Linux内存简介
概述
为何MemTotal小于RAM容量
[root@iZbp1dphe2bpv39op1g123Z ~]# dmesg | grep Memory
[ 1.391064] Memory: 131604168K/134217136K available (14346K kernel code, 9546K rwdata, 9084K rodata, 2660K init, 7556K bss, 2612708K reserved, 0K cma-reserved)
BIOS和Kernel启动过程消耗了部分内存,导致MemTotal(来自free)比RAM小。
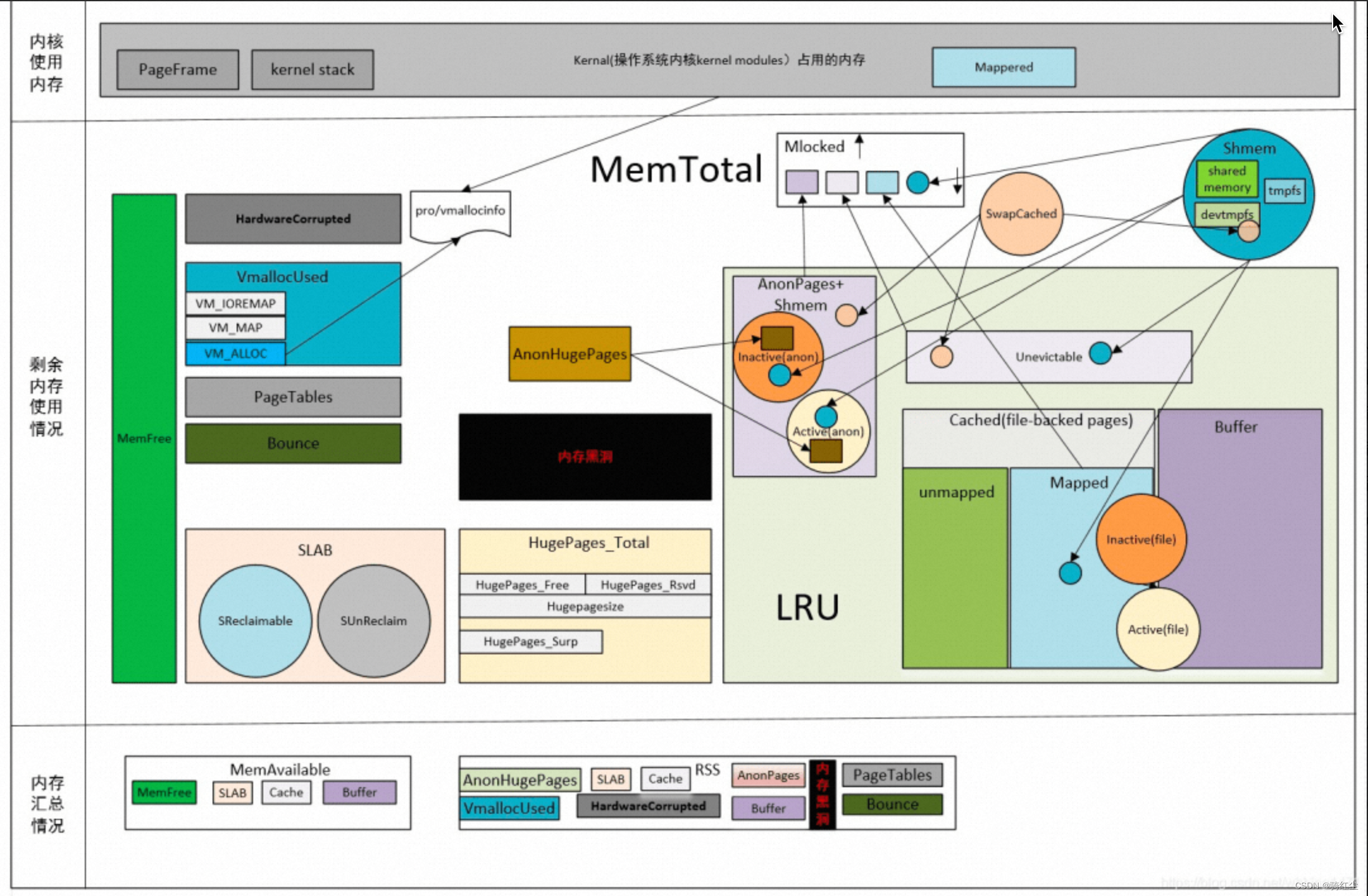
Linux的内存都用到哪里去了?(MemToal细分)
通过free,我们知道如下衡量内存的方式
total = used + free + buff/cache
free的数据源来自/proc/meminfo
cat /proc/meminfo
MemTotal: 131641168 kB
MemFree: 122430044 kB
MemAvailable: 124968912 kB
Buffers: 63308 kB
Cached: 3415776 kB
SwapCached: 0 kB
Active: 613436 kB
Inactive: 7674576 kB
Active(anon): 3504 kB
Inactive(anon): 4784612 kB
Active(file): 609932 kB
Inactive(file): 2889964 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 1472 kB
Writeback: 0 kB
AnonPages: 4641928 kB
Mapped: 1346848 kB
Shmem: 6972 kB
KReclaimable: 174888 kB
Slab: 352948 kB
SReclaimable: 174888 kB
SUnreclaim: 178060 kB
KernelStack: 48416 kB
PageTables: 30296 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 65820584 kB
Committed_AS: 22967072 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 77312 kB
VmallocChunk: 0 kB
Percpu: 42752 kB
HardwareCorrupted: 0 kB
AnonHugePages: 2852864 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
FileHugePages: 0 kB
FilePmdMapped: 0 kB
DupText: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 288568 kB
DirectMap2M: 12294144 kB
DirectMap1G: 123731968 kB
如下示意图:
 total = used + free + buff/cache
total = used + free + buff/cache
= kernel used + user used + free + buff/cache
其中:
kernel used =【Slab+ VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X】
user used =
∑
所有用户进程内存使用
\sum所有用户进程内存使用
∑所有用户进程内存使用
