re库使用
re.findall
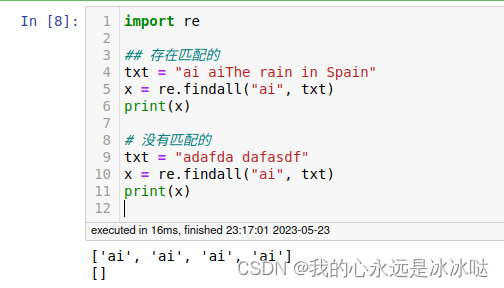
import re
## 存在匹配的
txt = "ai aiThe rain in Spain"
x = re.findall("ai", txt)
print(x)
# 没有匹配的
txt = "adafda dafasdf"
x = re.findall("ai", txt)
print(x)
s='中国人adfadsfasfasdfsdaf中国万岁\n'
print(re.findall(r"\w",s))

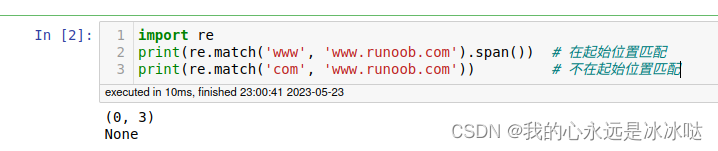
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
re.search
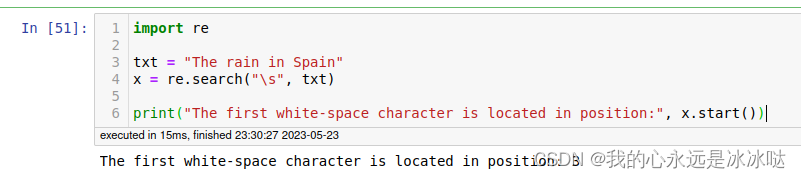
import re
txt = "The rain in Spain"
x = re.search("\s", txt)
print("The first white-space character is located in position:", x.start())
re.split(对元素进行划分)
import re
txt = "The rain in Spain"
x = re.split("\s", txt)
print(x)
import re
txt = "The rain in Spain"
x = re.split("\s", txt, 1)
print(x)

re.sub()
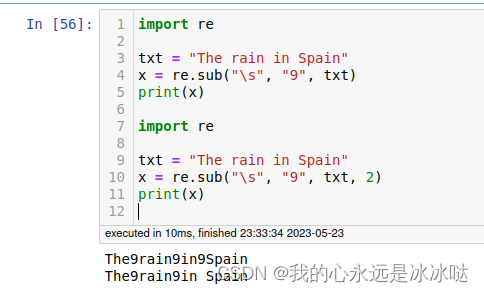
import re
txt = "The rain in Spain"
x = re.sub("\s", "9", txt)
print(x)
import re
txt = "The rain in Spain"
x = re.sub("\s", "9", txt, 2)
print(x)
pandas库正则表达式
pandas.str.match(元素匹配)
exampe1
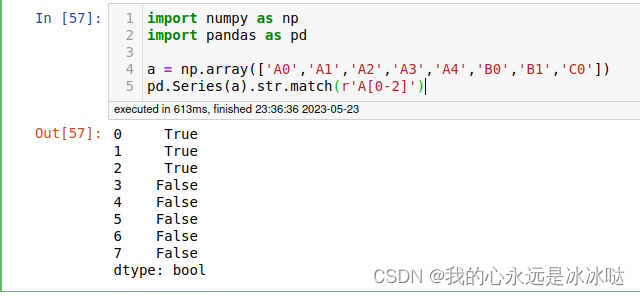
import numpy as np
