电脑上进行的,如果你想在手机端编写python文件,编译和执行,可以使用 QPython 来编写、运行 Python 程序。
QPython 是一个专门在安卓设备上运行 Python 程序的软件,包含 Python 解释器、执行 Python 代码的终端(Terminal)、编写 Python 程序的编辑器等。QPython 既能运行 Python 2 版本的程序,也能运行 Python 3 版本的程序。打开应用商店,搜索“QPython”,就可以下载并安装它。
其实,远不止只有这一个软件,国内也推出了一些python手机端的IDE,只要你去找,在手机上配置一个python的IDE还是很快的。
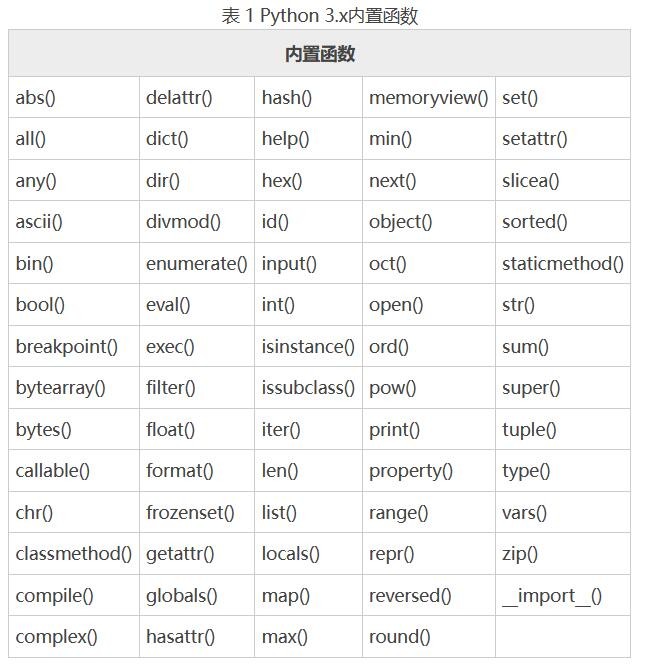
4.内置函数
所谓内置函数,即你不导入任何库的情况下就可以使用的函数。
于此同时,也意味着你自定义函数时,需要避开这些关键字。
二.结构方法
1.三目运算符
在其他语言中我们都很少使用三目运算符,更不谈在python中了。在python中使用if语句来实现三目运算符。
使用 if else 实现三目运算符(条件运算符)的格式如下:
exp1 if contion else exp2
condition 是判断条件,exp1 和 exp2 是两个表达式。如果 condition 成立(结果为真),就执行 exp1,并把 exp1 的结果作为整个表达式的结果;如果 condition 不成立(结果为假),就执行 exp2,并把 exp2 的结果作为整个表达式的结果。
前面的语句max = a if a>b else b的含义是:
- 如果 a>b 成立,就把 a 作为整个表达式的值,并赋给变量 max;
- 如果 a> b 不成立,就把 b 作为整个表达式的值,并赋给变量 max。
2.bytes类
在Python中,bytes是一种数据类型,用于表示字节序列。bytes对象是不可变的,它由0到255的整数构成,可以通过字面量或使用bytes()函数创建。
以下是一些常见的方式来创建bytes对象:
- 使用前缀为
b的字符串字面量:
my_bytes = b'hello'
- 使用
bytes()构造函数:
my_bytes = bytes([72, 101, 108, 108, 111])
- 使用十六进制字符串:
my_bytes = bytes.fromhex('48656c6c6f')
bytes对象和Python的其他字符串类型(如str和bytearray)之间可以进行转换。要将bytes对象转换为字符串对象,可以使用decode()方法:
my_bytes = b'hello'
my_string = my_bytes.decode('utf-8')
print(my_string) # 输出:hello
要将字符串对象转换为bytes对象,可以使用encode()方法:
my_string = 'hello'
my_bytes = my_string.encode('utf-8')
print(my_bytes) # 输出:b'hello'
3.运算符优先级
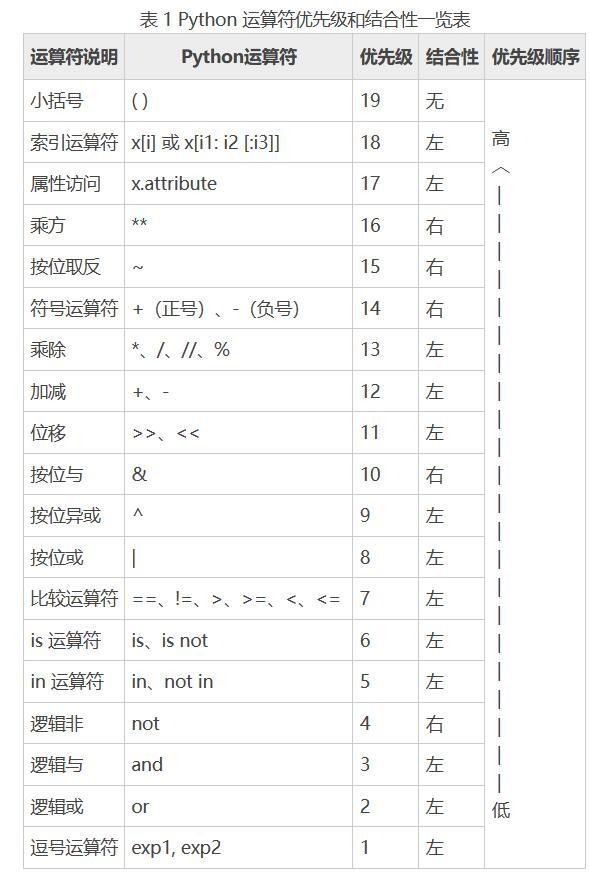
这么多的运算符,显然不可能全部记住,推荐不清楚运算符的优先级时根据你要运算的顺序使用括号。
4.数据结构
python中经常使用的数据结构有列表、元组、字典和集合四种。
详细的我已经专门写了一篇博客,点击这里查看原文。
5.字符串方法
以下是 Python 中常用的字符串方法:
str.capitalize():将字符串的首字母大写。str.lower():将字符串中的所有字母转换为小写形式。str.upper():将字符串中的所有字母转换为大写形式。str.title():将字符串中每个单词的首字母大写。str.swapcase():将字符串中的大小写互换。str.strip([chars]):返回移除字符串开头和结尾指定字符后生成的新字符串。str.replace(old, new[, count]):用新字符串替换旧字符串,可选参数 count 指定替换次数,默认替换所有匹配项。str.split([sep[, maxsplit]]):将字符串按分隔符切分成列表。str.join(iterable):合并一个可迭代对象中的元素为一个字符串,以 str 为分隔符。str.startswith(prefix[, start[, end]]):检查字符串是否以指定前缀开头。str.endswith(suffix[, start[, end]]):检查字符串是否以指定后缀结尾。str.find(sub[, start[, end]]):查找子字符串第一次出现的位置,未找到返回 -1。str.index(sub[, start[, end]]):查找子字符串第一次出现的位置,未找到抛出 ValueError 异常。str.count(sub[, start[, end]]):计算子字符串在字符串中出现的次数。str.format(*args, **kwargs):格式化字符串,可使用位置参数或关键字参数指定替换值。