进程内存使用
从使用角度看,进程消耗内存总共是两块:
- 虚拟地址空间映射物理内存消耗;
- 读写磁盘生成的PageCache;
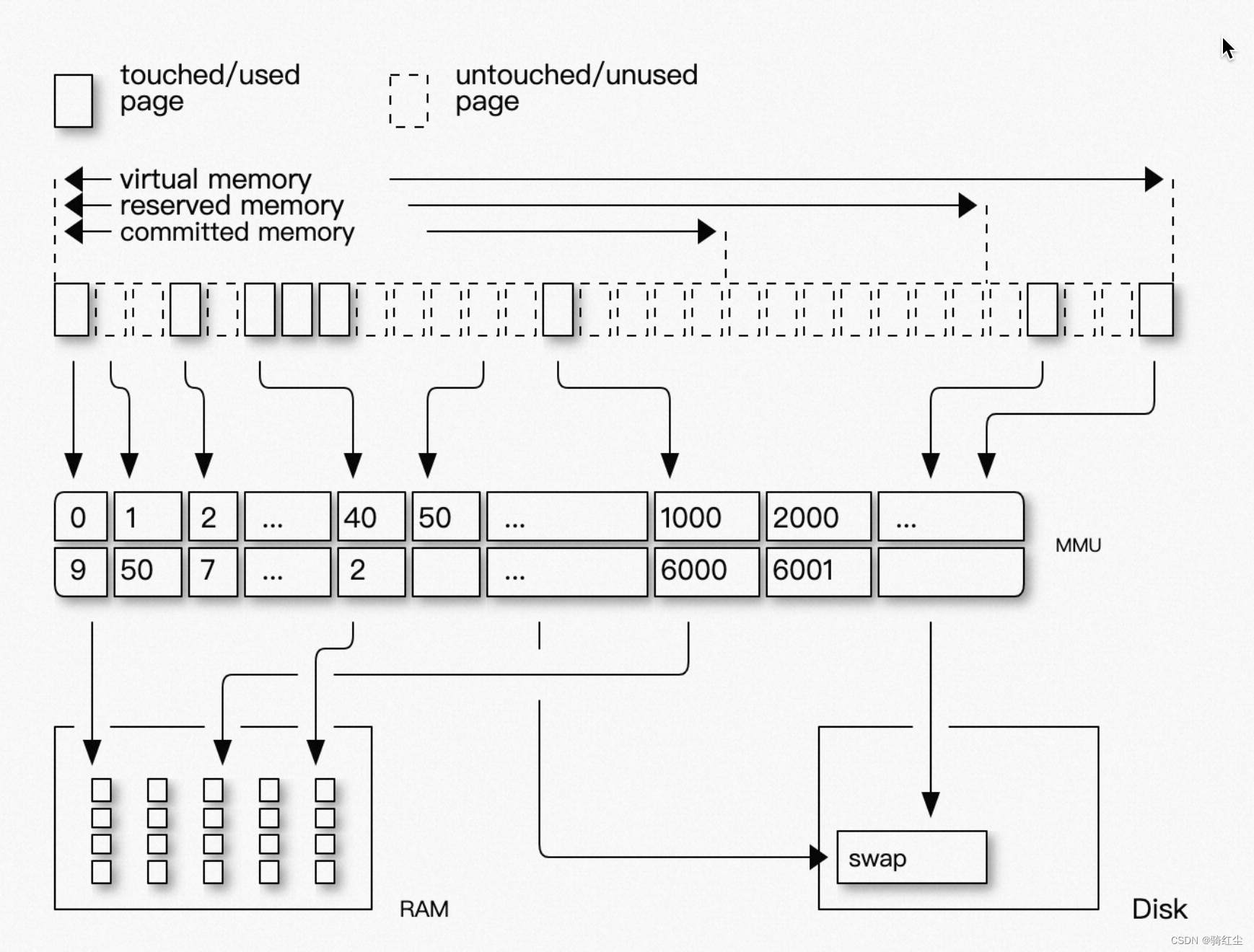
进程的虚拟地址空间和物理内存
虚拟地址空间模型和物理内存的映射
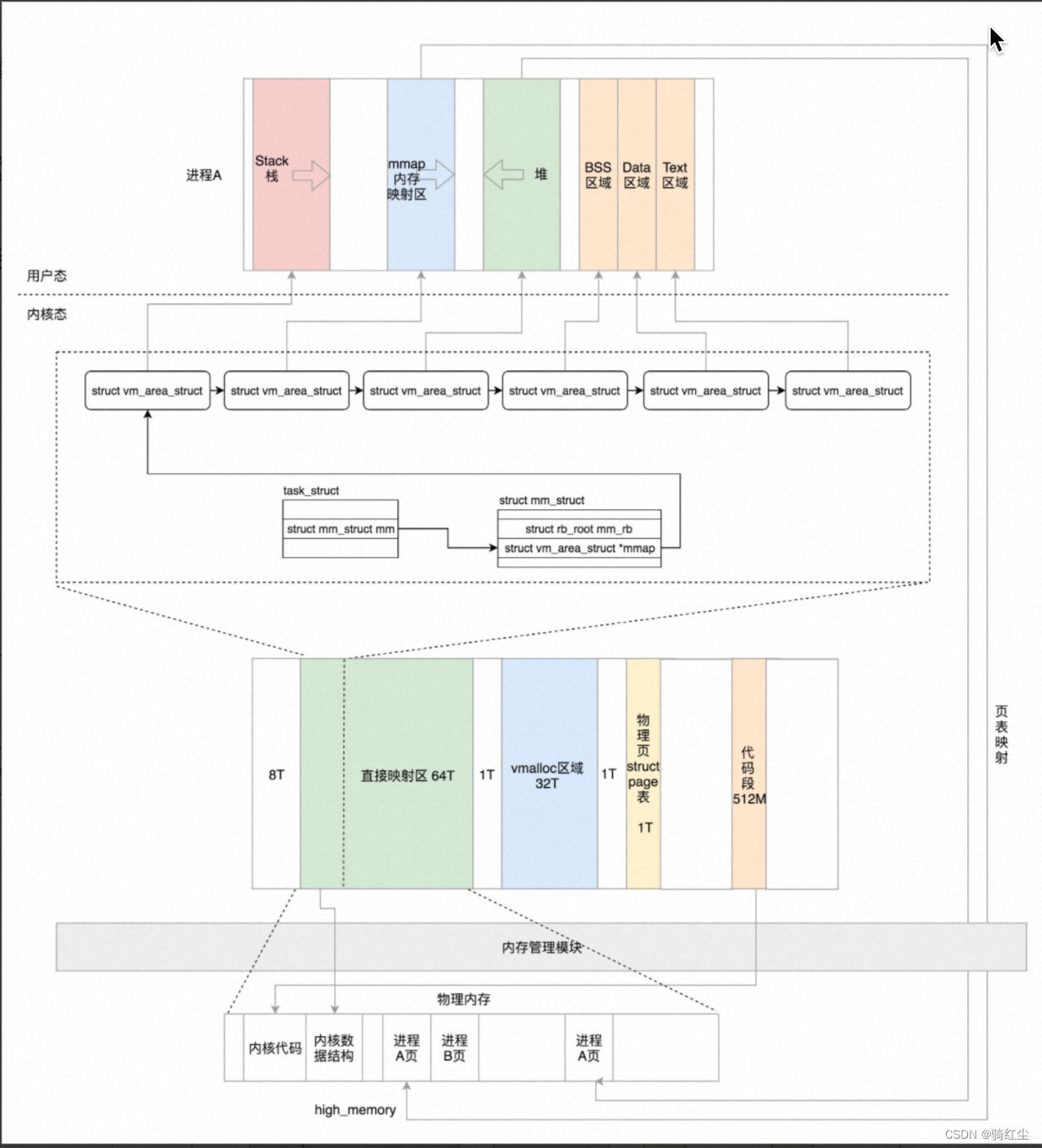
虚拟内存申请路径

进程内存的特性
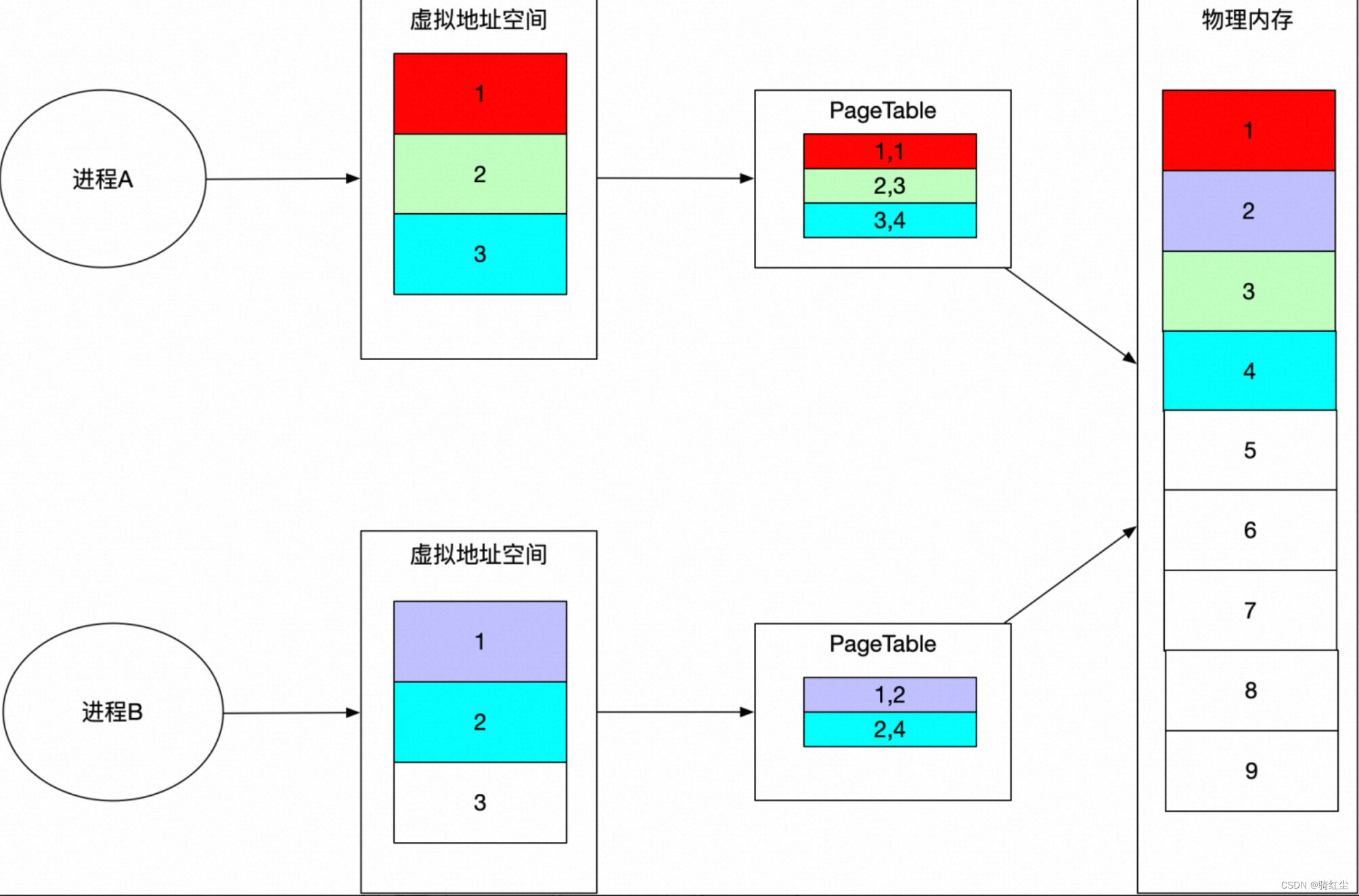
● 共享物理内存
● 独占物理内存
● 基于filesystem,而filesystem背后可能是磁盘,也可能是磁盘(这个上图没有表达出来)
○ 典型的如tmpfs
认识进程虚拟地址空间
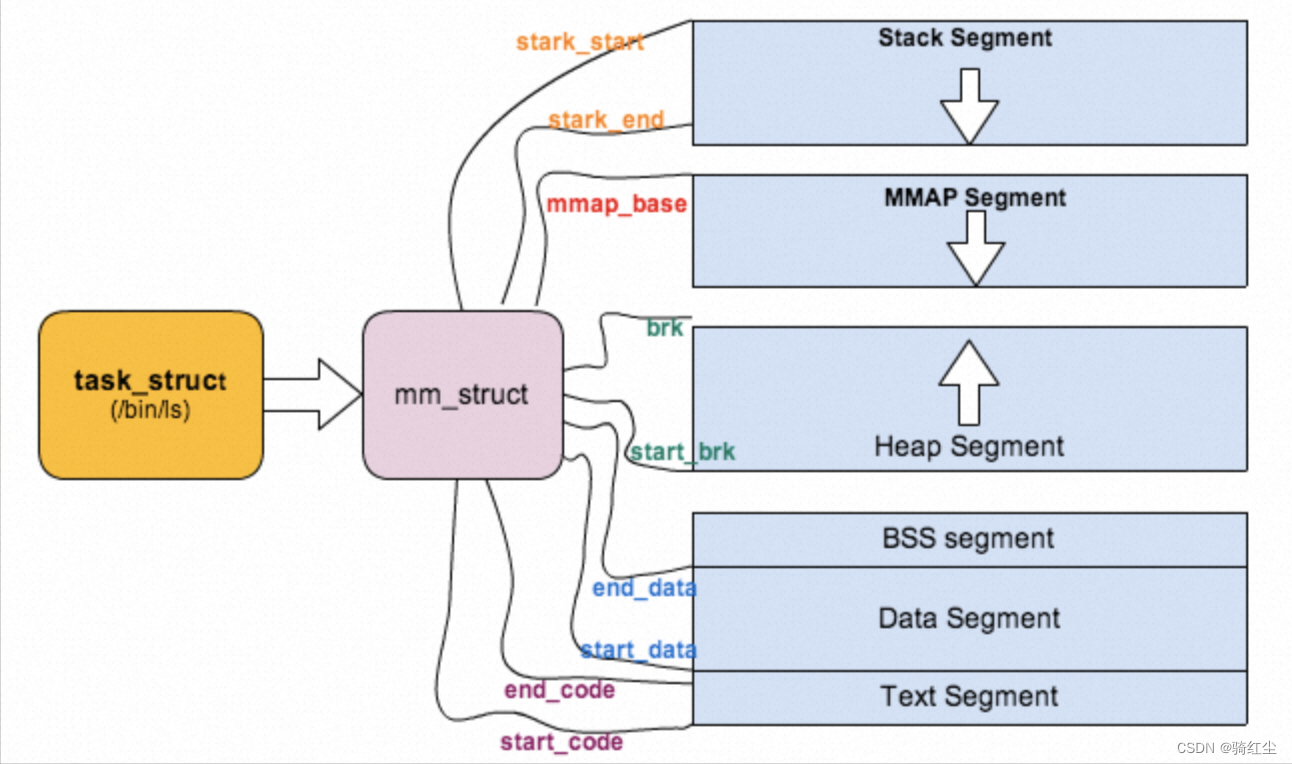
进程和PageCache
进程除了上述部分的内存意外,还有一部分文件数据并不是通过mmap file映射到内存的,文件是通过系统调用buffered io相关的syscall read,write读入进程的,进入pagecache空间,如下图:
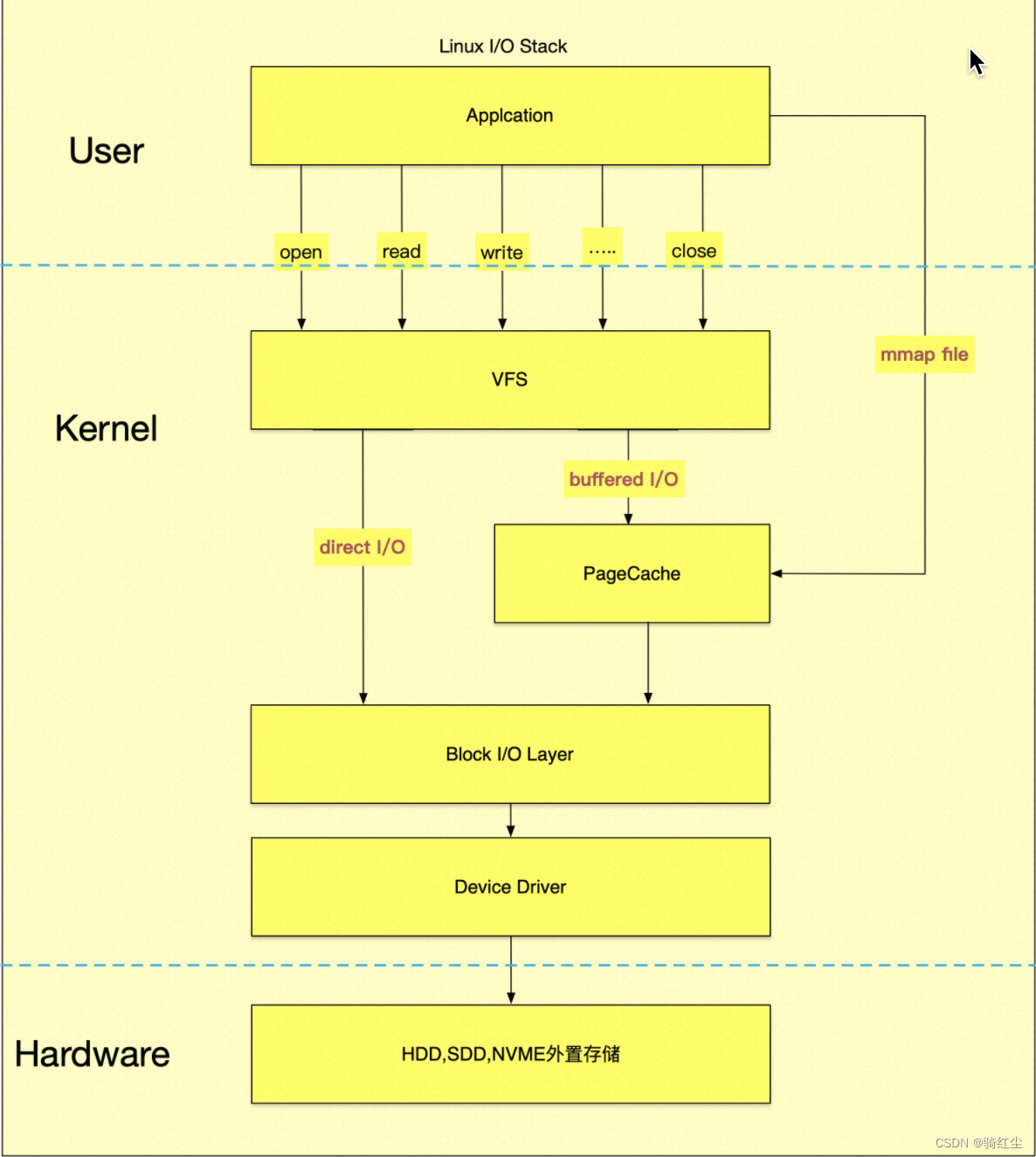
可以看到pagecache保留的page并不归属任何进程,因此这部分物理内存的消耗是全局性的。
pagecache逻辑上是进程通过syscall生成的,但是从各类进程内存统计工具,都是不计算pagecache。
进程内存统计
单进程内存统计
工具 字段 含义 数据来源 额外
top VIRT 虚拟地址空间大小 /proc/[pid]/statm 第一个字段;
same as VmSize in /proc/[pid]/status -
RES resident set size
映射的物理内存 /proc/[pid]/statm 第二个字段;
same as VmRSS in /proc/[pid]/status anno_rss + file_rss + shmem_rss
SHR shared pages /proc/[pid]/statm 第三个字段;
(from shared mappings) file_rss+
shmem_rss
MEM% 内存使用率 RES/MemTotal -
ps VSZ 虚拟地址空间大小 /proc/[pid]/statm 第一个字段;
same as VmSize in /proc/[pid]/status -
RSS resident set size
映射的物理内存 /proc/[pid]/statm 第二个字段;
same as VmRSS in /proc/[pid]/status anno_rss + file_rss + shmem_rss
MEM% 内存使用率 RSS/MemTotal -
smem USS Unique Set Size - anno_rss
PSS Proportional Set Size - anno_rss + file_rss/m + shmem_rss/n
RSS Resident Set size - anno_rss + file_rss + shmem_rss
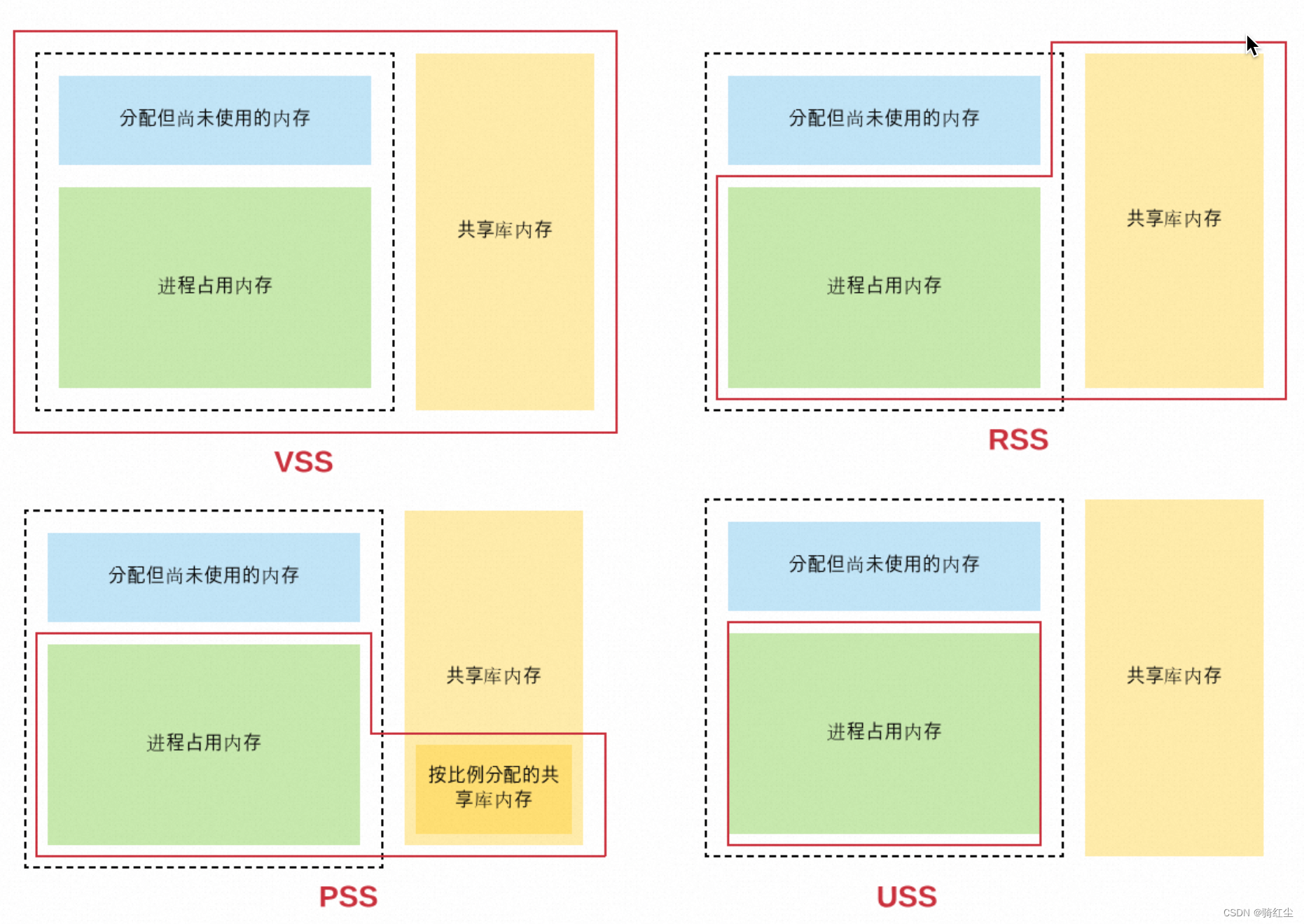
除了上述VSS,RSS,PSS,USS,还有一个概念是Memoy Working Set Size(WSS),这是Linux提出的一种更为合理评估进程内存真实使用内存的计算方式。
但是受限于Linux Page Reclaim机制机制,这个概念目前还是概念,并没有哪一个工具可以正确统计出WSS,只能是趋近,这个概念对于大部分开发人员是更为陌生。但是受到docker,k8s,Prometheus的热度影响,随之带来了评估Container,Pod的内存统计指标container_memory_working_set_bytes。这个真是一种特殊的计算方式,距离正确的Memoy Working Set Size还是有不小的差距,我们在下文完成memcg进程组的内存统计完成后在进行一些细节讨论。
