在实时视频互动中,影响观众对视频体验的有较多且复杂的因素,包括:画质、流畅度以及与其耦合的观看设备等。传统客观算法会利用网络传输或编解码参数拟合接收端人的感知体验,或者使用图像质量结合其他相关参数拟合实时视频质量。由于缺少除画质外的量化指标且没有直接衡量视频感知体验,所以当前QoE算法有一定局限性。目前端到端的QoE模型可以有效解决上述面临的难题,但同时也面临着主观实验复杂、数据依赖与模型运算量大等问题。LiveVideoStackCon 2022北京站邀请到郑林儒老师为我们介绍视频体验数据库的建立、视频画质评估建模及其端上轻量优化。
文/郑林儒
编辑/LiveVideoStack
大家好,我是来自声网的视频算法工程师郑林儒,今天给大家分享的是实时互动下视频QoE端到端轻量化网络建模。

今天将从影响视频主观体验的因素、针对这些影响因素现阶段建立的一些数据库、对于视频画质评估做了一个端到端建模、考虑模型端上运行的实时性介绍了当前主流的深度学习模型加速方法和对视频QoE的展望五个部分展开介绍。
-01-
QoE介绍
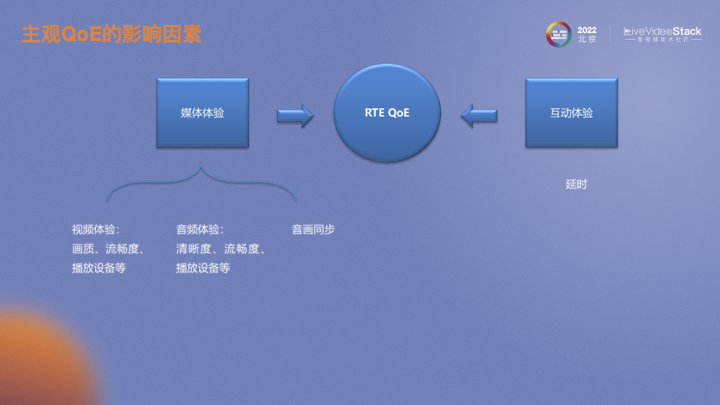
视频或者实时互动场景下QoE体验的影响因素主要有媒体体验和互动体验。媒体体验分为视频体验和音频体验。视频体验包括画质、流畅度、播放设备等。音频体验则包括清晰度、流畅度、播放设备。除此之外还有连接视频和音频的音画同步。互动体验目前主要定义为延迟。
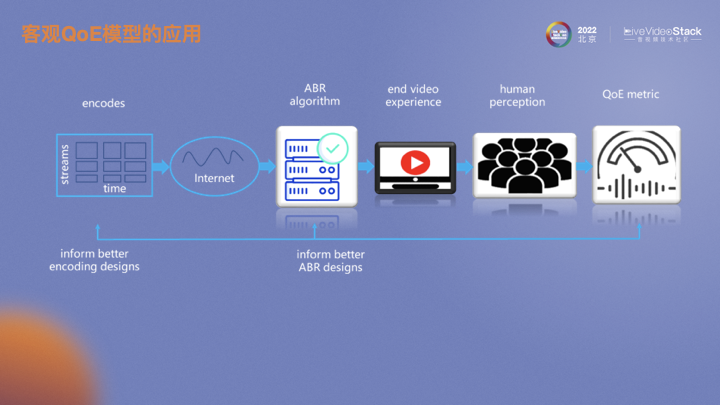