import pandas as pd
a = np.array(['A0','A1','A2','A3','A4','B0','B1','C0'])
pd.Series(a).str.match(r'A[0-2]')
example2
s = pd.Series(['zzzz', 'zzzd', 'zzdd', 'zddd', 'dddn', 'ddnz', 'dnzn', 'nznz',
'znzn', 'nznd', 'zndd', 'nddd', 'ddnn', 'dnnn', 'nnnz', 'nnzn', 'nznn', 'znnn',
'nnnn', 'nnnd', 'nndd', 'dddz', 'ddzn', 'dznn', 'znnz', 'nnzz', 'nzzz', 'zzzn',
'zznn', 'dddd', 'dnnd'])
#print(s.str.endswith("dd"))
#print("*"*50)
#print(s[s.str.endswith("dd")])
#print("*"*50)
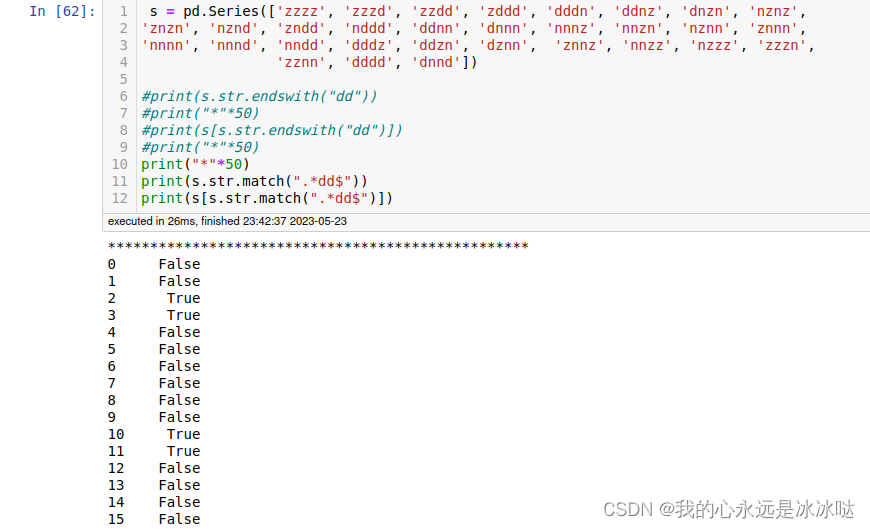
print("*"*50)
print(s.str.match(".*dd$"))
print(s[s.str.match(".*dd$")])
pandas.str.extract
注意正则表达式里的括号里的内容就是最终返回匹配的内容
example1
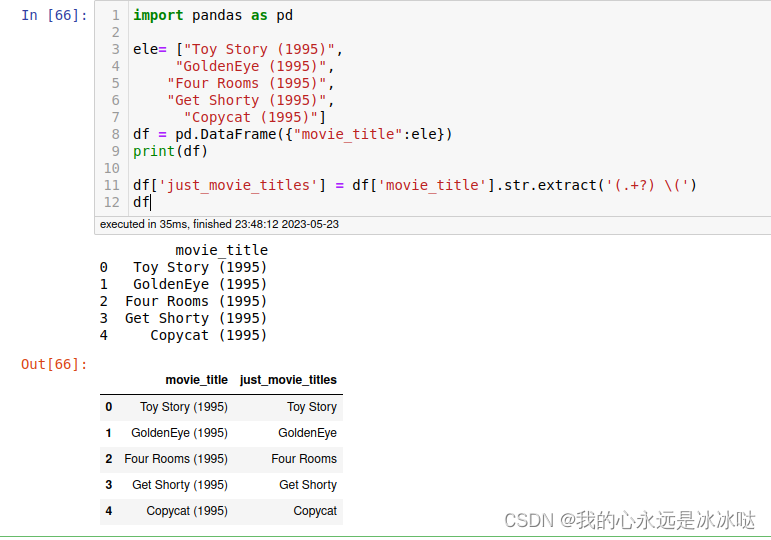
import pandas as pd
ele= ["Toy Story (1995)",
"GoldenEye (1995)",
"Four Rooms (1995)",
"Get Shorty (1995)",
"Copycat (1995)"]
df = pd.DataFrame({"movie_title":ele})
print(df)
df['just_movie_titles'] = df['movie_title'].str.extract('(.+?) \(')
df
example 2
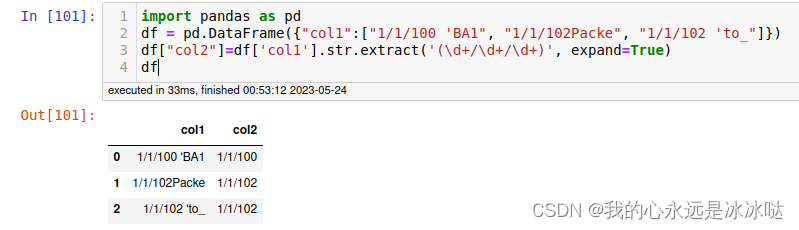
import pandas as pd
