背景
python 的APScheduler配置的定时任务会被Miss掉,经常在控制台收到一些Miss的告警信息,就觉得是任务太多导致的,为了定位到具体的原因,看了一些源码,了解到了定时任务的6大模块的协同工作模式。
异常信息及来源
异常信息
Run time of job “check_job_status (trigger: interval[0:00:05], next run at: 2023-04-11 12:05:01 CST)” was missed by 0:00:03.012525
异常信息解析
异常日志表示一个任务(名称为 “check_job_status”)的运行时间被错过了。任务使用了一个 interval 触发器,即每隔 5 秒触发一次。该任务的下一次运行时间应该是在 2023-04-11 12:05:01,CST 时区(中国标准时间)
异常日志来源
任务到了被触发执行的时候,执行器将该任务提交给子线程,执行方法run_job,run_job方法内部会再次校验当前时间和需要触发执行时间的时间差是否超过配置的超时时间(misfire_grace_time),如果超过了,则打印该告警信息。
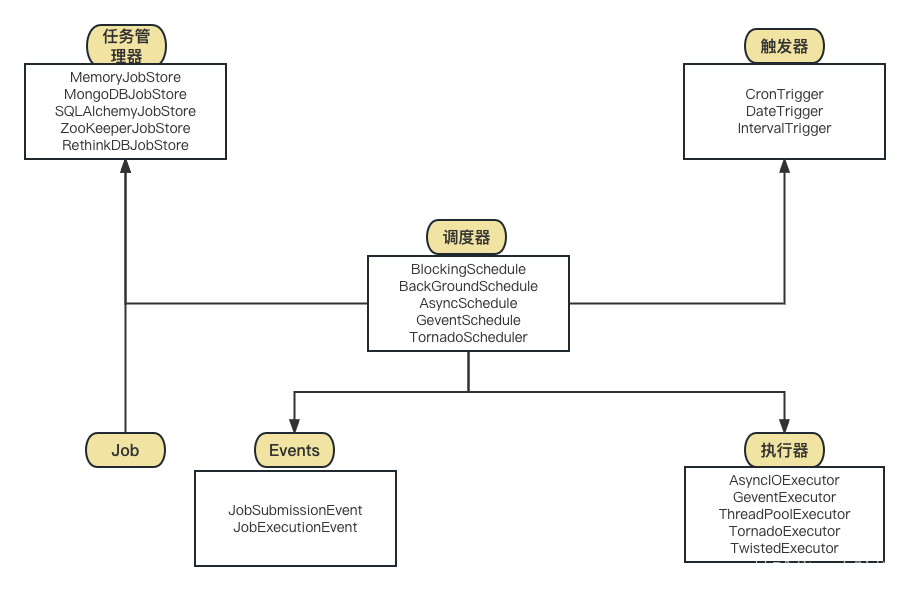
APScheduler 的六大模块
路径下的 executors、jobstores、schedulers、triggers、events、job 这几个模块是协同工作来实现调度任务的。下面是它们之间的关系和工作流程:
-
jobstores 模块:任务存储器,用于存储任务信息和执行计划,包括 MemoryJobStore、SQLAlchemyJobStore、MongoDBJobStore 和 RedisJobStore 等多种实现。jobstores 模块将任务定义和计划信息存储在一个任务列表中,供 schedulers 模块调度任务。
-
triggers 模块:触发器,用于确定任务的执行时间,包括 SimpleTrigger、IntervalTrigger、CronTrigger 等多种实现。triggers 模块提供了不同类型的触发器,用于根据不同的时间或事件条件触发任务的执行。
-
job 模块:任务,用于封装要执行的任务内容,包括 Job 和 AsyncJob 两种实现。job 模块将任务的执行方法和参数封装在一个 Job 对象中,供 schedulers 模块调度。
-
executors 模块:任务执行器,用于执行任务,包括 ThreadPoolExecutor、ProcessPoolExecutor、BlockingScheduler 等多种实现。executors 模块会根据 Job 对象中的执行方法和参数来执行任务,执行结果会被传递给 schedulers 模块。
-
schedulers 模块:调度器,用于调度任务的执行,包括 BlockingScheduler、BackgroundScheduler、AsyncIOScheduler 和 GeventScheduler 等多种实现。schedulers 模块会从 jobstores 模块获取任务列表,并根据 triggers 模块提供的触发器信息,将需要执行的任务交给 executors 模块执行。