进程组的内存统计
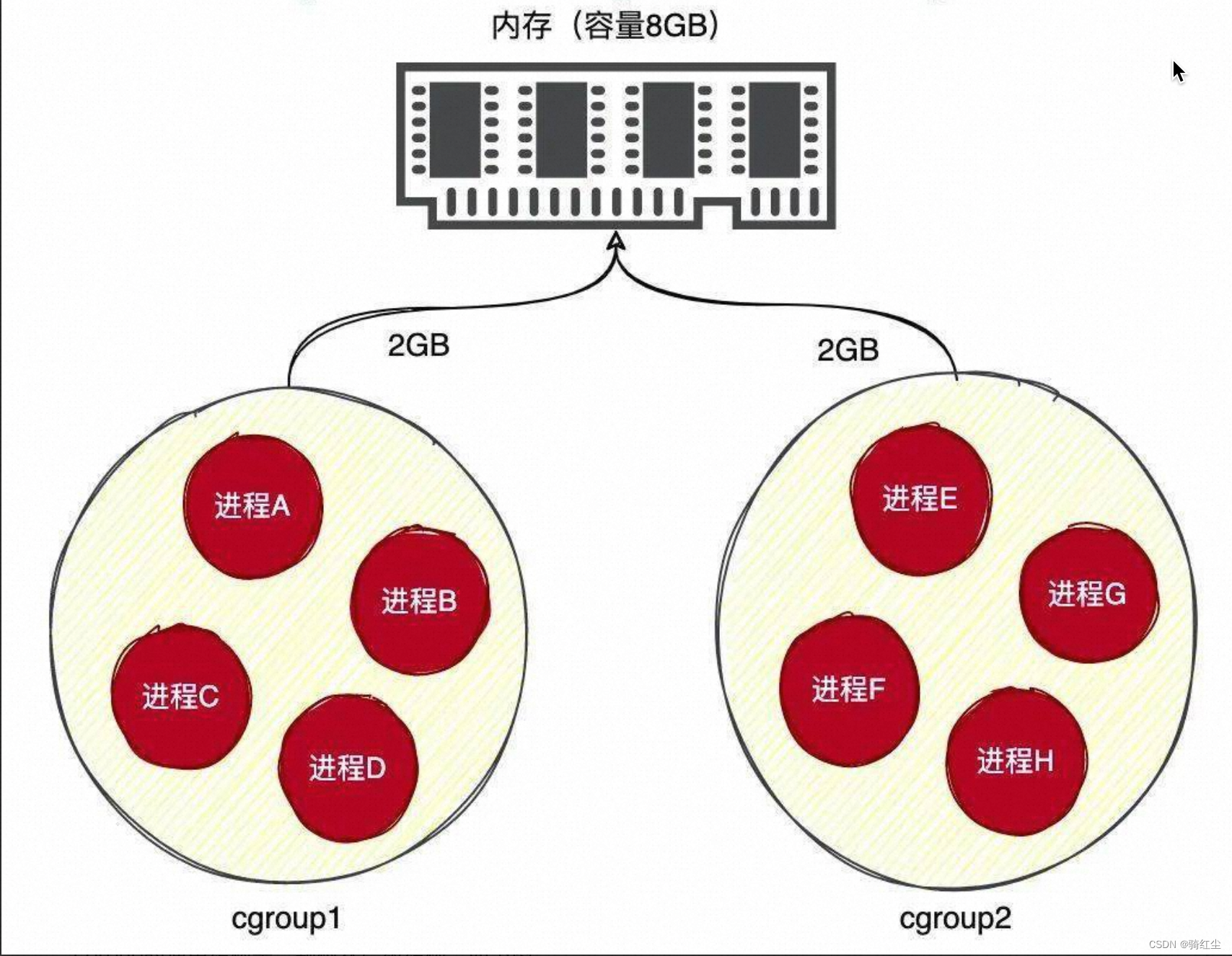
cgroup的理解
cgroup就是将linux上的大部分进程按照业务想要的规则进行分组控制,如下图示:
cgroup的通用结构是一颗树状层级结构,如下图: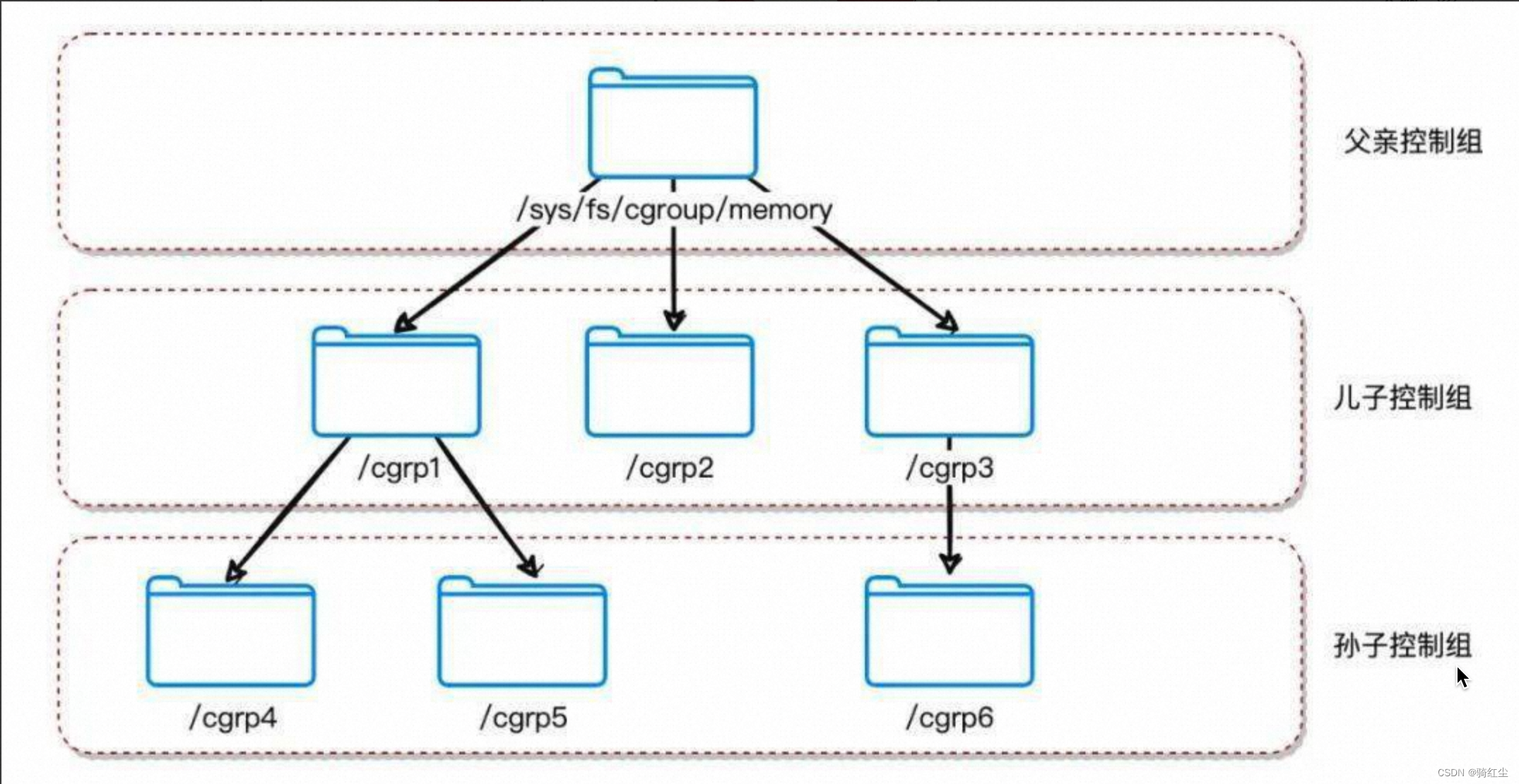
关于CGroup本身,是一个篇幅巨大的内容,本文尽不想用户陷入这些跟本文关系不大的内容,感兴趣的读者可以从这里找到更多信息。这里需要注意的是上图中每个节点都包含一组文件,用于统计由这个节点圈住的进程组的某些方面的统计值。典型的,memory Control Group统计内存统计值(这里描述并不是严格准确的,跟内存相关的子系统除了memcg,还有hugetlb。这两个区别是memcg统计普通页面和透明大页,hugetlb统计静态大夜。大部分场景用不上HugePage,可以忽略)。
memory cgroup的文件
首先是memcg的文件包含如下:
cgroup.event_control #用于eventfd的接口
memory.usage_in_bytes #显示当前已用的内存
memory.limit_in_bytes #设置/显示当前限制的内存额度
memory.failcnt #显示内存使用量达到限制值的次数
memory.max_usage_in_bytes #历史内存最大使用量
memory.soft_limit_in_bytes #设置/显示当前限制的内存软额度
memory.stat #显示当前cgroup的内存使用情况
memory.use_hierarchy #设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
memory.force_empty #触发系统立即尽可能的回收当前cgroup中可以回收的内存
memory.pressure_level #设置内存压力的通知事件,配合cgroup.event_control一起使用
memory.swappiness #设置和显示当前的swappiness
memory.move_charge_at_immigrate #设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
memory.oom_control #设置/显示oom controls相关的配置
memory.numa_stat #显示numa相关的内存
其中:
● memory.limit_in_bytes:memcg hard limit限制(对应在k8s,docker等场景memory limit的);
● memory.usage_in_bytes:memcg内存使用总量(约等于memory.stat[rss]+memory.stat[cache])
● memory.stat:是memcg的内存统计,如下表:
memcg的memory.stat字段 解释
cache pagecache
rss anno_rss(包含匿名透明大页)
mapped_file file_rss+shmem_rss
active_anon 在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
inactive_anon 不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
active_file 活跃 LRU 列表中的 file-backed 内存,以字节为单位
inactive_file 不活跃 LRU 列表中的 file-backed 内存,以字节为单位