df = pd.DataFrame({"col1":["1/1/100 'BA1", "1/1/102Packe", "1/1/102 'to_"]})
df["col2"]=df['col1'].str.extract('(\d+/\d+/\d+)', expand=True)
df
结果如下
example3
# importing pandas as pd
import pandas as pd
# importing re for regular expressions
import re
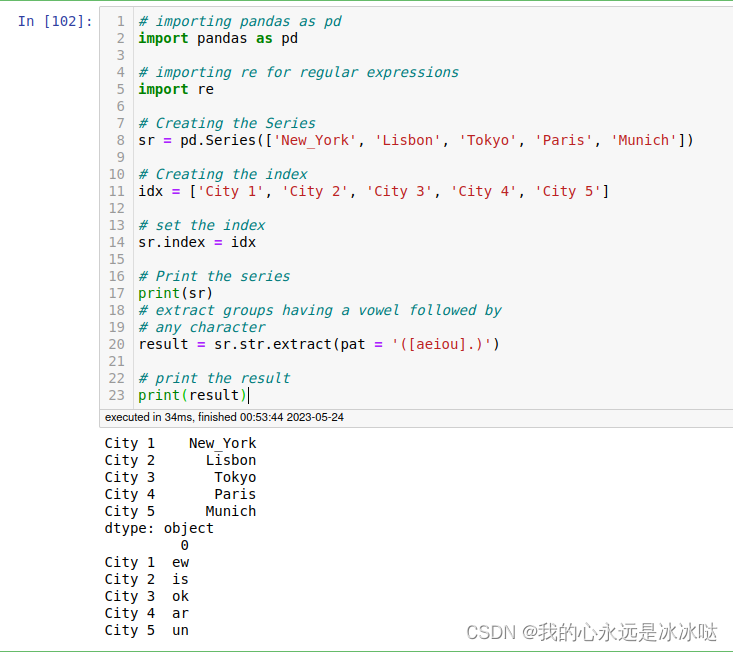
# Creating the Series
sr = pd.Series(['New_York', 'Lisbon', 'Tokyo', 'Paris', 'Munich'])
# Creating the index
idx = ['City 1', 'City 2', 'City 3', 'City 4', 'City 5']
# set the index
sr.index = idx
# Print the series
print(sr)
# extract groups having a vowel followed by
# any character
result = sr.str.extract(pat = '([aeiou].)')
# print the result
print(result)
example4
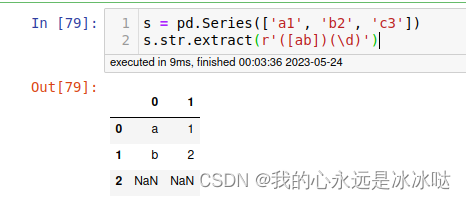
import pandas as pd
s = pd.Series(['a1', 'b2', 'c3'])
s.str.extract(r'([ab])(\d)')
设置expand = True
s.str.extract(r'[ab](\d)', expand=True)
 设置新的列名
设置新的列名
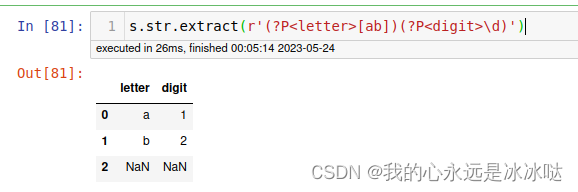
s.str.extract(r'(?P<letter>[ab])(?P<digit>\d)')
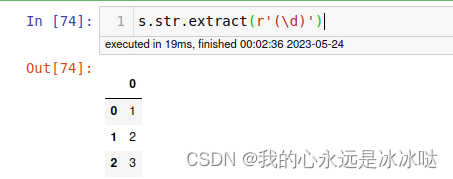
s.str.extract(r'(\d)')
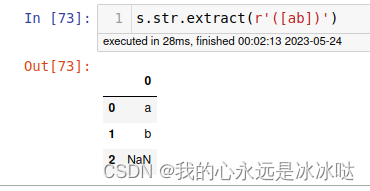
