作者:开七 蚂蚁集团数据技术专家
本文围绕 hash cluster 表运用及 Shuffle 过程原理进行讨论,欢迎各位开发者加入大数据计算 MaxCompute 社区:https://developer.aliyun.com/group/maxcompute
概述
蚂蚁的转化归因在初期运行两个多小时的情况下,进行了一系列优化,其中建立hash cluster表及强制hash关联及Shuffle的手动干预进行remove操作此部分优化占了较大比重。本文则主要讲述hash cluster表的一些运用。
Hash cluster表具有两个作用:
-
存储预排序的重排压缩。Hash cluster表采用分桶排序操作,若相同的值重复度高,则可以达到更好的压缩效果。
-
下游任务的Shuffle Remove。Hash cluster表由于采用对指定字段分桶操作,下游若一些关联、聚合操作与分桶键策略相同,则会进行Shuffle Remove操作。MaxCompute操作中,Shuffle是昂贵的,因此有必要在优化阶段尽可能移除不必要的Shuffle。什么情况下可以移除Shuffle?简单来说就是数据本身已经具有某些数据分布特性,刚好这个数据分布特性满足了上游算子对这份数据的分布要求,就不需要再做Shuffle,这个也是Hash cluster表的重要应用场景。
前言
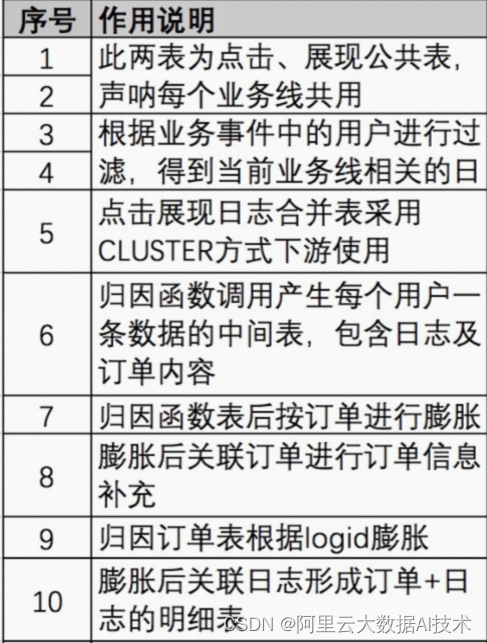
转化归因任务加工相对较复杂,在此对其中关键步骤做个说明:
1、源头分三部分,访问日志数据A,点击日志数据B,接入的事件数据C,此三部分数据表已设置为4096分桶的hash表。
2、以上三部分数据以用户进行分组,分别传入用户的点击、访问和事件数据,通过udf处理得到单用户的归因结果数据(以字条串返回)。