此外,还有很多其他的字符串方法,可以使用 help(str) 命令查看完整列表。
三.流程控制方法
1.assert
assert 语句,又称断言语句,可以看做是功能缩小版的 if 语句,它用于判断某个表达式的值,如果值为真,则程序可以继续往下执行;反之,Python 解释器会报 AssertionError 错误。
assert 语句的语法结构为:assert 表达式
assert 语句的执行流程可以用 if 判断语句表示,如下所示:
if 表达式==True:
程序继续执行
else:
程序报 AssertionError 错误
有人可能会问,明明 assert 会令程序崩溃,为什么还要使用它呢?这是因为,与其让程序在晚些时候崩溃,不如在错误条件出现时,就直接让程序崩溃,这有利于我们对程序排错,提高程序的健壮性。因此,assert 语句通常用于检查用户的输入是否符合规定,还经常用作程序初期测试和调试过程中的辅助工具。
下面的程序演示了 assert 语句的用法:
mathmark = int(input()) #断言数学考试分数是否位于正常范围内
assert 0 <= mathmark <= 100 #只有当 mathmark 位于 [0,100]范围内,程序才会继续执行
print("数学考试分数为:",mathmark)
2.break和continue
我们知道,在执行 while 循环或者 for 循环时,只要循环条件满足,程序将会一直执行循环体,不停地转圈。但在某些场景,我们可能希望在循环结束前就强制结束循环,Python 提供了 2 种强制离开当前循环体的办法:
- 使用 continue 语句,可以跳过执行本次循环体中剩余的代码,转而执行下一次的循环。
- 只用 break 语句,可以完全终止当前循环。
这就好比在操场上跑步,原计划跑 10 圈,可是当跑到第 2 圈的时候,突然想起有急事要办,于是果断停止跑步并离开操场,这就相当于使用了 break 语句提前终止了循环。和 break 语句相比,continue 语句的作用则没有那么强大,它只会终止执行本次循环中剩下的代码,直接从下一次循环继续执行。
仍然以在操作跑步为例,原计划跑 10 圈,但当跑到 2 圈半的时候突然接到一个电话,此时停止了跑步,当挂断电话后,并没有继续跑剩下的半圈,而是直接从第 3 圈开始跑。
3.推导式
推导式(又称解析器),是 Python 独有的一种特性。使用推导式可以快速生成列表、元组、字典以及集合类型的数据,因此推导式又可细分为列表推导式、元组推导式、字典推导式以及集合推导式。这里以列表推导式为例解释:
列表推导式的语法格式如下:
[表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] ]
此格式中,[if 条件表达式] 不是必须的,可以使用,也可以省略。
通过列表推导式的语法格式,明显会感觉到它和 for 循环存在某些关联。其实,除去 [if 条件表达式] 部分,其余各部分的含义以及执行顺序和 for 循环是完全一样的(表达式其实就是 for 循环中的循环体),即它的执行顺序如下所示:
for 迭代变量 in 可迭代对象
表达式
既然它可以理解为一个for循环,那么它同样也是可以嵌套的,比如:
d_list = [(x, y) for x in range(5) for y in range(4)]
# d_list列表包含20个元素
print(d_list)
上面代码中,x 是遍历 range(5) 的迭代变量(计数器),因此该 x 可迭代 5 次;y 是遍历 range(4) 的计数器,因此该 y 可迭代 4 次。因此,该(x,y)表达式一共会迭代 20 次。上面的 for 表达式相当于如下嵌套循环:
dd_list = []
for x in range(5):
for y in range(4):
dd_list.append((x, y))
4.zip()函数
zip() 函数是 Python 内置函数之一,它可以将多个序列(列表、元组、字典、集合、字符串以及 range() 区间构成的列表)“压缩”成一个 zip 对象。所谓“压缩”,其实就是将这些序列中对应位置的元素重新组合,生成一个个新的元组。
my_list = [11,12,13]
my_tuple = (21,22,23)
print(list(zip(my_list,my_tuple)))