s.str.extract(r'([ab])')
pandas.str.split
example1
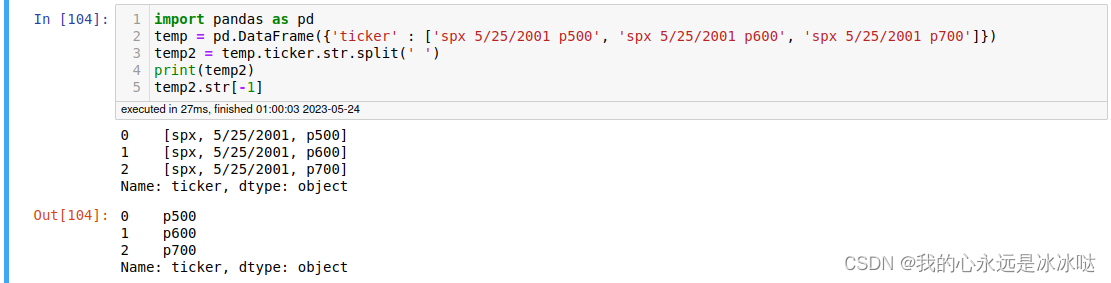
import pandas as pd
temp = pd.DataFrame({'ticker' : ['spx 5/25/2001 p500', 'spx 5/25/2001 p600', 'spx 5/25/2001 p700']})
temp2 = temp.ticker.str.split(' ')
print(temp2)
temp2.str[-1]
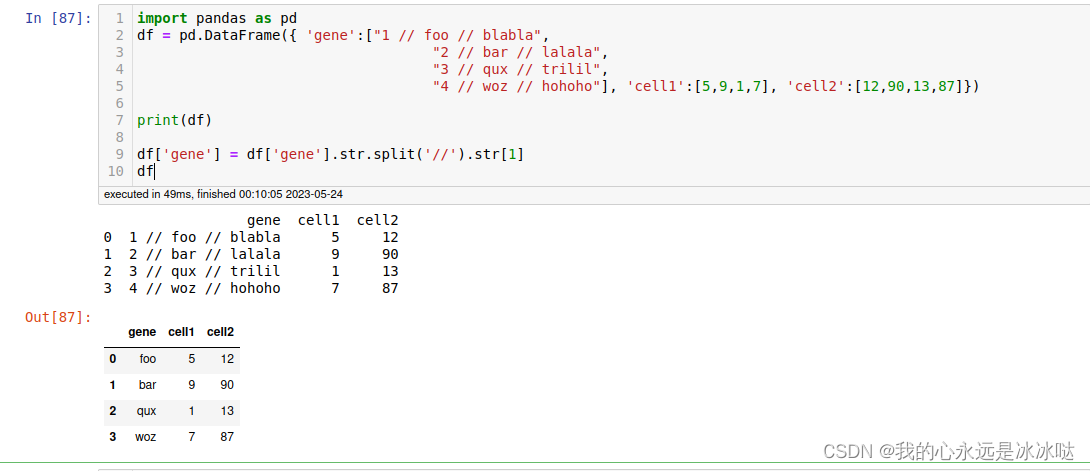
抽取某一列的部分元素设置为新列
import pandas as pd
df = pd.DataFrame({ 'gene':["1 // foo // blabla",
"2 // bar // lalala",
"3 // qux // trilil",
"4 // woz // hohoho"], 'cell1':[5,9,1,7], 'cell2':[12,90,13,87]})
print(df)
df['gene'] = df['gene'].str.split('//').str[1]
df
结果如下
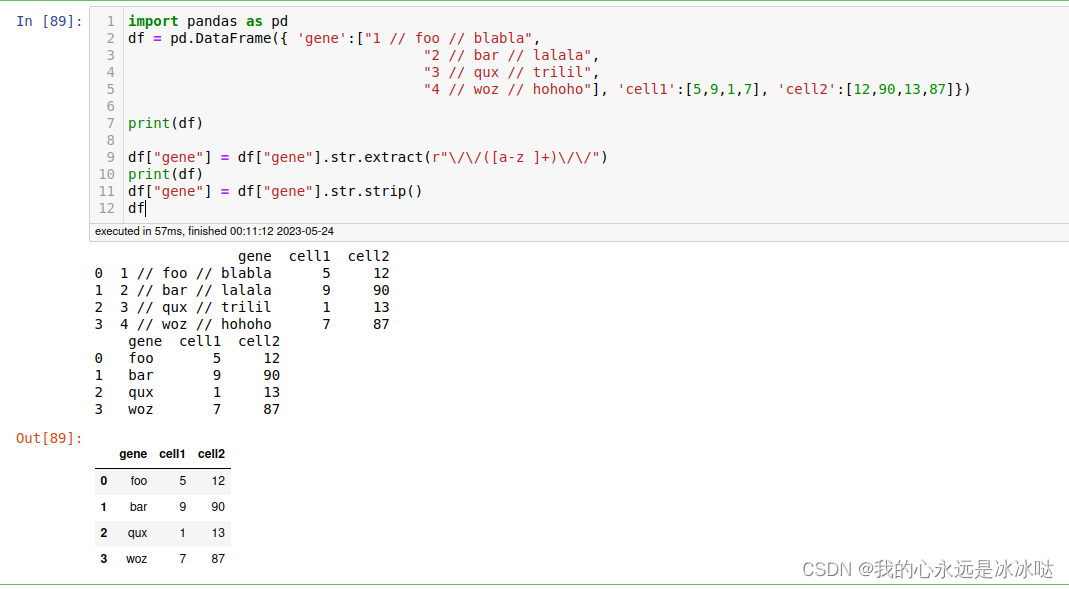
 可以使用pandas.str.extract达到pandas.str.split的同样结果
可以使用pandas.str.extract达到pandas.str.split的同样结果
import pandas as pd
df = pd.DataFrame({ 'gene':["1 // foo // blabla",
"2 // bar // lalala",
"3 // qux // trilil",
"4 // woz // hohoho"], 'cell1':[5,9,1,7], 'cell2':[12,90,13,87]})
print(df)
df["gene"] = df["gene"].str.extract(r"\/\/([a-z ]+)\/\/")
print(df)
df["gene"] = df["gene"].str.strip()