3、返回以用户粒度的结果数据进行字段拆分后以用户的事件id进行膨胀,膨胀后关联用户事件数据补充事件数据后其它字段。
4、上一步关联后的结果数据以日志id进行膨胀,膨胀后的数据关联访问和点击日志数据得到日志中的其它一些补充字段。
以上步骤按单用户数据处理过程流程大致如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iMR7tkd1-1684723382294)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/b6c137ce3d324099a5b00d9eaa520aac~tplv-k3u1fbpfcp-zoom-1.image "1.jpg")]](https://img-blog.csdnimg.cn/67abe0c6369c4fc89b5b511eaf632c64.png)
以支付宝支付线来讲,最初总计运行两个来小时,加工逻辑步骤有近十来个任务。后续进行了udf优化并逻辑合并为一个script,图2右部分。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KX4iZboC-1684723382295)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/461d95a774e244ab9d879c24fa05d280~tplv-k3u1fbpfcp-zoom-1.image "image.png")]](https://img-blog.csdnimg.cn/c3d9f337edd843809b06978c53c92700.png)
优化过程
中间状态
以下任务是在经过多任务合并为一script任务后内容,其中源头输入表点击(mid_log_clk_xxxx_di)和访问(mid_log_vst_xxxx_di)表建立hash cluster,而事件表是以事件代码为二级分区的普通表(事件表是通过页面通过不同的事件码在线接入后生成不同的任务产出的表),以支付线为例,任务改造后稳定在半小时左右,但目前随着事件增加有所增长。
点击访问建表主要内容
CLUSTERED BY (user_id ASC) SORTED BY (user_id ASC,log_id ASC) INTO 4096 BUCKETS
整体运行图如下,相比原来十来个任务,无论是日常运行、历史回刷都变的相对简洁。
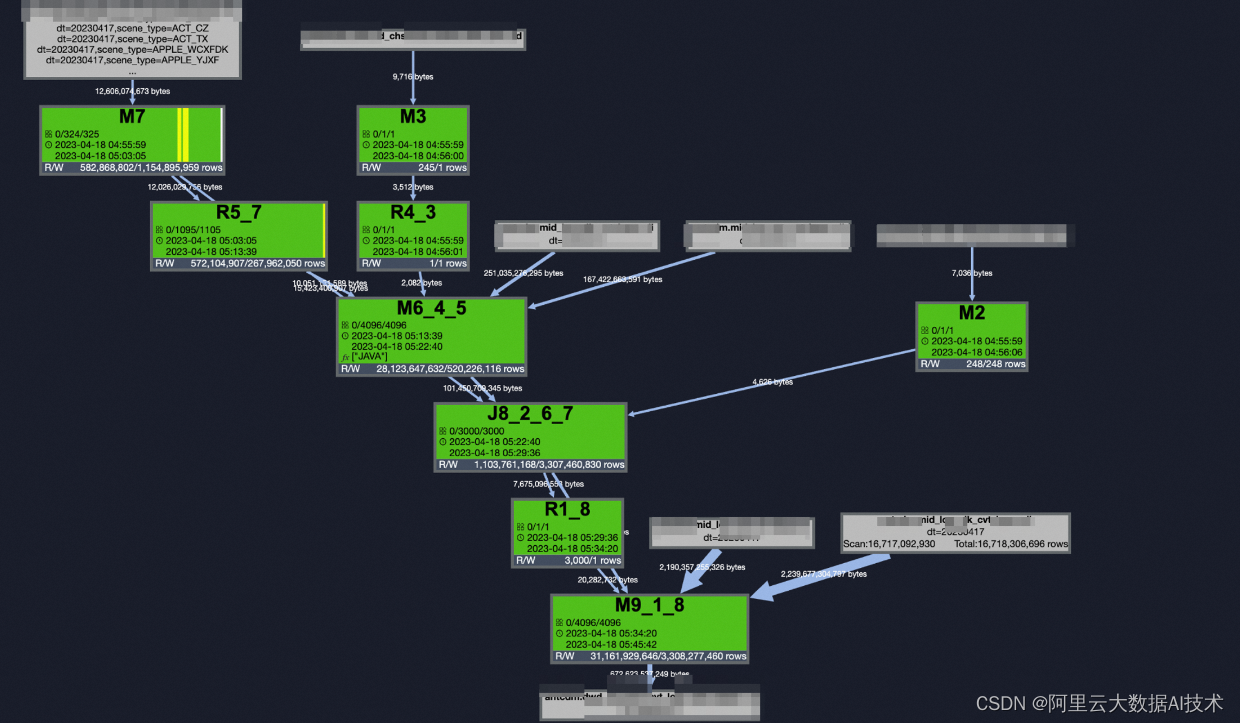
在此过程中个人分析若事件输入表能在运行过程中变hash cluster的话,那下游按理可再减少一些Shuffle操作,尝试对事件表增加 DISTRIBUTE BY user_id SORT BY scene_type,order_id 操作且设置参数set odps.sql.reducer.instances=4096,但测试发现下游对此无感知,联系MaxCompute 开发人员得知目前暂无此功能。
接入事件hash表不能在运行中得到那只能再增加一个任务把事件数据插入一cluster表供任务使用,但由于在主链路上,增加的时间影响整体产出时间,但以支付线几个亿数据量为例,插入cluster表整体3分钟左右,建立cluster后整体执行图如下:
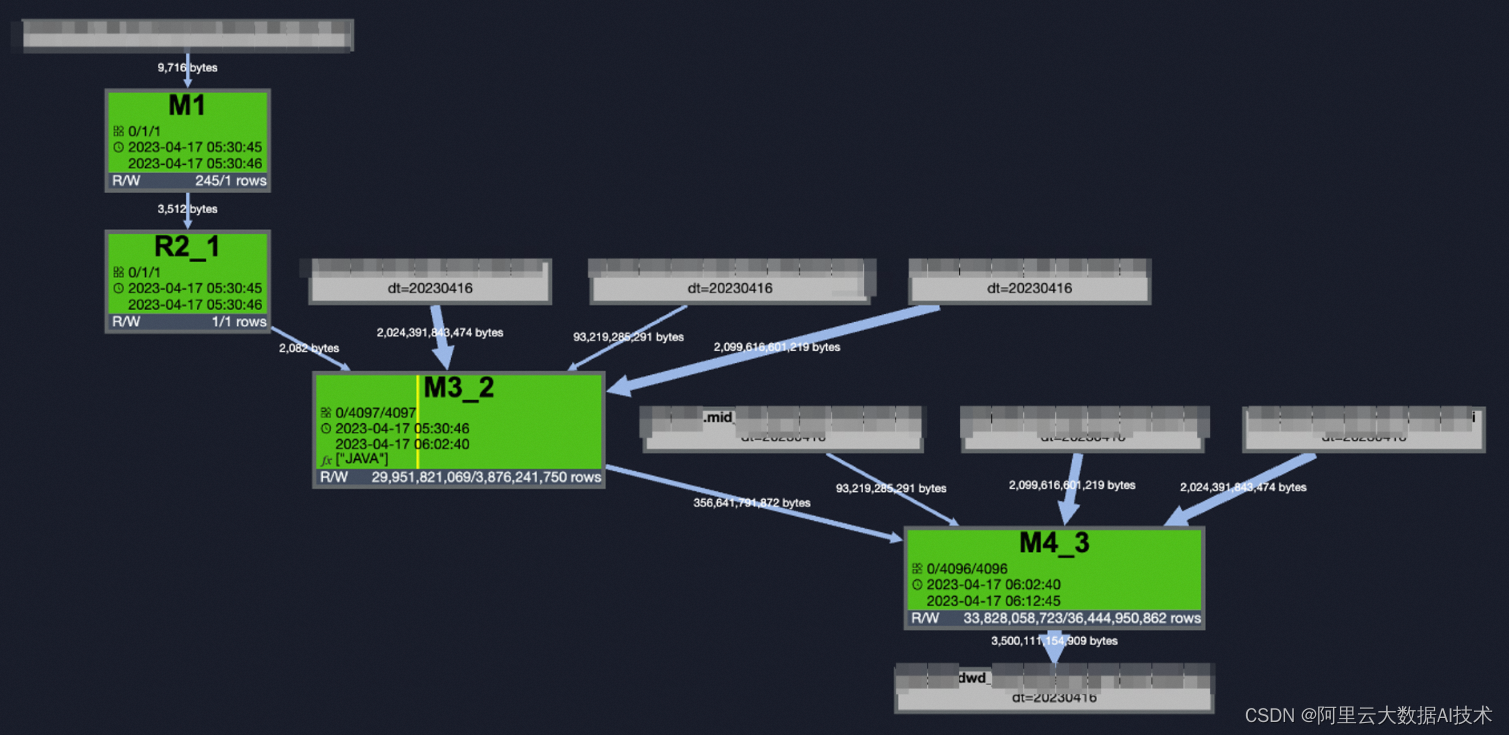
以上执行图已经相当简单,运行速度相比原来任务及增加的上游整体也有一定的提升,但是发现两主task中,m3和m4同样都是4096实例,都是按用户分桶进行的分发,按理此两M应该是可以Shuffle remove进行合并的,问及MaxCompute开发人员大致是一些复杂操作后属性丢失后不能消除Shuffle。