注意它的返回值是一个zip对象,所以需要把它变成你想要的数据结构。
5.reserved()函数
eserved() 是 Pyton 内置函数之一,其功能是对于给定的序列(包括列表、元组、字符串以及 range(n) 区间),该函数可以返回一个逆序序列的迭代器(用于遍历该逆序序列)。
reserved() 函数的语法格式如下:reversed(seq)
其中,seq 可以是列表,元素,字符串以及 range() 生成的区间列表。
使用 reversed() 函数进行逆序操作,并不会修改原来序列中元素的顺序,例如:
a = [1,2,3,4,5]
#将列表进行逆序
print(list(reversed(a)))
print("a=",a)
程序执行结果为:
[5, 4, 3, 2, 1]
a= [1, 2, 3, 4, 5]
四.函数
1.局部函数
ython 函数内部可以定义变量,这样就产生了局部变量,有读者可能会问,Python 函数内部能定义函数吗?答案是肯定的。Python 支持在函数内部定义函数,此类函数又称为局部函数。
例如下面这个程序:
#全局函数
def outdef ():
name = "所在函数中定义的 name 变量"
#局部函数
def indef():
nonlocal name
print(name) #修改name变量的值
name = "局部函数中定义的 name 变量"
indef()
#调用全局函数
outdef()
程序执行结果为: 所在函数中定义的 name 变量
2.偏函数
简单的理解偏函数,它是对原始函数的二次封装,是将现有函数的部分参数预先绑定为指定值,从而得到一个新的函数,该函数就称为偏函数。相比原函数,偏函数具有较少的可变参数,从而降低了函数调用的难度。
定义偏函数,需使用 partial 关键字(位于 functools 模块中),其语法格式如下:
偏函数名 = partial(func, *args, **kwargs)
其中,func 指的是要封装的原函数,*args 和 **kwargs 分别用于接收无关键字实参和关键字实参。
例如下面代码:
from functools import partial
#定义个原函数
def display(name,age):
print("name:",name,"age:",age)
#定义偏函数,其封装了 display() 函数,并为 name 参数设置了默认参数
GaryFun = partial(display,name = 'Gary')
#由于 name 参数已经有默认值,因此调用偏函数时,可以不指定
GaryFun(age = 13)
运行结果为:
name: Gary age: 13
注意,此程序的第 8 行代码中,必须采用关键字参数的形式给 age 形参传参,因为如果以无关键字参数的方式,该实参将试图传递给 name 形参,Python解释器会报 TypeError 错误。
3.函数参数
Python 还支持将函数以参数的形式传入其他函数中。例如:
def add (a,b):
return a+b
def multi(a,b):
return a*b
def my_def(a,b,dis):
return dis(a,b)
#求 2 个数的和
print(my_def(3,4,add))
#求 2 个数的乘积
print(my_def(3,4,multi))
程序执行结果为:
7
12
通过分析上面程序不难看出,通过使用函数作为参数,可以在调用函数时动态传入函数,从而实现动态改变函数中的部分实现代码,在不同场景中赋予函数不同的作用。
4.闭包函数
闭包,又称闭包函数或者闭合函数,其实和前面讲的嵌套函数类似,不同之处在于,闭包中外部函数返回的不是一个具体的值,而是一个函数。一般情况下,返回的函数会赋值给一个变量,这个变量可以在后面被继续执行调用。
例如,计算一个数的 n 次幂,用闭包可以写成下面的代码:
#闭包函数,其中 exponent 称为自由变量
def nth_power(exponent):
def exponent_of(base):
return base ** exponent
return exponent_of # 返回值是 exponent_of 局部函数
square = nth_power(2) # 计算一个数的平方
cube = nth_power(3) # 计算一个数的立方
print(square(2)) # 计算 2 的平方
print(cube(2)) # 计算 2 的立方
运行结果为:
4
8
在上面程序中,外部函数 nth_power() 的返回值是函数 exponent_of(),而不是一个具体的数值。
5.lambda表达式(匿名函数)
lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda 表达式的语法格式如下: name = lambda [list] : 表达式
其中,定义 lambda 表达式,必须使用 lambda 关键字;[list] 作为可选参数,等同于定义函数是指定的参数列表;value 为该表达式的名称。
举个例子,如果设计一个求 2 个数之和的函数,使用普通函数的方式,定义如下:
def add(x, y):
return x+ y
print(add(3,4))
程序执行结果为:
7
由于上面程序中,add() 函数内部仅有 1 行表达式,因此该函数可以直接用 lambda 表达式表示:
add = lambda x,y:x+y
print(add(3,4))
程序输出结果为:
7
可以这样理解 lambda 表达式,其就是简单函数(函数体仅是单行的表达式)的简写版本。相比函数,lamba 表达式具有以下 2 个优势:
- 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
- 对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
6.解释器函数
这里的解释器函数指的是eval()和exec()函数,这是我个人的叫法。
eval() 和 exec() 函数的功能是相似的,都可以执行一个字符串形式的 Python 代码(代码以字符串的形式提供),相当于一个 Python 的解释器。二者不同之处在于,eval() 执行完要返回结果,而 exec() 执行完不返回结果。
a=10
b=20
c=30
g={'a':6, 'b':8} #定义一个字典
t={'b':100, 'c':10} #定义一个字典
print(eval('a+b+c', g, t)) #定义一个字典 116
输出结果为:
116
7.函数式编程
所谓函数式编程,是指代码中每一块都是不可变的,都由纯函数的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出。
Python 仅对函数式编程提供了部分支持,主要包括 map()、filter() 和 reduce() 这 3 个函数,它们通常都结合 lambda 匿名函数一起使用。
- map() 函数的基本语法格式如下:
map(function, iterable)
其中,function 参数表示要传入一个函数,其可以是内置函数、自定义函数或者 lambda 匿名函数;iterable 表示一个或多个可迭代对象,可以是列表、字符串等。
map() 函数的功能是对可迭代对象中的每个元素,都调用指定的函数,并返回一个 map 对象。
注意,该函数返回的是一个 map 对象,不能直接输出,可以通过 for 循环或者 list() 函数来显示。
- filter()函数的基本语法格式如下:
filter(function, iterable)
此格式中,funcition 参数表示要传入一个函数,iterable 表示一个可迭代对象。
filter() 函数的功能是对 iterable 中的每个元素,都使用 function 函数判断,并返回 True 或者 False,最后将返回 True 的元素组成一个新的可遍历的集合。
- reduce() 函数通常用来对一个集合做一些累积操作,其基本语法格式为:
reduce(function, iterable)
其中,function 规定必须是一个包含 2 个参数的函数;iterable 表示可迭代对象。
注意,由于 reduce() 函数在 Python 3.x 中已经被移除,放入了 functools 模块,因此在使用该函数之前,需先导入 functools 模块。
五.类和对象
1.相关术语
面向对象中,常用术语包括:
- 类:可以理解是一个模板,通过它可以创建出无数个具体实例。比如,前面编写的 tortoise 表示的只是乌龟这个物种,通过它可以创建出无数个实例来代表各种不同特征的乌龟(这一过程又称为类的实例化)。
- 对象:类并不能直接使用,通过类创建出的实例(又称对象)才能使用。这有点像汽车图纸和汽车的关系,图纸本身(类)并不能为人们使用,通过图纸创建出的一辆辆车(对象)才能使用。
- 属性:类中的所有变量称为属性。例如,tortoise 这个类中,bodyColor、footNum、weight、hasShell 都是这个类拥有的属性。
- 方法:类中的所有函数通常称为方法。不过,和函数所有不同的是,类方法至少要包含一个 self 参数(后续会做详细介绍)。例如,tortoise 类中,crawl()、eat()、sleep()、protect() 都是这个类所拥有的方法,类方法无法单独使用,只能和类的对象一起使用。
2.基础格式