df
结果如下
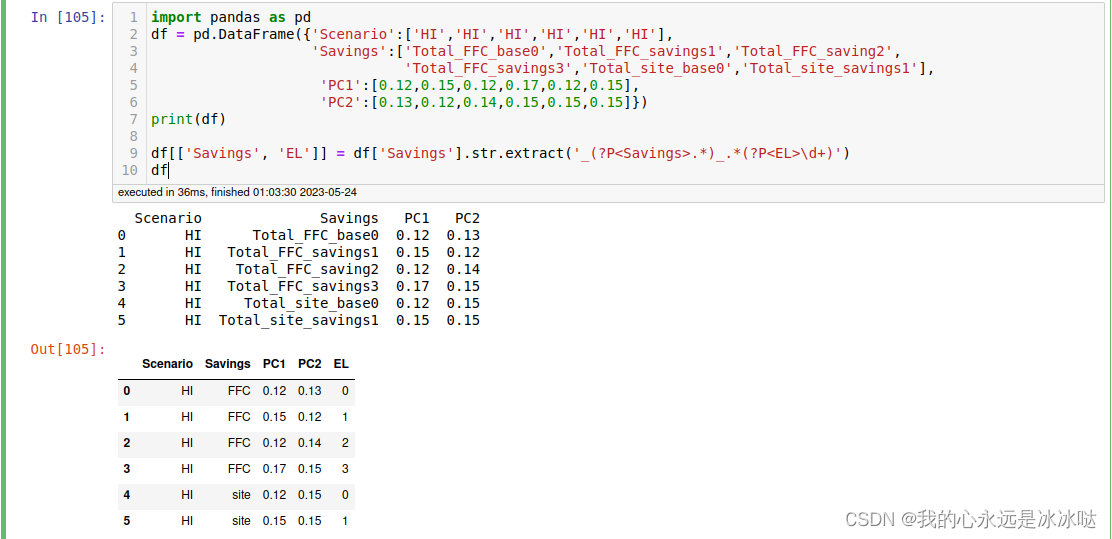
example2
import pandas as pd
df = pd.DataFrame({'Scenario':['HI','HI','HI','HI','HI','HI'],
'Savings':['Total_FFC_base0','Total_FFC_savings1','Total_FFC_saving2',
'Total_FFC_savings3','Total_site_base0','Total_site_savings1'],
'PC1':[0.12,0.15,0.12,0.17,0.12,0.15],
'PC2':[0.13,0.12,0.14,0.15,0.15,0.15]})
print(df)
df[['Savings', 'EL']] = df['Savings'].str.extract('_(?P<Savings>.*)_.*(?P<EL>\d+)')
df
import pandas as pd
df = pd.DataFrame({'Scenario':['HI','HI','HI','HI','HI','HI'],
'Savings':['Total_FFC_base0','Total_FFC_savings1','Total_FFC_saving2',
'Total_FFC_savings3','Total_site_base0','Total_site_savings1'],
'PC1':[0.12,0.15,0.12,0.17,0.12,0.15],
'PC2':[0.13,0.12,0.14,0.15,0.15,0.15]})
print(df)
df['Savings'].str.extract('(.*)_(.*)_(.*)')
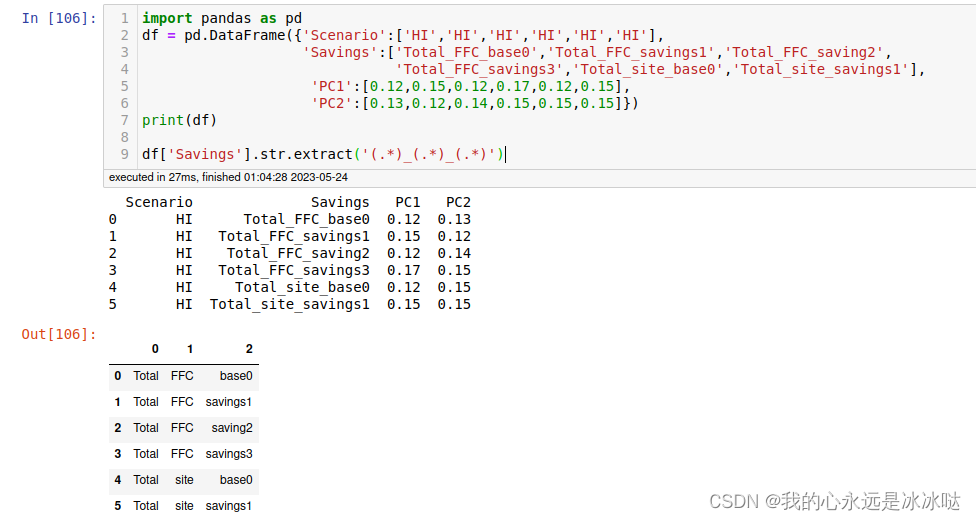
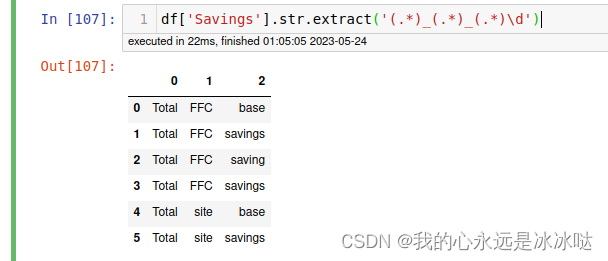
df['Savings'].str.extract('(.*)_(.*)_(.*)\d')
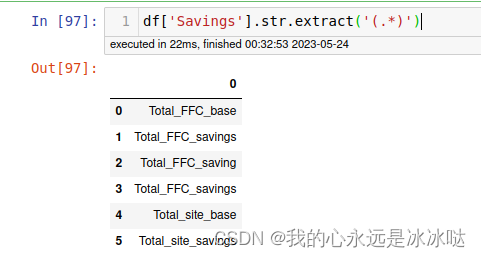
df['Savings'].str.extract('(.*)')