unevictable 无法再生的内存,以字节为单位
上述每一个字段还有一个带total_前缀的字段,表达所有子孙节点的和,如下图示:
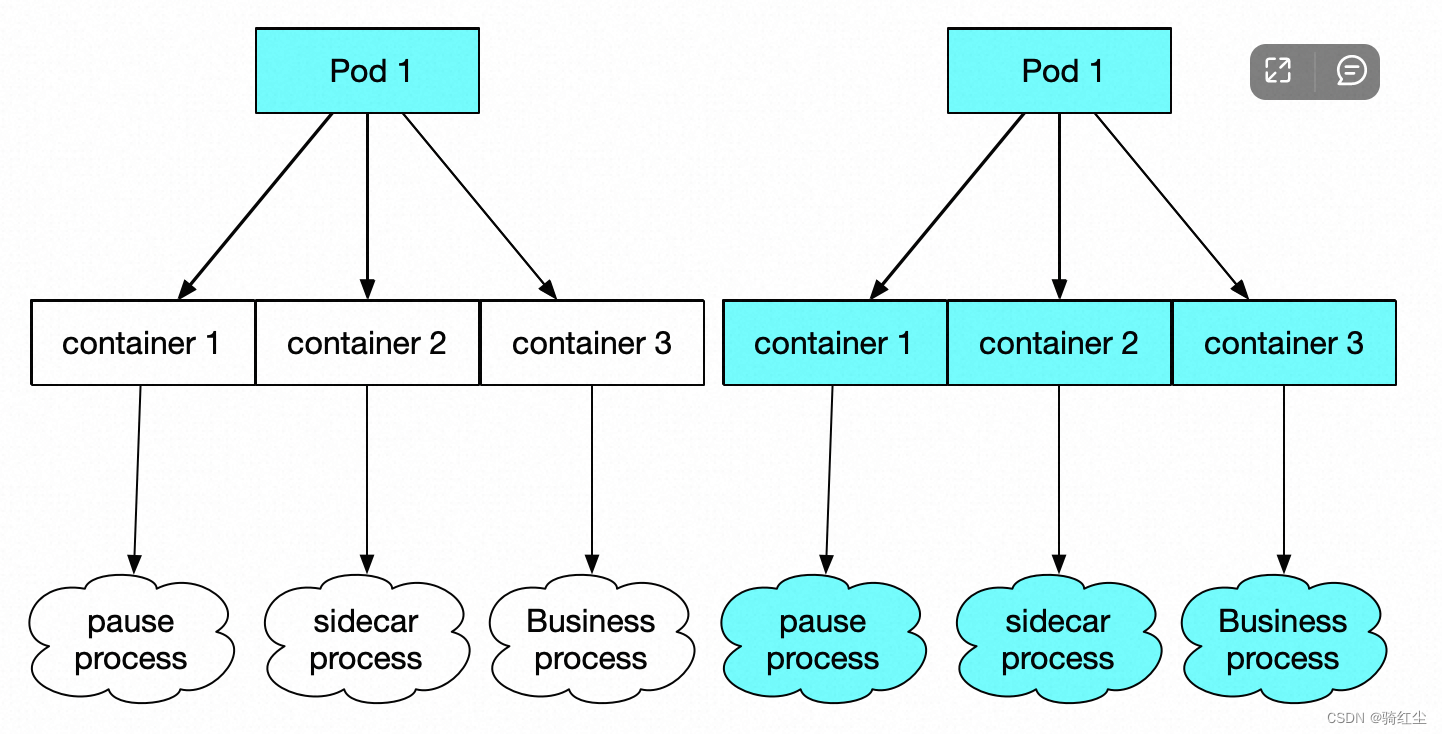
● 不带total_前缀的表达是上图中左边的内存统计;
● 带total_前缀的表达是上图中右边的内存统计
● 进程rss与memory cgroup rss的区别
区别 Process memcg
rss anon_rss+file_rss+shmem_rss anon_rss
mapped_file - file_rss+shmem_rss
cache - cache
特别强调:
● memcg的memory.stat文件中的rss只包含了anno_rss,因此映射的是上文进程的内存统计中提到的USS;而mapped_files包含file_rss+shmem_rss。因此在在memcg场景下:如果要和统计进程的常用工具,如top,ps做对比,关系是:memcg rss + mapped_file = top RES = ps rss;
● 前文我们提到page cache并不归属任何进程,但是memcg的统计,是包含page cache的统计的。(这个实现可以是memcg通过一些手段跟踪出来的,非本文重点,不展开了),这里需要澄清的核心是:
○ 对于进程的内存统计,不包含page cache;
○ 对于进程组的内存统计,包含page cache。
docker和k8s中的内存统计
当我们在docker或者k8s的场景,聊内存统计的话题,本质都是聊Linux memcg进程统计,即进程组的内存统计。核心的区别在于对于Memory Usage的定义不同带来的认知负担。
docker stat
docker stat显示如下:

docker stat的实现如下,源码:
func calculateMemUsageUnixNoCache(mem types.MemoryStats) float64 {
return float64(mem.Usage - mem.Stats[“cache”])
}
这里docker stat定义了两个概念:LIMIT和 MEM USAGE
● limit=memory.limit_in_bytes
● mem usage=memory.usage_in_bytes - memory.stat[total_cache]
kubectl top pod
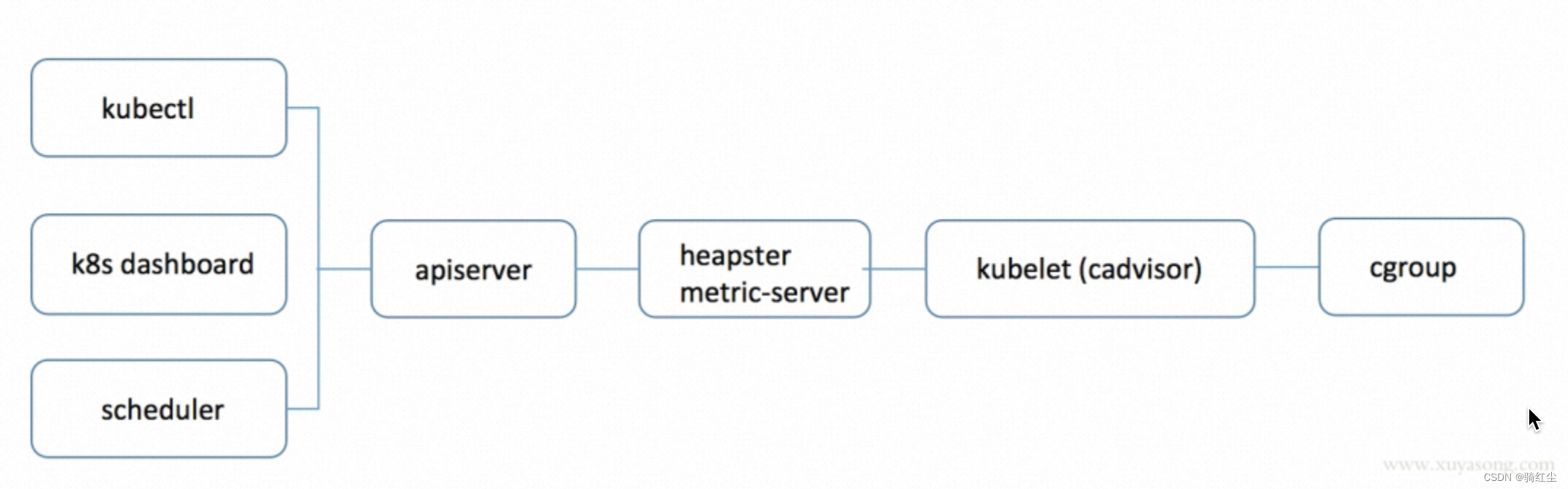
kubectl top命令通过metric-server/heapster获取cadvisor中working_set的值,来表示Pod实例使用内存大小(不包括pause容器),metrics-server中pod内存获取如下,源码:
func decodeMemory(target *resource.Quantity, memStats *stats.MemoryStats) error {
if memStats == nil || memStats.WorkingSetBytes == nil {
return fmt.Errorf(“missing memory usage metric”)
}
*target = *uint64Quantity(*memStats.WorkingSetBytes, 0)
target.Format = resource.BinarySI
return nil
}
cadvisor memory workingset算法,源码:
func setMemoryStats(s *cgroups.Stats, ret *info.ContainerStats) {
ret.Memory.Usage = s.MemoryStats.Usage.Usage
