目录
- 前言
- 一、读写json
- 1.1 读
- 1.2 写
- 1.2.1 list类型写入
- 1.2.2 dict类型写入
- 二、读写csv
- 2.1 读
- 2.2 写
- 2.2.1 list类型写入
- 2.2.2 dict类型写入
- 三、读写txt
- 3.1 读
- 3.2 写
- 按行写入(手动添加换行符\n)
- 按行写入(python添加换行符\n)
- 3.2.1 list类型写入
- 3.2.2 dict类型写入
- 四、读写docx
- 4.1 读
- 4.2 写
- 4.2.1 list类型写入
- 4.2.2 dict类型写入
- 五、读写xlsx
- 5.1 读
- 5.1.1 读多个sheet
- 5.1.2 读指定sheet工作表
- 5.1.3 读指定sheet中指定行/列内容
- 5.2 写
- 5.2.1 list类型写入
- 5.2.2 dict类型写入
- 六、读写xls
- 6.1 读
- 6.2 写
- 6.2.1 list类型写入
- 6.2.2 dict类型写入
- 6.2.3 修改原始文件内容
前言
最近再处理数据的时候,总会用到读写json,csv,xlsx和xls文件代码
这里就做个总结记录一下
一、读写json
1.1 读
## 读入json文件
### json格式:{'id':'....','instruction':'.......','input':'.....','output':'....'}
def get_json_data(path):
json_file = open(path, 'r', encoding='utf-8')
json_data = []
for line in json_file.readlines():
dic = json.loads(line)
## 单独提取每个字段
id = dic['id']
instruction = dic['instruction']
input_all = dic['input']
output = dic['output']
## 提取整个字段
json_data.append(dic)
return json_data
扩展: json.loads(line)和 json.load(line)
1.2 写
通用写法:
## 写入json文件
with open(path, 'a+', encoding='utf-8') as file:
json.dump(dic, file, ensure_ascii=False) # dic是准备写入的dict类型
file.write('\n')
1.2.1 list类型写入
import json
my_list = [1, 2, 3, "four", "five"]
# 将list写入JSON文件
with open("my_list.json", "w") as f:
json.dump(my_list, f)
# 如果想再把json文件读出
with open("my_list.json", "r") as f:
my_list = json.load(f)
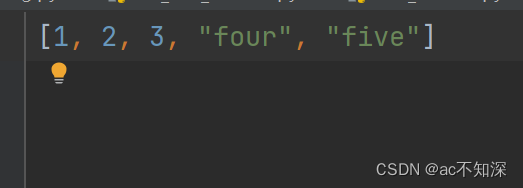
print(my_list) # [1, 2, 3, 'four', 'five']'
1.2.2 dict类型写入
import json
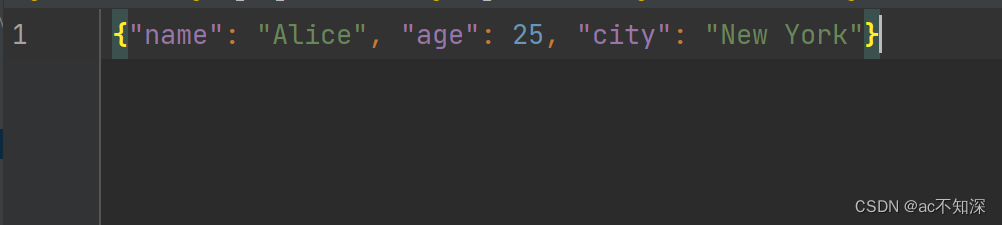
my_dict = {"name": "Alice", "age": 25, "city": "New York"}
# 将dict写入JSON文件
with open("my_dict.json", "w") as f:
json.dump(my_dict, f)
注意:json.dump()将Python对象序列化为JSON格式,并将其写入文件中。
扩展:json.dumps()和 json.dump()
二、读写csv
2.1 读
import csv
# 读取CSV文件
with open('input_file.csv', 'r') as input_file:
reader = csv.reader(input_file)
for row in reader:
print(row)
2.2 写
2.2.1 list类型写入
import csv
# 写入CSV文件
with open('output_file.csv', 'w', newline='') as output_file:
writer = csv.writer(output_file)
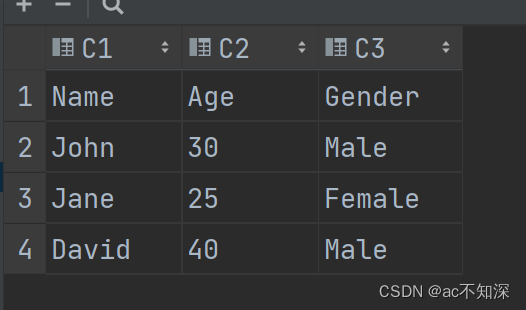
writer.writerow(['Name', 'Age', 'Gender'])
writer.writerow(['John', '30', 'Male'])
writer.writerow(['Jane', '25', 'Female'])
2.2.2 dict类型写入
import csv
data = [
{'Name': 'John', 'Age': '30', 'Gender': 'Male'},
{'Name': 'Jane', 'Age': '25', 'Gender': 'Female'},
{'Name': 'David', 'Age': '40', 'Gender': 'Male'}
]
# 写入CSV文件
with open('output_file.csv', 'w', newline='') as output_file:
fieldnames = ['Name', 'Age', 'Gender']
writer = csv.DictWriter(output_file, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
注意: 一般csv文件中只包含一个sheet工作表,所以这里就不举例含有多个sheet工作表的csv文件
三、读写txt
3.1 读
# 一、按行读取文本文件
with open('input.txt', 'r') as f:
# 使用 readline() 方法读取一行数据
line = f.readline()
while line:
print(line.strip()) # 去除行末的换行符
line = f.readline()
# 二、使用 readlines() 方法读取所有行数据
with open('input.txt', 'r') as f:
lines = f.readlines()
for line in lines:
print(line.strip()) # 去除行末的换行符
3.2 写
按行写入(手动添加换行符\n)
with open('output.txt', 'w') as f:
# 使用 write() 方法写入一行数据
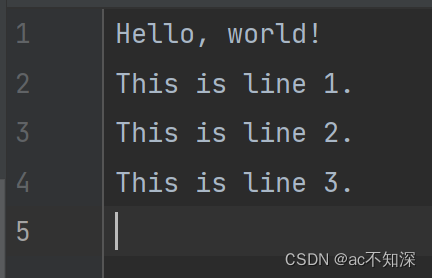
f.write('Hello, world!\n')
# 使用 writelines() 方法写入多行数据
lines = ['This is line 1.\n', 'This is line 2.\n', 'This is line 3.\n']
f.writelines(lines)
按行写入(python添加换行符\n)
python添加换行符的目的是防止使用不同平台(Windows/Mac/Linux),换行符编码不一致出现显示问题