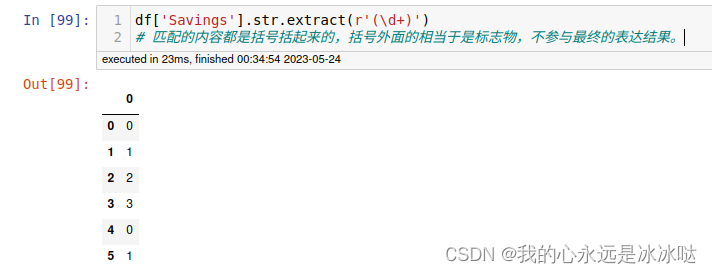
df['Savings'].str.extract(r'(\d+)')
# 匹配的内容都是括号括起来的,括号外面的相当于是标志物,不参与最终的表达结果。
实例操作1
import numpy as np
import pandas as pd
ele = np.array(['CD1C_P14_S91', 'CD1C_P14_S96', 'CD1C_P3_S12', 'CD141_P7_S22',
'CD141_P7_S24', 'CD1C_P4_S36', 'CD141_P7_S7', 'CD141_P8_S27',
'CD141_P8_S31', 'CD141_P9_S72', 'pDC_P10_S73', 'pDC_P10_S74',
'pDC_P10_S83', 'pDC_P13_S56', 'pDC_P13_S59', 'pDC_P13_S70',
'pDC_P14_S76', 'pDC_P14_S78', 'pDC_P14_S87', 'pDC_P14_S89',
'pDC_P14_S90', 'pDC_P14_S91', 'pDC_P14_S92', 'pDC_P3_S14',
'pDC_P3_S16', 'pDC_P3_S17', 'pDC_P3_S18', 'pDC_P3_S1',
'pDC_P3_S21', 'pDC_P3_S2', 'pDC_P3_S4', 'pDC_P3_S5', 'pDC_P4_S28',
'pDC_P4_S29', 'pDC_P4_S30', 'pDC_P4_S36', 'pDC_P4_S37',
'pDC_P4_S40', 'pDC_P4_S42', 'pDC_P4_S43', 'pDC_P4_S45',
'pDC_P4_S46', 'pDC_P4_S48', 'pDC_P7_S15', 'pDC_P7_S16',
'pDC_P7_S17', 'pDC_P7_S1', 'pDC_P7_S21', 'pDC_P7_S22', 'pDC_P7_S3',
'pDC_P7_S7', 'pDC_P8_S26', 'pDC_P8_S28', 'pDC_P8_S32',
'pDC_P8_S34', 'pDC_P8_S39', 'pDC_P8_S40', 'pDC_P8_S42',
