SAM是什么
前言
最近几周,人工智能的圈子里都在讨论SAM(Segment Anything Model),一个号称(零样本)分割一切的图像分割模型。

2023年4月6号,Meta AI发布一篇论文:《Segment Anything》。在论文中,他们提出一个用于图像分割的基础模型,名为SAM(Segment Anything Model)。该模型可以通过用户提示(如点击、画框、掩码、文本等)从图像中分割出特定的对象。除此之外,它可以零样本泛化到新颖的视觉概念和数据分布(通俗来说,就是它可以分割一切图像上的视觉对象,即使这些对象没有在训练集出现过)。这意味着从业者不再需要收集自己的细分数据为用例微调模型了,这种能够泛化到新任务和新领域的灵活性,在图像分割领域尚属首次。

SAM已经学会了关于物体的一般概念,并且它可以为任何图像或视频中的任何物体生成Mask,甚至包括在训练过程中没有遇到过的物体和图像类别。SAM足够通用,可以涵盖广泛的用例,并且可以在新的图像领域上开箱即用,无需额外的训练。
此外,SAM通过单一模型,既可以使用交互式方法进行图像分割,也可以全自动图像分割。
图解SAM

首先,这篇论文主要作出三点贡献:
-
抛出一个Segment Anything(SA)的项目,在一个统一框架Prompt Encoder内,指定一个点、一个边界框、一句话,直接一键分割出对应物体
-
提出一个图像分割的基础模型:SAM(由图像编码器、提示编码器、解码器组成)
-
提出一个大规模多样化的图像分割数据集:SA-1B(包含1100万张图片以及10亿个Mask图)
在这项工作中,SA的目标是建立一个图像分割的基础模型(Foundation Models)。换言之,作者团队寻求开发一个可提示的分割模型,并在一个大规模且支持强大泛化能力的数据集上对其进行预训练,然后用提示工程(Prompt Engineering)解决一系列新的数据分布上的下游分割问题。
基础模型是指在广泛的数据上进行大规模训练,并且是适应广泛的下游任务。
提示工程是指任意表示图像中要分割的信息,如一组前景/背景点、一个粗略的框或者掩码、自由形式的文本等。
那么,要实现上述方案,取决于三个组件:任务、模型、数据。因此,我们可以分为以下三章对SAM进行分析。
怎么样解决ZERO SHOT问题
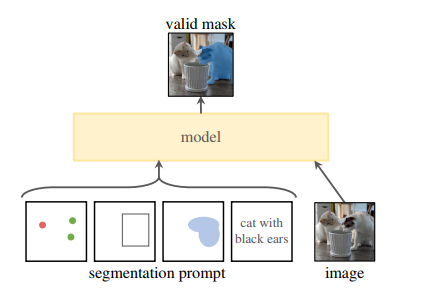
受到NLP领域中Prompt(提示)的启发,作者提出可提示分割任务。该任务的目标是给定任意分割提示,模型返回有效的分割掩码。其中,提示可以是任何指示要分割内容的信息(如点、框,掩码、文本等)。“有效”掩码要求即使提示是模糊的,并且可能指向多个对象,输出也应该是这些对象中的至少一个合理掩码。如下图所示,在手臂上的一个点提示,既可以表示手臂这个对象,也可以表示人这个对象(此要求,类似于期望语言模型对模棱两可的提示输出连贯的响应)。

ZERO SHOT模型的设计问题
由于可提示分割任务和现实世界使用的约束,模型的设置需要满足一些要求:
-
必须支持灵活的提示
-
需要在交互时实时计算掩码
-
必须具备歧义识别的能力
为此,设计了Segment Anything Model(SAM),包含一个强大的图像编码器(计算图像嵌入),一个提示编码器(计算提示嵌入),一个轻量级掩码解码器(实时预测掩码)。在使用时,只需要对图像提取一次图像嵌入,可以在不同的提示下重复使用。给定一个图像嵌入,提示编码器和掩码解码器可以在浏览器中在~50毫秒内根据提示预测掩码。

图像编码器:可以是任意能够编码图像的网络,实际项目中作者使用经过MAE预训练的Transformer(ViT-H)
提示解码器:考虑两组提示:稀疏(点、框、文本)和密集(掩码)。其中点和框通过位置编码来表示;文本通过CLIP的文本编码器来表示;掩码使用卷积来表示
掩码解码器:Transformer Decoder(类似于Maskformer),将图像嵌入、提示嵌入和Token映射到Mask
如何平衡巨量数据的质量/成本问题
提出一个用于图像分割的数据集:SA-1B,它包含1100万张多样化、高分辨率、授权和保护隐私的图像以及11亿个高质量的分割掩码组成。SA-1B的掩码比任何现有的分割数据集多400倍,并且掩码具有高质量和多样化等特点。
图像:从直接与摄像师合作的供应商处获得一组1100万张新图片的授权。原始图像是高分辨率的(平均3300x4950像素),为了存储方便,发布时图像下采样为最短边为1500像素的图像。(发布的图像中人脸和车辆拍照进行模糊处理)