import os
with open('output.txt', 'w') as f:
# 向文件写入多行数据,并在每行数据末尾添加换行符
lines = ['This is line 1.', 'This is line 2.', 'This is line 3.']
f.write(os.linesep.join(lines))
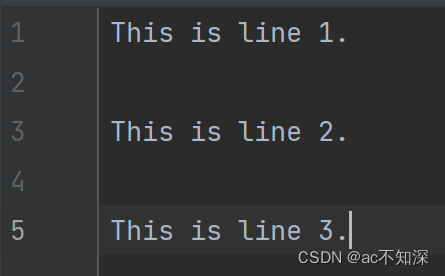
3.2.1 list类型写入
将列表中的每个字符串写入文件中,每个字符串占用一行。
# 将 List 类型的数据写入文本文件
data = ['apple', 'banana', 'orange', 'grape']
with open('output.txt', 'w') as f:
f.writelines([f'{item}\n' for item in data])
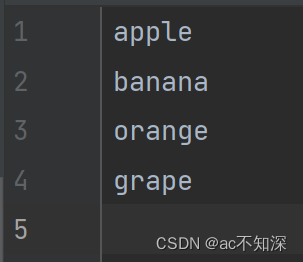
3.2.2 dict类型写入
# 将 Dict 类型的数据写入文本文件
data = {'name': 'Alice', 'age': 25, 'gender': 'female'}
with open('output.txt', 'w') as f:
f.writelines([f'{key}: {value}\n' for key, value in data.items()])
四、读写docx
注意:doc是Microsoft Word 97-2003文档文件格式。docx是Microsoft Word 2007及更高版本使用的文档文件格式。这里都使用的是docx后缀名,适不适用doc文件没有测试。
4.1 读
首先读取docx文件需要安装docx库:pip install python-docx 或者conda install -c conda-forge python-docx
docx文件中有以下内容:

import docx
# 打开DOCX文件
doc = docx.Document('my_doc.docx')
# 读取DOCX文件内容
for para in doc.paragraphs:
print(para.text)
4.2 写
4.2.1 list类型写入
import docx
my_list = ['apple', 'banana', 'orange']
# 创建一个新的DOC对象
doc = docx.Document()
# 将list写入DOCX文件中
for item in my_list:
doc.add_paragraph(item)
# 保存DOCX文件
doc.save('my_list.docx')

4.2.2 dict类型写入
import docx
my_dict = {'apple': 1.0, 'banana': 2.0, 'orange': 3.0}
# 创建一个新的DOC对象
doc = docx.Document()
# 将dict写入DOCX文件中
for key, value in my_dict.items():
doc.add_paragraph(f'{key}: {value}')
# 保存DOCX文件
doc.save('my_dict.docx')

五、读写xlsx
5.1 读
5.1.1 读多个sheet
这里以my_file.xlsx为例,文件中有三个sheet工作表,每个工作表中都有三行两列内容。对内容进行读取,5.1节代码都是沿用my_file.xlsx格式内容
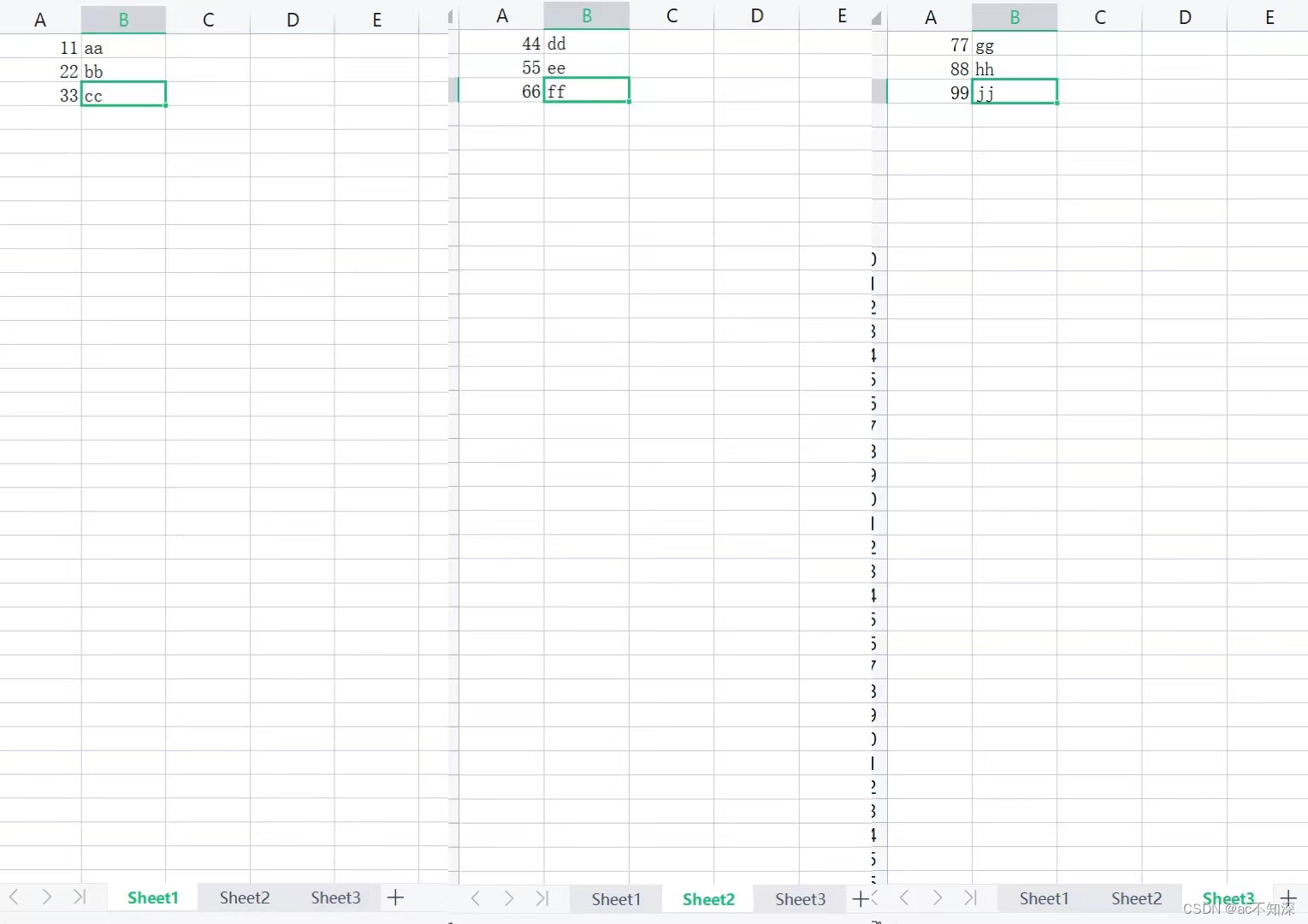
import openpyxl