为什么要建立一套端到端的QoE评估体系呢?上图是视频从编码传输到被用户感知的流程。编码器将视频编成码流,经过复杂的网络环境会有各种码率自适应算法去感知当前网络变化或根据客户端播放情况自动做出合理的码率调整,以最大化用户在线观看视频的体验。一个端到端的QoE指标可以提供相对于PSNR、SSIM更贴合主观的画质指标。从而基于这个指标可以指导编码器选择最优编码参数,进而在不影响用户感知画质情况下实现码率节省。类似的,它也可作为ABR算法的参考指标。
-02-
QoE建库
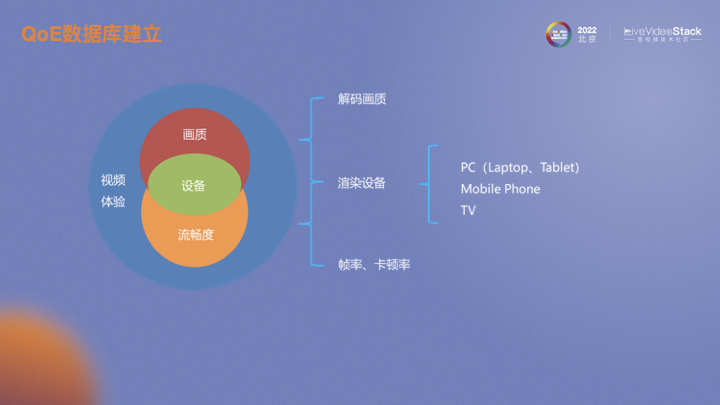
当前我们所建立的数据库主要针对视频体验。首先考虑的是解码端视频画质,这里画质包括了清晰度、亮度、对比度、色彩等等方面。在画质基础上增加了画面流畅度的评估维度,刻画流畅度的客观指标主要是帧率和卡顿率,但也和画面、应用场景有关。可以看到无论是解码端画质还是流畅度都会收到观看设备的影响,比如屏幕ppi会影响画质体验、刷新率会影响流畅度体验。这里我们将设备大致归为3类,分别为电脑、手机以及电视。

首先建立了一个画质主观评估数据库,通过内部视频软件收集了一些数据。随后对收集数据进行处理,通过我们开发的打分软件,按照ITU标准进行主观评估,得到每个视频的MOS。
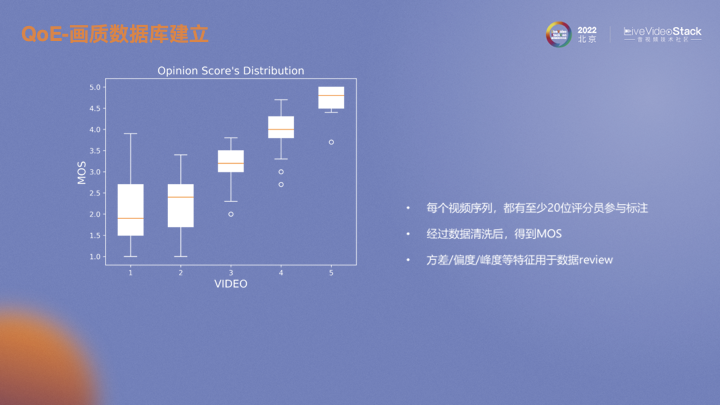
对于每个视频序列我们都至少有20位评估人员参与打分以保证数据清洗后的有效人数。根据ITU推荐的方法,计算每个人与整体打分的相关性,再排除相关性较低的参与者。实验中我们通过设置锚点发现了设备不同ppi对画质评估影响很大,在像素密度较高屏幕素质越好的设备上给出的分也相对较高。同时锚点的设置也可以作为数据筛选的依据。
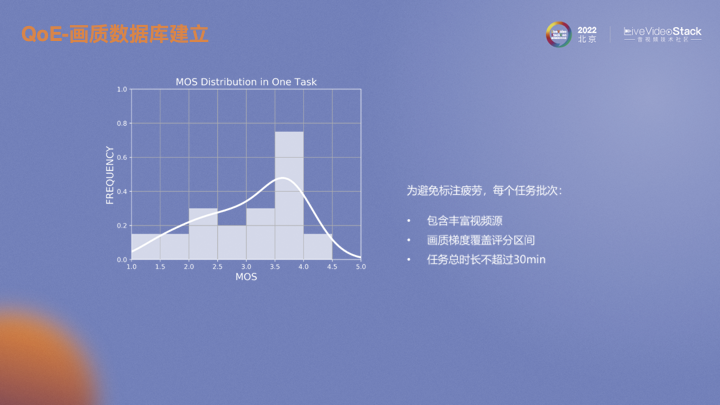
设置合理的视频序列也是需要考虑的。为了避免长时间单调标注过程中产生疲劳而导致数据失真,每个批次尽量差异化视频内容,并且在画质层面最大化覆盖评分区间,每个评估人员每次打分的时长不超过30分钟。