ret.Memory.MaxUsage = s.MemoryStats.Usage.MaxUsage
ret.Memory.Failcnt = s.MemoryStats.Usage.Failcnt
if s.MemoryStats.UseHierarchy {
ret.Memory.Cache = s.MemoryStats.Stats["total_cache"]
ret.Memory.RSS = s.MemoryStats.Stats["total_rss"]
ret.Memory.Swap = s.MemoryStats.Stats["total_swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["total_mapped_file"]
} else {
ret.Memory.Cache = s.MemoryStats.Stats["cache"]
ret.Memory.RSS = s.MemoryStats.Stats["rss"]
ret.Memory.Swap = s.MemoryStats.Stats["swap"]
ret.Memory.MappedFile = s.MemoryStats.Stats["mapped_file"]
}
if v, ok := s.MemoryStats.Stats["pgfault"]; ok {
ret.Memory.ContainerData.Pgfault = v
ret.Memory.HierarchicalData.Pgfault = v
}
if v, ok := s.MemoryStats.Stats["pgmajfault"]; ok {
ret.Memory.ContainerData.Pgmajfault = v
ret.Memory.HierarchicalData.Pgmajfault = v
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats["total_inactive_file"]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
}
Memory Usage = Memory WorkingSet = memory.usage_in_bytes - memory.stat[total_inactive_file]
总结
命令 体系 memory usage计算方式
docker stat docker memory.usage_in_bytes - memory.stat[total_cache]
kubectl top pod k8s memory.usage_in_bytes - memory.stat[total_inactive_file]
我们在叠加上linux原始工具做个整体对比:
生态 对象 memory usage计算方式 额外
top,ps等 单进程 rss
memcg 进程组 rss+cache(active cache + inactive cache)
docker 进程组 rss
k8s 进程组 rss+active cache MemoryWorkingSet
java的内存统计
如何理解java进程的虚拟地址空间
从Linux进程虚拟地址空间看:

叠加上JAVA的一些概念,就会像下面这个样子:
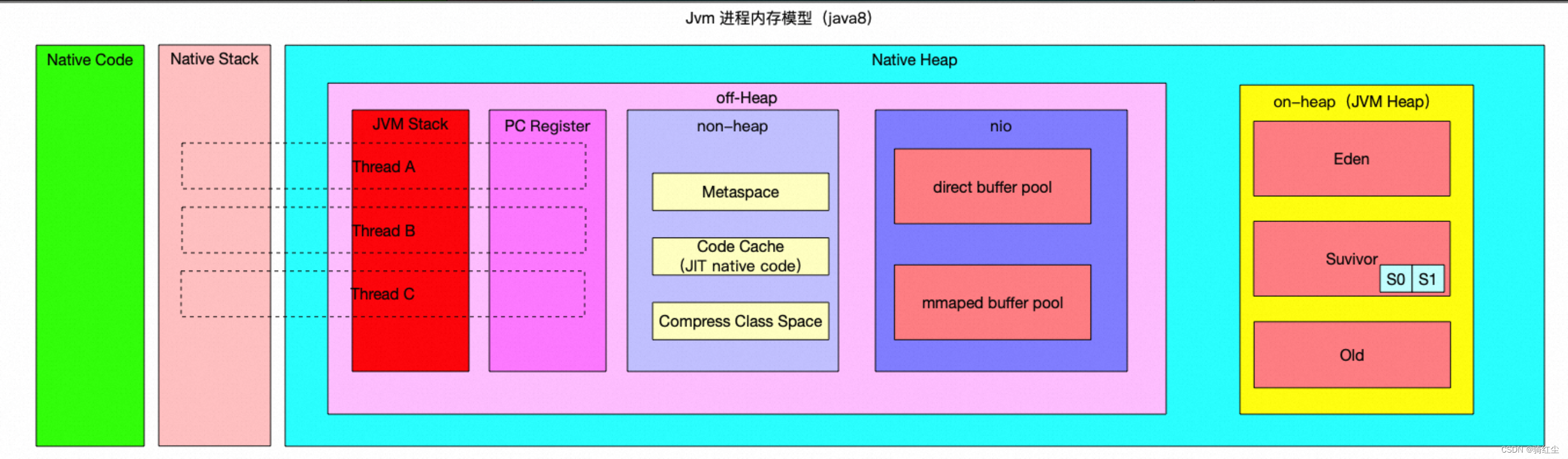
上图模型按照JMX暴漏的指标形成的概念图,并不能严格物理映射。
java程序的内存衡量
JMX
对于JAVA开发者,衡量JAVA程序内存情况,传统方式是通过JMX暴漏的数据获取,典型的,如jconsole,如下图:
内存相关的数据通过如下MBean透出:
注意上图,JMX暴漏一些非常容易混淆的东西。我们非常容易的认为这些指标足以把JVM进程的内存统计出来,但是遗憾的是,并不能:容易得出这些全部也不是JVM的内存总和,至少缺Java Thread消耗的内存;细想的话,JVM用来处理GC的数据结构的内存消耗都不在里面。
因此,拿JMX暴漏的内存usage数据累加得出的结果和JVM进程的RSS数据对比是没意义的,肯定不相等。
JMX MemoryUsage
JMX通过MemoryPool的MBean透出了一个MemoryUsage的概念,文档。
used是真正的物理内存消耗,其他都不是。
NMT
Java Hotspot VM提供了一个跟踪内存的工具Native Memory Tracking (NMT) ,文档。
NMT本身有额外的OverHead,并不适合在生产环境使用。
Enabling detailed native memory tracking (NMT) causes a 5% to 10% performance overhead. The summary mode merely has an impact in memory usage as shown below and is usually enough.
NMT summary的输出如下:
jcmd 7 VM.native_memory
Native Memory Tracking:
Total: reserved=5948141KB, committed=4674781KB
-
Java Heap (reserved=4194304KB, committed=4194304KB) (mmap: reserved=4194304KB, committed=4194304KB) -
Class (reserved=1139893KB, committed=104885KB) (classes #21183) ( instance classes #20113, array classes #1070) (malloc=5301KB #81169) (mmap: reserved=1134592KB, committed=99584KB) ( Metadata: ) ( reserved=86016KB, committed=84992KB) ( used=80663KB) ( free=4329KB) ( waste=0KB =0.00%) ( Class space:) ( reserved=1048576KB, committed=14592KB) ( used=12806KB) ( free=1786KB) ( waste=0KB =0.00%) -
Thread (reserved=228211KB, committed=36879KB) (thread #221) (stack: reserved=227148KB, committed=35816KB) (malloc=803KB #1327) (arena=260KB #443) -
Code (reserved=49597KB, committed=2577KB) (malloc=61KB #800) (mmap: reserved=49536KB, committed=2516KB) -
GC (reserved=206786KB, committed=206786KB) (malloc=18094KB #16888) (mmap: reserved=188692KB, committed=188692KB) -
Compiler (reserved=1KB, committed=1KB) (malloc=1KB #20) -
Internal (reserved=45418KB, committed=45418KB) (malloc=45386KB #30497) (mmap: reserved=32KB, committed=32KB) -