掩码:11亿个高质量掩码,其中99.1%由数据引擎全自动生成

掩码质量:为了评估掩码质量,作者随机抽取了500张图像(~5万个掩码),要求专业标注员使用像素精确的“画笔”和“橡皮擦”在模型预测掩码的基础上对其进行专业矫正。这一过程,产生成对的模型预测掩码以及人工专业矫正后的掩码。通过计算每对之间的IoU,来评估掩码质量。实现结果发现,94%的对具有大于90%的IoU(97%的对具有大于75%的IoU)
数据引擎:为了对庞大数据的图像进行掩码标注,作者开发了数据引擎。如图所示,它是一个模型、数据的闭环系统。模型标注数据,标注好的数据用来优化模型。循环,迭代优化模型以及数据质量
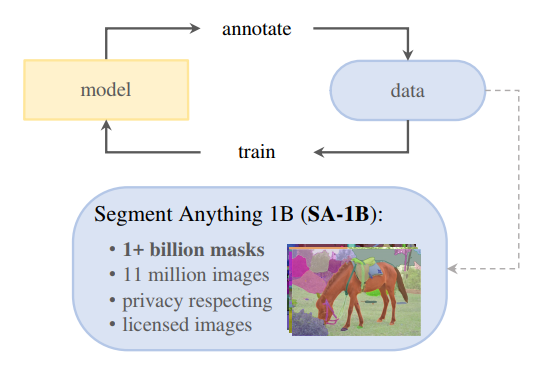
该数据引擎有三个阶段:(1)模型辅助手动标注;(2)半自动标注阶段,混合自动预测的掩码和人工标注掩码;(3)全自动阶段。
(1)模型辅助手动标注阶段
该阶段开始之前,首先使用常见的公开图像分割数据集训练SAM,然后使用SAM为SA-1B数据预测图像掩码(提示为前景/背景点击),由一组专业标注人员在预测掩码的基础上进行掩码细化。
标注人员可以自由地为掩码赋予标签(类别语义没有受限);此外,标注人员需要按照对象的突出程度来标记对象,并且掩码标注超过30秒就要继续处理下一张图像。
在充分的数据标注后,仅使用新标注的掩码对SAM进行重新训练(该阶段总共训练了模型6次)。随着收集到更多的掩码,图像编码器从ViT-B扩展到ViT-H。同时,随着模型的改进。每个掩码的平均标注时间从34秒减少到14秒(比COCO的掩码标注快6.5倍,比2D框标注慢2倍);每个图像的平均掩码数量从20个掩码增加到44个掩码。总的来说,该阶段从12万张图像中收集了4630万个掩码。
(2)半自动阶段
该阶段的目标是增加掩码的多样性,以提供模型分割东西的能力。为了使标注者专注于不太突出的对象,首先SAM自动分割高置信度的掩码(为了检测高置信度掩码,使用通过目标类别在第一阶段掩码上训练了一个目标检测器),然后向标注者展示预填充这些掩码的图像,并要求他们标注任何其他未标注的对象。
该阶段在18万张图像中额外收集590万个掩码(总共1020万个掩码)。与第一阶段一样,定期在新收集的数据集上重新训练模型(5次)。
每个掩码的平均标注时间回到34秒(因为这些目标更具挑战性)。每个图像的平均掩码数量从44个增加到72个。
(3)全自动阶段
这个阶段,标注是全自动的,因为模型有两个主要的增强。首先,在这一阶段的开始,收集了足够多的掩码来大大改进模型;其次,在这一阶段,已经开发了模糊感知模型,它允许在有歧义的情况下预测有效的掩码。具体来说,用32x32的规则网络点来提示网络,并为每个点预测一组可能对应于有效对象的掩码。
在模糊感知模型中,如果一个点位于某个部分或子部分上,模型将返回子部分、局部和整个对象。该模型的IoU模块将选择高置信度的掩码,同时选择稳定掩码(如果阈值化概率图在0.5-σ,0.5+σ)产生相似的掩码,则认为是稳定掩码。
最后,在选择高置信度和稳定的掩码后,采用NMS对重复数据进行过滤。该阶段,在1100万张图像上全自动生成11亿个高质量掩码。
SAM带来的影响
随着SAM的出现,越来越多的工作依托于SAM进行各自领域的开发,如:
-
Edit Everything:编辑一切,该系统结合SAM、CLIP、Stable Diffusion,允许用户使用简单的文本指令编辑图像
-
SkinSAM:使用SAM实现皮肤癌分割
-
Track Anything:将SAM扩展到视频,以实现交互式视频目标跟踪和分割
-
MSA:对SAM进行高效微调,在各种模态(包括CT/MRI/超声等)19个医学图像分割上取得最优成绩
-
SA3D:将SAM从2D提升到3D,与Nerf相结合,允许用户在单个渲染试图中仅通过一次手动提示获得任何目标的3D分割结果
-
缺陷检测:将SAM和U-Net结合,用于检测混凝土结构裂缝
-
MedSAM:将SAM应用到医学图像分割的首次尝试,整理了一个大型医学图像分割数据集,通过对SAM进行微调,使其适应一般医学图像分割任务
-
SAM-Adapter:探索和实验SAM在不同下游任务的表现
-
SSA:提出一个基于SAM的语义分割框架,不仅能够准确地分割mask,还能预测每个mask的语义分类。
-
SEEM:在没有提示的开放集中执行任何分割任务
-
Grounded SAM:结合SAM、DINO、Stable Diffusion、Whisper、ChatGPT来检测和分割带有文本输入的任何东西
-
......
SAM促进了计算机视觉领域更蓬勃地发展,对于从业者来说,SAM将Engineering的开箱即用做到了极致,SAM的生产力工具属性远远超过了其潜在的危险属性。在SAM问世之前,对于中下游的从业者来说,完成一个图像分割任务至少需要满足以下几个条件:
-
大量的图像标注工作
-
足够算力的设备
-
算法训练
原生SAM对于伪装目标分割领域无法取得较大的成绩之外,在其他下游任务(包含但不限于医学图像分割、遥感图像分割、缺陷检测、自动驾驶场景分割等)都有不错的表现。此外,SAM还可以作为算子融合中的一部分,搭配其他算子完成除图像分割之外的其他任务。
同时,我们发现原版的SAM在以下这些数据生产的场景中仍然有一些不足:
-
Segment Anything模式会生成一些不连续的Mask,粗细粒度调整困难,边界有一些不够清晰,分散的结构不能很好支持(例如闪电中的镂空、道路裂缝等)
-
SAM目前生成的Mask都是无标签的(目前已有通过DINO这样的开集目标检测来做优化,但离企业级的数据仍有较大距离)
同时我们发现在细分领域 / 场景下的其他模型,也会超过SAM,例如Ilastik,但总的来说我们仍认为SAM是一颗图片数据生产场景的银弹,通过对SAM的改造就可以极大的提升数据生产的效率,而其Prompt Encoder的设计意味着只要是能向量化的操作都可以对数据进行分割,这给数据生产带来更多的可能性,之后的很多工作会围绕着自动生成更好的Prompt展开。
整数智能已经通过将SAM集成进ABAVA标注平台,为用户提供了更好的标注体验。在使用SAM模型时,用户可以轻松、高效地完成数据标注任务,并且基于SAM的特点为数据场景做了专项优化,使标注结果更加准确。
整数智能将继续致力于为用户提供更优质的产品和创新的解决方案服务。也将持续优化SAM模型,致力于不断提升其标注效率和准确性以满足用户不断增长的需求。
关于整数智能
80%的数据 + 20%的算法 = 更好的AI