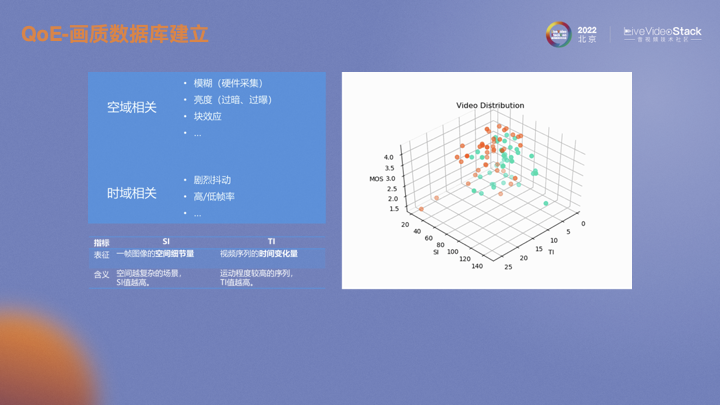
如何在视频失真类型以及视频特征上最大化多样性呢?首先考虑空域失真即画面失真,一般会因为视频采集时聚焦不准而导致模糊,会由于背光等光照不均匀时出现过暗或过曝。视频传输前会通过编码器编成码流,由于有量化操作所以在解码后会有块效应,还有其他很多类型的失真。时域相关的失真一般会有画面卡顿以及不同的视频帧率。从特征层面去表述或者区分的话,用经典的视频特征SI和TI表述。SI表示视频的空间细节程度,越复杂的场景SI越高;TI表示视频在时域上的画面变化程度,运动越剧烈的场景TI越高。
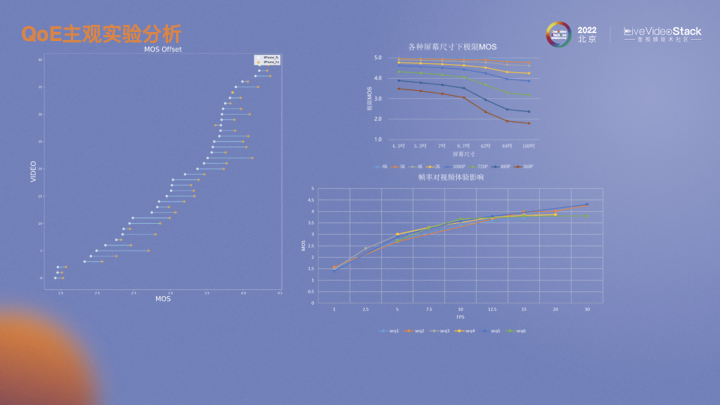
左图是几十个视频在iPhone上全屏和半屏观看时画质MOS分变化趋势图。可以看到,相对于hs,fs大部分情况下画质都有所降低。建模的目的就是为了找出相同画质范围内的偏移。右上角的图来自华为的白皮书,表示不同分辨率视频在不同尺寸设备上的极限MOS。越小分辨率的视频在更大尺寸的设备上播放衰减越严重。右下角是我们做的一个实验。对六个原视频进行不同帧率的MOS评估,发现不同视频,随着帧率的上升,MOS会有所提升。但不同视频内容导致的变化趋势也略有不同,与视频画面会有很大关系,当运动剧烈时则需要更高的帧率支持,反之则不需要浪费更多的帧率资源。
-03-
QoE建模
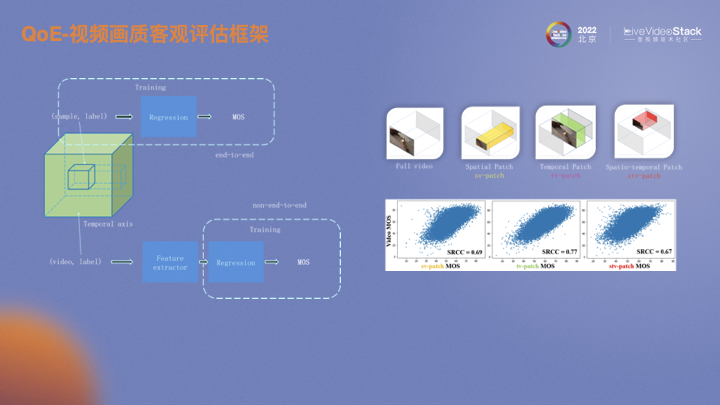
首先考虑的是视频解码端画质的建模。业内目前主要有两种方式。一种是端到端的训练方式,另一种是非端到端的训练方式。端到端是对一组视频直接采样,然后回归MOS。采集的数据在分辨率和帧率大概率是不一样的,需要通过采样统一size。非端到端利用特征提取器,将原始视频通过特征提取器提取到同一个维度,然后再回归。