# 打开XLSX文件
workbook = openpyxl.load_workbook('my_file.xlsx')
# 遍历所有工作表
for worksheet in workbook.worksheets:
print(f'工作表名称:{worksheet.title}')
# 读取工作表内容
for row in worksheet.iter_rows(values_only=True):
for cell in row:
print(cell)
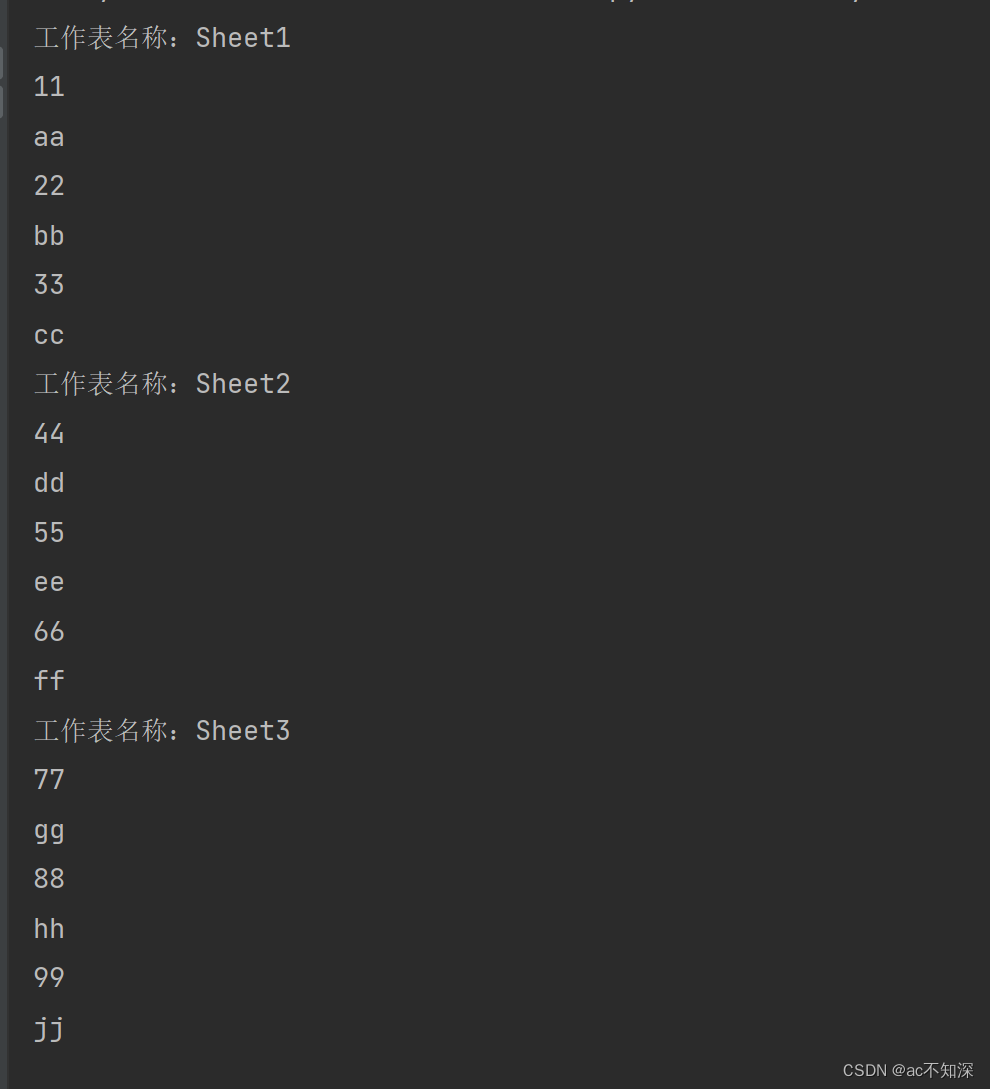
5.1.2 读指定sheet工作表
如果仅读取指定sheet工作表及特定某列的内容,可以考虑以下代码
import openpyxl
# 打开XLSX文件
workbook = openpyxl.load_workbook('my_file.xlsx')
# 选择特定工作表
worksheet = workbook['Sheet2']
# 读取特定单元格
cell_value = worksheet['A2'].value
print(cell_value)
即读取sheet2工作表的第A列2行内容
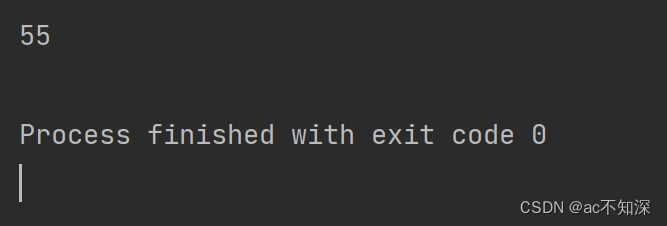
5.1.3 读指定sheet中指定行/列内容
import openpyxl
# 打开XLSX文件
workbook = openpyxl.load_workbook('my_file.xlsx')
# 指定工作表
worksheet = workbook['Sheet2']
# 读取第1、2行的内容
row_values = []
for row in worksheet.iter_rows(min_row=1, max_row=2): # 第一行和第二行内容
for cell in row:
row_values.append(cell.value)
print(row_values)
# 读取第1列的内容
col_values = []
for col in worksheet.iter_cols(min_col=1, max_col=1): # 第一列内容
for cell in col:
col_values.append(cell.value)
print(col_values)
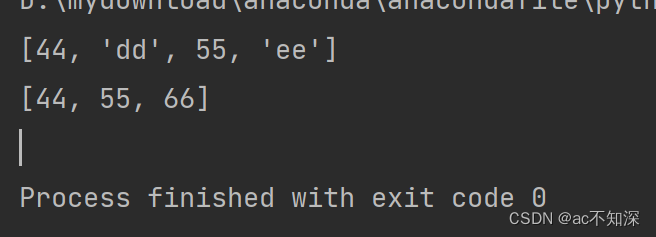
5.2 写
5.2.1 list类型写入
多sheet工作表写入代码
import openpyxl
from openpyxl import Workbook
# 创建工作簿对象
wb = Workbook()
# 创建第一个工作表并写入数据
ws1 = wb.active # 选择默认的工作簿
ws1.title = "List 1"
my_list1 = ['apple', 'banana', 'cherry']
for i in range(len(my_list1)):
ws1.cell(row=i+1, column=1, value=my_list1[i])
# 创建第二个工作表并写入数据
ws2 = wb.create_sheet("List 2")
my_list2 = ['date', 'elderberry', 'fig']
for i in range(len(my_list2)):
ws2.cell(row=i+1, column=1, value=my_list2[i])
# 保存工作簿为Excel文件
wb.save('my_lists.xlsx')


5.2.2 dict类型写入
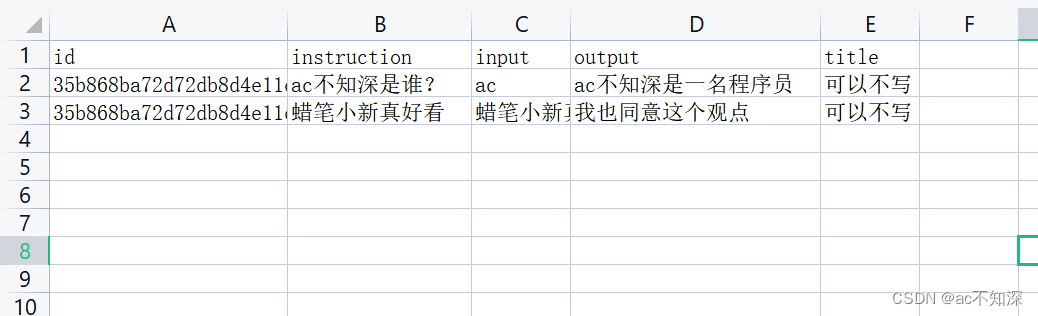