最终状态
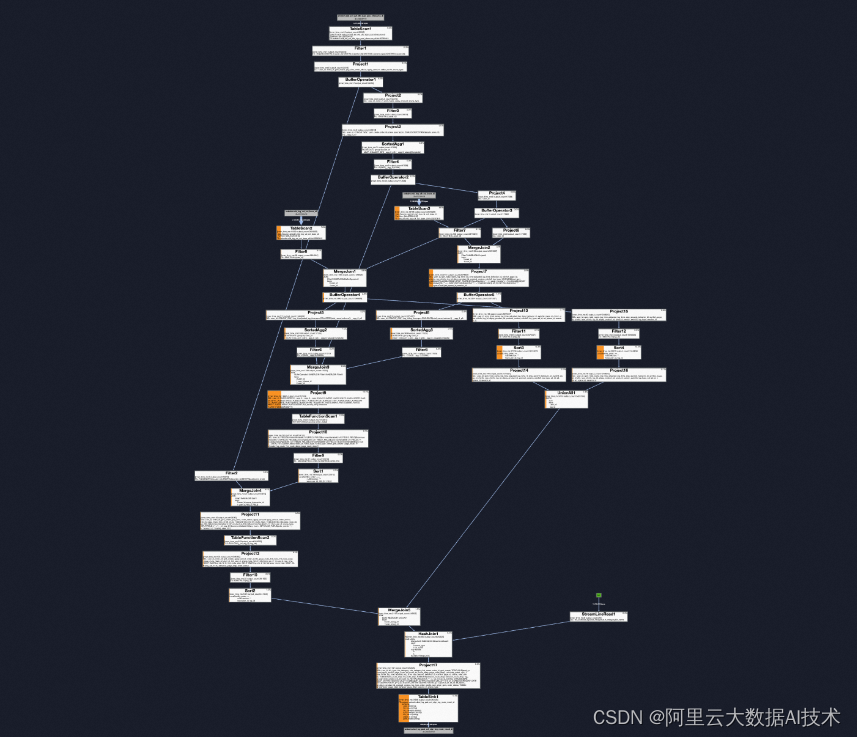
虽然图5的执行计划相对来说已经非常简洁,但一些实际结果与认知不同时总想找到问题出在哪里。因此,我对任务中的一些sql嵌套进行层次减少,对一些关联先拆解再慢慢增加,在此过程中发现增加了一个小表的mapjoin会导致下游需要进行Shuffle(理论上小表mapjoin不影响主表分发),其中一个黑名单列表,数据量少且近三年都无增加数据,因此直接改造为固定值传入,另外一个小表在最后再进行mapjoin关联,最终执行图如下,只有一个主的task,非常简洁。

以下为m2中的算子,非常复杂,但无需Shuffle执行效率非常高。
执行结果
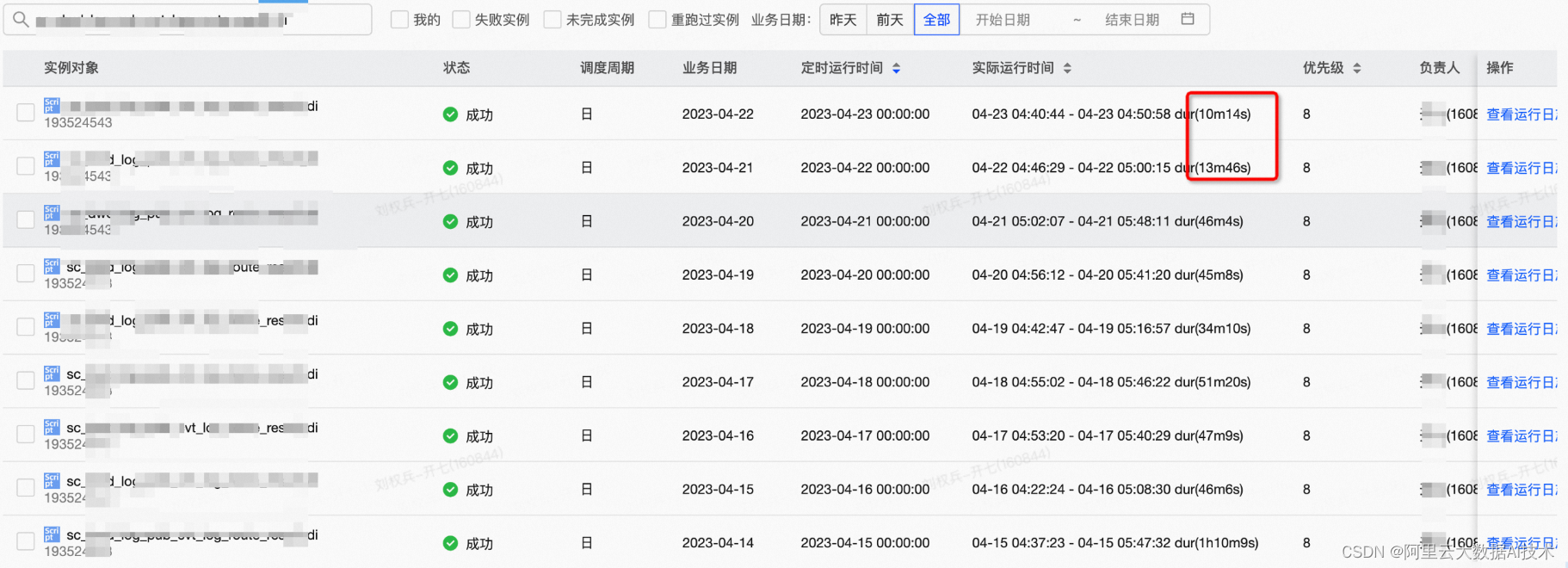
最终执行时长不到20分钟,相对原先减少一半,而且消耗的cu及内存都有所降低,转化归因整体链路产出提前20分钟+。

总结
1、本文的一些优化整体是基于 Hash Clustering Table的建立,在创建Hash表时需要考虑分桶键的设定,并不是说一定要所有的关联键设置为分桶键,在考虑Hash的一些任务性能的同时,也需要考虑表的存储压缩大小。
2、针对MaxCompute平台的一些策略原理,首先需要有自己的一些自身认知,很多时候不一定是一两个文档能够说清楚,更需要一些实践的测试来加深知识点的理解。
3、MaxCompute很多方面已经非常智能及高效,希望在自动的优化方面可以更加智能 。
【 MaxCompute发布免费试用计划,为数仓建设提速 】新用户可0元领取5000CU*小时计算资源与100GB存储,有效期3个月。 立即领取>>