-
events 模块:事件管理器,用于管理和触发各种事件,包括 JobExecutionEvent、JobSubmissionEvent 等多种实现。events 模块可以检测任务的执行结果,并触发相应的事件,供开发者进行监控和处理。
下面根据部分业务代码和源码来捋一下定时任务的全流程
一、初始化定时任务对象时,我这里配置ThreadPoolExecutoe, 最多10个线程的线程池(实际不配置的话,默认也是10)
二、 在业务逻辑里添加定时任务:
# 最大实例数为1, interval触发器
cls.schedule.add_job(id=job_id, args=(func,), trigger="interval", max_instances=1, **params)
add_job方法的底层实现如下
/venv/lib/python3.8/site-packages/apscheduler/schedulers/base.py
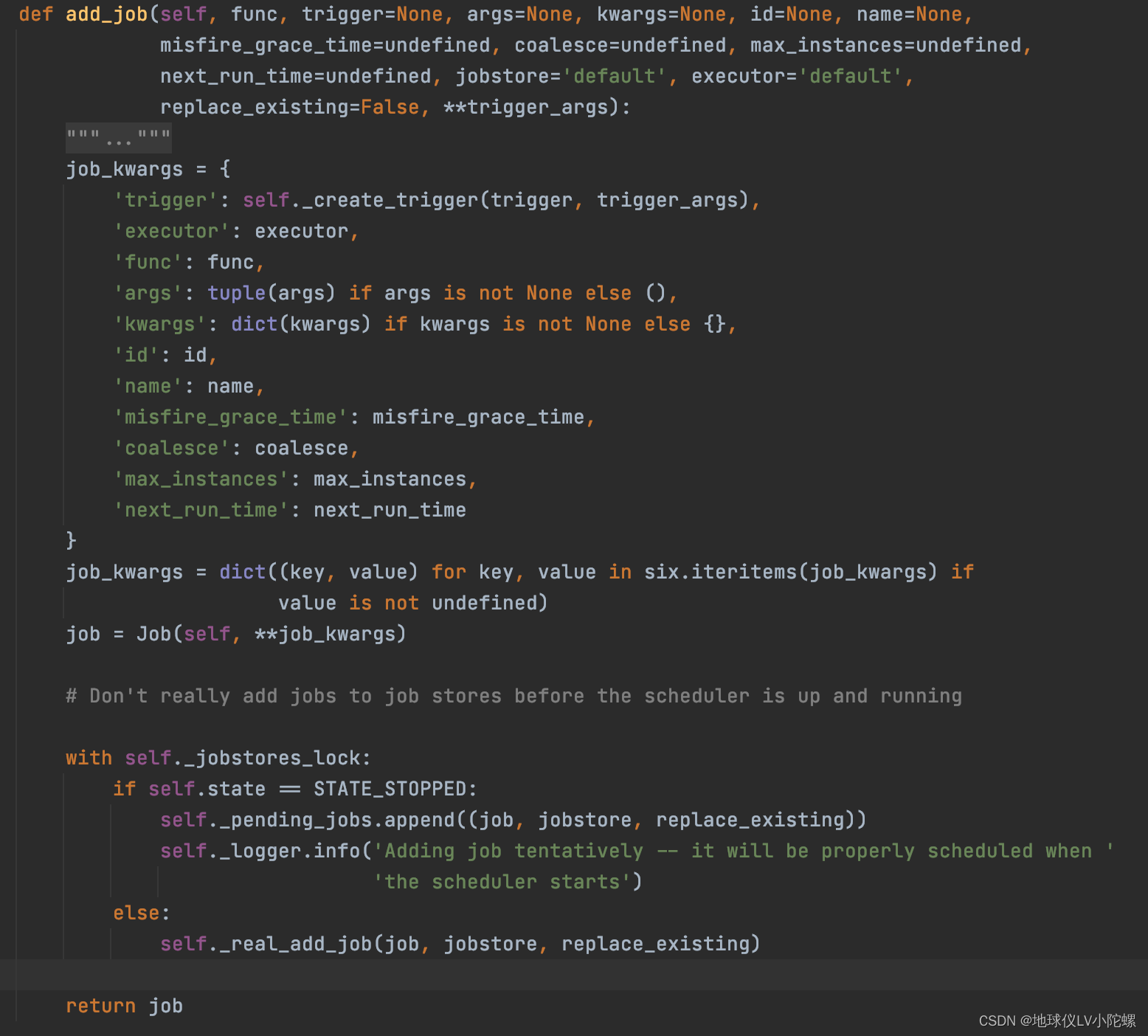
这段源码的自我分析:将任务信息封装成Job对象,然后调用_real_add_job方法将任务添加到任务管理器中,添加时会携带任务信息(执行时间,执行次数,时间间隔等)以及触发器,调度器和下次期望被触发的时间。
三、 调度器会循环校验每个任务的执行时间,如果执行时间到,则获取到任务的触发器,触发器将任务转给执行器,执行器执行任务。具体逻辑在如下的源码中
def _process_jobs(self):
"""
Iterates through jobs in every jobstore, starts jobs that are due and figures out how long
to wait for the next round.
If the ``get_due_jobs()`` call raises an exception, a new wakeup is scheduled in at least
``jobstore_retry_interval`` seconds.
"""
if self.state == STATE_PAUSED:
self._logger.debug('Scheduler is paused -- not processing jobs')
return None
self._logger.debug('Looking for jobs to run')
now = datetime.now(self.timezone)
next_wakeup_time = None
events = []
with self._jobstores_lock:
for jobstore_alias, jobstore in six.iteritems(self._jobstores):
try:
due_jobs = jobstore.get_due_jobs(now)
except Exception as e:
# Schedule a wakeup at least in jobstore_retry_interval seconds
self._logger.warning('Error getting due jobs from job store %r: %s',
jobstore_alias, e)
retry_wakeup_time = now + timedelta(seconds=self.jobstore_retry_interval)
if not next_wakeup_time or next_wakeup_time > retry_wakeup_time:
next_wakeup_time = retry_wakeup_time
# 如果任务还没到触发执行的时候,就pass
continue
for job in due_jobs:
# Look up the job's executor
try:
executor = self._lookup_executor(job.executor)
except BaseException:
self._logger.error(
'Executor lookup ("%s") failed for job "%s" -- removing it from the '
'job store', job.executor, job)
self.remove_job(job.id, jobstore_alias)
continue
run_times = job._get_run_times(now)
run_times = run_times[-1:] if run_times and job.coalesce else run_times
if run_times:
try:
# 这里将任务和任务要触发的时间交给执行器,任务的实例值+1; 如果是线程池执行器,submit_job方法内部会将任务提交到线程池中执行,执行成功后,会将该任务的实例值-1。
executor.submit_job(job, run_times)
except MaxInstancesReachedError:
self._logger.warning(
'Execution of job "%s" skipped: maximum number of running '
'instances reached (%d)', job, job.max_instances)
# 将任务封装成事件,将事件添加到事件列表中
event = JobSubmissionEvent(EVENT_JOB_MAX_INSTANCES, job.id,
jobstore_alias, run_times)
events.append(event)
except BaseException:
self._logger.exception('Error submitting job "%s" to executor "%s"',
job, job.executor)
else:
# 将任务封装成事件,将事件添加到事件列表中
event = JobSubmissionEvent(EVENT_JOB_SUBMITTED, job.id, jobstore_alias,
run_times)
events.append(event)
