问题
有这样一段代码,编译器会傻傻地做多次 compare 来找到对应分支吗?
#include <stdio.h>
#include <stdlib.h>
int func(int i)
{
return (long)(&i) + i + rand();
}
int test(int flag)
{
int i = 0;
switch (flag) {
case 0:
i += func(i);
break;
case 1:
i += func(i+11);
break;
case 2:
i += func(i+111);
break;
case 3:
i += func(i+112);
break;
case 4:
i += func(i+1123);
break;
case 5:
i += func(i+131);
break;
default:
i += func(i+311);
break;
}
return i;
}
江湖传言,编译器会自动对 switch 做自动优化。使用在线汇编工具 Compiler Explorer 可以很方便地做实验,观察 C 语言对应的汇编代码,我们来看看。
实验
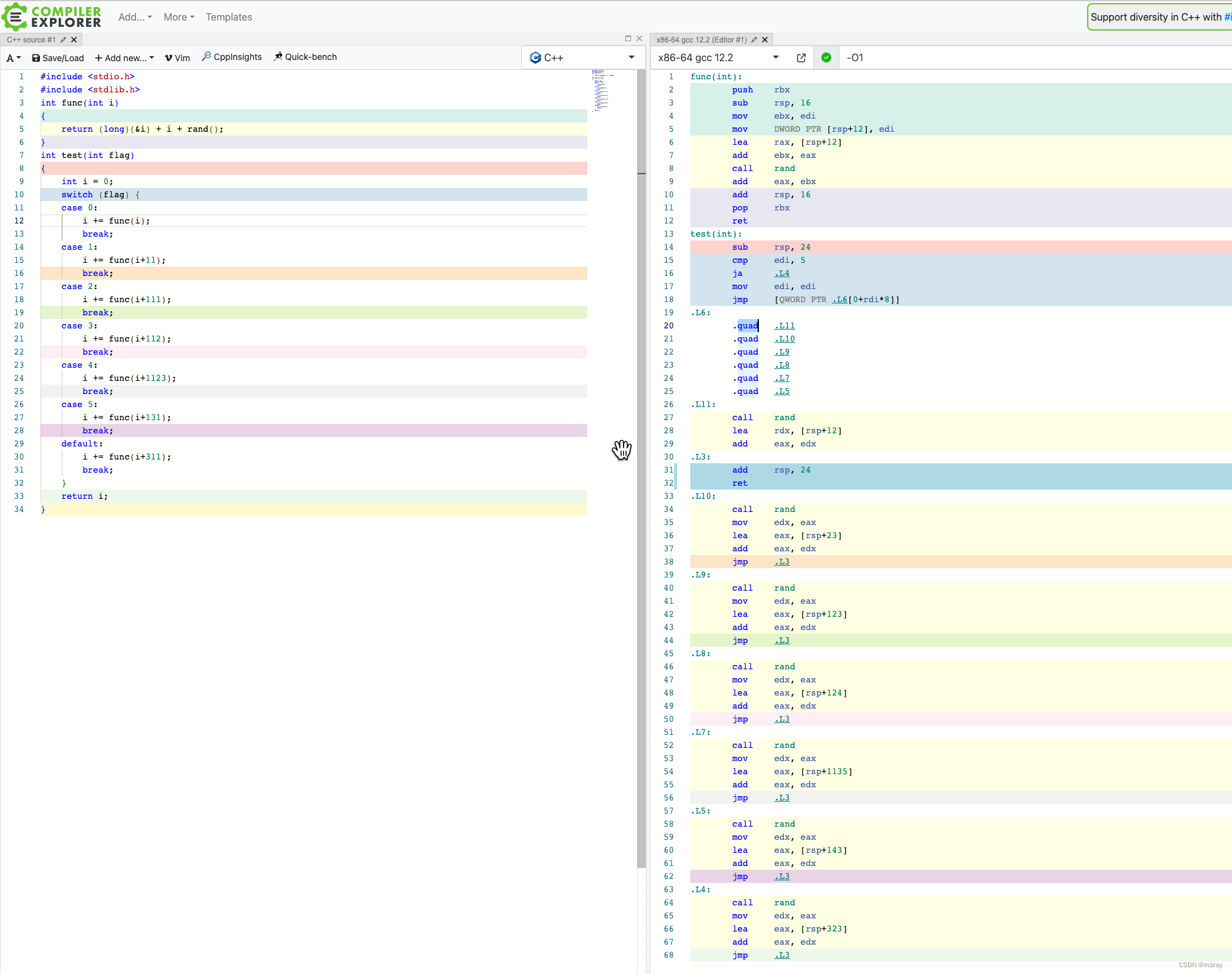
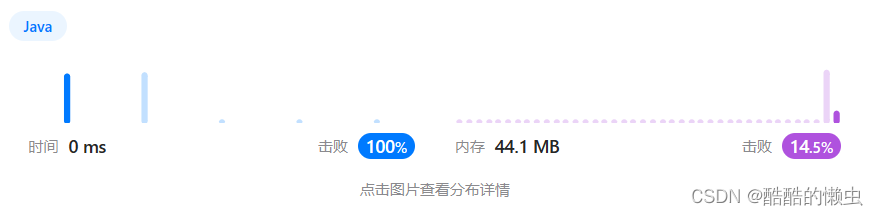
实验效果很好!如下图所示,flag 有 6 个取值,编译器能自动计算出一个 jump table,然后根据 flag 值直接做跳转,把 O(n) 的计算复杂度转化成 O(1),非常高效。代价嘛,则是增加了 jump table 带来的 O(n) 空间复杂度。
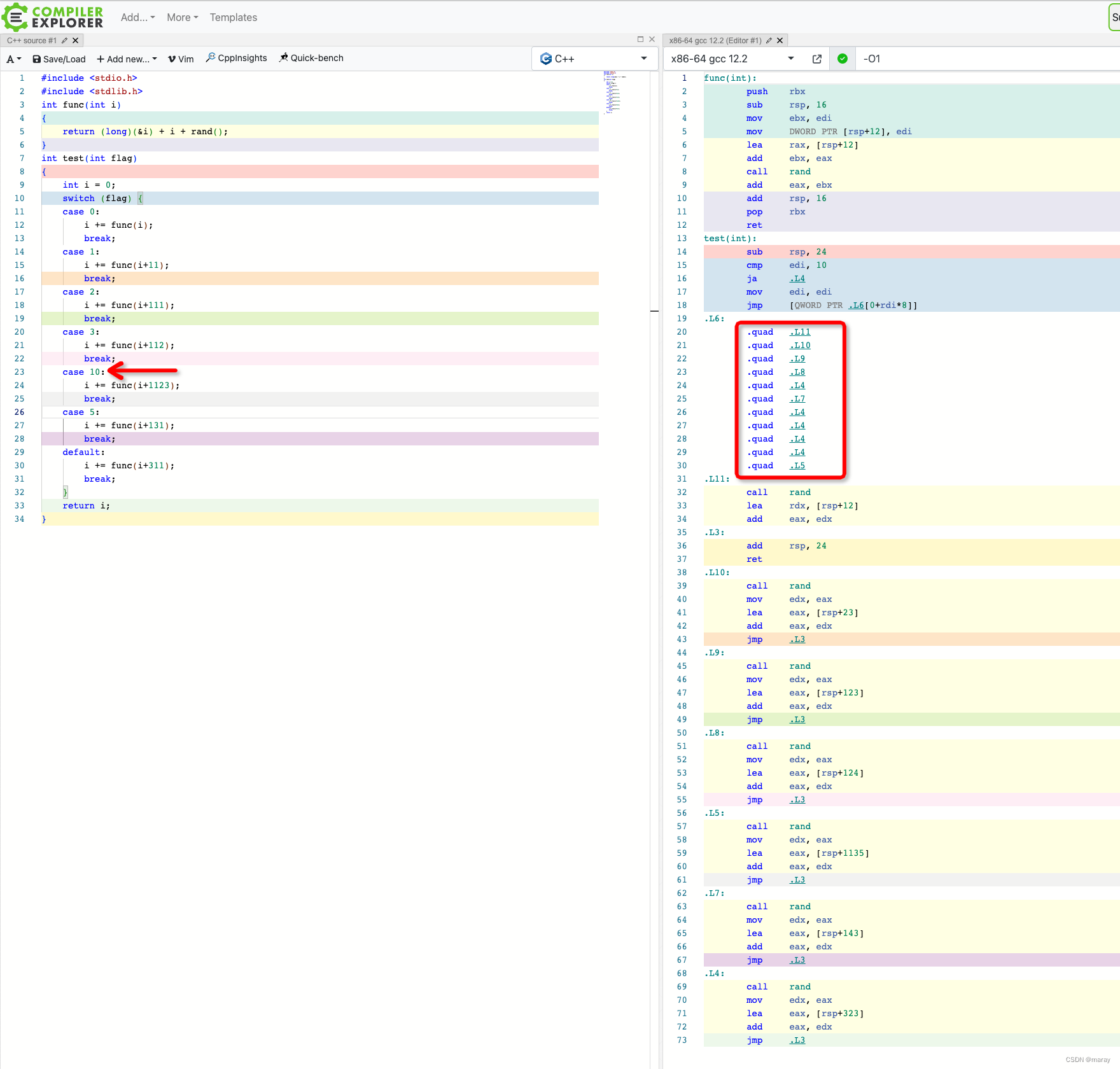
那么,是不是所有场景编译器都能做优化呢?我们把 case 4、case 5 改成两个比较大的值看看。从下图可以发现,优化失效,编译器改用 compare 来定位分支。

我们可以猜测,编译器最擅长对取值连续的 switch case 做优化,比如 flag = 0…5。如果有少许间隔,但是间隔并不大,估计编译器还是可以做好优化。下面试试把 case 4 改成 case 10,可以发现,优化的确依然生效。
总结