人工智能的研发是一个非常标准化的流程,它会经历4步,从数据采集->数据标注->模型训练->模型部署。而80%的研发时间,则消耗在了数据采集与数据标注的环节。数据工程的核心在于高效率、高质量的数据标注。
整数智能——AI行业的数据合伙人
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员。

整数智能提供了智能数据工程平台(ABAVA Platform)与数据集构建服务(ACE Service)。满足了智能驾驶、AIGC、智慧医疗、智能安防、智慧城市、工业制造、智能语音、公共管理等数十个应用场景的数据需求。目前公司已合作海内外顶级科技公司与科研机构200余家,拥有知识产权数十项,多次参与人工智能领域的标准与白皮书撰写。整数智能也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。
1.专业级的团队和技术支撑
-
强大的研发团队持续迭代AI数据平台ABAVA Platform,创造极致的AI数据标注效率
-
数据专家为您制定数据集构建方案,满足您对数据集的定制化需求
2.满足全领域多场景的数据标注需求
-
在图像与视频数据方面,支持关键点标注、线标注、框标注、语义分割标注、立体框标注、逐帧标注等标注需求
-
在点云数据方面,支持3D点云框标注、3D点云语义分割、3D点云车道线标注、2/3D融合标注等标注需求
-
在文本数据方面,支持NER命名实体标注、SPO文本三元组标注、内容审核、情绪分析等标注需求
-
在音频数据方面,支持ASR标注、音素标注、MIDI标注等标注需求

3.极致的的数据交付质量
-
整数智能拥有数十家自建数据产业基地和合作产业基地,覆盖10万名人工智能训练师,逐步形成一套科学专业的人员、质量管控及数据安全保障机制
-
依托数据标注方面所积累的经验,平台可达成100万张图像标注量级的峰值。整数智能数据管理平台通过流程与机制的双重保障,为您提供质量更优、响应速度更快的数据服务,助力企业用户实现降本增效
联系我们
希望能够与正在阅读这篇文章的您进一步交流沟通,一起探索AI数据的更多可能性。欢迎联系我们:
电话(微信同号):137-8507-0844
邮箱:zzj@molardata.com
也可以关注我们的账号:整数智能AI研究院