# Update the job if it has a next execution time.
# Otherwise remove it from the job store.
# 触发器获取到该任务下次需要被触发的时间,并更新任务管理器
job_next_run = job.trigger.get_next_fire_time(run_times[-1], now)
if job_next_run:
job._modify(next_run_time=job_next_run)
jobstore.update_job(job)
else:
self.remove_job(job.id, jobstore_alias)
# Set a new next wakeup time if there isn't one yet or
# the jobstore has an even earlier one
jobstore_next_run_time = jobstore.get_next_run_time()
if jobstore_next_run_time and (next_wakeup_time is None or
jobstore_next_run_time < next_wakeup_time):
next_wakeup_time = jobstore_next_run_time.astimezone(self.timezone)
# Dispatch collected events
# 遍历事件列表 `events`,并分别调用 `_dispatch_event` 方法来处理每个事件。
# 具体地说,`_dispatch_event` 方法会将事件分发给所有已注册的监听器进行处理。遍历监听器列表 `self._listeners`,
# 并分别调用# 每个监听器的 `handle_event` 方法来处理事件。
# 如果监听器处理事件时出现异常,会将异常记录到日志中。处理完所有监听器后,`_dispatch_event` 方法会返回。
# 这样,整个事件分发过程就完成了。通过这个过程,我们可以实现在任务执行成功、失败、被取消等情况下触发相应的事件,并对这些事件进行监听和处理。
#(配置事件管理器的是add_listener方法,可以全局配置的事件管理器,也可以为每个任务配置不同的管理器。)
for event in events:
self._dispatch_event(event)
# Determine the delay until this method should be called again
if self.state == STATE_PAUSED:
wait_seconds = None
self._logger.debug('Scheduler is paused; waiting until resume() is called')
elif next_wakeup_time is None:
wait_seconds = None
self._logger.debug('No jobs; waiting until a job is added')
else:
wait_seconds = min(max(timedelta_seconds(next_wakeup_time - now), 0), TIMEOUT_MAX)