当 switch 的取值 “比较连续” 的情况下,编译器会使用 jump table 技术来优化 switch 的执行。当连续性很差的时候,优化效果不佳。
补充
- 如何写出编译器友好的代码
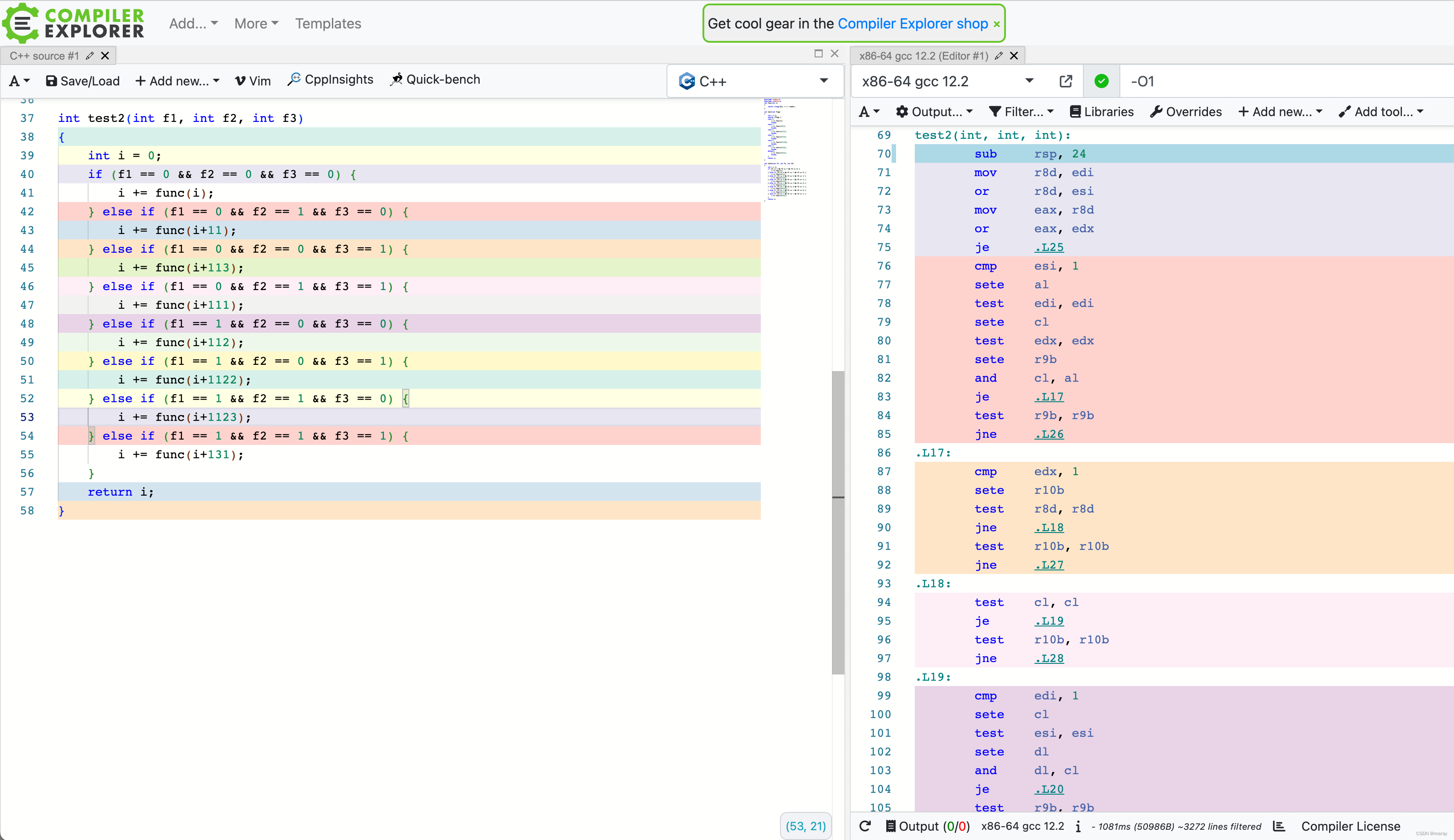
我们的一些 if else 如果能转换成 switch,能让编译器生成更好的代码。因为 if else 对于编译器来说,优化起来更难一些:
2. 离散值的 switch 优化
对于离散值,还是有办法做优化的。核心想法是构建 hash 表,通过查表的方式来做跳转。在存在大量离散值的场景里,hash 查表的方法比 if else 决策树的方法性能更好。详细情况可以参考这篇文章:https://programming.sirrida.de/hashsuper.pdf









![[论文评析]C-Mixup: Improving Generalization in Regression, NeurIPS,2022](https://img-blog.csdnimg.cn/27aacabdd026426caf4615e5dc5d5273.png#pic_center)