'pDC_P8_S44', 'pDC_P8_S46', 'pDC_P8_S47', 'pDC_P9_S52',
'pDC_P9_S54', 'pDC_P9_S61', 'pDC_P9_S63', 'pDC_P9_S65',
'pDC_P9_S71', 'DoubleNeg_P10_S73', 'DoubleNeg_P10_S76',
'DoubleNeg_P10_S79', 'DoubleNeg_P10_S80', 'DoubleNeg_P10_S81',
'DoubleNeg_P10_S84', 'DoubleNeg_P10_S86', 'DoubleNeg_P13_S49',
'DoubleNeg_P13_S53', 'DoubleNeg_P13_S64', 'DoubleNeg_P13_S67',
'DoubleNeg_P14_S74', 'DoubleNeg_P14_S78', 'DoubleNeg_P14_S81',
'DoubleNeg_P14_S82', 'DoubleNeg_P14_S83', 'DoubleNeg_P14_S87',
'DoubleNeg_P14_S90', 'DoubleNeg_P14_S92', 'DoubleNeg_P14_S95',
'DoubleNeg_P3_S1', 'DoubleNeg_P3_S20', 'DoubleNeg_P3_S24',
'DoubleNeg_P3_S3', 'DoubleNeg_P3_S5', 'DoubleNeg_P3_S7',
'DoubleNeg_P4_S29', 'DoubleNeg_P4_S30', 'DoubleNeg_P4_S35',
'DoubleNeg_P4_S39', 'DoubleNeg_P4_S42', 'DoubleNeg_P4_S45',
'DoubleNeg_P4_S46', 'DoubleNeg_P7_S11', 'DoubleNeg_P7_S13',
'DoubleNeg_P7_S14', 'DoubleNeg_P7_S16', 'DoubleNeg_P7_S24',
'DoubleNeg_P7_S2', 'DoubleNeg_P7_S3', 'DoubleNeg_P7_S5',
'DoubleNeg_P7_S7', 'DoubleNeg_P7_S8', 'DoubleNeg_P8_S25',
