0. 引言
做大模型性能优化的一定对KV Cache不陌生,那么我们对这个技术了解到什么程度呢?请尝试回答如下问题:
KV Cache节省了Self-Attention层中哪部分的计算?
KV Cache对MLP层的计算量有影响吗?
KV Cache对block间的数据传输量有影响吗?本文打算剖析该技术并给出上面问题的答案。
1. KV Cache是啥
大模型推理性能优化的一个常用技术是KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。网上有一些关于该技术的分析博客,但读过后仍然会很迷糊,甚至可能会被带偏,认为这个Cache过程和数据库读取或CPU Cache加速类似的荒谬结论。刚开始我也有类似误解,直到逐行查阅并运行源码,才清楚了解到其Cache了啥,以及如何节省计算的。
2. 背景
生成式generative模型的推理过程很有特点,我们给一个输入文本,模型会输出一个回答(长度为N),其实该过程中执行了N次推理过程。即GPT类模型一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
如上描述是我们通常认知的GPT推理过程。代码描述如下:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, _ = model(in_tokens)
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = torch.cat((in_tokens, out_token), 0)
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text = tokenizer.decode(in_tokens)
print(f' Input: {in_text}')
print(f'Output: {out_text}')输出:
step 0 input: Lionel Messi is a player
step 1 input: Lionel Messi is a player who
step 2 input: Lionel Messi is a player who has
step 3 input: Lionel Messi is a player who has been
step 4 input: Lionel Messi is a player who has been a
step 5 input: Lionel Messi is a player who has been a key
step 6 input: Lionel Messi is a player who has been a key part
step 7 input: Lionel Messi is a player who has been a key part of
step 8 input: Lionel Messi is a player who has been a key part of the
step 9 input: Lionel Messi is a player who has been a key part of the team
step 10 input: Lionel Messi is a player who has been a key part of the team's
step 11 input: Lionel Messi is a player who has been a key part of the team's success
step 12 input: Lionel Messi is a player who has been a key part of the team's success.
step 13 input: Lionel Messi is a player who has been a key part of the team's success.
Input: Lionel Messi is a
Output: Lionel Messi is a player who has been a key part of the team's success.可以看出如上计算的问题吗?每次推理过程的输入tokens都变长了,导致推理FLOPs随之增大。有方法实现推理过程的FLOPs基本恒定不变或变小吗?(埋个伏笔,注意是基本恒定)。
3. 原理
在上面的推理过程中,每step内,输入一个token序列,经过Embedding层将输入token序列变为一个三维张量[b, s, h],经过一通计算,最后经logits层将计算结果映射至词表空间,输出张量维度为[b, s, vocab_size]。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第i+1轮输入数据只比第 轮i输入数据新增了一个token,其他全部相同!因此第i+1轮推理时必然包含了第i轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果,就是这么简单,不存在什么Cache miss问题。
4. 实现细节
目前各大模型推理都实现了KV Cache,下面就看如何使用了。我们可以在上面代码基础上修改,主要改动:
在推理时新增了
past_key_values参数,该参数就会以追加方式保存每一轮的K V值。kvcache变量内容为((k,v), (k,v), ..., (k,v)),即有L个 k,v 组成的一个元组,其中 k 和 v 的维度均为[b, n_head, s, head_dims]。这里可以顺带计算出每轮推理对应的 cache 数据量为2bshL,这里s值等于当前轮次值。可以随着输出tokens的增长,cache数据量呈现线性增加特点。以GPT3-175B为例,假设以 float16 来保存 KV cache,senquence长度为100,batchsize=1,则KV cache占用显存为 2×100×12288×96×2 Byte = 472MB。推理输出的token直接作为下一轮的输入,不再拼接,因为上文信息已经在 kvcache 中。
代码示例:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
kvcache = None
out_text = in_text
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, kvcache = model(in_tokens, past_key_values=kvcache) # 增加了一个 past_key_values 的参数
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = out_token # 输出 token 直接作为下一轮的输入,不再拼接
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text += text
print(f' Input: {in_text}')
print(f'Output: {out_text}')通过上面代码只能看到调用层面的变化,实现细节还需看各框架的底层实现,例如Hugging Face的transformers库代码实现就比较清爽,在modeling_gpt2.py中Attention部分相关代码如下:
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None: # 当输出第一个token后,layer_past就是非None了
past_key, past_value = layer_past # 取出之前计算好的 key, value
key = torch.cat((past_key, key), dim=-2) # past_key 与当前 token 对应的 key 拼接
value = torch.cat((past_value, value), dim=-2) # past_value 与当前 token 对应的 value 拼接
if use_cache is True:
present = (key, value)
else:
present = None在 block 层面也有相关代码,大家有空细品吧。还是那句话,说一千道一万不如阅读并运行源码一次。
其实,KV Cache 配置开启后,推理过程可以分为2个阶段:
预填充阶段:发生在计算第一个输出token过程中,这时Cache是空的,计算时需要为每个 transformer layer 计算并保存key cache和value cache,在输出token时Cache完成填充;FLOPs同KV Cache关闭一致,存在大量gemm操作,推理速度慢。
使用KV Cache阶段:发生在计算第二个输出token至最后一个token过程中,这时Cache是有值的,每轮推理只需读取Cache,同时将当前轮计算出的新的Key、Value追加写入至Cache;FLOPs降低,gemm变为gemv操作,推理速度相对第一阶段变快,这时属于Memory-bound类型计算。
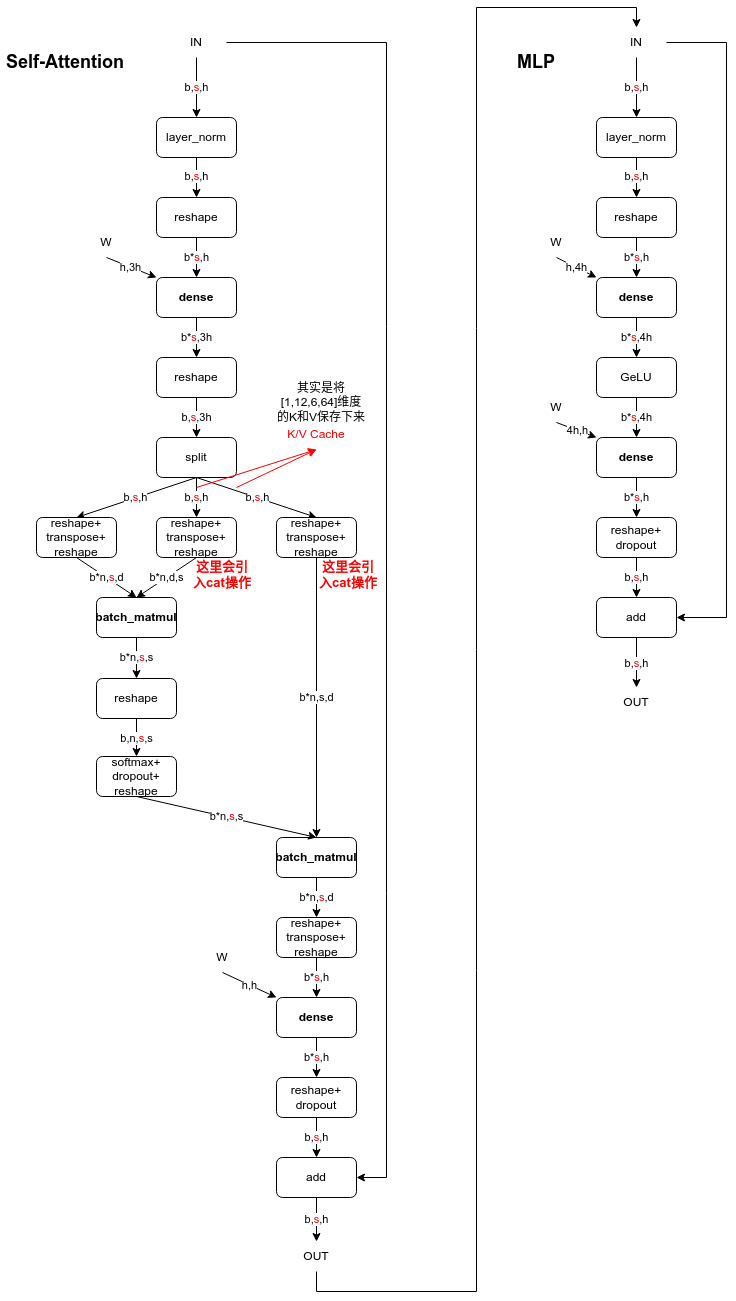
这里用图可能更有助理解,下图是一个Decoder Block,含有Self-Attention和MLP,标红部分为KV Cache影响到的内容,即KV Cache开启后,标红的序列长度s变为 1,当batch_size=1时,Self-Attention中的2个dense全都变为gemv操作,MLP中的dense也全都变为gemv操作。看懂这个图就可以答对上面的3个问题啦。
如下链接也有这方面的定量分析,写的很棒,推荐大家看看。
回旋托马斯x:分析transformer模型的参数量、计算量、中间激活、KV cache
5. 总结
KV Cache是Transformer推理性能优化的一项重要工程化技术,各大推理框架都已实现并将其进行了封装(例如 transformers库 generate 函数已经将其封装,用户不需要手动传入past_key_values)并默认开启(config.json文件中use_cache=True)。本文尝试打开封装分析该技术内部实现,希望对大家有所帮助,文中如有纰漏,欢迎指正。
最后给我们团队的开源项目打个广告,Adlik 是中兴通讯贡献的深度学习推理工具,已获得 Linux AI 基金会支持,目前仍在持续完善中,期待大家的支持和关注。另外,我们也在做深度学习编译器和大模型方向的前沿技术研发工作,欢迎感兴趣的小伙伴加入我们 ~~