一、简介
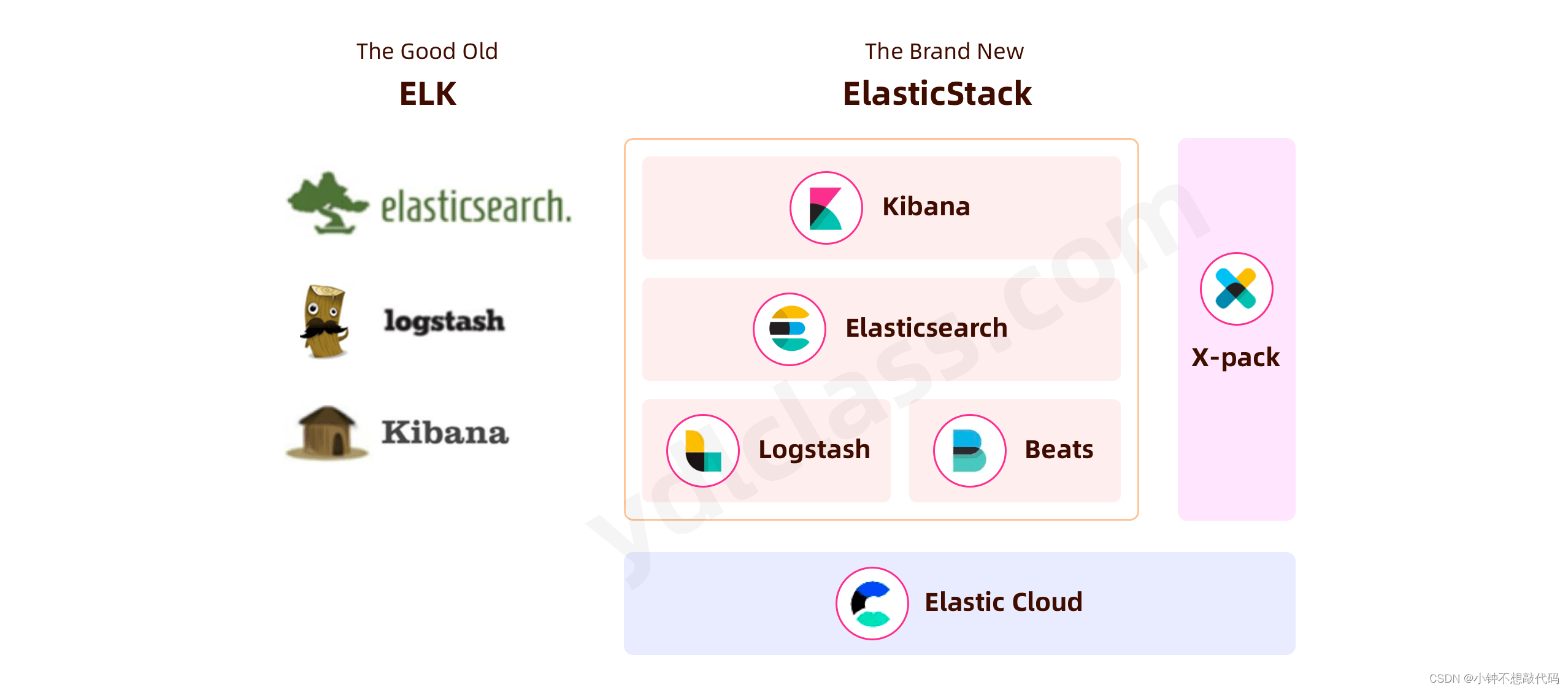
ELK是一个免费开源的日志分析架构技术栈总称,官网https://www.elastic.co/cn。包含三大基础组件,分别是Elasticsearch、Logstash、Kibana。但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据搜索、分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。下面是ELK架构:
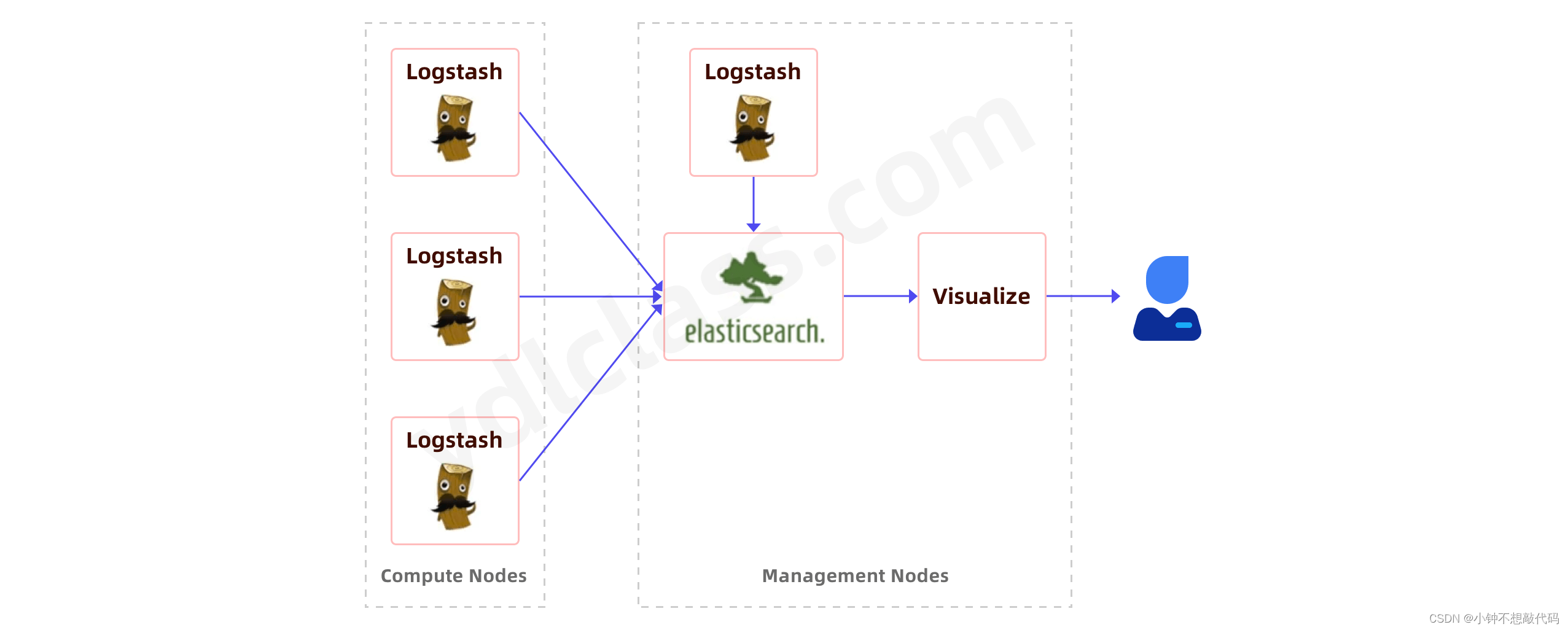
随着elk的发展,又有新成员Beats、elastic cloud的加入,所以就形成了Elastic Stack。所以说,ELK是旧的称呼,Elastic Stack是新的名字
二、特色
- 处理方式灵活:elasticsearch是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力。
- 配置简单:安装elk的每个组件,仅需配置每个组件的一个配置文件即可。修改处不多,因为大量参数已经默认配在系统中,修改想要修改的选项即可。
- 接口简单:采用json形式RESTFUL API接受数据并响应,无关语言。
- 性能高效:elasticsearch基于优秀的全文搜索技术Lucene,采用倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应。
- 灵活扩展:elasticsearch和logstash都可以根据集群规模线性拓展,elasticsearch内部自动实现集群协作。
- 数据展现华丽:kibana作为前端展现工具,图表华丽,配置简单。
三、组件介绍
Elasticsearch
- Elasticsearch 是使用java开发,基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
- Logstash 基于java开发,是一个数据抽取转化工具。一般工作方式为c/s架构,client端安装在需要收集信息的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch或其他组件上去。
Kibana
- Kibana 基于nodejs,也是一个开源和免费的可视化工具。Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
- Beats 平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Elastic cloud
- 基于 Elasticsearch 的软件即服务(SaaS)解决方案。通过 Elastic 的官方合作伙伴使用托管的 Elasticsearch 服务。
三、elasticsearch核心概念
官网:https://www.elastic.co/cn/products/elasticsearch
1、lucene和elasticsearch的关系
-
Lucene:最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂
-
Elasticsearch:基于lucene,封装了许多lucene底层功能,提供简单易用的restful api接口和许多语言的客户端,如java的高级客户端(Java High Level REST Client)和底层客户端(Java Low Level REST Client)
-
起源:Shay Banon。2004年失业,陪老婆去伦敦学习厨师。失业在家帮老婆写一个菜谱搜索引擎。封装了lucene的开源项目,compass。找到工作后,做分布式高性能项目,再封装compass,写出了elasticsearch,使得lucene支持分布式。现在是Elasticsearch创始人兼Elastic首席执行官。
2、elasticsearch的核心概念
1、NRT(Near Realtime):近实时
两方面:
- 写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。
- es搜索时:搜索和分析数据需要秒级出结果。
2、Cluster:集群
- 包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集群名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
3、Node:节点
- 每个es实例称为一个节点。节点名自动分配,也可以手动配置。
4、Index:索引
- 包含一堆有相似结构的文档数据。
索引创建规则:
- 仅限小写字母
- 不能包含\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
- 从7.0版本开始不再包含冒号
- 不能以-、_或+开头
- 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
5、Document:文档
- es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
6、Field:字段
- 就像数据库中的列(Columns),定义每个document应该有的字段。
7、Type:类型
- 每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。本教程typy都为_doc。
8、shard:分片
- index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
9、replica:副本
-
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片经行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。
-
能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
-
es6默认新建索引时,5分片,2副本,也就是一主一备,共10个分片。所以,es集群最小规模为两台。
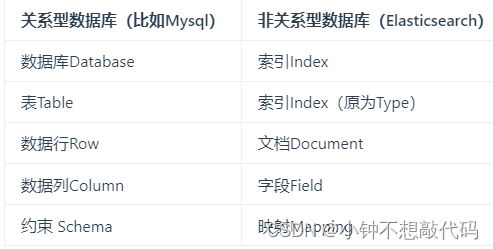
3、elasticsearch核心概念 vs. 数据库核心概念