给出json中包含dict类型的两条测试案例:
{"id": "35b868ba72d72db8d4e11ca71e679f26", "instruction": "ac不知深是谁?", "input": "ac", "output": "ac不知深是一名程序员", "title": "可以不写"}
{"id": "35b868ba72d72db8d4e11ca71e679f27", "instruction": "蜡笔小新真好看", "input": "蜡笔小新真可爱", "output": "我也同意这个观点", "title": "可以不写"}
想测试的代码可以直接把上面两条复制,然后保存到my_file.json中
import json
import openpyxl
from tqdm import tqdm
data = []
# 读取json文件中dict类型的信息
with open('my_file.json', 'r',encoding='utf-8') as f:
for line in tqdm(f.readlines()):
dic = json.loads(line)
data.append(dic)
# 创建新的XLSX文件
workbook = openpyxl.Workbook()
# 创建新的工作表
worksheet = workbook.active
# 写入表头
header = list(data[0].keys())
for i in range(len(header)):
worksheet.cell(row=1, column=i+1, value=header[i])
# 写入数据
for i in range(len(data)):
row_data = list(data[i].values())
for j in range(len(row_data)):
worksheet.cell(row=i+2, column=j+1, value=row_data[j])
# 保存XLSX文件
workbook.save('my_output.xlsx')
六、读写xls
注意:xls是Excel 97-2003二进制工作簿格式,而xlsx是Excel 2007及更高版本使用的Open XML工作簿格式。
6.1 读
import openpyxl
# 打开Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
# 获取工作表对象
worksheet = workbook.active
# 读取单元格的值
cell = worksheet['A1']
print('cell.value:',cell.value)
# 迭代行和列,读取单元格的值
print("rows:")
for row in worksheet.iter_rows():
for cell in row:
print(cell.value)

6.2 写
6.2.1 list类型写入
import xlwt
# 创建一个新的Excel文件
workbook = xlwt.Workbook()
# 创建一个工作表对象
worksheet1 = workbook.add_sheet('My Sheet1')
worksheet2 = workbook.add_sheet('My Sheet2')
# 写入列表1的内容
my_list1 = ['apple', 'banana', 'cherry']
for i in range(len(my_list1)):
worksheet1.write(i, 0, my_list1[i])
# 写入列表2的内容
my_list2 = ['cat', 'dog', 'bird']
