对比测试了一下IO翻转速度在各种函数调用的情况下的差异
CPU运行速度150Mhz,SDRAM开
- 直接调用翻转函数
while(1)
{
GPIO_InvBit(GPIOA, PIN0);
}
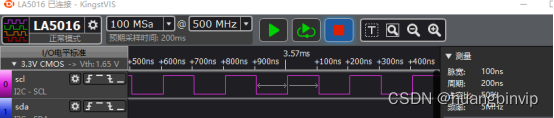
速度大约5Mhz,主要是因为函数调用开销和函数内部的移位和异或操作,增加了指令的运行数量。
void GPIO_InvBit(GPIO_TypeDef * GPIOx, uint32_t n)
{
GPIOx->ODR ^= (0x01 << n);
}
2 去掉调用开销,优化操作
while(1)
{
GPIOA->ODR |= (0x01 << PIN0); //set
GPIOA->ODR &= ~(0x01 << PIN0); //clear
}
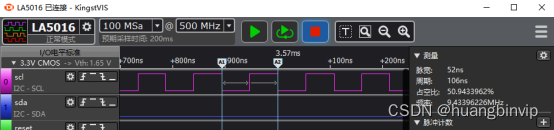
速度能提高到9M左右。
我们发现这个调用,因为有一个或和与的操作,来完成read-modify-write的动作。要完成这个操作,需要先读一下IO的状态,然后修改完成再写会,通用多做了不少工作。
那么有没有类似st等其他芯片一样直接写bit的操作呢?答案是有,查询了一下手册,居然有一个不太注意的地方是可以的,操作虽然和st等其他类似芯片的有差异,但是结果是一致的。
3. 直接bit操作
while(1)
{
GPIOA->DATAPIN0 = 1; //set
GPIOA->DATAPIN0 = 0; //clear
}
//这个来自于对下面这个函数的优化
void GPIO_AtomicSetBit(GPIO_TypeDef * GPIOx, uint32_t n)
{
*(&GPIOx->DATAPIN0 + n) = 1;
}
void GPIO_AtomicClrBit(GPIO_TypeDef * GPIOx, uint32_t n)
{
*(&GPIOx->DATAPIN0 + n) = 0;
}
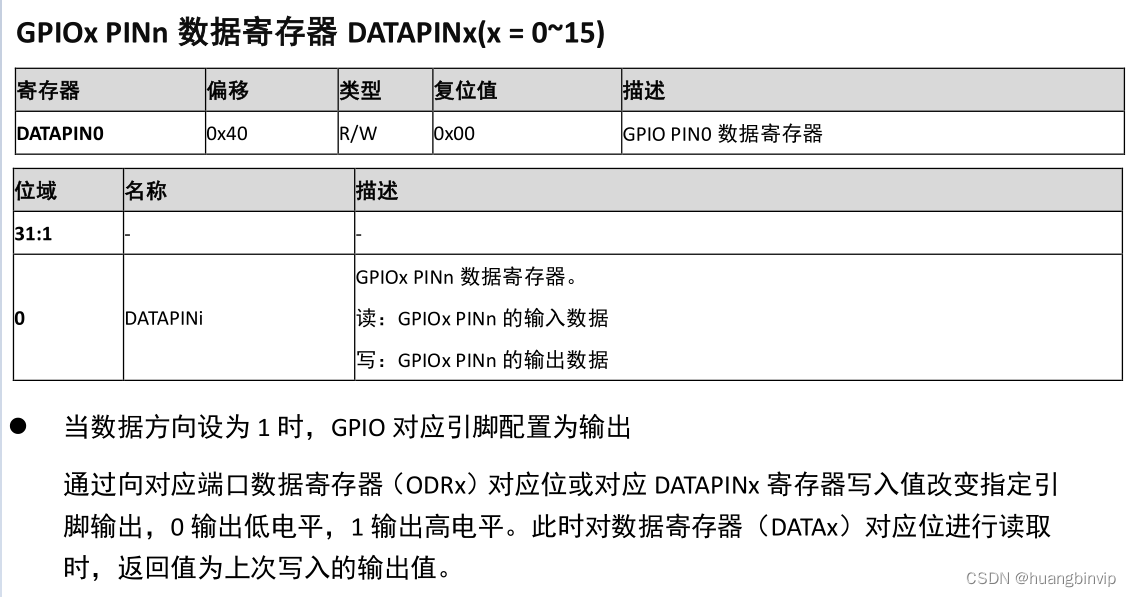
查阅datasheet发现有相关的描述,可以做位操作,虽然和用习惯了的st系列比起来有点不一样,但是结果一样。
测试优化后的数据,io最高速度已经能到接近30Mhz(我这个是连续输出8bit,有判断语句,非纯粹翻转速度,也是大多应用的情况),估计这也是极限了。

文章为原创,欢迎转载,请注明出处