目录
什么是消息队列
常用的消息队列工具对比
1 、ActiveMQ
2 、RabbitMQ
3、Kafka
4、 RocketMQ
什么是消息队列
消息队列是分布式应用间交换信息的重要组件,消息队列可驻留在内存或磁盘上, 队列可以存储消息直到它们被应用程序读走。通过消息队列,应用程序可以在不知道彼此位置的情况下独立处理消息,或者在处理消息前不需要等待接收此消息。所以消息队列可以解决应用解耦、异步消息、流量削锋等问题,是实现高性能、高可用、可伸缩和最终一致性架构中不可以或缺的一环。
消息队列是分布式系统中重要的中间件,在高性能、高可用、低耦合等系统架构中扮演着重要作用。分布式系统可以借助消息队列的能力,轻松实现以下功能:
- 解耦,将一个流程的上游和下游拆开,上游专注生产消息,下游专注处理消息。
- 广播,一个上游生产的消息轻松被多个下游服务处理。
- 缓冲,应对流量突然上涨,消息队列可以扮演一个缓冲器的作用,保护下游服务使其可以根据实际的消费能力处理消息。
- 异步,上游发送消息后可以马上返回,下游可以异步处理消息。
- 冗余,保留历史消息,处理失败或当出现异常时可以进行重试或者回溯防止丢失。
常用的消息队列工具对比
1 、ActiveMQ

- ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
- ActiveMQ特性如下:
- 多种语言和协议编写客户端。语言: Java,C,C++,C#,Ruby,Perl,Python,PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
- 完全支持JMS1.1和J2EE 1.4规范 (持久化,XA消息,事务)
- 对Spring的支持,ActiveMQ可以很容易内嵌到使用Spring的系统里面去,而且也支持Spring2.0的特性
- 通过了常见J2EE服务器(如 Geronimo,JBoss 4,GlassFish,WebLogic)的测试,其中通过JCA 1.5 resource adaptors的配置,可以让ActiveMQ可以自动的部署到任何兼容J2EE 1.4 商业服务器上
- 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
- 支持通过JDBC和journal提供高速的消息持久化
- 从设计上保证了高性能的集群,客户端-服务器,点对点
- 支持Ajax
- 支持与Axis的整合
- 可以很容易得调用内嵌JMS provider,进行测试
2 、RabbitMQ

RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是AMQP(高级消息队列协议)的标准实现。支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化。用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
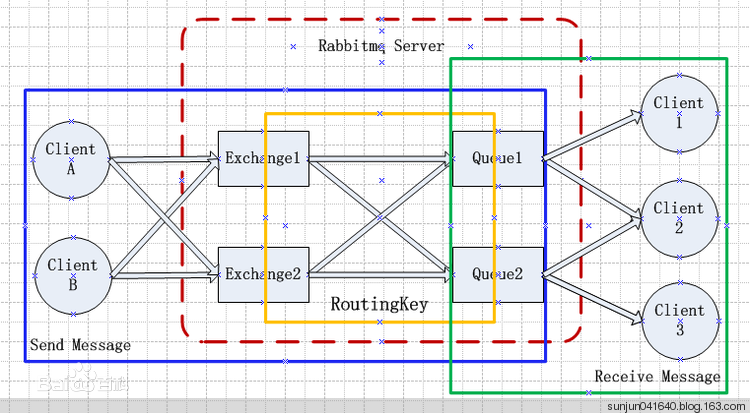
几个重要概念:
- Broker:简单来说就是消息队列服务器实体。
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
- producer:消息生产者,就是投递消息的程序。
- consumer:消息消费者,就是接受消息的程序。
- channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程,如下:
- 客户端连接到消息队列服务器,打开一个channel。
- 客户端声明一个exchange,并设置相关属性。
- 客户端声明一个queue,并设置相关属性。
- 客户端使用routing key,在exchange和queue之间建立好绑定关系。
- 客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
3、Kafka

Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。(文件追加的方式写入数据,过期的数据定期删除)
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
- 支持通过Kafka服务器和消费机集群来分区消息
- 支持Hadoop并行数据加载
Kafka相关概念
| 名称 | 作用 |
| Broker | Kafka集群包含一个或多个服务器,这种服务器被称为broker[5] |
| Topic | 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) |
| Partition | Parition是物理上的概念,每个Topic包含一个或多个Partition. |
| Producer | 负责发布消息到Kafka broker |
| Consumer | 消息消费者,向Kafka broker读取消息的客户端。 |
| Consumer Group | 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。 |
一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用。
4、 RocketMQ

RocketMQ是阿里开源的消息中间件,纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是简单的复制,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景,支撑了阿里多次双十一活动。
因为是阿里内部从实践到产品的产物,因此里面很多接口、api并不是很普遍适用。可靠性毋庸置疑,而且与Kafka一脉相承(甚至更优),性能强劲,支持海量堆积。
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| PRODUCER-COMSUMER | 支持 | 支持 | 支持 | 支持 |
| PUBLISH-SUBSCRIBE | 支持 | 支持 | 支持 | 支持 |
| REQUEST-REPLY | 支持 | 支持 | - | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持,JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级 | 万级 | 十万级 | 单机万级 |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 提供快速入门 | 有 | 有 | 有 | 无 |
| 首次部署难度 | - | 低 | 中 | 高 |