鉴于都有一定了解,直接举个例子:
class tortoise:
bodyColor = "绿色"
footNum = 4
weight = 10
hasShell = True
#会爬
def crawl(self):
print("乌龟会爬")
#会吃东西
def eat(self):
print("乌龟吃东西")
#会睡觉
def sleep(self):
print("乌龟在睡觉")
#会缩到壳里
def protect(self):
print("乌龟缩进了壳里")
3.__init__()类构造方法
在创建类时,我们可以手动添加一个 init() 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
构造方法用于创建对象时使用,每当创建一个类的实例对象时,Python 解释器都会自动调用它。Python 类中,手动添加构造方法的语法格式如下:
def __init__(self,...):
代码块
注意,此方法的方法名中,开头和结尾各有 2 个下划线,且中间不能有空格。Python 中很多这种以双下划线开头、双下划线结尾的方法,都具有特殊的意义。另外,__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。也就是说,类的构造方法最少也要有一个 self 参数。
注意,即便不手动为类添加任何构造方法,Python 也会自动为类添加一个仅包含 self 参数的构造方法。
仅包含 self 参数的 init() 构造方法,又称为类的默认构造方法。
下面我们举个例子来通过该函数创建一个实例:
class CLanguage :
# 下面定义了2个类变量
name = "CSDN@终究还是散了"
add = "https://blog.csdn.net/weixin_51496226?spm=1000.2115.3001.5343"
def __init__(self,name,add):
#下面定义 2 个实例变量
self.name = name
self.add = add
print(name,"网址为:",add)
# 下面定义了一个say实例方法
def say(self, content):
print(content)
# 将该CLanguage对象赋给clanguage变量
clanguage = CLanguage("CSDN@终究还是散了","https://blog.csdn.net/weixin_51496226?spm=1000.2115.3001.5343")
4.封装
和其它面向对象的编程语言(如 C++、Java)不同,Python 类中的变量和函数,不是公有的(类似 public 属性),就是私有的(类似 private),这 2 种属性的区别如下:
- public:公有属性的类变量和类函数,在类的外部、类内部以及子类(后续讲继承特性时会做详细介绍)中,都可以正常访问;
- private:私有属性的类变量和类函数,只能在本类内部使用,类的外部以及子类都无法使用。
但是,Python 并没有提供 public、private 这些修饰符。为了实现类的封装,Python 采取了下面的方法:
- 默认情况下,Python 类中的变量和方法都是公有(public)的,它们的名称前都没有下划线(_);
- 如果类中的变量和函数,其名称以双下划线“__”开头,则该变量(函数)为私有变量(私有函数),其属性等同于 private。
#定义个私有方法
def __display(self):
print(self.__name,self.__add)
例如上述函数就是一个私有函数,它使用的变量也是私有变量。
5.继承
继承机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),但又不想直接将现有类代码复制给新类。也就是说,通过使用继承这种机制,可以轻松实现类的重复使用。
举个例子,假设现有一个 Shape 类,该类的 draw() 方法可以在屏幕上画出指定的形状,现在需要创建一个 Form 类,要求此类不但可以在屏幕上画出指定的形状,还可以计算出所画形状的面积。使用类的继承机制,实现方法为:让 Form 类继承 Shape 类,这样当 Form 类对象调用 draw() 方法时,Python 解释器会先去 Form 中找以 draw 为名的方法,如果找不到,它还会自动去 Shape 类中找。如此,我们只需在 Form 类中添加计算面积的方法即可,示例代码如下:
class Shape:
def draw(self,content):
print("画",content)
class Form(Shape):
def area(self): #....