'DoubleNeg_P8_S30', 'DoubleNeg_P8_S38', 'DoubleNeg_P8_S41',
'DoubleNeg_P8_S42', 'DoubleNeg_P8_S43', 'DoubleNeg_P8_S44',
'DoubleNeg_P9_S64', 'DoubleNeg_P9_S66', 'CD1C_P13_S57',
'CD1C_P13_S63', 'CD1C_P14_S85'])
df = pd.DataFrame({"cell":ele})
df
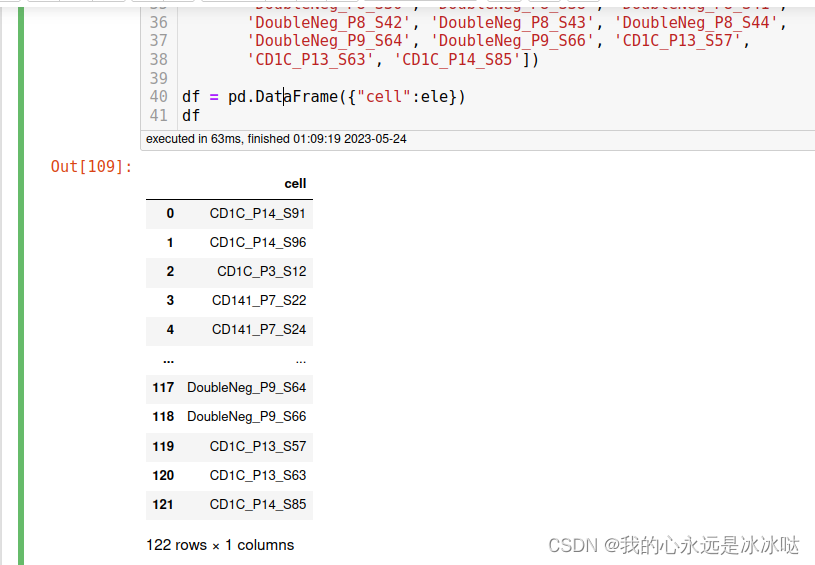
测试1(仅仅抽取大写字母)
df["cell"].str.extract(r"([A-Z]+)")
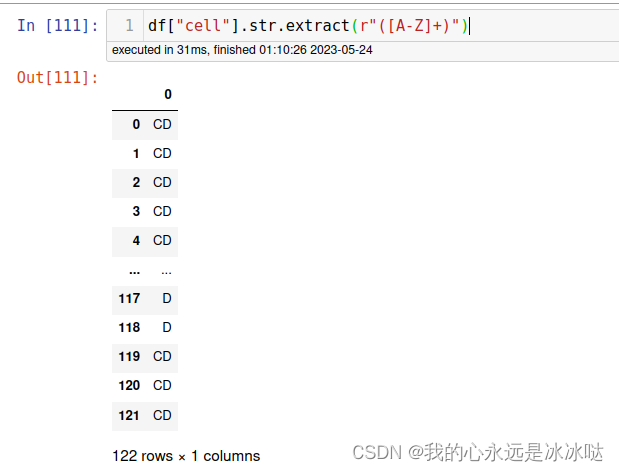
测试2(抽取大写字母和小写字母)
df["cell"].str.extract(r"([A-Za-z]+)")

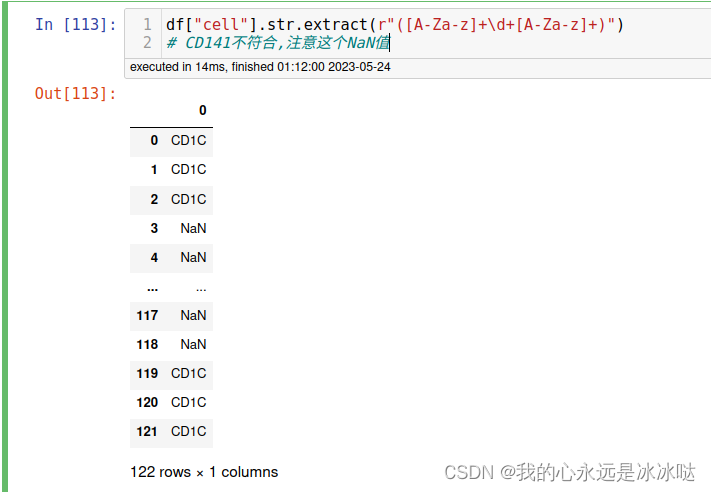
测试3(联合使用)
df["cell"].str.extract(r"([A-Za-z]+\d+[A-Za-z]+)")
# CD141不符合,注意这个NaN值
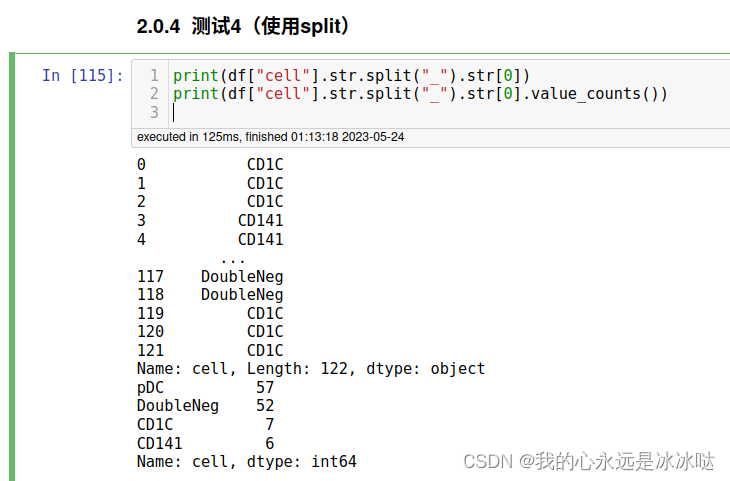
测试4(使用split)
print(df["cell"].str.split("_").str[0])
print(df["cell"].str.split("_").str[0].value_counts())
测试5(使用正则表达式)
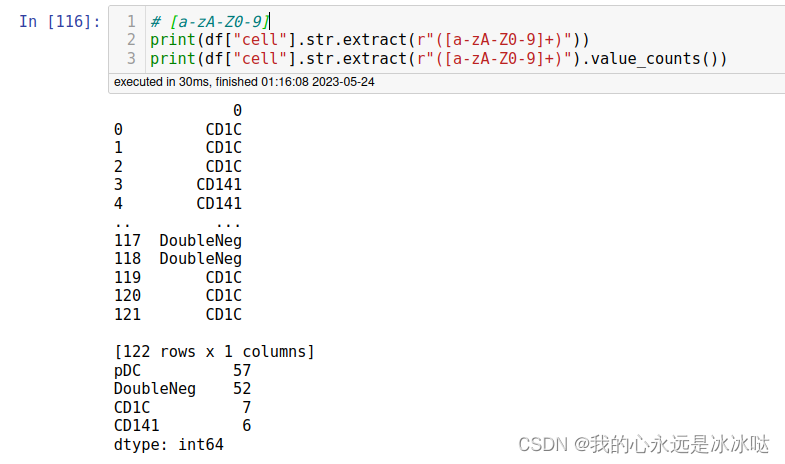
# [a-zA-Z0-9] 判断字母和数字
print(df["cell"].str.extract(r"([a-zA-Z0-9]+)"))
print(df["cell"].str.extract(r"([a-zA-Z0-9]+)").value_counts())





![[ 云计算 Azure ] Chapter 07 | Azure 网络服务中的虚拟网络 VNet、网关、负载均衡器 Load Balancer](https://img-blog.csdnimg.cn/ac01608c4a524646bb0cf777c148b348.png)