self._logger.debug('Next wakeup is due at %s (in %f seconds)', next_wakeup_time,
wait_seconds)
# 这里的 wait_seconds 就是再次触发_process_jobs方法被调用时,需要阻塞的时间,单位 秒。
return wait_seconds
这段源码的自我分析:调度器会轮训任务管理器中的每一个任务,如果任务要被触发,会将任务交给执行器,同时将任务添加到事件管理列表中。然后获取任务的下一次触发时间,如果没有获取到,则将该任务移除。最后获取一个该方法被循环调用的阻塞时间。
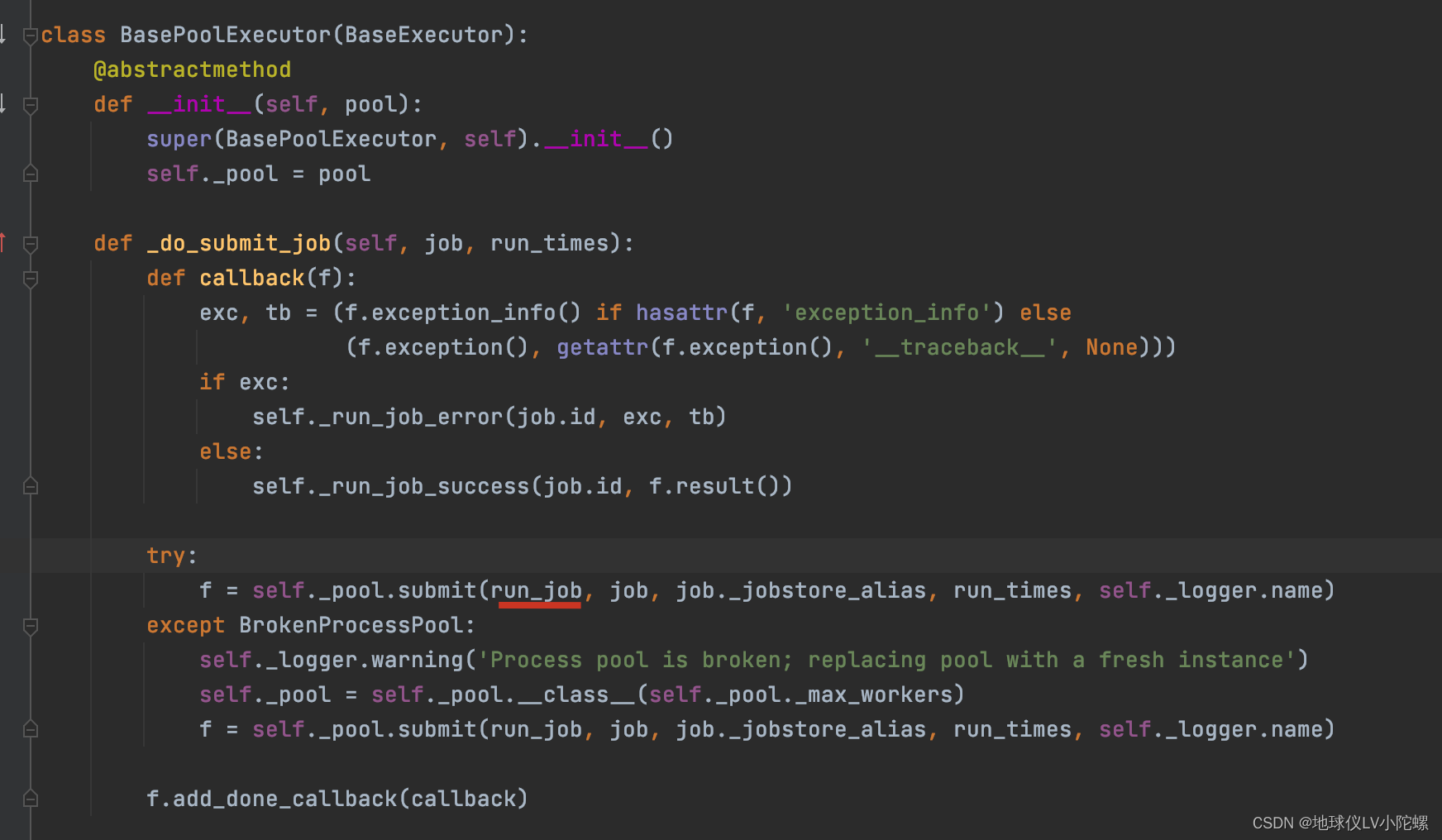
四、 _process_jobs方法实际在调度器启动时就已经被注册调用了,具体的源码如下图:
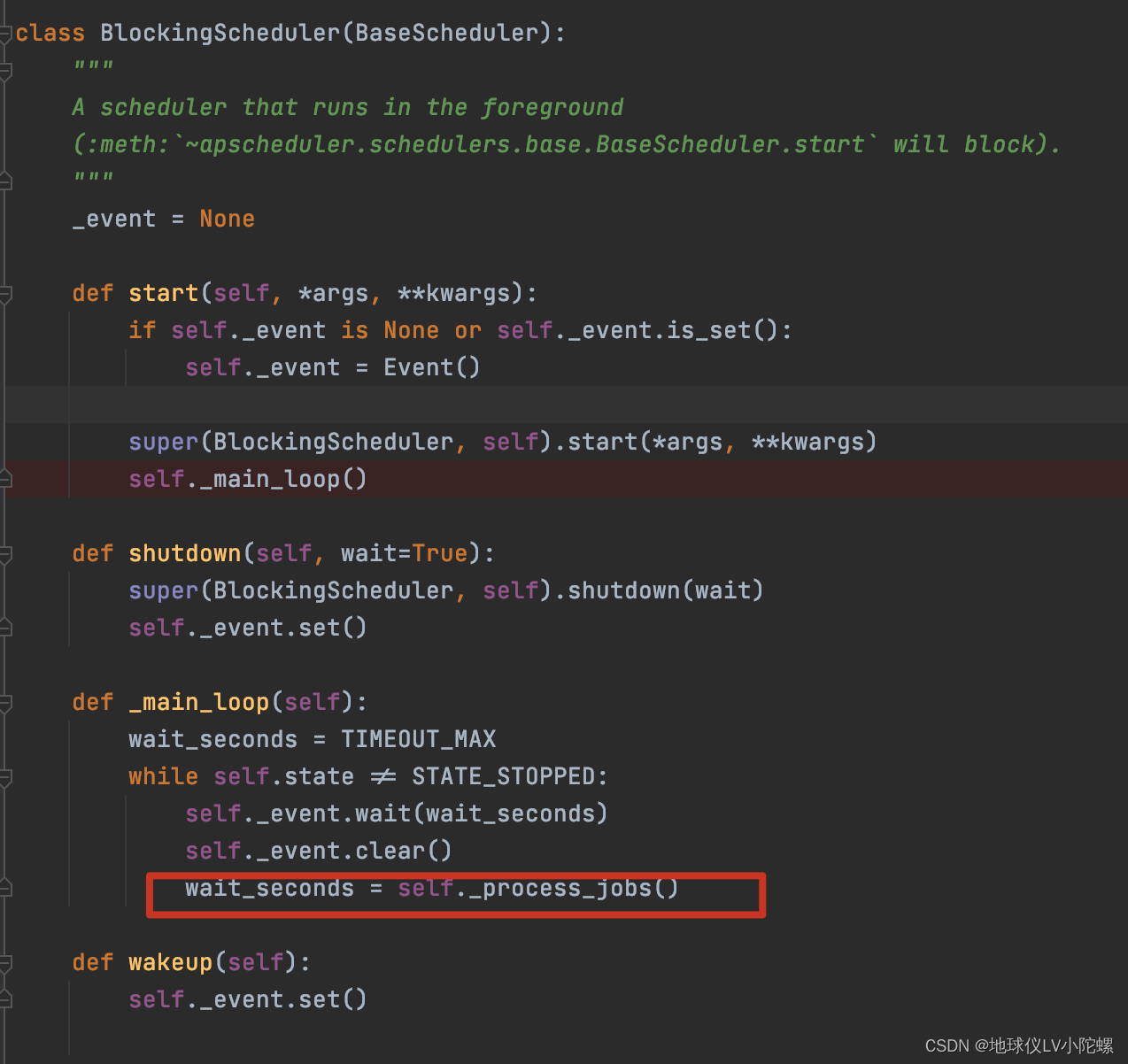
wakeup 方法仅仅是调用了 _event.set() 方法,该方法会设置一个事件。当调度器处于休眠状态时,等待 _event 事件被设置,一旦事件被设置,调度器就会立即执行 _process_jobs 方法,检查所有的任务是否到了执行时间。
总结整个流程
- 调用start方法启动定时任务
- 调用add_job方法添加定时任务,定时任务被存入任务管理器,此时会调用wakeup方法触发_process_jobs方法执行
- _process_jobs方法做的事情比较多
a. 会将任务和任务要触发的时间交给执行器,任务的实例值+1;
b. 如果是线程池执行器,submit_job方法内部会将任务提交到线程池中执行,执行成功后,会将该任务的实例值-1.