print("此图形的面积为...")
上面代码中,class Form(Shape) 就表示 Form 继承 Shape。
Python 中,实现继承的类称为子类,被继承的类称为父类(也可称为基类、超类)。因此在上面这个样例中,Form 是子类,Shape 是父类。
子类继承父类时,只需在定义子类时,将父类(可以是多个)放在子类之后的圆括号里即可。语法格式如下:
class 类名(父类1, 父类2, ...):
#类定义部分
注意,如果该类没有显式指定继承自哪个类,则默认继承 object 类(object 类是 Python 中所有类的父类,即要么是直接父类,要么是间接父类)。另外,Python 的继承是多继承机制(和 C++ 一样),即一个子类可以同时拥有多个直接父类。
注意,有读者可能还听说过“派生”这个词汇,它和继承是一个意思,只是观察角度不同而已。换句话话,继承是相对子类来说的,即子类继承自父类;而派生是相对于父类来说的,即父类派生出子类。
使用多继承经常需要面临的问题是,多个父类中包含同名的类方法。对于这种情况,Python 的处置措施是:根据子类继承多个父类时这些父类的前后次序决定,即排在前面父类中的类方法会覆盖排在后面父类中的同名类方法。
6.type()函数
我们知道,type() 函数属于 Python 内置函数,通常用来查看某个变量的具体类型。其实,type() 函数还有一个更高级的用法,即创建一个自定义类型(也就是创建一个类)。
type() 函数的语法格式有 2 种,分别如下:
type(obj)
type(name, bases, dict)
以上这 2 种语法格式,各参数的含义及功能分别是:
- 第一种语法格式用来查看某个变量(类对象)的具体类型,obj 表示某个变量或者类对象。
- 第二种语法格式用来创建类,其中 name 表示类的名称;bases 表示一个元组,其中存储的是该类的父类;dict 表示一个字典,用于表示类内定义的属性或者方法。
这里重点介绍 type() 函数的另一种用法,即创建一个新类,先来分析一个样例:
#定义一个实例方法
def say(self):
print("我要学 Python!")
#使用 type() 函数创建类
CLanguage = type("CLanguage",(object,),dict(say = say, name = "CSDN@终究还是散了"))
#创建一个 CLanguage 实例对象
clangs = CLanguage()
#调用 say() 方法和 name 属性
clangs.say()
print(clangs.name)
注意,Python 元组语法规定,当 (object,) 元组中只有一个元素时,最后的逗号(,)不能省略。
可以看到,此程序中通过 type() 创建了类,其类名为 CLanguage,继承自 objects 类,且该类中还包含一个 say() 方法和一个 name 属性。
7.多态
类的多态特性,要满足以下 2 个前提条件:
- 继承:多态一定是发生在子类和父类之间;
- 重写:子类重写了父类的方法。
class WhoSay:
def say(self,who):
who.say()
class CLanguage:
def say(self):
print("调用的是 Clanguage 类的say方法")
class CPython(CLanguage):
def say(self):
print("调用的是 CPython 类的say方法")
class CLinux(CLanguage):
def say(self):
print("调用的是 CLinux 类的say方法")
a = WhoSay()
#调用 CLanguage 类的 say() 方法
a.say(CLanguage())
#调用 CPython 类的 say() 方法
a.say(CPython())
#调用 CLinux 类的 say() 方法
a.say(CLinux())
可以看到,CPython 和 CLinux 都继承自 CLanguage 类,且各自都重写了父类的 say() 方法。从运行结果可以看出,同一变量 a 在执行同一个 say() 方法时,由于 a 实际表示不同的类实例对象,因此 a.say() 调用的并不是同一个类中的 say() 方法,这就是多态。
六.说明
还有几个点没写,我准备写在下一篇博客,大家期待!