右边的图是不同的采样方式。第一个是空域采样,保证了所有时域上的帧数。还有时域采样和时空域采样。下面的图表示不同采样方式MOS和原始视频MOS的相关性。在空域进行时域采样时相关性最高,时域信息没有空域信息重要。线上推理完整的size则需要消耗更多资源。评估视频的画质不仅仅是空域上的失真,如果仅有空域的失真,直接用IQA拟合VQA即可,但目前该类方案的拟合效果都不佳。所以时域的影响不能消除。
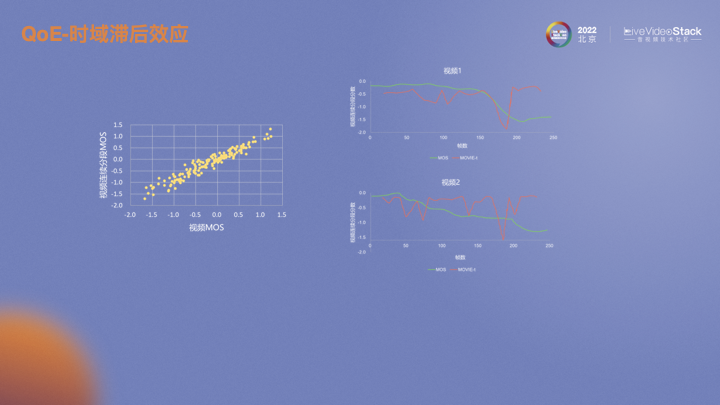
假设现在有一个十秒的视频,每一秒都有一个MOS。每一秒MOS的均值和整个视频的MOS有强相关性,基本可以认为互等。在这样的前提下,滞后效应可以描述为当视频的画质下降时,MOS也会立即下降。但当画质恢复时,由于人的主观对之前的损失有记忆,提升是一个缓慢的过程。视频2反映的趋势也是如此。画质不断波动,画质差的印象会一直在人的印象中,主观MOS很难提升。
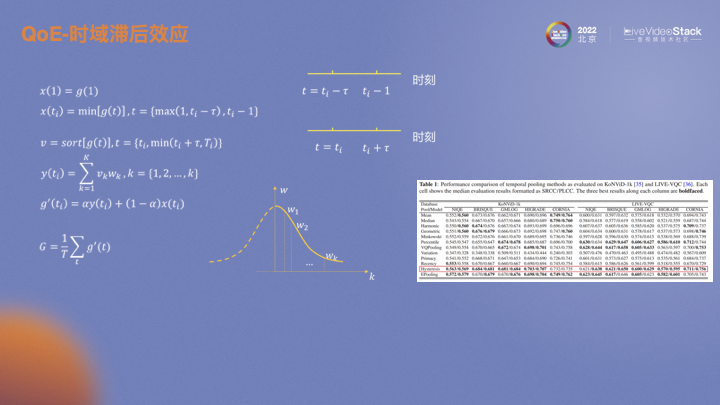
通过建模可以非常直观的反映该效应。充分考虑前ti时刻和后ti时刻的影响。前ti时刻类比快速下降,对前ti时刻每一时刻的预测值取最小值,可以体现MOS快速下降的行为;而对后ti时刻的每一时刻预测值进行升序排序,对预测值较高的赋更低的权重,这一操作体现了缓慢提升的思想。将两段时刻加权求和,作为最终的MOS。右下图红框就是效果展示。两个数据集上以及不同的客观指标上都有比较明显的提升。但简单的求平均,类似单帧IQA平均VQA,效果较差。
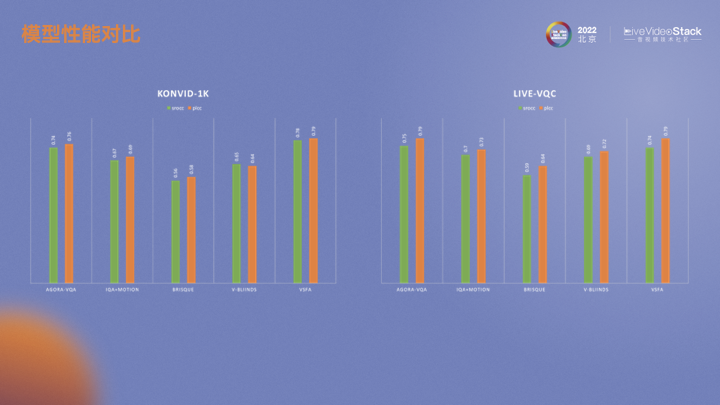