Other (reserved=30498KB, committed=30498KB) (malloc=30498KB #234) -
Symbol (reserved=19265KB, committed=19265KB) (malloc=16796KB #212667) (arena=2469KB #1) -
Native Memory Tracking (reserved=5602KB, committed=5602KB)
(malloc=55KB #747)
(tracking overhead=5546KB) -
Shared class space (reserved=10836KB, committed=10836KB) (mmap: reserved=10836KB, committed=10836KB) -
Arena Chunk (reserved=169KB, committed=169KB) (malloc=169KB) -
Tracing (reserved=16642KB, committed=16642KB) (malloc=16642KB #2270) -
Logging (reserved=7KB, committed=7KB) (malloc=7KB #267) -
Arguments (reserved=19KB, committed=19KB) (malloc=19KB #514) -
Module (reserved=463KB, committed=463KB) (malloc=463KB #3527) -
Synchronizer (reserved=423KB, committed=423KB) (malloc=423KB #3525) -
Safepoint (reserved=8KB, committed=8KB) (mmap: reserved=8KB, committed=8KB)
通过上述输出,我们可以知道,JVM内部划分了非常多细分的用途不同的内存区域,被java开发者熟知的是Java Heap和Class等,但是还有非常多额外的内存块。特别提一下Thread,因为JMX并没有暴漏线程
的内存使用信息,但是很多java程序有数以万计的线程,Thread消耗的内存非常大,但是却经常被忽略。
这里是hotspot内部关于内存种类划分的定义,供参考。
reserved和commited
NMT的输出统计透出了两个概念:reserved和commited。java开发者最关心的部分其实哪个值和物理内存映射。
非常遗憾,reserved和commited和物理内存使用(即used)都映射不上。
他们之间的关系如下图:
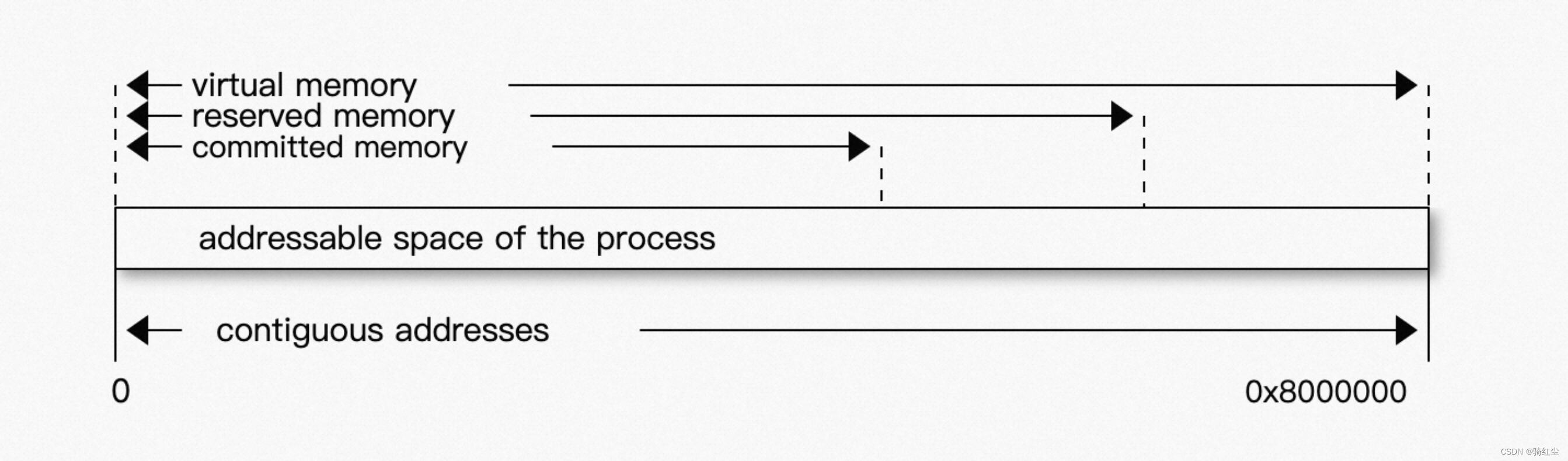
Virtual Address ranges that have been mapped or malloced. They may or may not be backed by physical or swap due to lazy allocation and paging. This applies to the JVM and the OS. These ranges are actually not necessarily contiguous.
Reserved The total address range that has been pre-mapped via mmap or malloc for a particular memory pool. In other words reserved memory represents the maximum addressable memory. Those could be referred to as uncommitted.