c. 最后将任务封装成事件,将事件添加到事件列表中
d. 如果任务配置了事件管理器,则执行注册的事件
e. 获取阻塞_process_jobs方法的时间 - 下次调用_process_jobs方法继续监控任务列表
架构图
引用这位博主的一张架构图, 感谢~
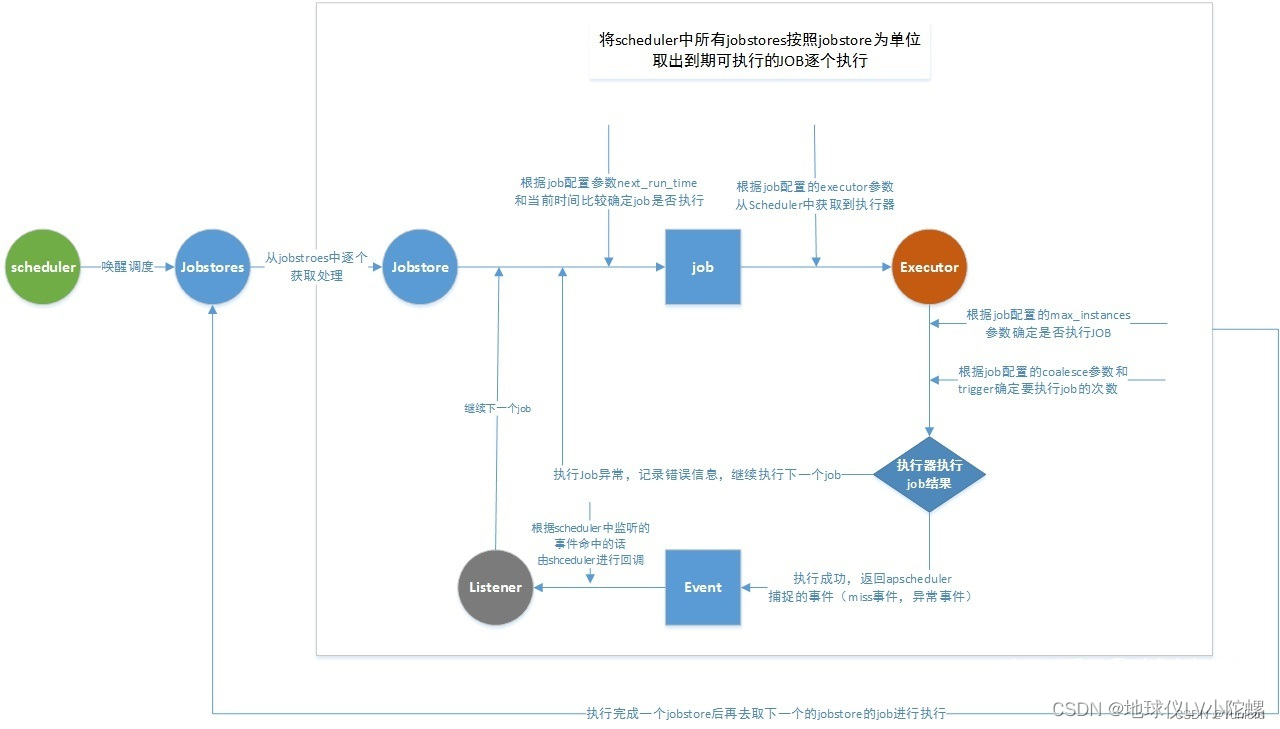
任务被Miss的原因
通过整个流程的梳理,项目中任务被Miss掉的真正原因如下:
- 任务量太大,大概500个定时任务
- 任务触发间隔时间太短, 5秒钟触发一次
- 线程池配置比较小。感觉这里也不应该配置太多,太多的话,资源消耗肯定会增加
- 任务里有对第三方服务发起http请求,比较耗时。这里也许可以用
解决方案
批处理:下游服务提供批量查询的功能,我的服务就不用一个个查询了,一下子解决了。