我们也同时在两个数据集上做了实验。AGORA-VQA是目前采用的方法。IQA+MOTION是基于深度学习的IQA算法。BRISQUE是传统IQA算法。V-BINDS是传统视频的算法。VSFA是视频的深度学习算法。
-04-
模型加速

基于深度学习算法落地时避免不了的一个问题就是运算量与性能的平衡。怎么在减小模型参数和运算量的同时保持甚至提高性能,业内一些小模型的设计给我们提供了一些思路。第一张图是一个标准卷积过程,输入3通道图片经过一个4通道卷积层。MobileNet中对标准卷积进行了拆解,拆解成一个个深度卷积和逐点卷积。深度卷积的参数量和运算量有相同的关系,均为输出通道1/N,而逐点卷积为卷积核大小平方分之一,通常在较深的网络中N远大于K,所以也可以看出这种结构下运算量主要来自于逐点卷积。
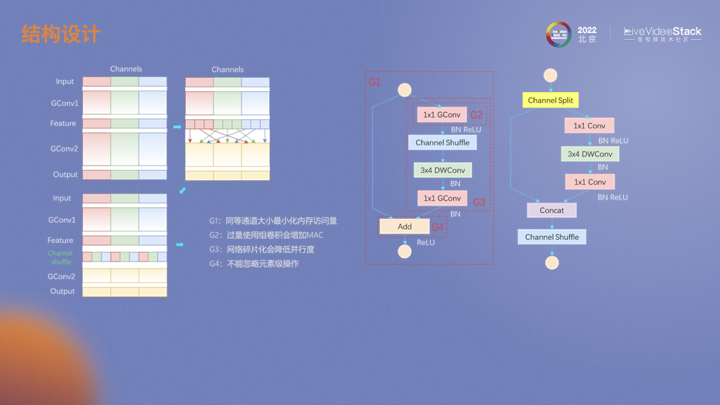
为了减少运算量同时增加通道间的信息流通,ShuffleNet中对分组卷积中不同通道进行重排,这样下面的分组卷积中不同组的输入就实现了特征融合。在模型落地的过程中也发现了一些问题。在V1模型中,如果采用ResNet瓶颈结构,输入和输出通道会不一样,会增加内存的存取,即MAC。另外,分组卷积也会增加MAC。不同分支上的碎片化操作会降低并行度,例如channel shuffle。ReLU、add、shuffle这类元素级操作的运算量虽然比较低但是也会带来MAC。针对这些问题,V2进行了一定的优化。
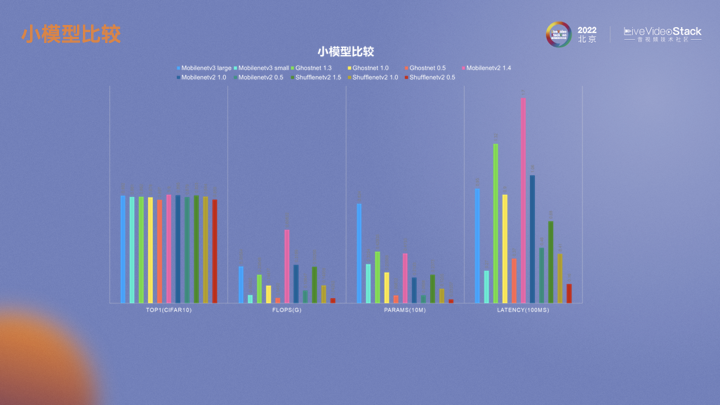
这张图展示了不同小模型的性能。ShuffleNet的运算量、参数量还是线上推理延迟都比较小。在落地算法模型时,更为关注的是延迟,特别是RTE的场景下。
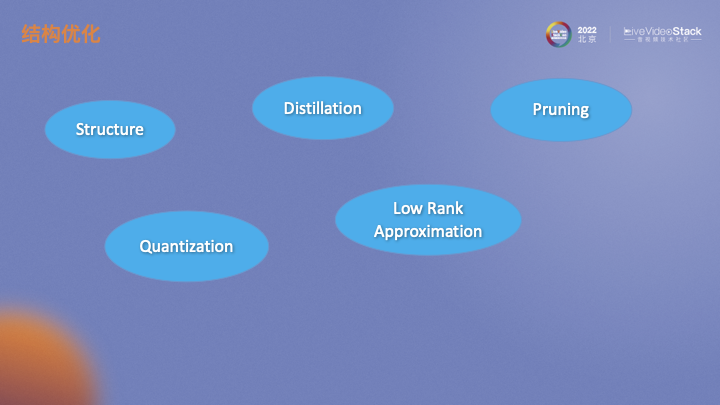