Committed OS memory pages which are currently in physical ram. This means code, stacks, part of the committed memory pools but also portions of mmaped files which have recently been accessed and allocations outside the control of the JVM.
Resident The sum of all virtual address mappings. Covers committed, reserved memory pools but also mapped files or shared memory. This number is rarely informative since the JVM will reserve large address ranges upfront. We can see this number as the pessimistic memory usage.
结合虚拟地址和物理地址映射:
然后我们在把java heap也加进去:
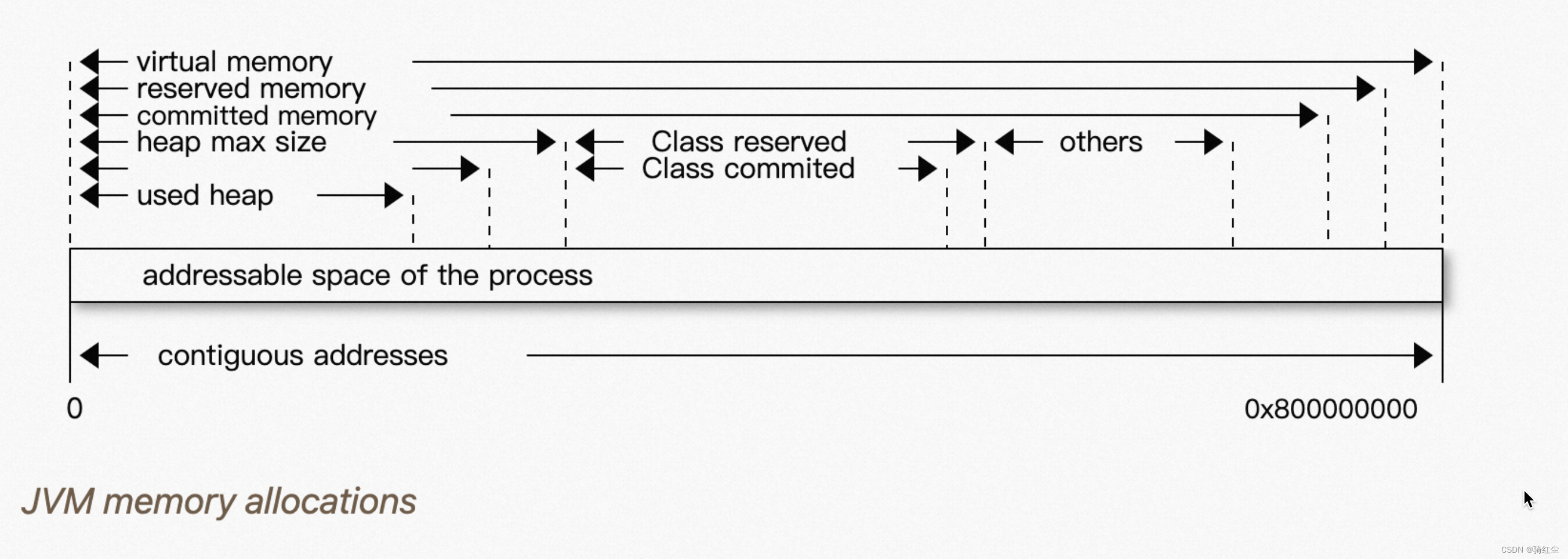
commited总是比used要大(这里的used,基本是等同于进程JVM的rss)
总结
- 对于Java应用开发者,我们看到的各种工具统计出来的指标,主要是JMX暴漏的,关于内存的统计,JMX暴漏了一些JVM内部可跟踪的MemoryPool,这些MemoryPool的总和并不能和JVM进程的RSS映射;
- NMT暴漏了JVM内部使用内存的细节,但是衡量结果并不是used,而是commited。总commited应该比rss稍大;
- NMT对于JVM外的一些内存没有办法跟踪,因此如果java程序有额外的molloc等行为,NMT是统计不到的,因此如果看到rss比NMT大,也是正常的;
- 如果NMT的commited和rss相差非常多,那就要怀疑内存泄漏的问题:
a. 借助NMT的baseline和diff来查是JVM内部哪个区域的问题;
b. 借助NMT结合pmap查JVM之外的内存问题。
QA
1.为啥arms应用监控产品界面上看到的heap,non-heap等等内存总和 和 通过TOP看到的RES相差很多?
arms界面上的数据来源一样来自JMX,NMT输出告诉我们:heap和non-heap并不是进程的全部内存消耗,差的内容至少包含Thread,GC,Symbol的等等部分,而且还缺不能被JVM跟踪的内存部分;
2.为啥arms应用监控产品界面上看到的heap,non-heap等等内存总和Prometheus,Grafana看到的内存利用率相差很多?
arms界面上的数据来源一样来自JMX;
Grafana上看到的内存利用率,通过Prometheus Query Language查询的指标一般是Pod,Container的名为container_memory_working_set_bytes指标,这个和上文提到的kubectl top pod是一个东西,即统计的是memcg(进程组)的rss+actived cache;
3.我的Pod发现一些OOM Killer导致的重启,如何通过arms应用监控产品排查?
只依靠arms应用监控产品无法完全定位;关于java进程,arms能拿到的数据只有JMX暴漏出来的这部分,而JVM进程的RSS消耗不一定是JMX暴漏的出来的。即便借助k8s的Prometheus监控生态,中间还是有很多信息需要知道: - Pod内是单进程模型么?排查其他进程内存消耗的干扰;
- JVM进程外的一些泄漏,比如glibc导致的内存泄漏;
- 如果是简单的Heap,Class,DirectorMemory的容量规划问题是比较容易发现解决的;
最后的大招就是pmap结合NMT分析虚拟地址空间,这招不到万不得已别用,太麻烦了。