for i in range(len(my_list2)):
worksheet2.write(i, 0, my_list2[i])
# 保存Excel文件
workbook.save('my_list.xls')


6.2.2 dict类型写入
这一段代码可以参考5.2.2的内容部分
dict类型同上
{"id": "35b868ba72d72db8d4e11ca71e679f26", "instruction": "ac不知深是谁?", "input": "ac", "output": "ac不知深是一名程序员", "title": "可以不写"}
{"id": "35b868ba72d72db8d4e11ca71e679f27", "instruction": "蜡笔小新真好看", "input": "蜡笔小新真可爱", "output": "我也同意这个观点", "title": "可以不写"}
import json
import openpyxl
from tqdm import tqdm
data = []
# 读取json文件中dict类型的信息
with open('my_file.json', 'r', encoding='utf-8') as f:
for line in tqdm(f.readlines()):
dic = json.loads(line)
data.append(dic)
# 创建新的XLSX文件
workbook = openpyxl.Workbook()
# 创建新的工作表
worksheet = workbook.active
# 写入表头
header = list(data[0].keys())
for i in range(len(header)):
worksheet.cell(row=1, column=i + 1, value=header[i])
# 写入数据
for i in range(len(data)):
row_data = list(data[i].values())
for j in range(len(row_data)):
worksheet.cell(row=i + 2, column=j + 1, value=row_data[j])
# 保存XLSX文件
# workbook.save('my_output.xlsx') # 5.2.2的版本
workbook.save('my_output.xls') # 把5.2.2的保存后缀改为 .xls
6.2.3 修改原始文件内容
在原始文件上进行修改
import xlrd
import xlwt
# 打开Excel文件
workbook = xlrd.open_workbook('example.xls')
# 获取第一个工作表
worksheet = workbook.sheet_by_index(0)
# 修改第一个单元格的值
worksheet.cell(0, 0).value = 'New Value' # 这里填写新的值
# 创建一个新的Excel文件并将修改后的数据写入其中
new_workbook = xlwt.Workbook()
new_worksheet = new_workbook.add_sheet('Sheet 1')
for row_index in range(worksheet.nrows):
for col_index in range(worksheet.ncols):
new_worksheet.write(row_index, col_index, worksheet.cell(row_index, col_index).value)
new_workbook.save('new_example.xls')