对于模型加速,选取一个合理的,对硬件友好的结构是基础。基于模型结构基础上,还可以通过一些方法对模型做进一步的压缩。模型蒸馏类似于一个迁移学习,将一个大模型的输出作为监督信息指导小模型的训练。模型剪枝主要是通过评估不同结构、不同通道的重要性对其进行剪枝。模型量化通常训练的权重是float32,我们通过对其量化成float16甚至int8,也可以加速运算。低秩分解认为深度学习模型权重矩阵非常大,可以将其近似分解成多个低秩矩阵来降低模型运算量。
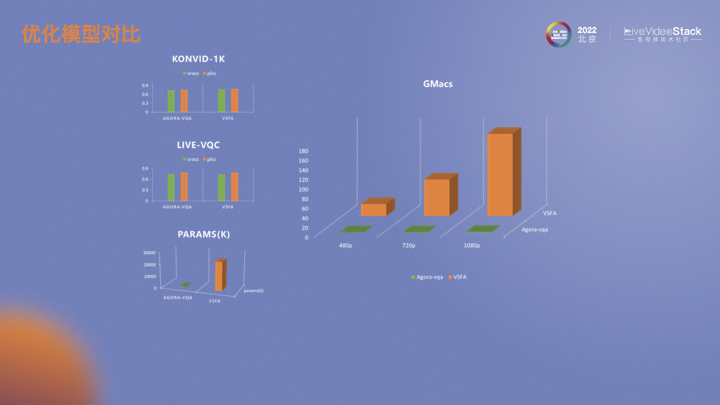
剪枝分为结构剪枝和非结构剪枝。非结构剪枝对硬件不友好,在实际应用中少见。结构化剪枝有一点需要注意,如果是在硬件上实时去跑,通道不是8、16、32的倍数的话,后续也需要通道对齐的处理,此时效果不一定会好。经过模型选择、优化、加速处理后,我们的模型与当前大模型相比,在性能相同的情况下参数量和运算量远低于大模型。
-05-
QoE展望

目前这些QoE指标仍在内部打磨中,后续会开放给开发者和用户。后续阶段还要对端到端RTE-QoE指标进行完善,包括适配场景的增加、整合流畅度、延迟和音频MOS。在对这些指标建模后还需要一个完备可靠的算法验收确保其在线上线下表现一致。最后,基于画面的QoE算法随着视频分辨率的上升其运算量也会相应提高。画面剪切也会损失模型性能,怎么平衡模型准确率与不同分辨率下运算量也是需要考虑的。
谢谢大家!

▲扫描图中二维码或点击“阅读原文” ▲
查看更多LiveVideoStackCon 2023上海站精彩话题
![chatgpt赋能python:Python[-5:-1]:一种高效且灵活的编程语言](https://img-blog.csdnimg.cn/img_convert/44de0d90e0ae0c8cf84d27ee6f9bfa15.png)